


这是一篇关于 OneThread 动态线程池框架中“告警限流机制” 的深度技术解析。基于你提供的目录结构和文档内容,我将从业务痛点、架构设计、算法实现、并发细节、性能优化、以及设计模式六个维度,为你进行“通透”的拆解。
这不仅仅是对现有代码的解释,更是对中间件开发思维的一次深度复盘。
OneThread 告警限流机制深度解析
第一部分:业务痛点——为什么我们需要“告警限流”?
在分布式高并发系统中,线程池是资源调度的核心。当系统遭遇流量洪峰或依赖服务故障时,线程池往往是第一个“崩溃”或“报警”的组件。
1.1 告警风暴的形成逻辑
假设你的系统有一个核心线程池 OrderProcessPool,参数配置为:核心线程 50,队列 100。
当数据库发生死锁或慢查询时,线程池任务处理变慢,队列迅速堆积。
- 时刻 T1:队列达到 80%,触发“队列堆积告警”。
- 时刻 T1+10ms:又有新请求进来,队列依然 > 80%,再次触发告警。
- 时刻 T1+20ms:触发拒绝策略,触发“拒绝策略告警”。
如果你的 QPS 是 1000,且没有限流机制,那么在 1 分钟内,运维人员的钉钉可能会收到几万条重复的告警信息。
1.2 造成的后果
- 狼来了效应(告警疲劳):运维人员会因为消息太多而选择“屏蔽”或“无视”,导致真正关键的报错(如 OOM 或 机器宕机)被淹没。
- 系统资源雪崩:发送告警本身是需要消耗 CPU、内存和网络 IO 的。在系统已经脆弱的时候,高频构建告警对象、序列化、发起 HTTP 请求,反而可能成为压死系统的最后一根稻草。
- 费用成本:短信、电话等通知渠道通常是按条收费的。
因此,“告警限流”不是锦上添花,而是监控系统的核心保命机制。
oneThread 的设计目标非常明确:在固定的时间窗口内,同一线程池的同一类型故障,只允许发送一次告警。
这需要解决三个核心技术问题:
- 识别:如何唯一标识一类告警?
- 限流:如何高效、线程安全地计算时间窗口?
- 解耦:如何让业务逻辑不被告警逻辑污染?
在 oneThread 的代码结构中,core/src/main/java/com/nageoffer/onethread/core/notification 包下承载了通知模块的核心逻辑。这里采用了经典的 简单工厂模式(Simple Factory Pattern)。
2.1 为什么选择简单工厂?
在通知系统的设计中,我们面临多渠道适配的问题。用户可能配置了钉钉、企微、飞书,甚至自定义的 HTTP 回调。
如果不使用设计模式,代码可能会变成这样:
if ("DING".equals(platform)) {
sendDingTalk(msg);
} else if ("WECHAT".equals(platform)) {
sendWeChat(msg);
} else if ("LARK".equals(platform)) {
sendLark(msg);
}这种代码违反了 开闭原则(Open/Closed Principle):每次新增渠道都要修改核心逻辑,且 if-else 难以维护。
2.2 接口抽象:NotifierService
简单工厂模式 (Simple Factory Pattern)是一种创建型设计模式,它提供了一种创建对象的最佳方式。在简单工厂模式中,我们在创建对象时不会对客户端暴露创建逻辑,而是通过一个共同的接口来指向新创建的对象。
oneThread 定义了顶层接口 NotifierService,它规范了所有通知渠道必须具备的行为:
- sendChangeMessage:配置变更通知。
- sendAlarmMessage:告警通知。
这是一种 策略模式(Strategy Pattern) 的雏形,不同的实现类(如 DingTalkMessageService)封装了不同平台的 API 调用细节(HTTP 请求、JSON 结构、鉴权逻辑)。
2.3 调度核心:NotifierDispatcher
NotifierDispatcher 既是调度器,也扮演了工厂的角色。codeJava
public class NotifierDispatcher implements NotifierService {
private static final Map<String, NotifierService> NOTIFIER_SERVICE_MAP = new HashMap<>();
static {
// 在工厂中注册不同的通知实现
NOTIFIER_SERVICE_MAP.put("DING", new DingTalkMessageService());
// 后续可以轻松扩展其他通知渠道
// NOTIFIER_SERVICE_MAP.put("WECHAT", new WeChatMessageService());
// NOTIFIER_SERVICE_MAP.put("EMAIL", new EmailMessageService());
}
@Override
public void sendChangeMessage(ThreadPoolConfigChangeDTO configChange) {
getNotifierService().ifPresent(service ->
service.sendChangeMessage(configChange));
}
@Override
public void sendWebChangeMessage(WebThreadPoolConfigChangeDTO configChange) {
getNotifierService().ifPresent(service ->
