


这份文档详细介绍了如何利用 Prometheus 监控系统来采集 oneThread 动态线程池框架的指标数据。为了让你“通透”地理解,我将内容拆解为三个核心部分进行详细讲解:
- 架构与原理:为什么选 Prometheus?它是怎么工作的?
- 实战部署(难点解析):详细拆解那个复杂的 Docker 启动命令。
- 数据查询与价值(PromQL):如何写查询语句来真正通过数据发现问题。
第一部分:架构与原理 —— 从“盲人摸象”到“上帝视角”
1. 为什么要引入 Prometheus?
在没有监控系统之前,运维或开发人员了解系统状态通常是被动的:
- 传统方式:接到用户投诉 -> 登录 Linux 服务器 -> 查日志 (
tail -f) -> 写脚本统计。 - 痛点:这是“事后诸葛亮”,而且无法看到历史趋势(比如:是突然变慢的,还是过去一周都在变慢?)。
Prometheus 的主要特性包括:
- 一个多维数据模型,其中时间序列数据由指标名称和键/值对标识。
- PromQL,一种灵活的查询语言,用于利用这种多维性。
- 不依赖分布式存储;单个服务器节点是自主的。
- 时间序列收集通过 HTTP 上的拉取模型进行。
- 通过中间网关支持推送时间序列。
- 通过服务发现或静态配置发现目标。
- 支持多种图形和仪表盘模式。
Prometheus 的核心价值在于它提供了一个时间序列数据库(TSDB)。它不仅仅记录“现在有多少个线程”,而是记录“过去每一秒有多少个线程”。这让你能看到趋势。.
指标在通俗意义上是数值测量。术语“时间序列”是指随时间记录的变化。用户希望测量的内容因应用程序而异。对于 Web 服务器,可能是请求时间;对于数据库,可能是活动连接数或活动查询数等等。
指标在理解应用程序为何以某种方式工作方面发挥着重要作用。假设您正在运行一个 Web 应用程序并发现它运行缓慢。要了解应用程序发生了什么,您需要一些信息。例如,当请求数量很高时,应用程序可能会变慢。如果您拥有请求计数指标,则可以确定原因并增加服务器数量以处理负载。
Prometheus 生态系统由多个组件组成,其中许多是可选的
- 主 Prometheus 服务器,它抓取并存储时间序列数据。
- 用于对应用程序代码进行埋点的客户端库。
- 一个用于支持短生命周期作业的推送网关。
- 用于 HAProxy、StatsD、Graphite 等服务的专用导出器。
- 一个用于处理告警的告警管理器。
- 各种支持工具。
大多数 Prometheus 组件都是用 Go 编写的,这使得它们易于构建并部署为静态二进制文件。
2. “拉模式”(Pull) vs “推模式”(Push)
文档中特意提到了 Prometheus 采用的是 Pull(拉)模式。这是理解其架构的关键:
- Push(推)模式(如 Cat、Zipkin):应用服务(Client)主动把数据发送给监控服务器。
- 缺点:如果监控服务器挂了,应用发送数据可能会超时或积压,影响业务。对于必须推送的情况,Prometheus 同时也提供了 Pushgateway 组件
- Pull(拉)模式(Prometheus):
- 工作方式:你的应用(
oneThread)只需要开一个 HTTP 接口(例如/actuator/prometheus),静静地把数据展示在那里。Prometheus 服务器像一个“巡检员”,每隔一段时间(例如 15秒)过来访问一下这个接口,把数据抄走。 - 优点:应用完全解耦。就算 Prometheus 挂了,你的应用仅仅是少了一个 HTTP 请求而已,业务完全不受影响。
- 工作方式:你的应用(
3. 核心流程
基于文档中的架构图,数据流向是这样的:
- oneThread App:通过 Micrometer 将线程池内部数据(活跃数、队列大小等)转换为 Prometheus 可读的文本格式。
- Expose(暴露):在
http://localhost:18080/actuator/prometheus暴露数据。 - Scrape(抓取):Prometheus 根据配置文件,每 15 秒访问一次上述 URL,拉取数据。
- Storage(存储):Prometheus 将数据打上时间戳,存入本地数据库。
- Query(查询):用户在 WebUI 或 Grafana 中使用 PromQL 语言查询数据。
第二部分:Docker 实战部署 —— 那个“骚操作”命令解析
文档中提供了一个非常“极客”的 Docker 启动命令,目的是为了不挂载本地文件也能运行自定义配置。很多初学者会被这个长命令吓到,我们来逐行拆解:
注意不要复制空白区域,如有错误可以尝试重新来一遍(见文章末尾处)
docker run -d \
--name prometheus \
-p 9090:9090 \
--entrypoint sh \
-e TZ=Asia/Shanghai \
prom/prometheus:v2.51.1 \
-c 'echo "
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: '\''prometheus'\''
static_configs:
- targets: ['\''localhost:9090'\'']
- job_name: '\''onethread-app'\''
metrics_path: '\''/actuator/prometheus'\''
static_configs:
- targets: ['\''host.docker.internal:18080'\'']
scrape_interval: 10s
scrape_timeout: 5s
" > /etc/prometheus/prometheus.yml && /bin/prometheus --config.file=/etc/prometheus/prometheus.yml'1. 核心命令拆解
docker run -d \
--name prometheus \
-p 9090:9090 \
--entrypoint sh \ # <--- 关键点 1
...
