


在2014年的ImageNet图像识别挑战赛中,一个名叫GoogLeNet 的网络架构大放异彩。以前流行的网络使用小到1×1,大到7×7的卷积核。本文的一个观点是,有时使用不同大小的卷积核组合是有利的。
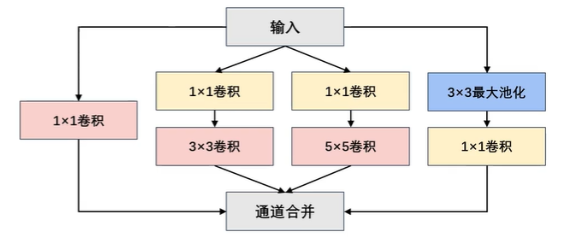
在GoogLeNet中,基本的卷积块被称为Inception块(Inception block)。这很可能得名于电影《盗梦空间》(Inception),因为电影中的一句话"我们需要走得更深"("We needto go deeper") 。Inception块由四条并行路径组成。前三条路径使用窗口大小为1x1、3x3和5x5的卷积层,从不同空间大小中提取信息。中间的两条路径在输入上执行1x1卷积,以减少通道数,从而降低模型的复杂性。第四条路径使用3x3最大池化层,然后使用1x1卷积层来改变通道数。这四条路径都使用合适的填充来使输入与输出的高和宽一致,最后我们将每条线路的输出在通道维度上连结,并构成Inception块的输出。在Inception块中,通常调整的超参数是每层输出通道数