service.sendWebChangeMessage(configChange));
}
@Override
public void sendAlarmMessage(ThreadPoolAlarmNotifyDTO alarm) {
getNotifierService().ifPresent(service -> {
// 在发送告警前进行频率检查
boolean allowSend = AlarmRateLimiter.allowAlarm(
alarm.getThreadPoolId(),
alarm.getAlarmType(),
alarm.getInterval()
);
// 只有通过限流检查才发送告警
if (allowSend) {
service.sendAlarmMessage(alarm);
}
});
}
/**
* 根据配置获取对应的通知服务实现
* 简单工厂模式的核心方法
*/
private Optional<NotifierService> getNotifierService() {
return Optional.ofNullable(BootstrapConfigProperties.getInstance().getNotifyPlatforms())
.map(BootstrapConfigProperties.NotifyPlatformsConfig::getPlatform)
.map(platform -> NOTIFIER_SERVICE_MAP.get(platform));
}
}设计亮点:
- 静态注册:利用 static 代码块在类加载时完成服务注册,避免了每次发送都创建实例的开销。
- 统一入口:上层业务(如 ThreadPoolAlarmChecker)不需要知道具体发送给谁,只需要调用 Dispatcher。
- 装饰器逻辑:Dispatcher 并不仅仅是转发,它还在转发前织入了“限流逻辑”。这是典型的 代理模式(Proxy Pattern) 或 装饰器模式(Decorator Pattern) 的思想——对原有功能进行增强(增加了限流控制),而不改变原有接口。
接下来,我们实现一个通知调度器,作为简单工厂,负责根据配置创建并返回合适的通知服务实例:
public class NotifierDispatcher implements NotifierService {
private static final Map<String, NotifierService> NOTIFIER_SERVICE_MAP = new HashMap<>();
static {
// 在工厂中注册不同的通知实现
NOTIFIER_SERVICE_MAP.put("DING", new DingTalkMessageService());
// 后续可以轻松扩展其他通知渠道
// NOTIFIER_SERVICE_MAP.put("WECHAT", new WeChatMessageService());
// NOTIFIER_SERVICE_MAP.put("EMAIL", new EmailMessageService());
}
@Override
public void sendChangeMessage(ThreadPoolConfigChangeDTO configChange) {
getNotifierService().ifPresent(service ->
service.sendChangeMessage(configChange));
}
@Override
public void sendWebChangeMessage(WebThreadPoolConfigChangeDTO configChange) {
getNotifierService().ifPresent(service ->
service.sendWebChangeMessage(configChange));
}
@Override
public void sendAlarmMessage(ThreadPoolAlarmNotifyDTO alarm) {
getNotifierService().ifPresent(service -> {
// 在发送告警前进行频率检查
boolean allowSend = AlarmRateLimiter.allowAlarm(
alarm.getThreadPoolId(),
alarm.getAlarmType(),
alarm.getInterval()
);
// 只有通过限流检查才发送告警
if (allowSend) {
service.sendAlarmMessage(alarm);
}
});
}
/**
* 根据配置获取对应的通知服务实现
* 简单工厂模式的核心方法
*/
private Optional<NotifierService> getNotifierService() {
return Optional.ofNullable(BootstrapConfigProperties.getInstance().getNotifyPlatforms())
.map(BootstrapConfigProperties.NotifyPlatformsConfig::getPlatform)
.map(platform -> NOTIFIER_SERVICE_MAP.get(platform));
}
}第二部分:核心算法——固定时间窗口限流的设计与取舍
OneThread 选择了固定时间窗口算法(Fixed Time Window)。在分布式限流中,常见的还有滑动窗口、令牌桶、漏桶算法。为什么这里选最简单的?