-c 'echo "..." > /etc/prometheus/prometheus.yml && /bin/prometheus ...' # <--- 关键点 2- 常规做法:通常我们需要在宿主机写好
prometheus.yml,然后用-v /my/config:/etc/prometheus/config挂载进去。 - 文档中的做法:
- 关键点 1 (
--entrypoint sh):它告诉 Docker,容器启动时不要直接运行 Prometheus 程序,而是先给我一个 Shell(命令行环境)。 - 关键点 2 (
echo "..." > ...):利用这个 Shell,先用echo命令把配置文件的内容动态写入到容器内的/etc/prometheus/prometheus.yml文件中。 - 最后一步 (
&& /bin/prometheus ...):配置文件写好后,紧接着启动 Prometheus 主程序。
- 关键点 1 (
为什么要这么做?
这种写法非常适合快速演示或测试。你不需要在电脑上创建任何文件,直接复制粘贴这一条命令,Prometheus 就带着配置跑起来了。
2. 网络通信的关键:host.docker.internal
在配置文件中,你看到了这个地址:
targets: ['host.docker.internal:18080']- 问题:Prometheus 跑在 Docker 容器里,你的 Java 应用跑在宿主机(你的电脑)上。容器想访问宿主机,不能用
localhost(因为容器的 localhost 是容器自己)。 - 解决:Docker 提供了一个特殊的 DNS 域名
host.docker.internal。在容器内部访问这个域名,请求就会转发给宿主机的 IP。 - 注意:这个功能在 Docker Desktop (Windows/Mac) 上是默认支持的。在纯 Linux 环境下可能需要额外配置
--add-host,但文档这里的演示环境主要面向开发机的快速验证。
3. 配置文件解读
scrape_configs:
- job_name: 'onethread-app' # 任务名称,作为标签存储
metrics_path: '/actuator/prometheus' # 抓取的路径
static_configs:
- targets: ['host.docker.internal:18080'] # 目标地址
scrape_interval: 10s # 只有这个任务每10秒抓一次(覆盖全局)这告诉 Prometheus:“请每隔 10 秒,去宿主机的 18080 端口,访问 /actuator/prometheus,把拿到的数据都打上 job=onethread-app 的标签存起来。”---
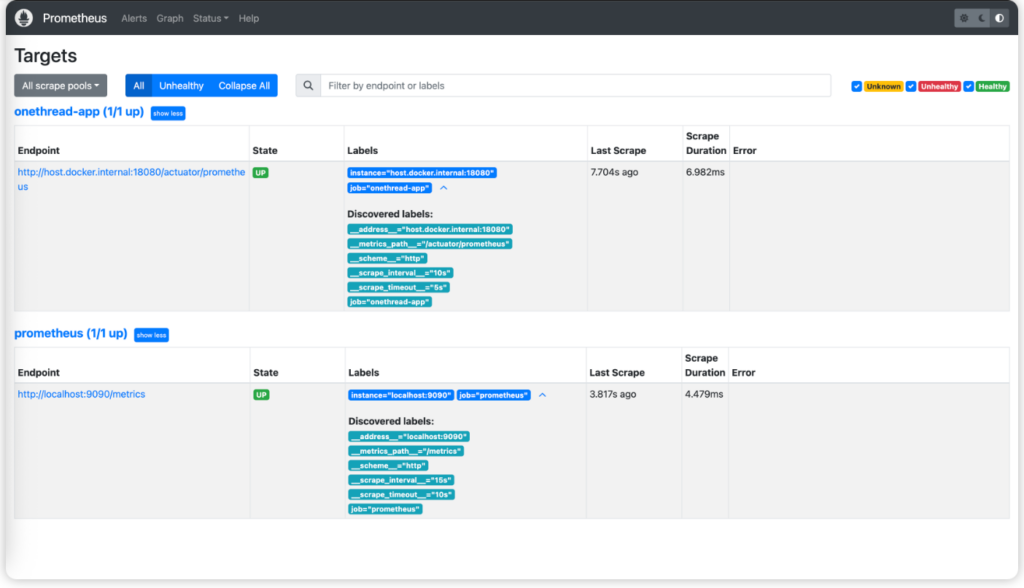
如果想简易实现oneThread动态线程Metric采集,上面这条命令足够了。上述配置文件重写等同于:yamlglobal:scrape_interval:15s#全局采集间隔evaluation_interval:15s#告警规则评估间隔#采集任务配置scrape_configs:#Prometheus自身监控-job_name:'prometheus'static_configs:-targets:['localhost:9090']#oneThread应用监控-job_name:'onethread-app'metrics_path:'/actuator/prometheus'static_configs:-targets:['host.docker.internal:18080','host.docker.internal:18081']#同一任务需要采集多IP,可以逗号分割scrape_interval:10sscrape_timeout:5s因为Docker和宿主机的IP是不一样的,如果在Docker容器中运行Prometheus时, 要访问宿主机的服务或端口*,推荐使用:host.docker.internal。在Linux(Dockerv20.10+)、macOS和Windows中,Docker提供了特殊的主机名,它可以在容器内解析为宿主机的IP。host.docker.internal:18080表示Prometheus容器去访问宿主机18080端口的服务。###2.运行检查浏览器访问http://localhost:9090/targets如果可以出现下述页面,即为运行成功。
如果出现在这种报错怎么办?