回到他那个图里面你会发现,这里的一个通过我们最大的池化输出的特征图,有四条线.这个是1×1的卷积,这里还是1×1的卷积,之后呢做3×3的卷积,然后这里1×1的卷积再做5×5的卷积,然后这里还有一个3*3×3的最大池化我们1×1在每个路径当中啊都用到了.四个路径输出之后做个comcat的操作即----按通道的方向进行融合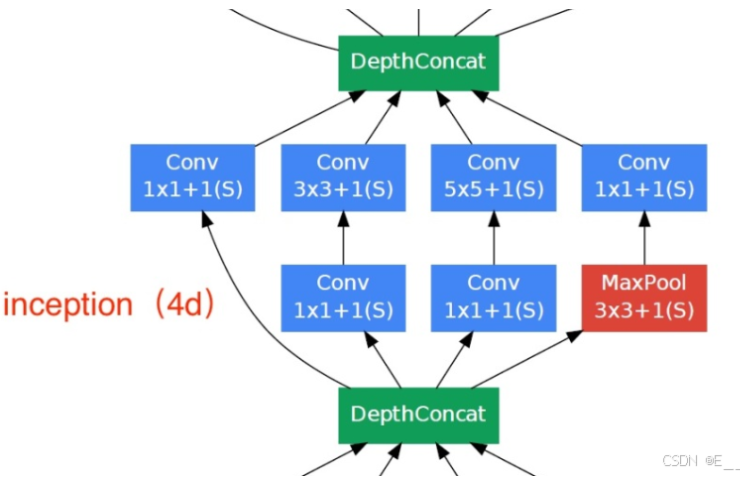
通道在维度上连接什么意思呢???前面所讲通过填充和不符来使输入和输出的通道数高和宽一致,累加操作可以合成224*224*100的图片
网络结构
输入为224x224x3三通道的图像。
路径1:
(1)输入为224x224x3,卷积核数量为64个;卷积核的尺寸大小为1x1x3;步幅为1 (stride=l),填充为0(padding=0);卷积后得到shape为224x224x64的特征图输出,
路径2:
(1) 输入为224x224x3,卷积核数量为96个;卷积核的尺寸大小为1x1x3;步幅为1 (stride = 1),填充为96(padding=96);卷积后得到shape为224x224x64的特征图输出。
(2)输入为224x224x96,卷积核数量为128个;卷积核的尺寸大小为3X3X ;步幅为1 (stride =1),填充为1 (padding=1);卷积后得到shape为224x224x128的特征图输出。
