


虽然现在我们可以通过拒绝策略告警、线程活跃度告警、队列使用率告警 等机制及时发现部分异常,但如果缺乏对线程池运行状态的持续观测与数据分析能力 ,很多问题依然难以深入理解。这些都需要依赖细粒度的指标监控和趋势分析所以我们强调,线程池监控不是只为了报警,它更重要的价值在于:
- 洞察系统瓶颈 :比如是否存在某些任务执行时间异常拉长,影响整体调度效率。
- 辅助定位问题 :出故障时,能看到是线程数打满了,还是队列堆积了;
- 支持容量规划 :通过长期趋势判断线程池配置是否合理;
1. 核心架构分层解析
根据你提供的架构图,我们将代码拆分为三个主要层次:
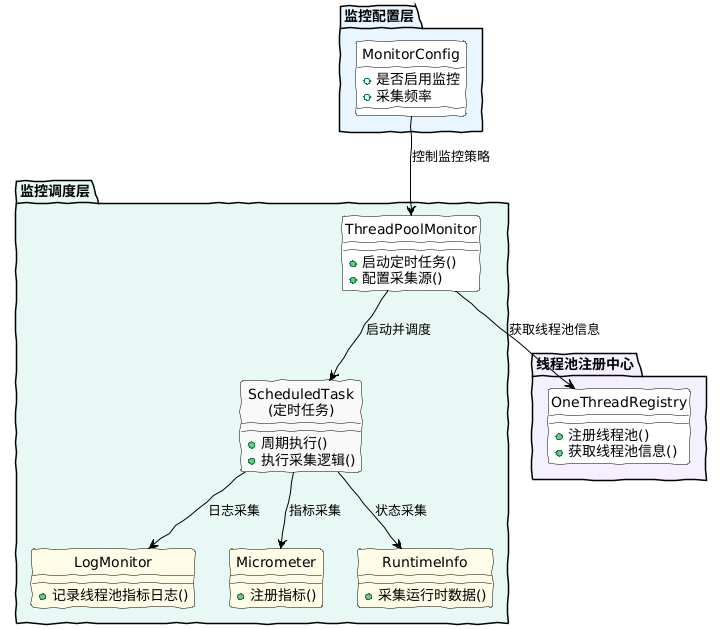
A. 监控配置层 (Configuration Layer)
代码文件:BootstrapConfigProperties.java
作用:控制监控的“开关”和“节奏”。
- 设计思路:
- 开关 (
enable):生产环境如果压力极大,可能需要一键关闭监控,避免额外开销。 - 频率 (
collectInterval):默认 5 秒一次。这个时间是权衡过的——太快(如 1s)会频繁抢占锁,影响业务性能;太慢(如 1min)则捕捉不到瞬时流量洪峰。 - 类型 (
collectType):目前支持log(本地日志),预留了micrometer(Prometheus/Grafana),方便未来扩展。
文件路径: core/src/main/java/com/nageoffer/onethread/core/config/BootstrapConfigProperties.java
package com.nageoffer.onethread.core.config;
import lombok.Data;
/**
* 启动配置属性
*/
@Data
public class BootstrapConfigProperties {
// ... 原有的属性 ...
/**
* 监控配置
*/
private MonitorConfig monitorConfig;
// 单例模式实现(配合代码中的 getInstance 使用)
private static final BootstrapConfigProperties INSTANCE = new BootstrapConfigProperties();
public static BootstrapConfigProperties getInstance() {
return INSTANCE;
}
@Data
public static class MonitorConfig {
/**
* 是否开启监控
*/
private Boolean enable = true;
/**
* 采集类型:log, micrometer
*/
private String collectType = "log";
/**
* 采集间隔(单位:秒)
*/
private Long collectInterval = 5L;
}
}注意:如果你的项目是纯 Spring 环境,通常通过
@ConfigurationProperties注入。但为了适配你提供的ThreadPoolMonitor代码中BootstrapConfigProperties.getInstance()的写法,这里保留了单例访问方式。在 Spring 启动时,你需要确保将配置文件中的值注入到这个单例对象中(可以在ConfigParser或 AutoConfiguration 中处理)。
实现监控核心逻辑 (ThreadPoolMonitor.java);这是核心调度类,负责定时采集数据并输出。
文件路径: core/src/main/java/com/nageoffer/onethread/core/monitor/ThreadPoolMonitor.java
package com.nageoffer.onethread.core.monitor;
import com.alibaba.fastjson2.JSON;
import com.nageoffer.onethread.core.config.BootstrapConfigProperties;
import com.nageoffer.onethread.core.executor.OneThreadExecutor;
import com.nageoffer.onethread.core.executor.OneThreadRegistry;
import com.nageoffer.onethread.core.executor.ThreadPoolExecutorHolder;
import com.nageoffer.onethread.core.toolkit.ThreadFactoryBuilder;
import lombok.SneakyThrows;
import lombok.extern.slf4j.Slf4j;
import java.util.Collection;
import java.util.Map;
import java.util.Objects;
import java.util.concurrent.*;
/**
* 线程池监控执行器
*/
@Slf4j
public class ThreadPoolMonitor {
private ScheduledExecutorService scheduler;
// 预留给 Micrometer 的缓存,暂未使用
private Map<String, ThreadPoolRuntimeInfo> micrometerMonitorCache;
/**
* 启动定时检查任务
*/
public void start() {
BootstrapConfigProperties.MonitorConfig monitorConfig =
BootstrapConfigProperties.getInstance().getMonitorConfig();
// 默认开启,如果配置显式关闭则返回
if (monitorConfig != null && Boolean.FALSE.equals(monitorConfig.getEnable())) {
return;
}
// 防御性编程:如果未配置,给个默认值
long interval = (monitorConfig != null && monitorConfig.getCollectInterval() != null)
? monitorConfig.getCollectInterval() : 5L;
String collectType = (monitorConfig != null && monitorConfig.getCollectType() != null)
? monitorConfig.getCollectType() : "log";
// 初始化监控相关资源
micrometerMonitorCache = new ConcurrentHashMap<>();
scheduler = Executors.newScheduledThreadPool(
1,
ThreadFactoryBuilder.builder()
.prefix("scheduler-thread-pool-monitor")
.daemon(true)
.build()
);
// 每指定时间检查一次,初始延迟0秒
scheduler.scheduleWithFixedDelay(() -> {
try {
Collection<ThreadPoolExecutorHolder> holders = OneThreadRegistry.getAllHolders();
for (ThreadPoolExecutorHolder holder : holders) {
ThreadPoolRuntimeInfo runtimeInfo = buildThreadPoolRuntimeInfo(holder);
// 根据采集类型判断
if (Objects.equals(collectType, "log")) {
logMonitor(runtimeInfo);
} else if (Objects.equals(collectType, "micrometer")) {
micrometerMonitor(runtimeInfo);
}
}