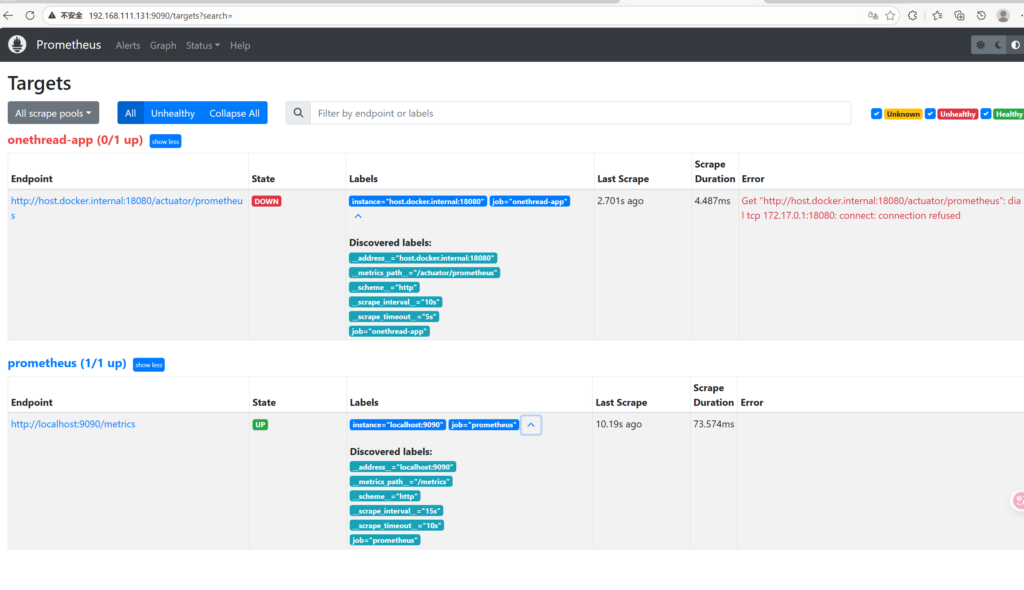
哎哎,idea启动程序即可
可以看到咱们在Prometheus配置文件中加的两个采集任务,都在列表上展示,并且State显示为UP健康状态。>大家记得把onethread-nacos-cloud-example项目运行起来,要不然上面那个任务状态会显示失败。##Prometheus控制台操作指南###1.WebUI界面概览访问http://localhost:9090进入PrometheusWeb控制台,主要包含以下功能模块:** Graph(图表查询)**:
- 功能 :执行 PromQL 查询,查看指标数据和图表。
- 用途 :数据探索、问题排查、趋势分析。
Alerts(告警管理) :
- 功能 :查看当前告警状态和历史记录。
- 用途 :告警监控、规则调试。
Status(状态信息) :
- Targets :查看采集目标状态。
- ServiceDiscovery :查看服务发现状态。
- Configuration :查看当前配置。
- Rules :查看告警规则状态。
第三部分:PromQL 查询与数据价值 —— 让数据说话
Prometheus 的强大之处在于 PromQL (Prometheus Query Language)。文档中列举了很多例子,我们来分析几个最具实战意义的场景。
1. 基础查询与标签过滤
- 查询:
dynamic_thread_pool_active_size - 解释:这会列出所有被监控实例的所有线程池的活跃线程数。
- 过滤:
dynamic_thread_pool_active_size{application_name="order-service"} - 场景:当你有 10 个微服务时,你只想看“订单服务”的线程池状态,就必须用大括号
{}进行标签过滤。
2. 计算使用率(核心监控指标)
仅仅知道“活跃线程数是 50”没有意义,必须知道“最大允许多少”。
- 公式:
promql dynamic_thread_pool_active_size / dynamic_thread_pool_maximum_size * 100 - 价值:这是做告警的最佳指标。
- 如果结果 > 80%,说明线程池快满了,系统可能处理不过来了。
- 如果结果长期 < 10%,说明线程池配置太大,浪费内存。
3. 速率计算(Rate)—— 处理“计数器”
对于“已完成任务数”这种指标,它是一个Counter(只增不减的计数器)。
- 错误查询:
dynamic_thread_pool_completed_task_count- 结果:你只会看到一条斜向上的线(例如:昨天 1万,今天 2万)。这看不出当前系统的负载。
- 正确查询:
promql rate(dynamic_thread_pool_completed_task_count[5m]) - 解释:
rate函数计算的是增长速率(每秒完成了多少个任务)。[5m]表示取过去 5 分钟的平均速率。 - 场景:这就是所谓的 QPS (Queries Per Second) 或 TPS。如果这个曲线突然跌零,说明系统挂了或卡死了。
4. 聚合查询(Aggregation)