路径3:
(1)输入为224x224x3,卷积核数量为16个;卷积核的尺寸大小为1x1x3;步幅为1 (stride = 1),填充为0 (padding=0);卷积后得至ijshape为224x224x16的特征图输出。
(2)输入为224x224x16,卷积核数量为32个;卷积核的尺寸大小为5x5x16;步幅为1 (stride=1),填充为2 ( padding=2 );卷积后得到shape为224x224x32的特征图输出。
路径4:
(1)输入为224x224x3,池化核的尺寸大小为3x3;步幅为 1 (stride = 1),填充为 1 (padding=l);池化后得shape为224x224x3的特征图输出。
(2)输入为224x224x3,卷积核数量为32个;卷积核的尺寸大小为1x1x3;步幅为1 (stride = 1),填充为0 (padding=0);卷积后得到shape为224x224x32的特征图输出
1×1的卷积

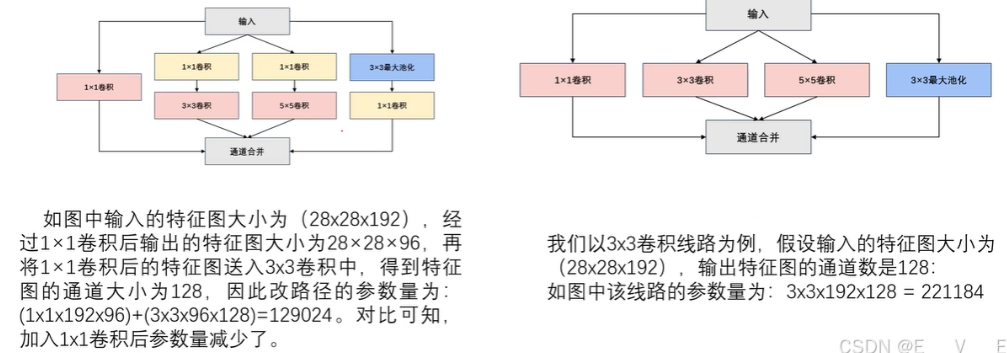