} catch (Exception e) {
log.error("ThreadPool monitor check failed.", e);
}
}, 0, interval, TimeUnit.SECONDS);
}
private void logMonitor(ThreadPoolRuntimeInfo runtimeInfo) {
log.info("[ThreadPool Monitor] {} | Content: {}",
runtimeInfo.getThreadPoolId(),
JSON.toJSONString(runtimeInfo));
}
private void micrometerMonitor(ThreadPoolRuntimeInfo runtimeInfo) {
// TODO: 对接 Micrometer 监控
}
@SneakyThrows
private ThreadPoolRuntimeInfo buildThreadPoolRuntimeInfo(ThreadPoolExecutorHolder holder) {
ThreadPoolExecutor executor = holder.getExecutor();
BlockingQueue<?> queue = executor.getQueue();
long rejectCount = -1L;
// 如果是 OneThreadExecutor 类型,可以获取拒绝次数
if (executor instanceof OneThreadExecutor) {
rejectCount = ((OneThreadExecutor) executor).getRejectCount();
}
int workQueueSize = queue.size();
int remainingCapacity = queue.remainingCapacity();
return ThreadPoolRuntimeInfo.builder()
.threadPoolId(holder.getThreadPoolId())
.corePoolSize(executor.getCorePoolSize())
.maximumPoolSize(executor.getMaximumPoolSize())
.activePoolSize(executor.getActiveCount()) // API 有锁,避免高频率调用
.currentPoolSize(executor.getPoolSize()) // API 有锁,避免高频率调用
.completedTaskCount(executor.getCompletedTaskCount()) // API 有锁,避免高频率调用
.largestPoolSize(executor.getLargestPoolSize()) // API 有锁,避免高频率调用
.workQueueName(queue.getClass().getSimpleName())
.workQueueSize(workQueueSize)
.workQueueRemainingCapacity(remainingCapacity)
.workQueueCapacity(workQueueSize + remainingCapacity)
.rejectedHandlerName(executor.getRejectedExecutionHandler().toString())
.rejectCount(rejectCount)
.build();
}
}修正说明:
getRejectCount(): 请确保OneThreadExecutor类中有此方法。如果是AtomicLong类型,需要调用.get()。ThreadFactoryBuilder: 假设core/toolkit下已有此工具类(目录结构中存在)。
B. 监控调度层 (Scheduling Layer)
代码文件:ThreadPoolMonitor.java
作用:监控系统的“心脏”,负责周期性地驱动采集任务。
- 核心逻辑:
- 使用 JDK 的
ScheduledExecutorService。为什么不用 Spring 的@Scheduled?- 独立性:我们需要一个完全独立、不受业务线程池影响的线程(命名为
scheduler-thread-pool-monitor)。即使业务线程池爆满了,监控线程依然能存活并打印日志,这才是监控存在的意义。
- 独立性:我们需要一个完全独立、不受业务线程池影响的线程(命名为
scheduleWithFixedDelay:使用“固定延迟”而不是“固定频率”。如果某次采集卡住了,下一次采集会顺延,防止任务无限堆积把内存撑爆。
C. 数据采集与适配层 (Collection & Adapter Layer)
代码文件:ThreadPoolMonitor.java (中的 buildThreadPoolRuntimeInfo 方法)
作用:去各个线程池里“抄水表”。
- 对接注册中心:通过
OneThreadRegistry.getAllHolders()获取当前系统中所有被管理的动态线程池。 - 数据标准化:无论底层是 JDK 的
ThreadPoolExecutor还是你自定义的包装类,都统一转换为ThreadPoolRuntimeInfo对象。
定义用于存储和打印的线程池运行时指标模型。
文件路径: core/src/main/java/com/nageoffer/onethread/core/monitor/ThreadPoolRuntimeInfo.java
package com.nageoffer.onethread.core.monitor;
import lombok.Builder;
import lombok.Data;
/**
* 线程池运行时信息实体
*/
@Data
@Builder
public class ThreadPoolRuntimeInfo {
private String threadPoolId; // 线程池唯一标识
private Integer corePoolSize; // 核心线程数
private Integer maximumPoolSize; // 最大线程数
private Integer currentPoolSize; // 当前线程数
private Integer activePoolSize; // 活跃线程数
private Integer largestPoolSize; // 历史最大线程数
private Long completedTaskCount; // 已完成任务数
private String workQueueName; // 队列类型
private Integer workQueueCapacity; // 队列容量
private Integer workQueueSize; // 队列当前大小
private Integer workQueueRemainingCapacity; // 队列剩余容量
private String rejectedHandlerName; // 拒绝策略名称
private Long rejectCount; // 拒绝次数
}需要在 Spring 启动时初始化 ThreadPoolMonitor 并调用其 start() 方法。我们需要修改 spring-base 或 starter 模块下的自动配置类。
文件路径: starter/src/main/java/com/nageoffer/onethread/starter/config/CommonAutoConfiguration.java (或者 spring-base 下的配置类,视你的 Bean 加载逻辑而定)
package com.nageoffer.onethread.starter.config;
import com.nageoffer.onethread.core.monitor.ThreadPoolMonitor;
import org.springframework.boot.autoconfigure.condition.ConditionalOnMissingBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class CommonAutoConfiguration {
// ... 原有的 Bean 定义 ...