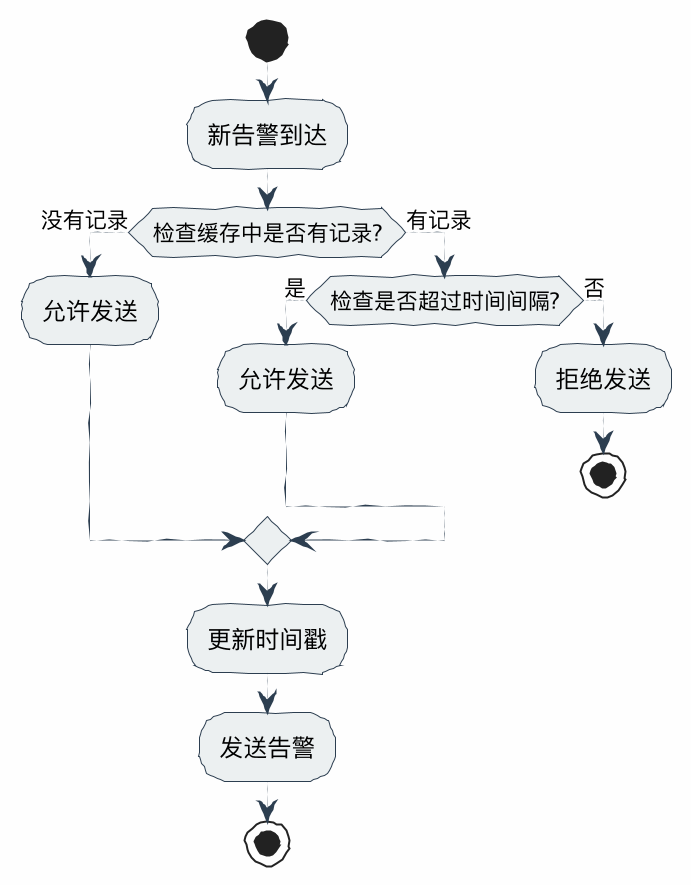
2.1 算法选型逻辑
- 令牌桶/漏桶:主要用于流量整形(让请求平滑处理),对于“告警”这种低频突发场景,不需要平滑,只需要“去重”。
- 滑动窗口:精度高,但实现复杂,需要存储多个时间格,内存占用略高。
- 固定窗口:逻辑最简单,内存占用最小(KV结构)。
OneThread 的策略:在 Interval(例如 5 分钟)内,同一个线程池的同一种告警,只发一次。为每个"线程池ID + 告警类型"的组合维护一个时间戳记录;当新告警到达时,检查距离上次发送是否超过配置的时间间隔;如果超过间隔时间,允许发送并更新时间戳;否则拒绝发送
2.2 数据结构设计
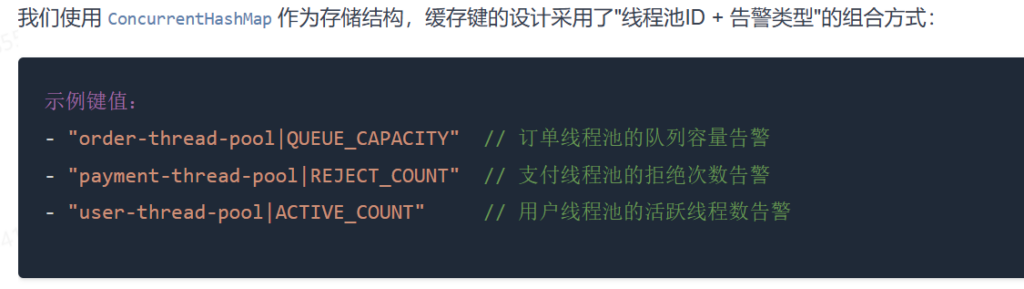
系统维护了一个全局的静态缓存:
// Key: 唯一标识(线程池ID + 告警类型)
// Value: 上次成功发送告警的时间戳
private static final Map<String, Long> ALARM_RECORD = new ConcurrentHashMap<>();- Key 的设计:
threadPoolId + "|" + alarmType。- 例如:
order-pool|REJECT和order-pool|QUEUE_FULL是两个独立的 Key,互不影响。这意味着“拒绝”和“堆积”可以同时发生并分别报警,符合业务直觉。
- 例如:
- Value 的设计:存储
LastTime,用于与CurrentTime对比。
第三部分:并发编程深度解析——ConcurrentHashMap 的原子性妙用
这部分代码看似简单,实则包含了高并发编程的精髓。请看这段核心代码:
public static boolean allowAlarm(String threadPoolId, String alarmType, int intervalMinutes) {
String key = buildKey(threadPoolId, alarmType);
long currentTime = System.currentTimeMillis();
long intervalMillis = intervalMinutes * 60 * 1000L;
// 核心并发逻辑
return ALARM_RECORD.compute(key, (k, lastTime) -> {
// 1. 如果没有记录 (首次告警) -> 允许发送,更新时间
// 2. 如果当前时间 - 上次时间 > 间隔 (过期) -> 允许发送,更新时间
if (lastTime == null || (currentTime - lastTime) > intervalMillis) {
return currentTime;
}
// 3. 否则 (还在冷却期内) -> 不更新,返回旧时间
return lastTime;
}) == currentTime; // 判断返回值是否被更新为当前时间