输入28×28乘192特征图.假如我们卷积核只有一个的话,不停的一个一个再做卷积运算,输出一百九十二个,再把这个192个卷积运算的结果进行一个相加,输出是一张特征图 如果啊如果你这里有32个卷积核,输出的特征图肯定是32嘛,输出的是一张卷积一张特征图,这里的一张特征图其实是包含在前面192个特征图的所有的信息,成了什么跨通道的交互和信息整合了.每32个这个特征图里面,每张都包含了前面192个通道里面的所有的信息嘛
全局平均池化层GAP

需要8分钟的解释
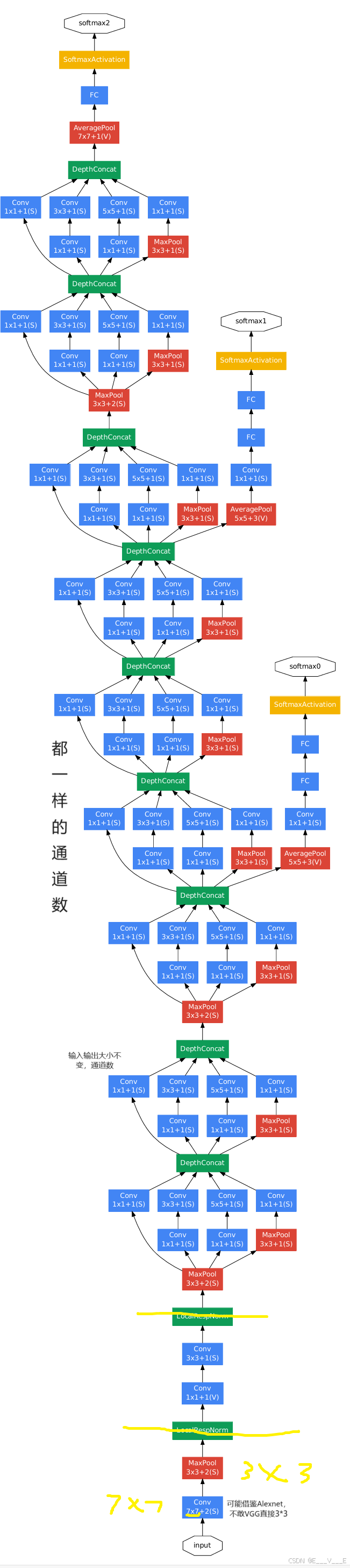
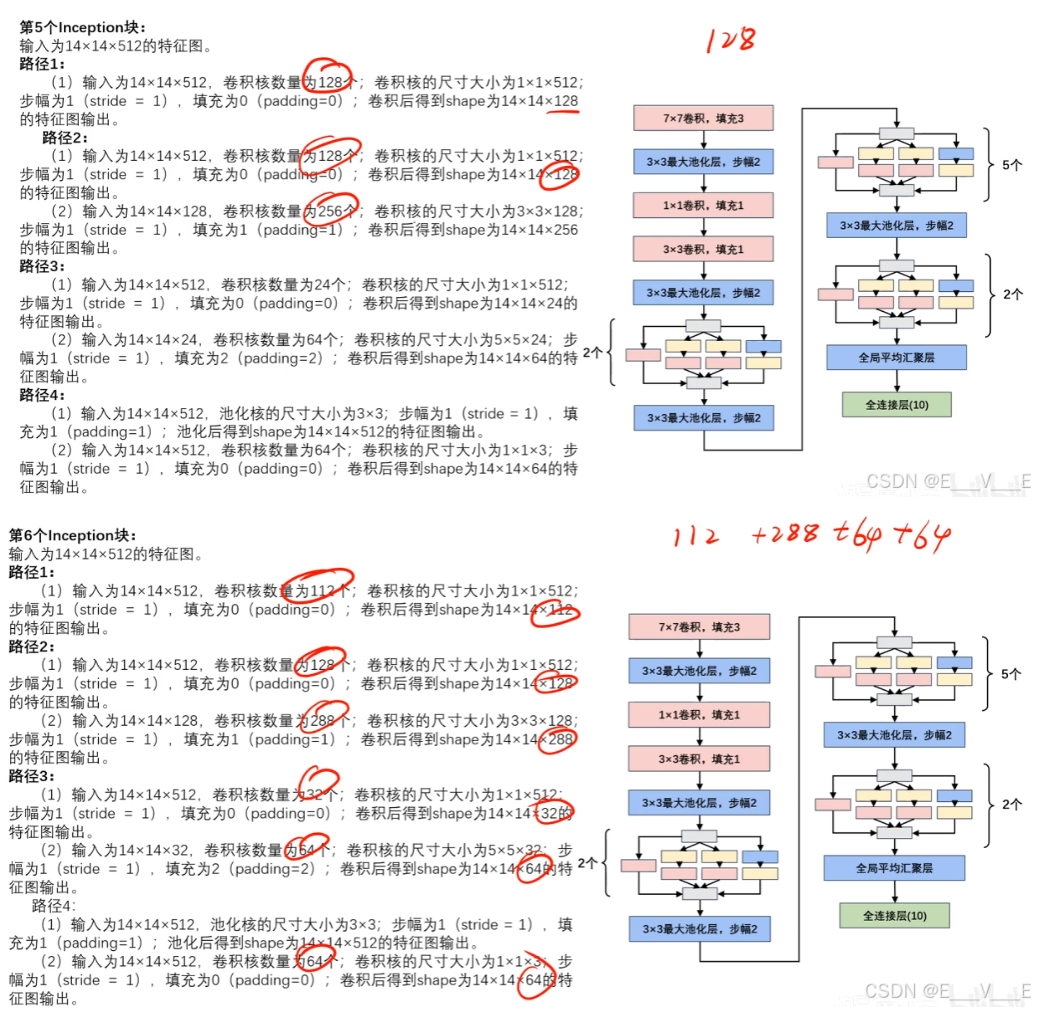
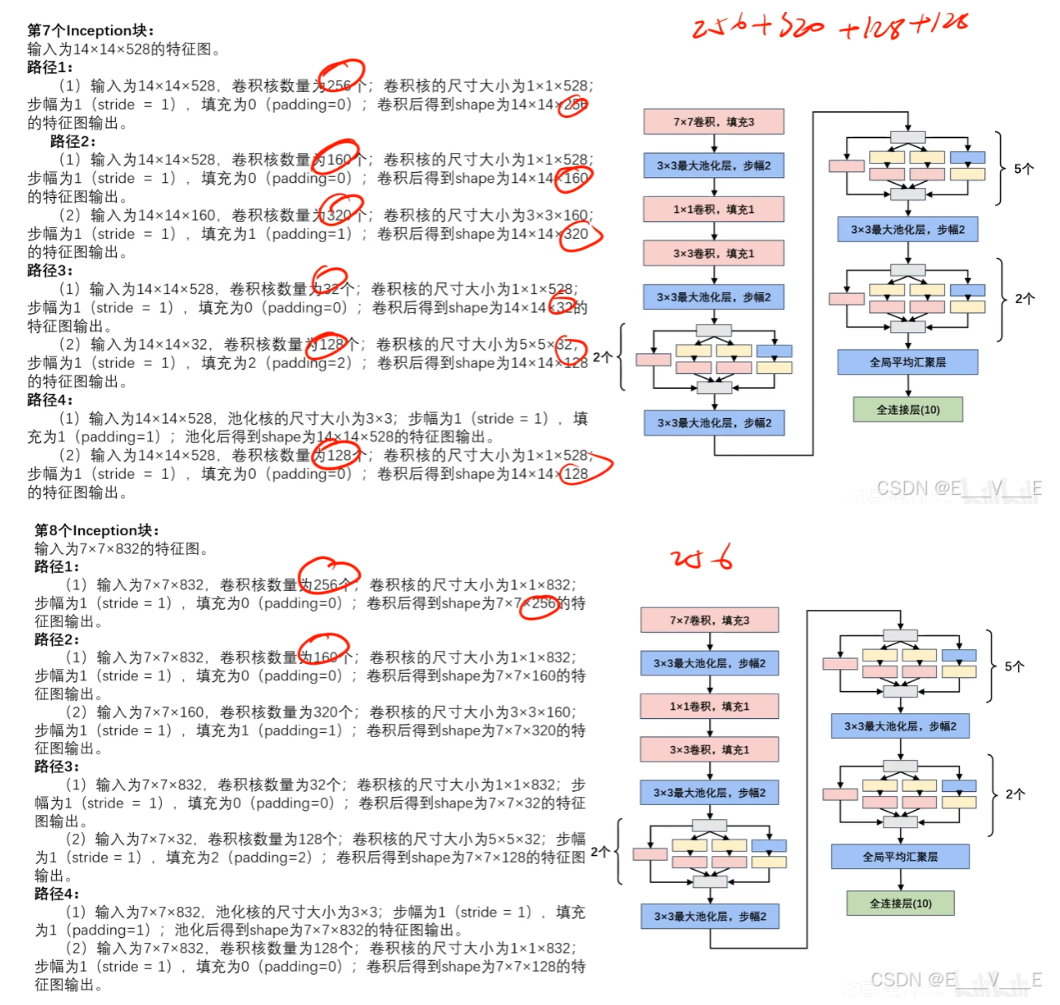
网络参数
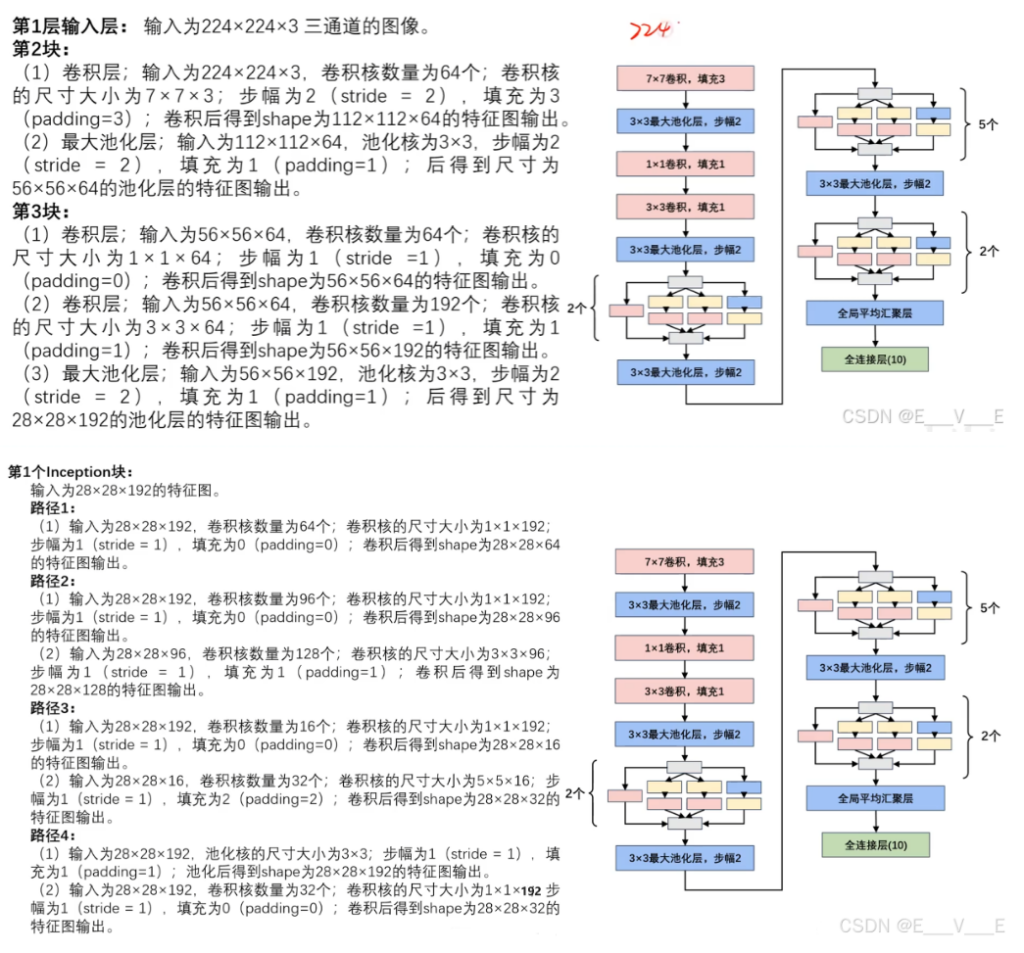
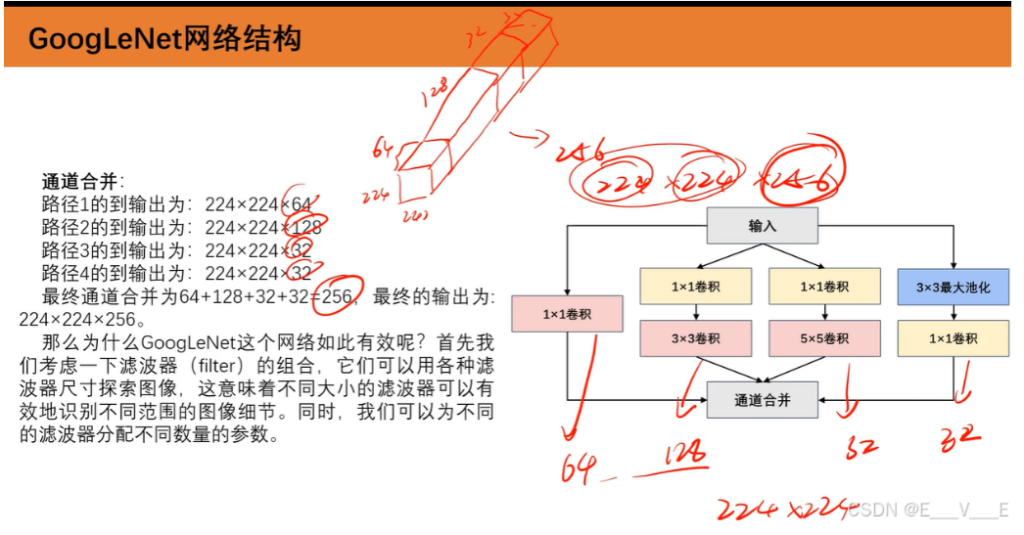
通道合并:
路径1的到输出为: 28×28×64
路径2的到输出为: 28×28×128
路径3的到输出为: 28×28×32
路径4的到输出为: 28×28x32
最终通道合并为64+128+32+32=256, 最终的输出为:28×28×256.