@Bean
@ConditionalOnMissingBean
public ThreadPoolMonitor threadPoolMonitor() {
ThreadPoolMonitor monitor = new ThreadPoolMonitor();
// 可以在这里调用 start,或者在 ThreadPoolMonitor 中使用 @PostConstruct
monitor.start();
return monitor;
}
}2. 关键代码细节与性能考量
在实现过程中,有几个细节是严格遵循你提到的“性能优先”原则的:
① 锁的代价 (Lock Awareness)
在代码注释中,我们明确标注了哪些API调用是有锁的,这提醒开发者在设计监控频率时要考虑性能影响:
- 有锁API :
getActiveCount()、getPoolSize()、getCompletedTaskCount()等。 - 无锁API :
getCorePoolSize()、getMaximumPoolSize()等。
在 buildThreadPoolRuntimeInfo 方法中,我特意保留了注释:
// API 有锁,避免高频率调用
.activePoolSize(executor.getActiveCount())
.currentPoolSize(executor.getPoolSize())讲解:
JDK 原生线程池的 getActiveCount() 等方法内部是包含 mainLock 全局锁的。虽然这个锁竞争通常不激烈,但在高并发场景下,如果监控频率过高(比如 100ms 一次),确实会轻微影响业务任务的提交和执行。
优化方案:所以我们将采集间隔默认设为 5 秒,这是一个安全的“甜点区间”。
② 防御性编程
在调度循环中,我添加了 try-catch:
try {
// 采集逻辑
} catch (Exception e) {
log.error("ThreadPool monitor check failed.", e);
}讲解:
这是为了防止某个线程池的状态异常(比如被销毁了但还没注销)抛出异常,导致整个监控定时任务崩溃停止。监控系统必须比业务系统更“坚强”。
③ 拒绝策略的统计
if (executor instanceof OneThreadExecutor) {
rejectCount = ((OneThreadExecutor) executor).getRejectCount();
}讲解:
JDK 原生的线程池是不记录总拒绝次数的。这里利用了 OneThreadExecutor 的扩展能力。拒绝次数是监控中最核心的指标,因为一旦出现拒绝,说明系统容量已经不够了,需要立刻报警或扩容。
监控采集类型的判断逻辑,其实还有优化空间。比如我们现在的两种存储方式,其实可以拆分成两个独立的实现类。这样一来,如果后续框架有计划支持更多存储策略(比如 ElasticSearch 等),就可以引入策略模式 ,实现按需切换,结构更清晰;但如果当前只打算用一种或两种固定方式,那用一个简单工厂模式 来创建也更轻量,足够应对,扩展成本也低。
当前实现方案中,通过配置参数collectType来决定使用哪种监控策略:
- log策略 :将监控信息输出到本地日志
- micrometer策略 :将监控指标发送到Micrometer监控系统
这种设计使得监控方式的选择变得灵活,未来可以轻松扩展其他监控策略
在定时任务设计中,我们采用了以下优化策略:
- 单线程调度器 :使用
newScheduledThreadPool(1)确保监控任务串行执行,避免并发问题。 - 固定延迟调度 :使用
scheduleWithFixedDelay而不是scheduleAtFixedRate,避免任务堆积。 - 可配置间隔 :通过配置文件控制监控频率,平衡监控精度和性能影响。
3. 数据流转过程演示
假设你的应用启动了,整个流程如下:
- 启动阶段:Spring Boot 启动 ->
CommonAutoConfiguration加载 ->ThreadPoolMonitor.start()被调用。 - 初始化:创建一个名为
scheduler-thread-pool-monitor的守护线程。 - 运行阶段(每 5 秒):
- 线程醒来,去
OneThreadRegistry拿名单(比如有一个叫 "order-service-pool" 的线程池)。 - 检查该线程池:
- 核心线程 10,最大 20。
- 当前在干活的线程 18 个(高水位预警!)。
- 队列容量 100,里面已经堆了 80 个任务(阻塞预警!)。
- 打包成
ThreadPoolRuntimeInfo对象。
- 线程醒来,去
- 输出阶段:
- 判断
collectType = log。 - 序列化为 JSON,打印到
logback或log4j文件中。
- 判断
4. 日志长什么样?
最终你在日志文件里看到的一行行数据,就是你排查问题的“黑匣子”:
[ThreadPool Monitor] order-service-pool | Content: {
"activePoolSize": 18,
"corePoolSize": 10,
"maximumPoolSize": 20,
"workQueueSize": 80,
"workQueueCapacity": 100,
"rejectCount": 5,
"threadPoolId": "order-service-pool",
...
}怎么用这个日志?
- 看趋势:如果
activePoolSize长期维持在maximumPoolSize附近,说明需要扩容。 - 查故障:如果接口超时,看同一时间的
workQueueSize是否很高,如果是,说明任务在排队,而不是处理慢。
这套实现方案虽然简单(基于本地日志),但它构建了一个完整的闭环监控体系:
- Registry 提供了数据源。
- Monitor 提供了驱动力。
- Log/JSON 提供了可视化数据。
后续如果需要接入 Prometheus + Grafana,只需要在 ThreadPoolMonitor 的 micrometerMonitor 方法中,把 ThreadPoolRuntimeInfo 的字段塞到 Metrics.gauge 里即可,架构完全不用动。
完成以上步骤后,项目结构变动如下:
- Model:
ThreadPoolRuntimeInfo(新增) - Monitor:
ThreadPoolMonitor(新增) - Config:
BootstrapConfigProperties(修改,增加 MonitorConfig) - AutoConfig: 注册 Bean 并启动。
重新编译并启动应用后,默认情况下(enable=true, type=log),你应该能在控制台看到每隔 5 秒输出的 [ThreadPool Monitor] 日志。
通过Actuator实现动态线程池Metrics监控
这是一个非常系统且专业的监控改造任务。根据你提供的项目结构和前文的设计理念,我们需要将 Micrometer 监控体系融入到现有的 oneThread 框架中。
为了清晰地完成这个任务,我将分 三步(三次回答) 详细讲解:
- 第一部分(本次):依赖分层架构与 Core 核心逻辑实现。
- 第二部分:Starter 自动配置与 Spring Boot Actuator 集成。
- 第三部分:Prometheus 接入实战与 Grafana 面板验证。
第一部分:依赖分层架构与 Core 核心逻辑实现
这部分主要解决框架底层的能力构建,确保 core 模块具备 Micrometer 的抽象能力,而不绑定具体的监控实现(如 Prometheus)。
1. 依赖分层改造 (Maven Dependencies)
根据文章的“依赖体系解析”,我们需要修改 pom.xml 文件。
1.1 修改 core/pom.xmlcore 模块作为框架核心,只引入 micrometer-core,提供监控的抽象层。
<!-- onethread-core/pom.xml -->
<dependencies>
<!-- 其他现有依赖 -->
<!-- Micrometer 核心依赖:提供 Metrics, Gauge 等抽象 API -->
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-core</artifactId>
<version>1.11.0</version> <!-- 建议使用稳定版本,或者由父工程管理 -->
<optional>true</optional> <!-- 设置为可选,不强制下游引入 -->