当你有 10 个实例(Pod)在运行同一个服务时,你可能不想看 10 条线,只想看总和。
- 公式:
promql sum by (application_name) (dynamic_thread_pool_active_size) - 解释:把所有实例的数据,按
application_name分组后相加。 - 场景:评估整个集群的负载能力。
总结
这篇文章通过一套完整的流程,展示了 oneThread 如何完成“可观测性”闭环:
- 数据源:应用通过 Micrometer 准备好数据。
- 采集:Prometheus 通过 Docker 部署,利用 Pull 模式抓取数据。
- 分析:通过 PromQL 计算活跃度、吞吐量等关键指标。
这一步完成后,你的线程池不再是一个黑盒。下一步(文档预告的 Grafana)就是把这些 PromQL 语句变成漂亮的可视化仪表盘。
这份文档紧接着上一篇 Prometheus 的教程,补全了监控系统的最后一块拼图——可视化(Visualization)。
如果不加这一步,Prometheus 就像是一个深埋在地下的巨大金矿(数据),虽然有价值,但你要想看一眼,还得拿铲子挖(写 PromQL 代码)。而 Grafana 就是把金矿变成了精美的首饰店,让你一眼就能看清数据的价值。
我将从网络架构、部署流程、核心配置、大屏集成四个维度,为你“通透”地讲解这一章的内容。
第一部分:网络架构 —— 容器间的“局域网”
在上一篇中,我们启动了 Prometheus。在这一篇,我们要启动 Grafana。最关键的一点是:Grafana 需要去 Prometheus 那里拉取数据。
这就涉及到了 Docker 容器间的通信问题。
1. 为什么要创建 monitoring 网络?
docker network create monitoring默认情况下,Docker 容器虽然也能通信,但通常需要依赖 IP 地址。容器重启后 IP 可能会变,这很麻烦。
自定义网络(User-defined Bridge Network) 的好处在于:由于 Docker 内置了 DNS 解析,同一网络下的容器,可以直接通过“容器名”互相访问。
2. “老”容器加入新网络
docker network connect monitoring prometheus因为 Prometheus 是上一章启动的,当时可能没指定这个网络。这条命令相当于把正在运行的 Prometheus 容器“拉”到了 monitoring 这个局域网里。
3. 启动 Grafana 并加入网络
docker run -d --name grafana --network monitoring ...这里明确指定了 --network monitoring。
结果:Grafana 和 Prometheus 现在就像住在同一个小区的邻居。Grafana 只要喊一声“prometheus”(容器名),对方就能听到,完全不需要知道对方的 IP 是多少。
第二部分:配置数据源 —— 打通任督二脉
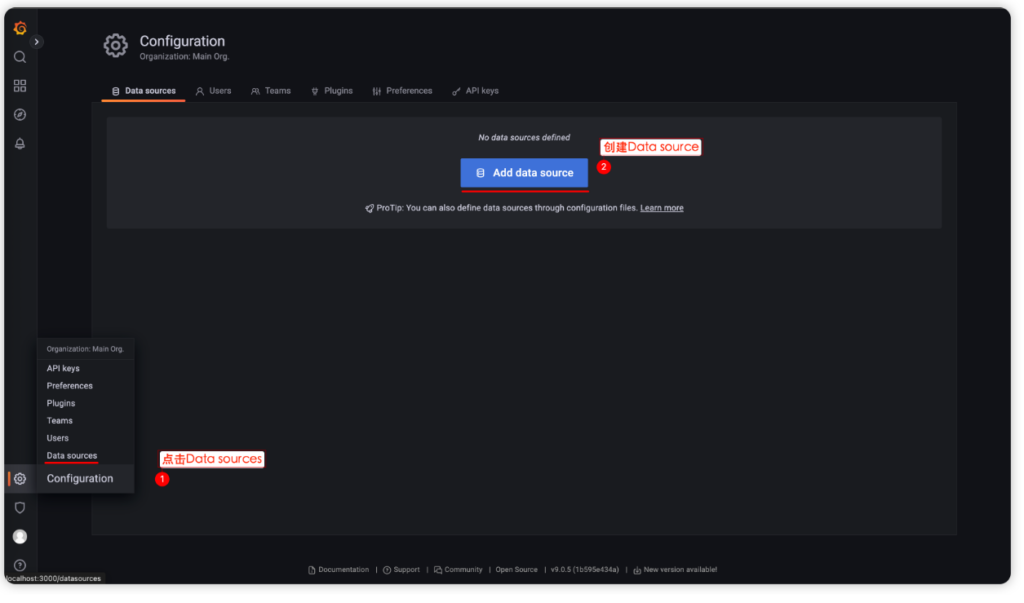
部署好 Grafana 后(访问 localhost:3000),第一件事是告诉它:数据从哪来?