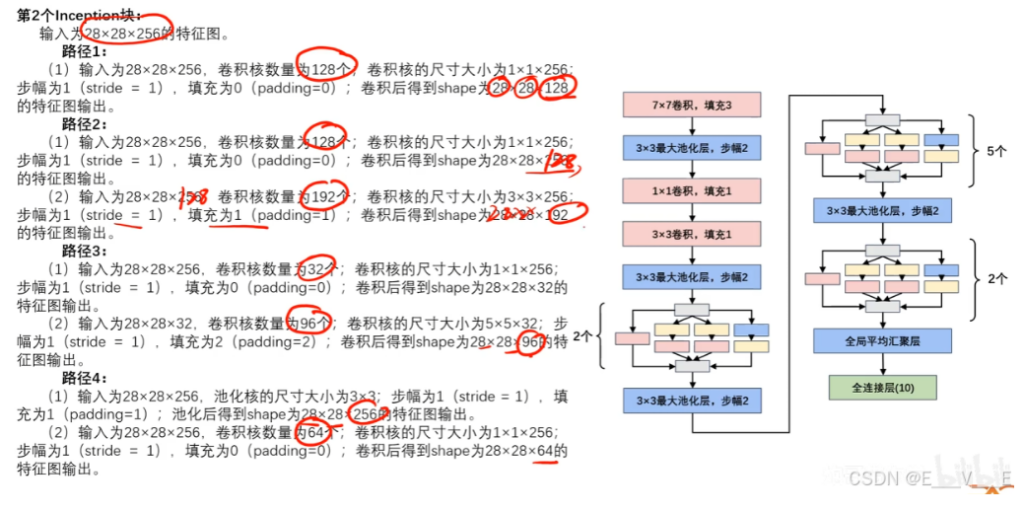
通道合并:
路径1的到输出为:28×28×128
路径2的到输出为:28×28×192
路径3的到输出为:28×28×96
路径4的到输出为:28×28×64
最终通道合并为128+192+96+64=480,最终的输出为28×28×480。
最大池化模块:
输入为28×28×480。池化核的尺寸大小为3×3;步幅为2(stride = 2),填充为1(padding=1);池化后得到shape 为14×14×480的特征图输出。
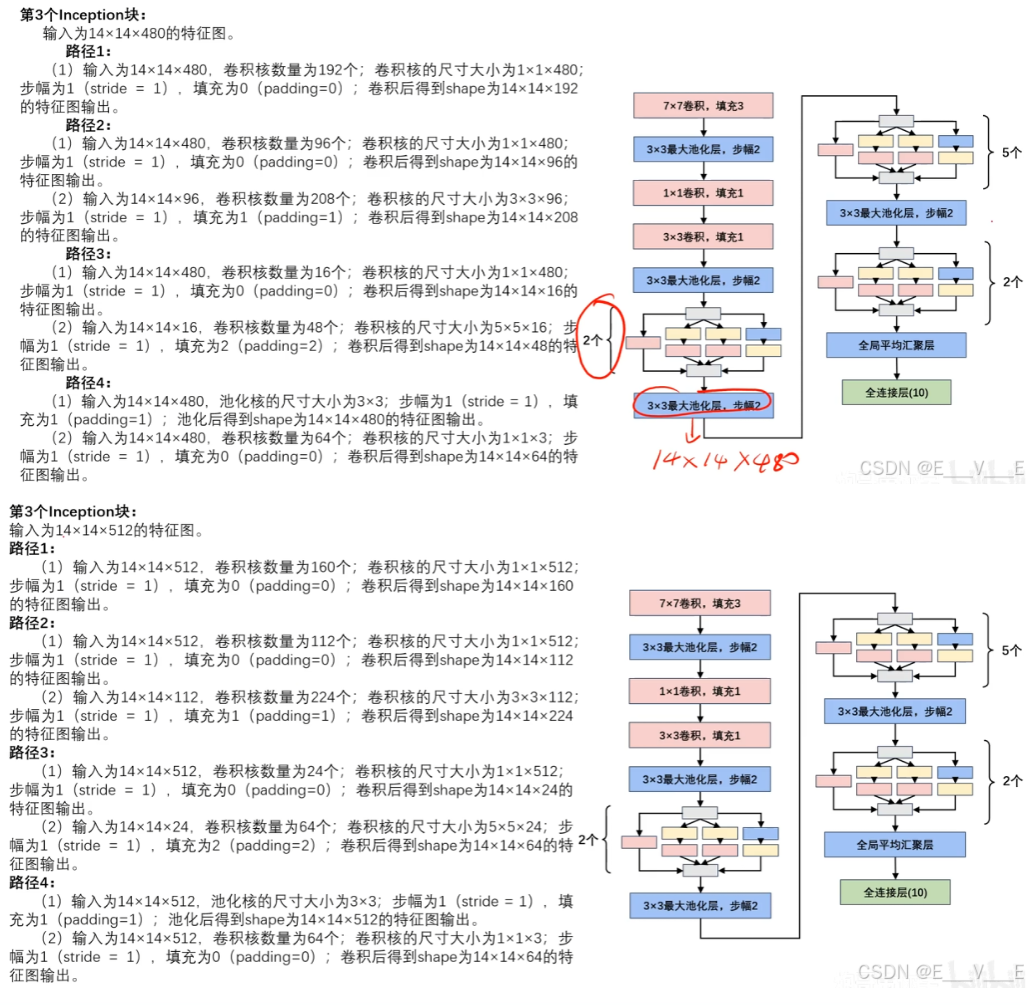
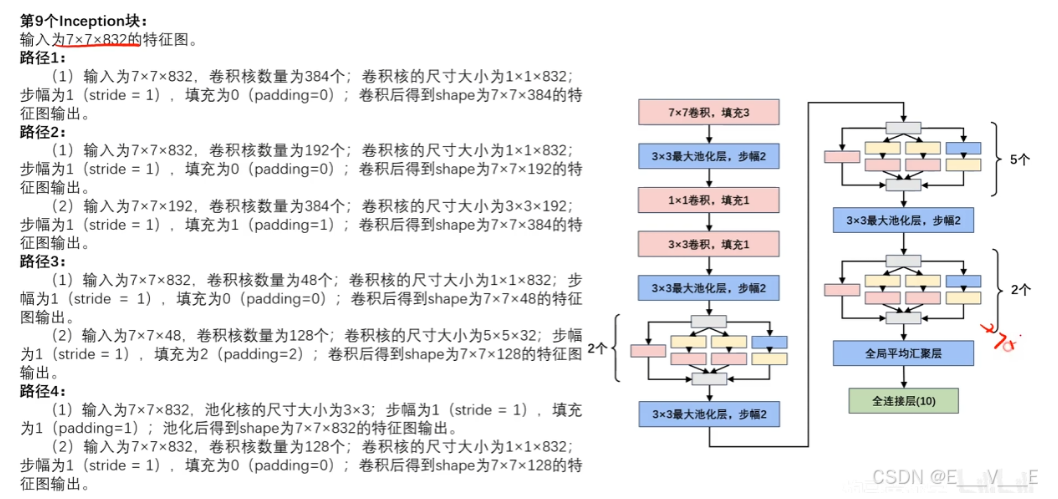
最后全局平均池化模块:输入为7×7×1024。池化后得到shape为1×1×1024的特征图输出。
Flatten层:输入为1×1×1024,输出为1×1024
线性全连接层:输入为1×1024。线性全连接层神经元个数分别为1000。最后一层全连接层用softmax输出1000个分类。共计1.38亿的参数
model.py
import torch
from torch import nn
from torchsummary import summary
class Inception(nn.Module):
def __init__(self, in_channels, c1, c2, c3, c4):
super(Inception, self).__init__()
self.ReLU = nn.ReLU()
# 路线1,单1×1卷积层
self.p1_1 = nn.Conv2d(in_channels=in_channels, out_channels=c1, kernel_size=1)
# 路线2,1×1卷积层, 3×3的卷积
self.p2_1 = nn.Conv2d(in_channels=in_channels, out_channels=c2[0], kernel_size=1)
self.p2_2 = nn.Conv2d(in_channels=c2[0], out_channels=c2[1], kernel_size=3, padding=1)
# 路线3,1×1卷积层, 5×5的卷积
self.p3_1 = nn.Conv2d(in_channels=in_channels, out_channels=c3[0], kernel_size=1)
self.p3_2 = nn.Conv2d(in_channels=c3[0], out_channels=c3[1], kernel_size=5, padding=2)
# 路线4,3×3的最大池化, 1×1的卷积
self.p4_1 = nn.MaxPool2d(kernel_size=3, padding=1, stride=1)
self.p4_2 = nn.Conv2d(in_channels=in_channels, out_channels=c4, kernel_size=1)
def forward(self, x):
p1 = self.ReLU(self.p1_1(x))
p2 = self.ReLU(self.p2_2(self.ReLU(self.p2_1(x))))
p3 = self.ReLU(self.p3_2(self.ReLU(self.p3_1(x))))
p4 = self.ReLU(self.p4_2(self.p4_1(x)))
#print(p1.shape, p2.shape, p3.shape, p4.shape)
return torch.cat((p1, p2, p3, p4), dim=1)
# 输出结构是(batchsize, channel, Hout, Wout),所以dim是1
class GoogLeNet(nn.Module):
def __init__(self, Inception):
super(GoogLeNet, self).__init__()
# 直接弄了,弄个块太麻烦了
self.b1 = nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=64, kernel_size=7, stride=2, padding=3),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
# 目前做的灰度图,单通道,后续再改就行了
self.b2 = nn.Sequential(
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=1),
nn.ReLU(),
nn.Conv2d(in_channels=64, out_channels=192, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
# 局部规划没什么用不写了
self.b3 = nn.Sequential(
Inception(192, 64, (96, 128), (16, 32), 32),
Inception(256, 128, (128, 192), (32, 96), 64),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
self.b4 = nn.Sequential(
Inception(480, 192, (96, 208), (16, 48), 64),
Inception(512, 160, (112, 224), (24, 64), 64),
Inception(512, 128, (128, 256), (24, 64), 64),