</dependency>
</dependencies>1.2 修改 starter/pom.xmlstarter 模块负责 Spring Boot 的自动装配,引入 Actuator 以提供基础监控能力。
<!-- onethread-starter/pom.xml -->
<dependencies>
<dependency>
<groupId>com.nageoffer</groupId>
<artifactId>onethread-core</artifactId>
</dependency>
<!-- Spring Boot Actuator:提供 /actuator 端点和指标收集器 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
</dependencies>2. Core 核心监控逻辑实现
核心逻辑位于 core 模块。我们需要改造 ThreadPoolMonitor 类,增加 Micrometer 的指标注册和采集逻辑。
文件路径: core/src/main/java/com/nageoffer/onethread/core/monitor/ThreadPoolMonitor.java
我们需要做以下改动:
- 引入 Micrometer 相关类。
- 增加
micrometerMonitor方法。 - 实现缓存机制(
micrometerMonitorCache)避免重复创建对象。 - 在采集入口调度该方法。
代码实现:
package com.nageoffer.onethread.core.monitor;
import com.nageoffer.onethread.core.config.ApplicationProperties;
import com.nageoffer.onethread.core.executor.ThreadPoolExecutorHolder;
import io.micrometer.core.instrument.Metrics;
import io.micrometer.core.instrument.Tag;
import io.micrometer.core.instrument.Tags;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.BeanUtils; // 或者使用 Hutool 的 BeanUtil
import java.util.Collections;
import java.util.List;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.ScheduledThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
/**
* 线程池监控核心组件
*/
@Slf4j
public class ThreadPoolMonitor {
private final ScheduledExecutorService scheduler;
// 缓存 Map,Key 为 threadPoolId,Value 为运行时信息对象
// 作用:确保 Micrometer 的 Gauge 指标始终引用同一个对象地址
private final Map<String, ThreadPoolRuntimeInfo> micrometerMonitorCache = new ConcurrentHashMap<>();
private static final String METRIC_NAME_PREFIX = "dynamic.thread-pool";
private static final String DYNAMIC_THREAD_POOL_ID_TAG = METRIC_NAME_PREFIX + ".id";
private static final String APPLICATION_NAME_TAG = "application.name";
public ThreadPoolMonitor() {
this.scheduler = new ScheduledThreadPoolExecutor(1, r -> {
Thread t = new Thread(r, "onethread-monitor");
t.setDaemon(true);
return t;
});
}
/**
* 启动监控采集
* @param collectInterval 采集间隔(秒)
* @param collectType 采集类型(log 或 micrometer)
*/
public void start(int collectInterval, String collectType) {
scheduler.scheduleWithFixedDelay(() -> {
try {
// 获取所有受管线程池的运行时信息
List<ThreadPoolRuntimeInfo> runtimeInfos = ThreadPoolExecutorHolder.getThreadPoolRuntimeInfos();
for (ThreadPoolRuntimeInfo runtimeInfo : runtimeInfos) {
if ("micrometer".equalsIgnoreCase(collectType)) {
micrometerMonitor(runtimeInfo);
} else {
// 保留原有的日志监控逻辑
logMonitor(runtimeInfo);
}
}
} catch (Exception e) {
log.error("ThreadPool monitor execution failed.", e);
}
}, 0, collectInterval, TimeUnit.SECONDS);
}
private void logMonitor(ThreadPoolRuntimeInfo runtimeInfo) {
// ... 原有的日志打印逻辑 ...
log.info("ThreadPool Status: [Name: {}, Core: {}, Active: {}]",
runtimeInfo.getThreadPoolId(), runtimeInfo.getCorePoolSize(), runtimeInfo.getActivePoolSize());
}
/**
* Micrometer 监控核心实现
* 实现了 "对象复用" 和 "指标注册"
*/
private void micrometerMonitor(ThreadPoolRuntimeInfo runtimeInfo) {
String threadPoolId = runtimeInfo.getThreadPoolId();
// 1. 缓存处理:确保 Gauge 绑定的对象引用不变
ThreadPoolRuntimeInfo existingRuntimeInfo = micrometerMonitorCache.get(threadPoolId);
if (existingRuntimeInfo != null) {
// 如果缓存存在,将新采集的数据 copy 到旧对象中
BeanUtils.copyProperties(runtimeInfo, existingRuntimeInfo);
} else {
// 如果缓存不存在,放入缓存并进行指标注册
micrometerMonitorCache.put(threadPoolId, runtimeInfo);
existingRuntimeInfo = runtimeInfo; // 用于下方注册
// 2. 只有第一次遇到该线程池时,才进行指标注册 (避免重复注册)
registerMetrics(existingRuntimeInfo);
}
}
/**
* 注册具体的 Gauge 指标
*/
private void registerMetrics(ThreadPoolRuntimeInfo runtimeInfo) {
String threadPoolId = runtimeInfo.getThreadPoolId();
// 构建标签:App Name + ThreadPool ID
// 注意:ApplicationProperties 需要能获取到 spring.application.name
Iterable<Tag> tags = Tags.of(
DYNAMIC_THREAD_POOL_ID_TAG, threadPoolId,