}3.1 为什么不用 get() 然后 put()?
如果你写成这样,就是线程不安全的:
// 错误示范
Long lastTime = map.get(key);
if (System.currentTimeMillis() - lastTime > interval) {
map.put(key, System.currentTimeMillis()); // 多线程下,这里可能被执行多次
return true;
}在高并发下,两个线程可能同时读到旧的 lastTime,同时判断过期,同时写入新时间,导致短时间内发出两条告警。获取当前时间 long currentTime = System.currentTimeMillis();计算时间间隔,将分钟转换为毫秒 intervalMinutes * 60 * 1000L;
如果缓存中没有记录(lastTime == null),说明是首次告警,允许发送;如果距离上次告警时间超过间隔(currentTime - lastTime > intervalMillis),允许发送;否则,保持原有时间戳,拒绝发送。通过比较 compute 方法的返回值与当前时间来判断是否允许发送。
3.2 compute 方法的原子性保证
ConcurrentHashMap.compute(key, remappingFunction) 是 JDK 1.8 提供的一个原子操作。
- 它利用了
ConcurrentHashMap内部的分段锁(Node 粒度的synchronized或 CAS)。 - 在
remappingFunction执行期间,其他线程针对同一个 Key 的修改会被阻塞。 - 这保证了:在同一纳秒内,无论有多少个线程触发同一个告警,只有一个线程能进入 Lambda 表达式并成功更新时间戳。
3.3 返回值判断技巧
代码最后通过 == currentTime 来判断是否拿到了“发送权”。
- 如果 Lambda 返回了
currentTime,说明更新成功,允许发送。 - 如果 Lambda 返回了
lastTime,说明未更新,lastTime != currentTime,拒绝发送。
第四部分:性能优化——Supplier 函数式接口与延迟加载
这是 OneThread 框架中非常亮眼的一个设计细节,体现了作者对JDK 源码的深刻理解。
4.1 痛点:线程池监控的性能开销
获取线程池的状态并不是“免费”的。以 JDK 标准的 ThreadPoolExecutor 为例:
- executor.getActiveCount():在 ThreadPoolExecutor 源码中,通常需要获取 mainLock 全局锁或者遍历 Worker 集合(取决于 JDK 版本和具体实现),虽然开销不大,但在高频告警检测下,频繁获取这些锁会影响线程池本身的任务处理性能。
- InetAddress.getLocalHost():获取本机 IP,可能涉及 DNS 解析,极其耗时。
如果我们在“限流检查”之前就组装好所有的告警信息,会发生什么?