Inception(512, 112, (128, 288), (32, 64), 64),
Inception(528, 256, (160, 320), (32, 128), 128),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
# 链式求导导致的趋0化
self.b5 = nn.Sequential(
Inception(832, 256, (160, 320), (32, 128), 128),
Inception(832, 384, (192, 384), (48, 128), 128),
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(),
nn.Linear(1024, 10))
# 经过输出是H*W*1024,全局池化后就是1*1*1024
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode="fan_out", nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
#前向传播
def forward(self, x):
x = self.b1(x)
x = self.b2(x)
x = self.b3(x)
x = self.b4(x)
x = self.b5(x)
return x
if __name__ == "__main__":
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = GoogLeNet(Inception).to(device)
print(summary(model, (1, 224, 224)))model_train.py
import copy
import time
import torch
from torchvision.datasets import FashionMNIST
from torchvision import transforms
import torch.utils.data as Data
import numpy as np
import matplotlib.pyplot as plt
from model import GoogLeNet, Inception
import torch.nn as nn
import pandas as pd
def train_val_data_process():
train_data = FashionMNIST(root='./data',
train=True,
transform=transforms.Compose([transforms.Resize(size=224), transforms.ToTensor()]),
download=True)
train_data, val_data = Data.random_split(train_data, [round(0.8*len(train_data)), round(0.2*len(train_data))])
train_dataloader = Data.DataLoader(dataset=train_data,
batch_size=32,
shuffle=True,
num_workers=2)
val_dataloader = Data.DataLoader(dataset=val_data,
batch_size=32,
shuffle=True,
num_workers=2)
return train_dataloader, val_dataloader
def train_model_process(model, train_dataloader, val_dataloader, num_epochs):
# 设定训练所用到的设备,有GPU用GPU没有GPU用CPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 使用Adam优化器,学习率为0.001
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 损失函数为交叉熵函数
criterion = nn.CrossEntropyLoss()
# 将模型放入到训练设备中
model = model.to(device)
# 复制当前模型的参数
best_model_wts = copy.deepcopy(model.state_dict())
# 初始化参数
# 最高准确度
best_acc = 0.0
# 训练集损失列表
train_loss_all = []
# 验证集损失列表
val_loss_all = []
# 训练集准确度列表
train_acc_all = []
# 验证集准确度列表
val_acc_all = []
# 当前时间
since = time.time()
for epoch in range(num_epochs):
print("Epoch {}/{}".format(epoch, num_epochs-1))
print("-"*10)
# 初始化参数
# 训练集损失函数
train_loss = 0.0
# 训练集准确度
train_corrects = 0
# 验证集损失函数
val_loss = 0.0
# 验证集准确度
val_corrects = 0
# 训练集样本数量
train_num = 0
# 验证集样本数量
val_num = 0
# 对每一个mini-batch训练和计算
for step, (b_x, b_y) in enumerate(train_dataloader):