APPLICATION_NAME_TAG, ApplicationProperties.getApplicationName()
);
// 注册核心线程数
Metrics.gauge(metricName("core.size"), tags, runtimeInfo, ThreadPoolRuntimeInfo::getCorePoolSize);
// 注册最大线程数
Metrics.gauge(metricName("maximum.size"), tags, runtimeInfo, ThreadPoolRuntimeInfo::getMaximumPoolSize);
// 注册当前线程数
Metrics.gauge(metricName("current.size"), tags, runtimeInfo, ThreadPoolRuntimeInfo::getCurrentPoolSize);
// 注册活跃线程数 (最关键指标)
Metrics.gauge(metricName("active.size"), tags, runtimeInfo, ThreadPoolRuntimeInfo::getActivePoolSize);
// 注册历史最大线程数
Metrics.gauge(metricName("largest.size"), tags, runtimeInfo, ThreadPoolRuntimeInfo::getLargestPoolSize);
// 队列相关
Metrics.gauge(metricName("queue.size"), tags, runtimeInfo, ThreadPoolRuntimeInfo::getWorkQueueSize);
Metrics.gauge(metricName("queue.capacity"), tags, runtimeInfo, ThreadPoolRuntimeInfo::getWorkQueueCapacity);
Metrics.gauge(metricName("queue.remaining.capacity"), tags, runtimeInfo, ThreadPoolRuntimeInfo::getWorkQueueRemainingCapacity);
// 任务统计
Metrics.gauge(metricName("completed.task.count"), tags, runtimeInfo, ThreadPoolRuntimeInfo::getCompletedTaskCount);
Metrics.gauge(metricName("reject.count"), tags, runtimeInfo, ThreadPoolRuntimeInfo::getRejectCount);
}
private String metricName(String name) {
return String.join(".", METRIC_NAME_PREFIX, name);
}
}micrometer-core (位于 onethread-core 包):
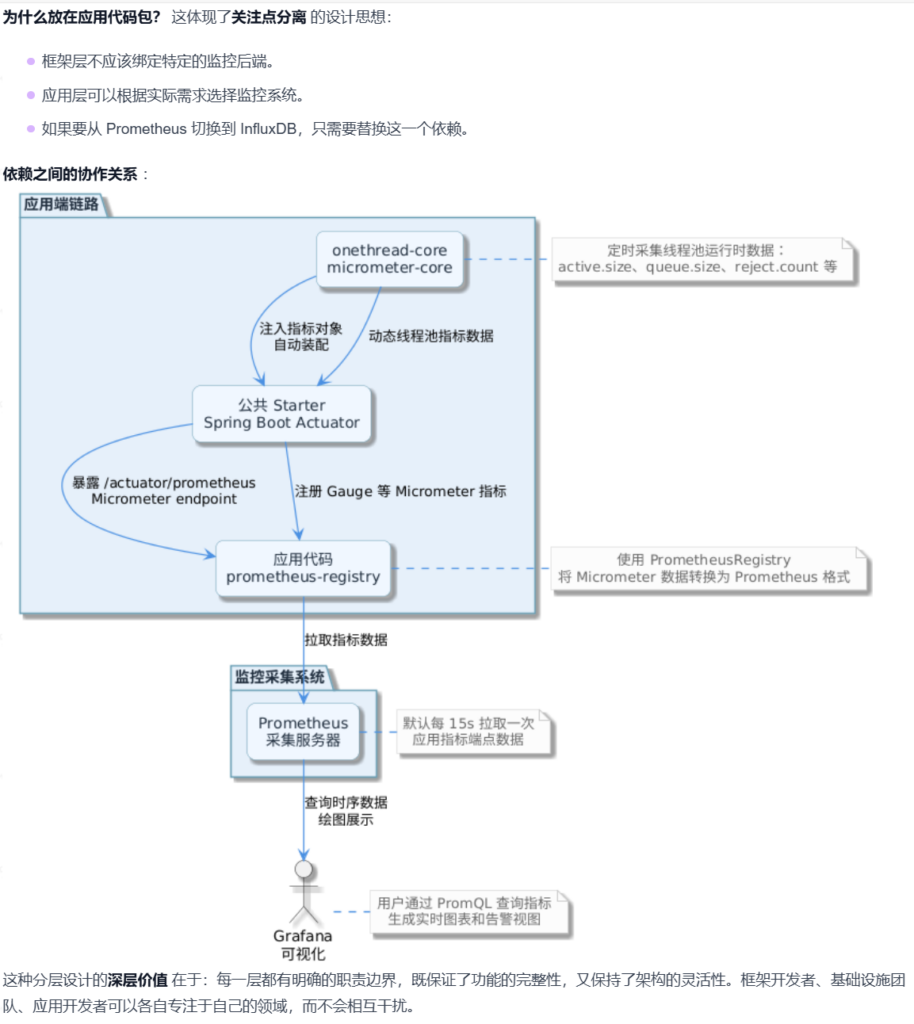
这是整个监控体系的基石 ,提供了 Micrometer 的核心抽象层。它最重要的作用是定义了统一的指标 API,让我们的框架代码不用关心底层到底用的是 Prometheus 还是 InfluxDB。
// 这行代码背后,micrometer-core 做了什么?Metrics.gauge(metricName("core.size"), tags, runtimeInfo,ThreadPoolRuntimeInfo::getCorePoolSize);当我们调用 Metrics.gauge() 时,micrometer-core 会:
- 1.查找可用的MeterRegistry :扫描 classpath 中的 Registry 实现;
- 2.创建Gauge实例 :根据指标名称和标签创建唯一的 Gauge 对象;
- 3.建立对象引用 :将 Gauge 与我们的
runtimeInfo对象绑定; - 4.注册到全局Registry :确保后续可以通过指标名称找到这个 Gauge。
设计考量 :放在 onethread-core 包中,意味着框架的监控能力是"内置"的,不需要额外的配置就能工作。但这里有个巧妙的设计:如果 classpath 中没有具体的 Registry 实现(比如 prometheus registry),这些指标调用不会报错,而是会被"静默忽略"。
spring-boot-starter-actuator (位于 onethread-common-spring-boot-starter 包):
Actuator 的作用远不止暴露几个 HTTP 端点那么简单,它是 Spring Boot 应用生产就绪 的核心组件。
在监控方面,Actuator 主要做了这几件事:
- 1.自动配置MeterRegistry :根据 classpath 中的依赖自动创建对应的 Registry Bean。
- 2.指标收集器注册 :自动注册 JVM、系统、Web 等各种内置指标收集器。
- 3.端点暴露 :提供
/actuator/metrics、/actuator/prometheus等端点。 - 4.安全控制 :支持对监控端点的访问控制和权限管理。
3. 补充说明与检查点
为了让上述代码正常工作,你需要确保 core 模块中的 ApplicationProperties 能够获取到应用名称。
检查文件: core/src/main/java/com/nageoffer/onethread/core/config/ApplicationProperties.java
如果目前该类是空的或者没有静态方法,需要补充:
package com.nageoffer.onethread.core.config;
/**
* 全局应用属性持有者
*/
public class ApplicationProperties {
}这个 applicationName 的值,我们将在下一部分(Spring 集成)中,通过 Spring 的 Environment 自动注入进去。
第一部分总结:
我们完成了地基的搭建。
- POM 依赖:
core引入了micrometer-core,starter引入了actuator。 - 监控逻辑:在
ThreadPoolMonitor中实现了基于缓存的 Gauge 指标注册逻辑,解决了对象引用变更导致的数据采集失效问题。
下一步(第二部分),我们将讲解如何修改 starter 模块的自动配置,将 Spring 环境中的应用名称注入到 Core,并配置 Actuator 端点。
好的,我们进入 第二部分:Starter 自动配置与 Spring Boot Actuator 集成。
这一部分的重点是将 Core 模块中写好的监控逻辑(ThreadPoolMonitor)与 Spring Boot 的生态环境连接起来。我们需要做三件事:
- 配置映射:让用户能在
application.yml中配置监控参数(开启/关闭、采集类型、间隔)。 - 环境注入:自动获取 Spring 应用名称(
spring.application.name)并注入到 Core 模块。 - Bean 装配:在 Spring 启动时自动初始化监控组件。
1. 扩展配置属性类 (Properties)
首先,我们需要在 Starter 模块中定义监控相关的配置属性。根据前文的设计,配置前缀为 onethread.monitor。
文件路径: starter/src/main/java/com/nageoffer/onethread/starter/config/BootstrapCoreProperties.java
代码修改:
我们在现有的 BootstrapCoreProperties 中增加 Monitor 内部类,或者直接添加字段。为了结构清晰,建议增加内部类结构。
package com.nageoffer.onethread.starter.config;
import lombok.Data;
import org.springframework.boot.context.properties.ConfigurationProperties;
/**
* 框架核心配置类
*/
@Data
@ConfigurationProperties(prefix = "onethread")
public class BootstrapCoreProperties {
// ... 其他已有配置 ...