1. 核心配置点:URL
在配置 Prometheus 数据源时,文档强调填写的 URL 是:
http://prometheus:9090
这里有初学者最容易犯的错:
- 错误写法:
http://localhost:9090或http://127.0.0.1:9090。- 为什么错? 因为这个请求是由 Grafana 容器内部 发出的。在 Grafana 容器里,
localhost指的是 Grafana 自己,它里面可没跑 Prometheus。
- 为什么错? 因为这个请求是由 Grafana 容器内部 发出的。在 Grafana 容器里,
- 正确写法:
http://prometheus:9090。- 原理:利用了上面创建的 Docker 网络 DNS 解析。
prometheus这个主机名会自动解析成 Prometheus 容器的内网 IP。
- 原理:利用了上面创建的 Docker 网络 DNS 解析。
第三部分:导入 Dashboard —— 站在巨人的肩膀上
手动一个一个去配图表(Panel)是非常耗时的。oneThread 官方提供了一个 JSON 文件,这相当于是一个模板包。
1. JSON 模板里有什么?
这个 JSON 文件里包含了:
- 布局信息:哪个图在左边,哪个在右边。
- PromQL 语句:上一章咱们学的那些
rate(...)、sum(...)语句,都已经预设在里面了。 - 变量(Variables):
- 文档截图里显示的
application_name和dynamic_thread_pool_id下拉框。 - 这利用了 Grafana 的变量功能,允许你在一套大屏里,通过切换下拉框来查看不同服务、不同线程池的数据,实现了复用。
- 文档截图里显示的
2. 效果解读
导入成功后,你会看到:
- 活跃线程数:实时波动的曲线,展示负载情况。
- 队列积压:如果有波峰,说明处理不过来了。
- IP 分组:如果你部署了集群(比如启动了 3 个服务实例),Grafana 会自动按 IP 分组展示,让你看出是不是某一台机器负载特别高(单点故障)。
第四部分:集成到业务系统 —— 闭环的最后一步
这一步是很多教程里不具备的,是 oneThread 框架的工程化体现。
1. 场景描述
通常,开发人员使用 oneThread 自带的 Admin 管理后台来动态调整线程池参数。如果此时想看监控,还需要单独打开 Grafana 网页,体验是割裂的。
2. 解决方案
在 onethread-dashboard-dev 的配置文件中:
onethread:
grafana:
url: http://grafana.nageoffer.com/d/gxBvKxYNz/...?var-application_name=...&kiosk=trueurl参数:这里填入你部署好的 Grafana 具体 Dashboard 的链接。kiosk=true:这是一个 Grafana 的 URL 参数,意思是以“电视模式/嵌入模式”打开,会隐藏 Grafana 顶部的菜单栏和侧边栏,只留下图表。这非常适合嵌入到其他系统中。- 联动效果:配置好后,你在 oneThread 的管理后台点击“监控”按钮,它会直接通过 iframe 或跳转的方式打开这个链接,并且自动带上参数,直接展示当前线程池的图表。
总结
至此,整个 oneThread 动态线程池框架 的学习之旅就画上了一个完美的句号:
- 核心原理:理解了线程池为什么要动态化(解决硬编码痛点)。
- 数据暴露:通过 Micrometer 将 Java 内部指标转为标准格式。
- 数据采集:使用 Docker 部署 Prometheus 进行“拉模式”存储。
- 数据展示:使用 Docker 部署 Grafana,通过内部网络连接,并利用 JSON 模板实现一键可视化。
(点击查看)有一点东西我愚钝没看出来有什么用?这种东西也有myplus这种沟通用的中间件吗?
