


这篇文章深入探讨了 Java 监控体系中(特别是基于 Micrometer 和 Spring Boot Actuator)关于 Metric Gauge(仪表盘)注册机制的一个经典误区与优化过程。
为了让你彻底理解,我将内容拆解为三个部分进行详细讲解:
- 原理篇:Micrometer 的注册机制与“引用陷阱”
- 分析篇:为什么旧代码“看起来错”却能跑?及其弊端
- 重构篇:如何优雅地实现高性能、可视化的指标监控
第一部分:原理篇——Micrometer 的注册机制与“引用陷阱”
要理解文章的核心矛盾,首先必须搞清楚 Metrics.gauge 底层是怎么工作的。
1. Gauge 的本质:持有对象引用
不同于 Counter(计数器)是每次调用 increment() 就加 1,Gauge(仪表盘)通常用于反映瞬时状态(比如当前线程池活跃线程数、内存占用)。
当你调用以下代码时:
Metrics.gauge("core.size", tags, myObj, MyObj::getValue);Micrometer 做了两件事:
- 持有引用:它不会把
getValue()的结果存下来,而是持有了myObj这个对象的内存引用(Reference)。 - 被动拉取:只有当 Prometheus 来“刮取”(Scrape)数据时,Micrometer 才会通过这个引用,去调用
myObj.getValue()获取当前值。
2. “第一次注册生效”原则(First Wins)
这是文章中最大的知识点。Micrometer 内部维护了一个 MeterRegistry(注册表)。
- 场景 A(首次注册):
- 你传入
obj1。 - 注册表里没有这个名字的指标。
- Micrometer 记录:
"core.size" -> 绑定 obj1。
- 你传入
- 场景 B(再次注册):
- 你传入
obj2(一个新的对象),名字还是"core.size",标签也一样。 - Micrometer 检查注册表:发现
"core.size"已经存在了。 - 动作:直接忽略
obj2,直接返回已存在的 Gauge(它依然绑定着obj1)。
- 你传入
换句话说,第一次传入的runtimeInfo1被绑定后,之后无论你传入runtimeInfo2、3、4,Micrometer都会忽略,只会继续读取runtimeInfo1的字段值 。在之前的文章中,我们提到过如果没有缓存层会出现获取值 NaN 的情况,这正好对应了“即使你传入的是新对象,也会被忽略,仍然使用原始绑定的对象“。这意味着 metric 获取的绑定对象被 GC 回收了,可能就会返回 NaN。
3. 为什么会有 NaN?
如果使用了弱引用或者代码逻辑不当,导致首次绑定的那个对象(obj1)被垃圾回收(GC)了,但 Gauge 还在注册表里。当 Prometheus 来拉取数据时,Gauge 找不到对象,就会返回 NaN(Not a Number)。
第二部分:分析篇——旧代码的“巧合”与隐患
文章中提到的旧代码逻辑如下:
// 旧代码逻辑
private void micrometerMonitor(ThreadPoolRuntimeInfo runtimeInfo) {
// 1. 尝试从缓存获取旧对象
ThreadPoolRuntimeInfo existingRuntimeInfo = cache.get(id);
if (existingRuntimeInfo != null) {
// 2. 如果旧对象存在,把新对象的数据 copy 给旧对象
BeanUtil.copyProperties(runtimeInfo, existingRuntimeInfo);
} else {
cache.put(id, runtimeInfo);
}
// 3. 【关键点】这里每次都传入 runtimeInfo(新对象)去注册
Metrics.gauge("core.size", tags, runtimeInfo, ...);
}1. 为什么它是“对”的?(能跑通的巧合)
星球同学的疑问是:“为什么注册时不传 existingRuntimeInfo 而传 runtimeInfo?”