/**
* 监控相关配置
*/
private Monitor monitor = new Monitor();
@Data
public static class Monitor {
/**
* 是否开启监控
*/
private boolean enable = true;
/**
* 采集类型:log 或 micrometer
*/
private String collectType = "micrometer";
/**
* 采集间隔(秒)
*/
private int collectInterval = 10;
}
}2. 改造自动配置类 (AutoConfiguration)
接下来,修改自动配置类,实例化 ThreadPoolMonitor 并启动它。这里有一个关键点:应用名称的注入。
文件路径: starter/src/main/java/com/nageoffer/onethread/starter/config/DynamicThreadPoolAutoConfiguration.java
代码修改:
package com.nageoffer.onethread.starter.config;
import com.nageoffer.onethread.core.config.ApplicationProperties;
import com.nageoffer.onethread.core.monitor.ThreadPoolMonitor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.boot.autoconfigure.condition.ConditionalOnProperty;
import org.springframework.boot.context.properties.EnableConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.env.Environment;
import org.springframework.util.StringUtils;
/**
* 动态线程池自动配置类
*/
@Slf4j
@Configuration
@EnableConfigurationProperties(BootstrapCoreProperties.class)
public class DynamicThreadPoolAutoConfiguration {
// ... 其他 Bean 定义 (如 ConfigParser 等) ...
/**
* 注册监控组件
* 仅当 onethread.monitor.enable = true (或不填默认 true) 时加载
*/
@Bean
@ConditionalOnProperty(prefix = "onethread.monitor", name = "enable", havingValue = "true", matchIfMissing = true)
public ThreadPoolMonitor threadPoolMonitor(Environment environment, BootstrapCoreProperties properties) {
// 1. 获取 Spring 应用名称
String appName = environment.getProperty("spring.application.name", "default-application");
// 2. 注入到 Core 模块的全局配置中
// 这样 Core 模块在打 Tag 时就能获取到 application.name
ApplicationProperties.setApplicationName(appName);
// 3. 创建监控组件
ThreadPoolMonitor monitor = new ThreadPoolMonitor();
// 4. 根据配置启动监控 (micrometer 或 log)
BootstrapCoreProperties.Monitor monitorConfig = properties.getMonitor();
monitor.start(
monitorConfig.getCollectInterval(),
monitorConfig.getCollectType()
);
log.info("OneThread Monitor initialized. Type: {}, Interval: {}s",
monitorConfig.getCollectType(), monitorConfig.getCollectInterval());
return monitor;
}
}3. 理解 Starter 的职责边界
到目前为止,Starter 模块已经完成了它的使命。这里有一个非常重要的设计细节需要回顾:
Starter 引入了什么?
在 Part 1 中,我们在 starter/pom.xml 中引入了 spring-boot-starter-actuator。
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>Starter 没有引入什么?
Starter 没有 引入 micrometer-registry-prometheus。
为什么?
这是为了保持框架的中立性。
ThreadPoolMonitor(在 Core 中) 通过micrometer-core的 API 注册指标(Metrics.gauge)。Metrics.globalRegistry是一个组合注册表。- 如果用户在应用层(如
example模块)引入了 Prometheus,Micrometer 会自动发现并将指标输出为 Prometheus 格式。 - 如果用户引入的是 InfluxDB,就会输出为 InfluxDB 格式。
- 如果用户什么都没引,Actuator 依然能工作,但不会有特定的后端存储格式,只会显示在
/actuator/metrics接口中。
这种设计让 oneThread 框架可以灵活适应各种监控环境。
spring-boot-starter-actuator (位于 onethread-common-spring-boot-starter 包):
Actuator 的作用远不止暴露几个 HTTP 端点那么简单,它是 Spring Boot 应用生产就绪 的核心组件。
在监控方面,Actuator 主要做了这几件事:
- 1.自动配置MeterRegistry :根据 classpath 中的依赖自动创建对应的 Registry Bean。
- 2.指标收集器注册 :自动注册 JVM、系统、Web 等各种内置指标收集器。
- 3.端点暴露 :提供
/actuator/metrics、/actuator/prometheus等端点。 - 4.安全控制 :支持对监控端点的访问控制和权限管理。
// Actuator 自动配置的核心逻辑(简化版)@ConditionalOnClass(PrometheusMeterRegistry.class)@AutoConfigurationpublicclassPrometheusMetricsExportAutoConfiguration{@Bean@ConditionalOnMissingBeanpublicPrometheusMeterRegistryprometheusMeterRegistry(){returnnewPrometheusMeterRegistry(PrometheusConfig.DEFAULT);}}为什么放在公共starter包? 因为 Actuator 提供的是基础监控能力 ,比如动态线程池监控指标、JVM 内存使用、GC 情况、HTTP 请求统计等,这些是 Apollo、Nacos 组件包都需要的。把它放在公共包中,意味着所有使用 oneThread 的应用都会自动获得这些基础监控能力。
micrometer-registry-prometheus (位于 onethread-nacos-cloud-example 包):
这个依赖是监控后端的具体实现 ,它的作用是将 Micrometer 的通用指标格式转换为 Prometheus 特有的格式。
深入来看,这个 Registry 做了以下几件事:
- 1.格式转换 :将 Micrometer 的 Gauge、Counter 等转换为 Prometheus 的 metric 格式;
- 2.标签处理 :处理标签的命名规范(比如将
.转换为_); - 3.数据暴露 :通过
/actuator/prometheus端点以 Prometheus 格式暴露指标数据; - 4.采集优化 :支持 Prometheus 的 scrape 机制,优化数据采集性能。