- 告警触发。
- 获取锁,计算线程池各项指标(耗时、耗CPU)。
- 进入
allowAlarm检查。 - 发现 1 秒前刚报过警 -> 拦截,丢弃数据。
问题: 如果限流器决定不发送告警(因为还在冷却期),那么我们提前计算好的这些 IP 地址、线程数、队列长度,岂不是白白浪费了 CPU 资源?
4.2 解决方案:Supplier 延迟加载
OneThread 引入了 JDK 8 的 Supplier<T> 接口,实现了Lazy Load(懒加载)。
// 1. 构建对象时,只填充 ID 等轻量数据
ThreadPoolAlarmNotifyDTO alarm = ThreadPoolAlarmNotifyDTO.builder()
.threadPoolId(threadPoolId)
.build();
// 2. 将昂贵的计算逻辑封装在 Supplier 中,此时并不会执行!
alarm.setSupplier(() -> {
// 这里面包含获取 ActiveCount、QueueSize 等昂贵操作
ThreadPoolExecutor executor = holder.getExecutor();
return alarm.setCorePoolSize(executor.getCorePoolSize())
.setActivePoolSize(executor.getActiveCount()); // 昂贵
});
// 3. 传递给 Dispatcher
notifierDispatcher.sendAlarmMessage(alarm);在 NotifierDispatcher 内部:
// 4. 先做限流检查(极快,纯内存计算)
boolean allowSend = AlarmRateLimiter.allowAlarm(...);
if (allowSend) {
// 5. 只有获得了发送令牌,才调用 .resolve() 触发 Supplier.get()
// 此时才真正去获取线程池指标
service.sendAlarmMessage(alarm.resolve());
}收益:在告警被限流拦截的 99% 的时间里,系统完全没有去读取线程池状态的开销,极大降低了监控本身对业务的影响。
4.3 序列化的大坑:transient
在 ThreadPoolAlarmNotifyDTO 中,你看到了:
@ToString.Exclude
private transient Supplier<ThreadPoolAlarmNotifyDTO> supplier;transient:必不可少。因为这个 DTO 可能会被序列化(比如通过 RPC 发送,或者转 JSON 存日志)。Supplier是一个 Lambda 表达式,本质是代码逻辑,无法被序列化。如果不加这个关键字,序列化时会直接报错。@ToString.Exclude:防止打印日志时调用toString()意外触发了Supplier.get(),导致在打印日志时发生了昂贵的计算,破坏了懒加载的初衷。
第五部分:钉钉消息发送实战
5.1 简单工厂模式(Simple Factory)
框架需要支持钉钉、企业微信、邮件等多种渠道。NotifierDispatcher 充当了工厂的角色:
// Map 注册表
private static final Map<String, NotifierService> NOTIFIER_SERVICE_MAP = new HashMap<>();
static {
NOTIFIER_SERVICE_MAP.put("DING", new DingTalkMessageService());