实际上,代码能跑通是因为一个巧妙的数据流转:
- 第一次执行:
existing为空,runtimeInfo被放入缓存,并被Metrics.gauge绑定。 - 第二次及以后:
Metrics.gauge再次被调用,传入了新的runtimeInfo。- 但是,根据“First Wins”原则,Micrometer 忽略了这个新对象,依然死死抓住第一次绑定的那个对象。
- 由于代码里有一句
BeanUtil.copyProperties(runtimeInfo, existingRuntimeInfo),这行代码把新数据注入到了第一次绑定的那个老对象里。 - 结果:Micrometer 再次读取老对象时,读到了更新后的值。
2. 旧代码的三个问题
虽然能跑,但这种写法语义不清且性能不佳:
- 性能浪费(Performance):
Metrics.gauge方法里有加锁、Map 查找等逻辑。如果不加判断,每次定时任务执行都去调一遍注册方法,虽然大部分时候是“无用功”,但依然消耗 CPU 资源。
- 语义混淆(Ambiguity):
- 阅读代码的人会误以为每次都在绑定新对象,实际上并没有。这违反了“代码即文档”的原则。
- 数据展示不直观(Visualization):
- 旧代码直接返回
getRejectCount()(总拒绝数)。 - 在监控图上,这会是一条斜率向上的直线(例如:昨天 100,今天 200)。
- 运维痛点:我们通常不关心“开机以来拒绝了多少”,我们关心的是“过去 1 分钟拒绝了多少”(突增检测)。旧代码没法直接体现这个“增量”。
- 旧代码直接返回
第三部分:重构篇——优雅的监控实现
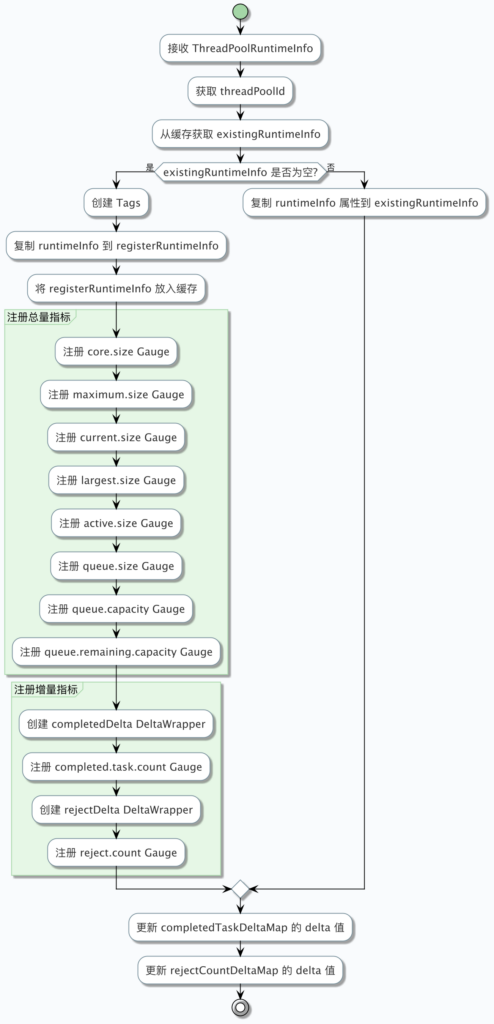
马哥(Martin)的重构代码解决了上述所有问题。我们来看核心优化点:
1. 逻辑分层:注册与更新分离
重构后的代码将流程清晰地分为了两步:
// 伪代码流程
ThreadPoolRuntimeInfo existing = cache.get(id);
if (existing == null) {
// === 分支 A:首次初始化 ===
// 1. 创建一个专属的注册对象(Register Object)
ThreadPoolRuntimeInfo registerInfo = new ThreadPoolRuntimeInfo();
copy(newData, registerInfo);
cache.put(id, registerInfo);
// 2. 注册 Gauge,绑定这个 registerInfo
// 注意:这行代码对于每个线程池只执行一次!
Metrics.gauge(..., registerInfo, ...);
} else {
// === 分支 B:后续更新 ===
// 1. 只做属性拷贝
// 不需要再调 Metrics.gauge,因为引用没变,变的是字段值
copy(newData, existing);
}- 优点:消除了重复调用的性能开销,逻辑清晰,明确告诉读者“注册只发生一次”。
2. 引入 DeltaWrapper(增量包装器)
这是为了解决监控图表“一直涨”的问题。
- 问题:线程池的
rejectCount是一个累计值(LongAdder),只会变大。 - 目标:想看“当前这轮采集周期内(比如 5 秒内)增加了多少”。
- 实现:
// 每次采集时执行 completedTaskDeltaMap.get(id).update(runtimeInfo.getCompletedTaskCount());DeltaWrapper内部逻辑大概是:class DeltaWrapper { long lastValue; // 上次的总量 long delta; // 增量public void update(long currentValue) { this.delta = currentValue - this.lastValue; // 计算差值 this.lastValue = currentValue; // 更新上次的值 } // Gauge 绑定的是这个方法 public double getDelta() { return delta; }} - 效果:现在 Prometheus 采集到的
reject.count不再是 1000, 1005, 1010,而是 0, 5, 5。运维人员可以直接在 Grafana 上看到波峰,一旦有拒绝任务,图表会瞬间跳起来,非常直观。
总结
这篇文章通过一个具体的代码重构案例,教了我们三件事:
- 深度理解工具:Micrometer 的 Gauge 是基于对象引用的,不是基于值的。重复注册同名 Gauge 是无效的。
- 代码整洁之道:不要依赖“副作用”(Side Effect)让代码工作(旧代码依赖 copyProperties 救活了错误的注册逻辑)。明确分离“初始化”和“更新”逻辑。
- 监控的业务价值:监控不仅是把数传上去,还要考虑“怎么看”。对于计数类指标(拒绝数、完成数),增量(Delta)往往比总量更有监控价值。
这篇文章的内容非常干货,指出了实际开发中很容易忽略的细节。为了让你对这个话题的理解更加立体和全面,我再补充 4 个在生产环境中至关重要的“隐藏关卡”。这些内容往往是重构代码上线后,才会被“毒打”出来的经验。
1. Prometheus 的“反直觉”最佳实践:Total vs Delta
文章中提到的一个优化点是:“为了图表直观,手动计算 Delta(增量)传给 Gauge”。
这一点需要辩证地看。虽然这样做在 Java 层面解决了“直观”问题,但从 Prometheus 原生最佳实践的角度来看,这其实是一种反模式(Anti-Pattern)。
- 标准做法:Prometheus 官方建议直接上报累加值(Counter/Total)。
- 为什么?