第二部分总结
我们在这一步完成了框架与 Spring Boot 的“握手”:
- 配置:用户可以通过
onethread.monitor.collect-type=micrometer来开启 Micrometer 模式。 - 注入:利用
Environment将spring.application.name传递给了底层。 - 启动:
ThreadPoolMonitor在 Spring 容器启动时被正确初始化和运行。
下一步(第三部分):
我们将进入 Prometheus 接入实战。这一步是在具体的应用模块(如 example 或 spring-base)中进行的。我们将:
- 引入
micrometer-registry-prometheus依赖。 - 配置
application.yml暴露 Actuator 端点。 - 演示如何验证 Prometheus 数据格式。
- (可选)简述 Grafana 的配置思路。
好的,我们进入 第三部分:Prometheus 接入实战与验证。
这一部分是“临门一脚”,我们将以项目中的 example 模块为例,模拟真实业务应用如何接入 oneThread 的监控体系,并最终看到 Prometheus 格式的数据。
1. 引入 Prometheus 适配器依赖
在具体应用模块(这里是 example 模块)中,我们需要明确告诉 Micrometer:“请把指标数据转换成 Prometheus 能看懂的格式”。
文件路径: example/pom.xml
代码修改:
<dependencies>
<!-- 引入 oneThread starter (前面步骤已完成) -->
<dependency>
<groupId>com.nageoffer</groupId>
<artifactId>onethread-starter</artifactId>
<version>${project.version}</version>
</dependency>
<!-- 核心步骤:引入 Prometheus 注册表实现 -->
<!-- 这会让 Actuator 自动配置 PrometheusMeterRegistry -->
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-registry-prometheus</artifactId>
</dependency>
<!-- Spring Web (Actuator 暴露端点需要 Web 环境) -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
</dependencies>2. 配置 Actuator 端点暴露
默认情况下,Spring Boot Actuator 只暴露 /health 端点。我们需要修改配置文件,允许外部访问 Prometheus 数据端点。
文件路径: example/src/main/resources/application.yml
配置内容:
spring:
application:
name: onethread-example-app # 这个名字会被自动打到标签 application.name 上
server:
port: 8080
# oneThread 框架配置
onethread:
monitor:
enable: true # 开启监控
collect-type: micrometer # 指定使用 Micrometer 模式
collect-interval: 5 # 为了测试方便,间隔设短一点,比如 5秒
# Actuator 端点配置
management:
endpoints:
web:
exposure:
include: "*" # 生产环境建议只开启 "prometheus,health,metrics"
metrics:
tags:
application: ${spring.application.name} # 额外保障:为所有通用指标加应用标签
export:
prometheus:
enabled: truePrometheus 和 Grafana 也有类似的告警机制,基于 Micrometer 指标,可以设计以下告警规则:
线程池活跃度告警 :
# 活跃线程数超过最大线程数的 80%
(dynamic_thread_pool_active_size / dynamic_thread_pool_maximum_size) > 0.8队列堆积告警 :
# 队列使用率超过 70%
(dynamic_thread_pool_queue_size / dynamic_thread_pool_queue_capacity) > 0.7拒绝策略触发告警 :
# 5 分钟内拒绝次数增长超过 10 次
increase(dynamic_thread_pool_reject_count[5m]) > 10结合当前先有告警能力,在 oneThread 中可以定义基础告警指标,其他个性化或者临时告警指标可以在监控中间件中配置。
3. 启动验证与数据核对
现在,启动 example 模块的主程序。
验证步骤:
- 访问 Prometheus 端点:
打开浏览器或使用终端访问:http://localhost:8080/actuator/prometheus - 搜索关键字:
在返回的茫茫多文本中,搜索dynamic_thread_pool(注意:Micrometer 会自动把我们代码里的.转换为_以符合 Prometheus 规范)。
预期结果:
你应该能看到类似下面的输出:
# HELP dynamic_thread_pool_core_size
# TYPE dynamic_thread_pool_core_size gauge
dynamic_thread_pool_core_size{application_name="onethread-example-app",dynamic_thread_pool_id="message-consume-executor",} 4.0
# HELP dynamic_thread_pool_active_size
# TYPE dynamic_thread_pool_active_size gauge
dynamic_thread_pool_active_size{application_name="onethread-example-app",dynamic_thread_pool_id="message-consume-executor",} 0.0
# HELP dynamic_thread_pool_queue_size
# TYPE dynamic_thread_pool_queue_size gauge
dynamic_thread_pool_queue_size{application_name="onethread-example-app",dynamic_thread_pool_id="message-consume-executor",} 0.0原理解析:
- 名称转换:Java 代码中的
dynamic.thread-pool.core.size变成了dynamic_thread_pool_core_size。 - 标签注入:
application_name是我们在 Starter 自动配置中注入进去的,dynamic_thread_pool_id是 Core 模块运行时获取的。 - 数值:后面的
4.0,0.0就是通过Metrics.gauge绑定的实时值。
1. 怎么找?——层次化命名(Naming)
代码: dynamic.thread-pool + name
- 痛点:如果你的指标叫 active_count,那么数据库连接池有这个指标,Tomcat 线程池有,你的业务线程池也有。在 Grafana 里一搜,全乱套了。
- 通透理解:
- 这就像给指标加了个**“姓氏”**。
- dynamic.thread-pool 是姓,core.size 是名。
- 好处:你在 Grafana 搜索栏输入 dynamic.thread-pool,所有相关的监控项(核心线程数、队列大小、活跃数)瞬间像一个文件夹一样展示在你面前,既不会跟别的组件冲突,又方便一键生成大盘。
2. 怎么看?——Gauge 指标的选择(Type)
选择: Gauge(仪表盘/规) vs. Counter(计数器)
- 痛点:很多初学者分不清什么时候用什么。
- 通透理解:
- Counter 是“里程表”:它只能一直涨,不能跌。比如“处理过的任务总数”,昨天100,今天200,它记录的是累计值。
- Gauge 是“速度表/油表”:它可以涨也可以跌,反映的是当下的状态。
- 为什么选 Gauge?:
- 线程池的场景是:现在有几个线程在干活?现在队列里堆了几个任务?