NOTIFIER_SERVICE_MAP.put("WECHAT", new WeChatMessageService());
}- 开闭原则(Open/Closed Principle):虽然简单工厂在新增类型时需要修改工厂类(注册 Map),但对于调用方(Client)来说是封闭的。
- 配置驱动:通过读取
application.properties中的配置来动态决定从 Map 中获取哪个 Service。
5.2 职责链的隐喻
这里的调用链非常清晰:
- Checker:负责发现问题(是拒绝了?还是堆积了?)。它是医生,负责诊断。
- Dispatcher:负责控制频率和分发。它是护士台,负责拦截无效呼叫,并将任务分配给具体的科室。
- Service:负责具体执行(发钉钉 HTTP 请求)。它是具体的治疗手段。
这种分层设计使得代码维护性极高。比如你要修改钉钉的消息格式,只需要动 DingTalkMessageService,完全不会影响限流逻辑。
Supplier 函数只有在调用 .get() 时才会真正触发,所以运行时会检查频率满足告警标准,然后去调用线程池运行时参数。
第六部分:实战细节与未来演进
6.1 钉钉消息的 Markdown 陷阱
文档中提到了 Markdown 格式在不同端的展示差异。
- 技术点:钉钉机器人 API 的 Markdown 语法是标准 Markdown 的子集。
- 坑:
- 表格在手机端无法渲染。
- 某些颜色标签不支持。
- 换行符
\n在某些情况下会被忽略,需要双换行。
- 代码实现:使用
HttpUtil发送 POST 请求,必须处理try-catch,并记录错误日志。特别注意:告警发送失败不应该抛出异常中断主业务流程,必须静默失败(Log Only)。
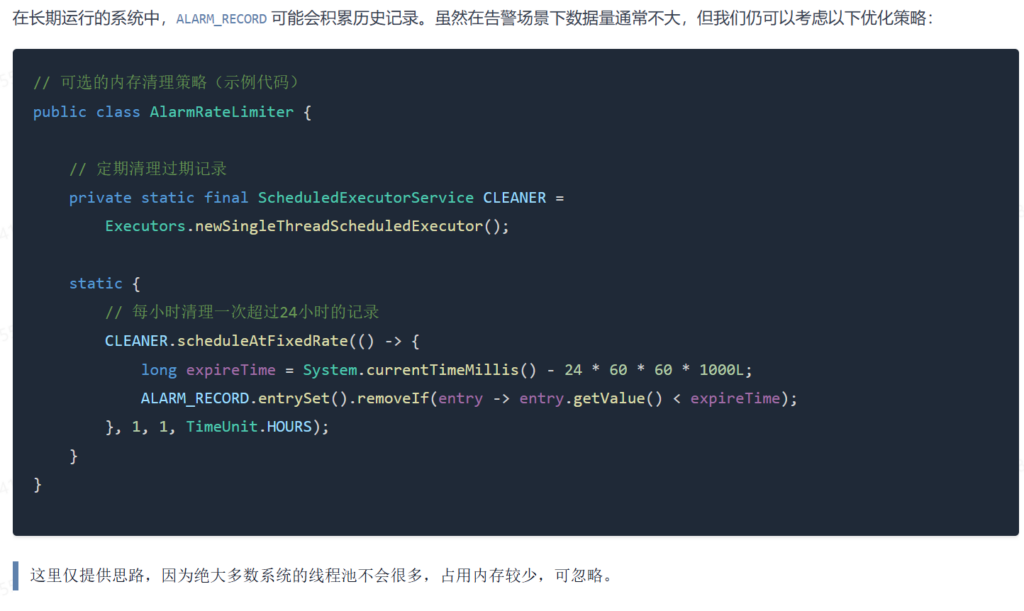
6.2 内存泄露的隐患与对策
代码中定义了 ALARM_RECORD 是一个 static final 的 Map,且没有看到明显的删除逻辑。
- 潜在风险:虽然线程池 ID 数量通常有限,但如果是一个动态创建销毁线程池的场景(例如 Serverless 架构),这个 Map 会无限膨胀,导致内存泄漏(OOM)。
- 解决建议:文档中提到使用
ScheduledExecutorService每小时清理一次过期 Key。ALARM_RECORD.entrySet().removeIf(entry -> entry.getValue() < expireTime);- 这是一个非常实用的补丁,生产环境级代码必须考虑数据的生命周期管理。
6.3 分布式限流的思考
当前的实现是单机限流(Local Rate Limiting)。
- 场景:如果你的服务部署了 100 个实例。
- 问题:当发生全局故障时(如数据库挂了),100 个实例会同时触发告警。虽然每个实例限制 5 分钟 1 次,但运维人员 5 分钟内依然会收到 100 条告警。
- 进阶演进:
- 方案 A:引入 Redis,使用 Redis 的
setNx或incr配合过期时间,实现集群级告警限流。 - 方案 B:告警聚合(Alert Aggregation)。由一个独立的监控中心(如 Prometheus + AlertManager)收集所有实例的 Raw Data,由监控中心统一进行去重、分组、发送。
- 方案 A:引入 Redis,使用 Redis 的
常见问题
3.1 为什么不把告警参数的组装逻辑放到 NotifierDispatcher?