# 将特征放入到训练设备中
b_x = b_x.to(device)
# 将标签放入到训练设备中
b_y = b_y.to(device)
# 设置模型为训练模式
model.train()
# 前向传播过程,输入为一个batch,输出为一个batch中对应的预测
output = model(b_x)
# 查找每一行中最大值对应的行标
pre_lab = torch.argmax(output, dim=1)
# 计算每一个batch的损失函数
loss = criterion(output, b_y)
# 将梯度初始化为0
optimizer.zero_grad()
# 反向传播计算
loss.backward()
# 根据网络反向传播的梯度信息来更新网络的参数,以起到降低loss函数计算值的作用
optimizer.step()
# 对损失函数进行累加
train_loss += loss.item() * b_x.size(0)
# 如果预测正确,则准确度train_corrects加1
train_corrects += torch.sum(pre_lab == b_y.data)
# 当前用于训练的样本数量
train_num += b_x.size(0)
for step, (b_x, b_y) in enumerate(val_dataloader):
# 将特征放入到验证设备中
b_x = b_x.to(device)
# 将标签放入到验证设备中
b_y = b_y.to(device)
# 设置模型为评估模式
model.eval()
# 前向传播过程,输入为一个batch,输出为一个batch中对应的预测
output = model(b_x)
# 查找每一行中最大值对应的行标
pre_lab = torch.argmax(output, dim=1)
# 计算每一个batch的损失函数
loss = criterion(output, b_y)
# 对损失函数进行累加
val_loss += loss.item() * b_x.size(0)
# 如果预测正确,则准确度train_corrects加1
val_corrects += torch.sum(pre_lab == b_y.data)
# 当前用于验证的样本数量
val_num += b_x.size(0)
# 计算并保存每一次迭代的loss值和准确率
# 计算并保存训练集的loss值
train_loss_all.append(train_loss / train_num)
# 计算并保存训练集的准确率
train_acc_all.append(train_corrects.double().item() / train_num)
# 计算并保存验证集的loss值
val_loss_all.append(val_loss / val_num)
# 计算并保存验证集的准确率
val_acc_all.append(val_corrects.double().item() / val_num)
print("{} train loss:{:.4f} train acc: {:.4f}".format(epoch, train_loss_all[-1], train_acc_all[-1]))
print("{} val loss:{:.4f} val acc: {:.4f}".format(epoch, val_loss_all[-1], val_acc_all[-1]))
if val_acc_all[-1] > best_acc:
# 保存当前最高准确度
best_acc = val_acc_all[-1]
# 保存当前最高准确度的模型参数
best_model_wts = copy.deepcopy(model.state_dict())
# 计算训练和验证的耗时
time_use = time.time() - since
print("训练和验证耗费的时间{:.0f}m{:.0f}s".format(time_use//60, time_use%60))
# 选择最优参数,保存最优参数的模型
model.load_state_dict(best_model_wts)
# torch.save(model.load_state_dict(best_model_wts), "C:/Users/86159/Desktop/LeNet/best_model.pth")
torch.save(best_model_wts, "./GoogLeNet/best_model.pth")
train_process = pd.DataFrame(data={"epoch":range(num_epochs),
"train_loss_all":train_loss_all,
"val_loss_all":val_loss_all,
"train_acc_all":train_acc_all,
"val_acc_all":val_acc_all,})
return train_process
def matplot_acc_loss(train_process):
# 显示每一次迭代后的训练集和验证集的损失函数和准确率
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(train_process['epoch'], train_process.train_loss_all, "ro-", label="Train loss")
plt.plot(train_process['epoch'], train_process.val_loss_all, "bs-", label="Val loss")
plt.legend()
plt.xlabel("epoch")