- 上一秒是 10 个,下一秒可能是 5 个。我们需要的是瞬时快照,而不是累计值。所以必须选 Gauge。
- 机制:Gauge 就像一个“探针”,Prometheus 每隔几秒来问它一下:“现在的数值是多少?”,它就读一下当前的内存值告诉 Prometheus。
3. 怎么细分?——多维度标签(Tags)
核心标签: application.name(哪个应用) + thread-pool.id(哪个池子)
- 痛点:如果只有指标名,你发现 active_count = 100,你慌了。但你不知道是“订单服务”炸了,还是“支付服务”炸了?是“VIP线程池”满了,还是“日志线程池”满了?
- 通透理解:
- 标签就是**“切蛋糕的刀”**。
- 第一刀(应用级):application.name。用于看哪个微服务负载高。
- 第二刀(实例级):thread-pool.id。用于看服务内部具体哪个线程池在忙。
- 实战威力(PromQL):
- 想看整个系统的拥堵情况?
→→忽略 ID,按应用聚合(sum by application)。 - 想定位具体故障点?
→→加上 ID 过滤(id="payment-processor")。
- 想看整个系统的拥堵情况?
- 扩展性:文中提到的 environment(生产/测试)和 cluster(机房)标签,是为了在更大规模架构下,能从上帝视角快速下钻到局部细节。
4. 怎么存?——缓存与引用的艺术(最关键的技术点)
这是文中最硬核的部分,也是最容易出 Bug 的地方。
问题根源:
Micrometer 的 Gauge 注册机制是**“基于引用的”**。
你可以想象 Micrometer 是一个观察者,你给它一个对象(Object A),告诉它:“盯着 A 里的 activeCount 属性看”。
如果不加缓存(错误的写法):
- 你每隔 5 秒采集一次数据。
- 你 new 了一个新的对象 Info_B,里面装着最新的数据。
- 你把 Info_B 扔给 Micrometer。
- 结果:Micrometer 还是死死盯着原来的 Info_A(因为 Gauge 注册后就不换目标了),而 Info_A 早就过时了或者被垃圾回收(GC)了。
- 现象:Prometheus 抓到的数据全是 NaN(Not a Number)或者永远不变化的老数据。
加了缓存的设计(正确的写法):
- Map 缓存:Map<线程池ID, Info对象>。
- 流程:
- 采集数据时,先去 Map 里查:这个线程池以前注册过吗?
- 如果是新客:创建一个 Info 对象,存入 Map,并注册给 Micrometer。
- 如果是老客:不要创建新对象,也不要重新注册! 而是把最新采集到的数值,拷贝(Copy Properties) 到 Map 里那个旧的 Info 对象中。
- 通透理解(黑板擦比喻):
- 没有缓存:你每次都拿一块新黑板写上数字,举给 Micrometer 看。Micrometer 说:“我只认第一块黑板,后面的我不看。”
- 有缓存:你只有一块黑板(挂在 Map 里)。每次数据变了,你拿黑板擦把旧数字擦掉,写上新数字。Micrometer 一直盯着这块黑板,自然就能看到最新的变化。
ConcurrentHashMap 的作用:
虽然目前是单线程采集,但作为底层框架,必须保证线程安全。万一以后变成多线程并行采集多个线程池的数据,用 HashMap 就会导致死循环或数据覆盖,ConcurrentHashMap 是为了兜底安全。
4. Grafana 可视化(加分项)
虽然不需要写代码,但了解如何在 Grafana 中展示是这个功能的最终闭环。
操作流程:
- Prometheus Server:配置
prometheus.yml,添加一个 job 抓取localhost:8080/actuator/prometheus。 - Grafana 数据源:添加 Prometheus 数据源。
- 创建 Dashboard:新建面板,添加 Query。
示例 PromQL (查询语句):
- 查看某线程池活跃度走势:
dynamic_thread_pool_active_size{application_name="onethread-example-app", dynamic_thread_pool_id="message-consume-executor"} - 查看队列堆积情况:
dynamic_thread_pool_queue_size - 计算队列使用率 (百分比):
promql (dynamic_thread_pool_queue_size / dynamic_thread_pool_queue_capacity) * 100
总结
至此,我们将整个 Micrometer 监控体系集成到了 oneThread 框架中:
- Core 层:提供了不依赖具体实现的监控抽象 (
Metrics.gauge) 和缓存机制。 - Starter 层:利用 Spring Boot 机制实现了自动配置、环境参数注入 (
application.name)。 - Example 层:通过引入
micrometer-registry-prometheus实现了“插件式”的监控后端接入。
这种架构设计保证了:
- 如果用户不想用 Prometheus,改用 InfluxDB,只需要在
example/pom.xml换一个依赖,框架核心代码一行不用改。 - 如果用户完全不想要监控,配置
onethread.monitor.enable=false,整个监控线程都不会启动,零开销。
这就是一个生产级开源框架应有的扩展性与健壮性设计。
核心亮点总结 :
- 整套 Micrometer 监控方案的最大价值在于标准化和易用性 。通过统一的指标格式,可以直接对接 Prometheus、Grafana 这些成熟的监控工具,不用自己造轮子。同时通过应用名称和线程池 ID 两个标签维度,既能看整体情况,也能深入到具体线程池的细节。
- 在性能方面,通过缓存机制和 Micrometer 自身的优化特性,确保监控本身不会成为系统负担。而且整个设计预留了扩展空间,后续可以根据需要添加更多标签维度。
实践建议 :
- 生产环境建议优先使用 Micrometer 监控,配合 Prometheus + Grafana 的组合,这是目前最成熟的监控方案。开发环境可以同时开启日志监控,方便本地调试。监控频率建议设置为 10-30 秒,既能及时发现问题,又不会对性能造成明显影响。
- 通过 Micrometer 监控,oneThread 框架真正实现了"可观测性"的目标——不仅能看到线程池在做什么,还能分析它做得怎么样,为生产环境的稳定运行提供了保障。



Comments NOTHING