Configuration 页面
查看当前配置 :
Status → Configuration 页面显示当前生效的完整配置,包括:
- 全局配置 :采集间隔、评估间隔等。
- 采集任务配置 :所有 scrape_configs 的详细配置。
- 告警规则配置 :rule_files 中定义的规则。
配置热重载 :
# 方法1:发送 HTTP 请求 curl -X POST http://localhost:9090/-/reload # 方法2:发送系统信号 docker exec prometheus kill -HUP 1PromQL 查询语言实践
1. PromQL 基础语法
即时查询 :
# 查询当前时刻的指标值 dynamic_thread_pool_active_size范围查询 :
# 查询过去5分钟的指标值 dynamic_thread_pool_active_size[5m]标签匹配 :
# 精确匹配 dynamic_thread_pool_active_size{job="onethread-app"} # 正则匹配 dynamic_thread_pool_active_size{application_name=~".*example.*"} # 不等匹配 dynamic_thread_pool_active_size{dynamic_thread_pool_id!="onethread-producer"}2. oneThread 指标查询实例
线程池活跃度监控 :
# 查看所有线程池的活跃线程数 dynamic_thread_pool_active_size # 查看特定应用的线程池活跃度 dynamic_thread_pool_active_size{application_name="xxx"} # 计算线程池使用率 dynamic_thread_pool_active_size / dynamic_thread_pool_maximum_size * 100队列状态监控 :
# 查看队列当前长度 dynamic_thread_pool_queue_size # 计算队列使用率 dynamic_thread_pool_queue_size / dynamic_thread_pool_queue_capacity * 100 # 查看队列剩余容量 dynamic_thread_pool_queue_remaining_capacity任务执行统计 :
# 查看已完成任务数 dynamic_thread_pool_completed_task_count # 计算任务完成速率(每秒) rate(dynamic_thread_pool_completed_task_count[5m]) # 查看拒绝任务数 dynamic_thread_pool_reject_count3. 聚合函数应用
按应用聚合 :
# 计算每个应用的总活跃线程数 sum by (application_name) (dynamic_thread_pool_active_size) # 计算每个应用的平均队列长度 avg by (application_name) (dynamic_thread_pool_queue_size) # 查找每个应用中活跃线程数最多的线程池 max by (application_name) (dynamic_thread_pool_active_size)时间窗口聚合 :
# 过去5分钟的平均活跃线程数 avg_over_time(dynamic_thread_pool_active_size[5m]) # 过去1小时的最大队列长度 max_over_time(dynamic_thread_pool_queue_size[1h]) # 过去10分钟的任务完成增长量 increase(dynamic_thread_pool_completed_task_count[10m])4. 复杂查询示例
线程池健康度评估 :
# 线程池压力指数(活跃线程数 + 队列长度) (dynamic_thread_pool_active_size + dynamic_thread_pool_queue_size) / dynamic_thread_pool_maximum_size # 识别高负载线程池(使用率超过80%) dynamic_thread_pool_active_size / dynamic_thread_pool_maximum_size > 0.8 # 检测队列堆积严重的线程池 dynamic_thread_pool_queue_size / dynamic_thread_pool_queue_capacity > 0.7多维度对比查询 :
# 对比不同线程池的性能表现 topk(5, dynamic_thread_pool_active_size) # 查找最繁忙的应用 topk(3, sum by (application_name) (dynamic_thread_pool_active_size)) # 识别异常线程池(活跃线程数突然下降) dynamic_thread_pool_active_size < avg_over_time(dynamic_thread_pool_active_size[1h]) * 0.55. PromQL 查询优化技巧
查询性能优化 :
# 避免:查询大时间范围的原始数据 dynamic_thread_pool_active_size[24h] # 推荐:使用聚合函数减少数据量 avg_over_time(dynamic_thread_pool_active_size[24h])标签选择优化 :
# 避免:使用正则匹配大量标签 {__name__=~"dynamic_thread_pool_.*"} # 推荐:使用精确的标签匹配 dynamic_thread_pool_active_size{application_name="xxx"}
有两点非常重要的生产环境建议需要补充。
目前的教程为了演示方便,使用的是“即用即扔”的 Docker 容器配置。如果你要在生产环境使用,必须注意以下两点,否则可能会丢数据或收不到报警:
1. 数据持久化(必做)
教程中的 Docker 命令没有挂载磁盘卷(Volume)。这意味着,如果你的 Prometheus 或 Grafana 容器被删除或重新创建,所有的监控历史数据、配置的仪表盘账户信息都会丢失。
- Prometheus 改进:需要通过
-v将宿主机的目录挂载到容器内的/prometheus(数据存储目录)。 - Grafana 改进:需要通过
-v将宿主机的目录挂载到容器内的/var/lib/grafana(数据存储目录)。
2. 告警通知(进阶)
目前的配置实现了“我们主动去看监控(Pull/Look)”,但生产环境需要“监控主动告诉我们出问题了(Push/Alert)”。
- Prometheus 生态中有一个组件叫 Alertmanager。
- 你需要配置它,当
dynamic_thread_pool_active_size超过阈值(比如 80%)时,自动发送消息到钉钉、企业微信、飞书或邮件,这样运维人员半夜才能睡得着觉。
docker报错怎么办?