- Prometheus 的强项在于 PromQL。你只需要上报总量,然后在 Grafana 里使用
rate()或irate()函数(例如rate(reject_count_total[1m])),它能自动计算出“每秒/每分钟的增长速率”。 - 容错性:如果你的 Java 应用重启了,手动计算的 Delta 可能会丢失或异常;而 Prometheus 对 Counter 的重启(重置为0)有专门的数学处理逻辑,不会导致图表断裂。
- Prometheus 的强项在于 PromQL。你只需要上报总量,然后在 Grafana 里使用
补充建议:
- 如果你的后端是 Prometheus:建议保留
reject_count_total(总量)指标,利用 PromQL 绘图。文章中的 Delta 方案更适合那些不支持强大的类似 PromQL 语法的简单监控系统,或者是为了在 Java 内部做某些瞬时报警逻辑。
2. 内存泄漏隐患:动态线程池的“销毁”问题
文章的代码解决了“注册”和“更新”的问题,但没有涉及“销毁”。
场景:
假设你的系统支持动态删除线程池,或者某些临时线程池用完就关闭了。
问题:
- 代码中的
micrometerMonitorCache是一个Map,它强引用了ThreadPoolRuntimeInfo。 - Micrometer 的
MeterRegistry内部也维护了 Gauge 的列表。 - 后果:如果你销毁了线程池,但没有从这两个地方移除,那么:
- 内存泄漏:对象永远无法被 GC。
- 脏数据:Prometheus 依然会拉取到这个已废弃线程池的指标(通常保持在最后一次的值),导致监控误报。
解决方案:
需要在销毁线程池的逻辑中,加入清理代码:
public void removeMonitor(String threadPoolId) {
// 1. 从本地缓存移除
ThreadPoolRuntimeInfo info = micrometerMonitorCache.remove(threadPoolId);
// 2. 【关键】从 Micrometer 注册表中移除 Gauge
// 这需要你在注册时保存 Gauge 的引用,或者通过 search 方法查找并 remove
if (info != null) {
// 伪代码:实际移除逻辑需要通过 MeterRegistry 查找
Tags tags = Tags.of("thread.pool.id", threadPoolId);
meterRegistry.remove(meterRegistry.find("core.size").tags(tags).meter());
// ... 对每个指标都要执行 remove
}
}3. 线程安全与可见性(Visibility)
在重构后的代码中:
// 线程 A (定时任务) 执行:
BeanUtil.copyProperties(runtimeInfo, existingRuntimeInfo);
// 线程 B (Prometheus HTTP 拉取) 执行:
Metrics.gauge(..., existingRuntimeInfo, ThreadPoolRuntimeInfo::getCorePoolSize);潜在风险:
ThreadPoolRuntimeInfo是一个普通的 POJO(普通 Java 对象)。- 如果它的字段(如
corePoolSize)只是普通的int而没有使用volatile关键字。 - 根据 Java 内存模型(JMM),线程 A 的写入,线程 B 不一定能立刻看见(虽然在 X86 架构下通常能看见,但在某些架构或极端高并发下可能有延迟)。
补充建议:
- 虽然监控数据的“最终一致性”通常是可以接受的(晚几秒看到变化没关系),但为了严谨,建议
ThreadPoolRuntimeInfo中的指标字段使用volatile修饰,或者直接使用AtomicLong/AtomicInteger,既保证可见性,又方便做原子更新。
4. Tag Cardinality(标签基数)爆炸
代码中使用了 threadPoolId 作为 Tag:
Tag.of(DYNAMIC_THREAD_POOL_ID_TAG, threadPoolId)严重警告:
- 如果你的
threadPoolId是有限的(比如order-pool,user-pool),这完全没问题。 - 如果你的代码里有逻辑会自动生成随机 ID 的线程池(比如
pool-uuid-1234),或者根据用户 ID 创建线程池。 - 后果:Micrometer 和 Prometheus 会为每一个唯一的 Tag 值创建一个新的 Time Series。如果 ID 是无限增长的,会导致 Prometheus 内存爆炸甚至崩溃。
经验:永远不要把 UUID、用户 ID、请求 ID 这种无限取值的数据放到 Metrics 的 Tag 里。
总结
马哥的这篇文章解决的是“如何正确地在该体系下把值传出去”,而以上补充的四点解决的是“如何在生产环境稳健、长久地运行”:
- 怎么算:优先用 Prometheus 算 Rate,Java 端只传 Total(除非有特殊需求)。
- 怎么删:有注册必须有注销,否则内存泄漏。
- 怎么存:多线程读写 POJO 注意可见性(volatile)。
- 怎么标:Tag 必须是有限集合,拒绝随机字符串。



Comments NOTHING