在设计基础组件或中间件时,我倾向于让每一层保持“薄”,并遵循单一职责原则 。NotifierDispatcher 的核心定位是告警派发 ,它只需要负责:
- 告警发送频率控制(如
AlarmRateLimiter); - 将告警路由到具体的
NotifierService实现(如钉钉、邮件、微信等)。
如果把参数组装逻辑下沉到 NotifierDispatcher,会导致:
- 1.职责模糊 :通知层既要处理路由,又要感知线程池细节,破坏了模块解耦;
- 2.扩展成本增大 :未来若增加新的告警类型,通知层需要持续修改,不符合开闭原则。
因此,保持参数组装逻辑在 ThreadPoolAlarmChecker(业务最贴近的地方)更合理,通知层仅做派发即可。
3.2 当前拆分是否合理?
目前的流程是:
Checker (组装 Supplier) -> Dispatcher (限流 + 路由) -> Service (执行 Supplier + 发送)
如果未来增加了新的告警源(例如:Nacos 配置中心变动告警、容器 CPU 告警),现有的 ThreadPoolAlarmChecker 就会变得臃肿。
如果当前系统仅支持三种告警类型 (例如线程池拒绝告警、任务堆积告警、线程数异常告警),这种拆分已经是偏合理的:
- Checker层 :负责业务侧触发和数据组装;
- Dispatcher层 :负责统一告警派发和频率控制。
但如果后续扩展出更多告警类型 ,并且这些告警不是统一通过定时任务触发,而是多点触发(不同模块、不同时机),那么现在的结构就显得不够整洁:
- 告警参数组装会散落在各个告警检查逻辑中;
- 缺乏统一适配,维护成本增大。
解决方案 :可以在 ThreadPoolAlarmChecker 和 NotifierDispatcher 之间增加一层 轻量的告警适配层(AlarmAdapter) :这样,Checker 只负责“发现问题”,Adapter 负责“翻译数据”,Dispatcher 负责“管控流量”。
- Adapter层 :集中完成告警参数的组装与标准化;
- Dispatcher层 :只负责频率控制与路由;
- Checker层 :只负责触发和告警类型判断。
这样既能保持单一职责,又能避免告警参数组装逻辑过于分散。
文章最后留了思考题,关于线程池还有哪些告警维度。这里补充几个深度的指标:
- 任务等待时间(Queue Latency):
- 任务在队列里排队了多久?这直接影响用户体验。如果队列很大但消费很慢,虽然没拒绝,但接口已经超时了。
- 任务执行耗时 TP99:
- 如果线程池活跃度高,是因为任务量大,还是因为单个任务变慢了?这两个原因的优化方向完全不同。
- 线程上下文切换(Context Switches):
- 如果 Core 线程数设置过大,CPU 会花费大量时间在线程切换上,反而降低吞吐量。
- 任务拒绝趋势:
- 不是等到拒绝了才告警,而是检测“队列增长速率”。如果队列以每秒 100 个的速度增长,且剩余容量只有 500,那么 5 秒后必死。提前 5 秒告警价值千金。



Comments NOTHING