plt.ylabel("Loss")
plt.subplot(1, 2, 2)
plt.plot(train_process['epoch'], train_process.train_acc_all, "ro-", label="Train acc")
plt.plot(train_process['epoch'], train_process.val_acc_all, "bs-", label="Val acc")
plt.xlabel("epoch")
plt.ylabel("acc")
plt.legend()
plt.show()
if __name__ == '__main__':
# 加载需要的模型
GoogLeNet = GoogLeNet(Inception)
# 加载数据集
train_data, val_data = train_val_data_process()
# 利用现有的模型进行模型的训练
train_process = train_model_process(GoogLeNet, train_data, val_data, num_epochs=20)
matplot_acc_loss(train_process)model.test.py
import torch
import torch.utils.data as Data
from torchvision import transforms
from torchvision.datasets import FashionMNIST
from model import GoogLeNet, Inception
def test_data_process():
test_data = FashionMNIST(root='./data',
train=False,
transform=transforms.Compose([transforms.Resize(size=224), transforms.ToTensor()]),
download=True)
test_dataloader = Data.DataLoader(dataset=test_data,
batch_size=1,
shuffle=True,
num_workers=0)
return test_dataloader
def test_model_process(model, test_dataloader):
# 设定测试所用到的设备,有GPU用GPU没有GPU用CPU
device = "cuda" if torch.cuda.is_available() else 'cpu'
# 讲模型放入到训练设备中
model = model.to(device)
# 初始化参数
test_corrects = 0.0
test_num = 0
# 只进行前向传播计算,不计算梯度,从而节省内存,加快运行速度
with torch.no_grad():
for test_data_x, test_data_y in test_dataloader:
# 将特征放入到测试设备中
test_data_x = test_data_x.to(device)
# 将标签放入到测试设备中
test_data_y = test_data_y.to(device)
# 设置模型为评估模式
model.eval()
# 前向传播过程,输入为测试数据集,输出为对每个样本的预测值
output= model(test_data_x)
# 查找每一行中最大值对应的行标
pre_lab = torch.argmax(output, dim=1)
# 如果预测正确,则准确度test_corrects加1
test_corrects += torch.sum(pre_lab == test_data_y.data)
# 将所有的测试样本进行累加
test_num += test_data_x.size(0)
# 计算测试准确率
test_acc = test_corrects.double().item() / test_num
print("测试的准确率为:", test_acc)
if __name__ == "__main__":
# 加载模型
model = GoogLeNet(Inception)
model.load_state_dict(torch.load('best_model.pth'))
# # 利用现有的模型进行模型的测试
test_dataloader = test_data_process()
test_model_process(model, test_dataloader)
# 设定测试所用到的设备,有GPU用GPU没有GPU用CPU
device = "cuda" if torch.cuda.is_available() else 'cpu'
model = model.to(device)
classes = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
with torch.no_grad():
for b_x, b_y in test_dataloader:
b_x = b_x.to(device)
b_y = b_y.to(device)
# 设置模型为验证模型
model.eval()
output = model(b_x)
pre_lab = torch.argmax(output, dim=1)
result = pre_lab.item()
label = b_y.item()
print("预测值:", classes[result], "------", "真实值:", classes[label])


Comments NOTHING