# 1. 先彻底删除失败的容器
docker rm -f prometheus
# 2. 运行清洗后的命令
docker run -d \
--name prometheus \
-p 9090:9090 \
-u root \
--add-host=host.docker.internal:host-gateway \
--entrypoint sh \
-e TZ=Asia/Shanghai \
prom/prometheus:v2.51.1 \
-c 'echo "
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: '\''prometheus'\''
static_configs:
- targets: ['\''localhost:9090'\'']
- job_name: '\''onethread-app'\''
metrics_path: '\''/actuator/prometheus'\''
static_configs:
- targets: ['\''host.docker.internal:18080'\'']
scrape_interval: 10s
scrape_timeout: 5s
" > /etc/prometheus/prometheus.yml && /bin/prometheus --config.file=/etc/prometheus/prometheus.yml'Grafana看板开发
1. 创建 Docker 网络
为了让 Grafana 能够通过容器名访问 Prometheus,我们先创建一个共享网络 monitoring:
docker network create monitoring该网络将作为 Prometheus 与 Grafana 的通信桥梁。
2. Prometheus 加入网络
将已运行的 prometheus 容器连接到 monitoring 网络:
docker network connect monitoring prometheus3. 创建 Grafana
运行以下命令,启动指定版本的 Grafana 并加入同一网络:
docker run -d\--name grafana \--network monitoring \-p3000:3000 \
grafana/grafana:9.0.5访问 http://127.0.0.1:3000 登录 Grafana 控制台,用户名和密码分别是 admin/admin。
HTTP URL 处填写 http://prometheus:9090 即可,通过 Docker 内部网络进行通信,会自动将 prometheus 解析为对应的 IP 地址。

划到最下面,点击 Save % test 按钮,出现上述绿色弹框,即可创建成功。
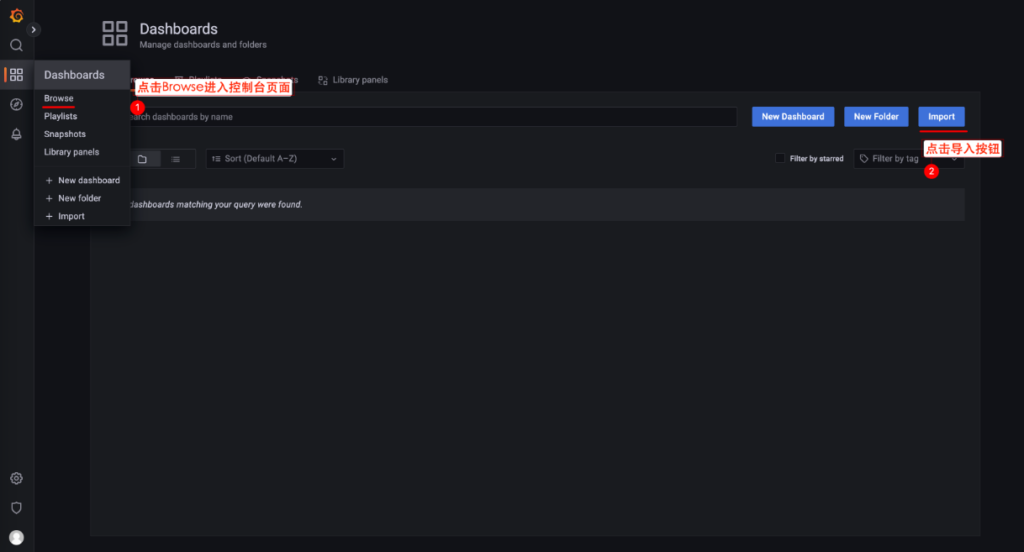
2. 导入 DashBoard 模板
点击 Dashboard-Browse 按钮进入控制台页面,并点击 Import 按钮进行导入操作。
通过下述百度网盘分享的文件下载 oneThread Grafana 的大屏 JSON 文件。
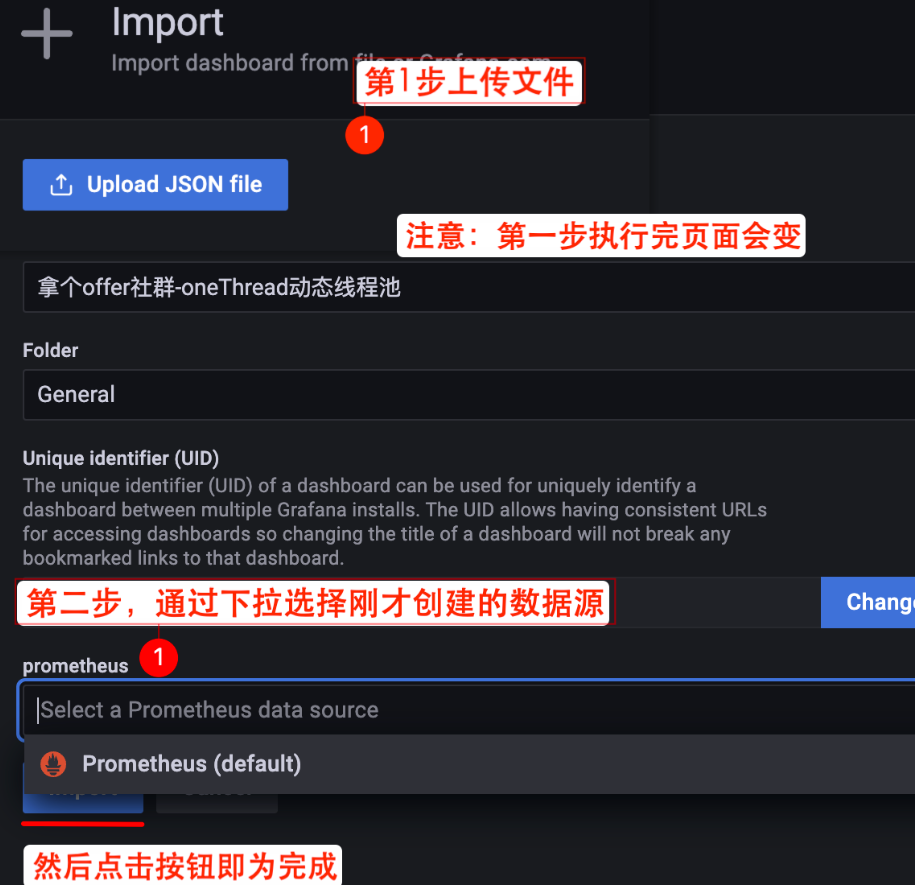
上传 JSON 文件并选择 Prometheus 数据源。
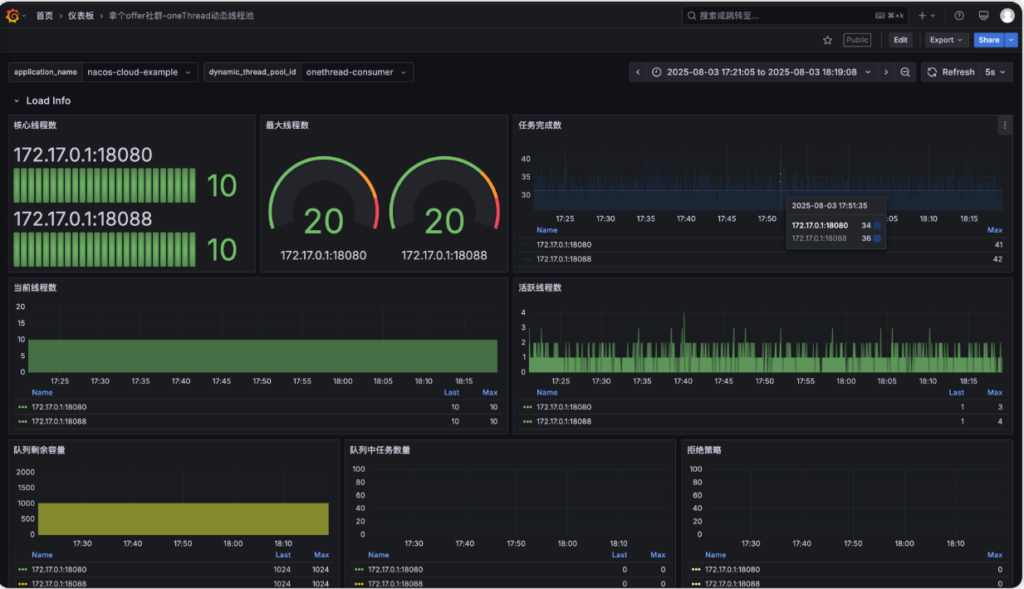
如果你的 onethread Nacos 项目一直在产出指标数据,并且 Prometheus 也在进行采集,那么导入后就会得到类似于下述的监控大盘。

如果存在监控多个项目和多个线程池,上面的 application_name 和 dynamic_thread_pool_id 可以进行选择。如果单个应用起了多个实例(集群部署),这个监控图表会有类似于下面这种效果,IP 展示会变成多个。
onethread-dashboard-dev Grafana 地址替换
在 dashboard-dev 项目的配置文件中,有这么一个配置:
onethread:grafana:# 如果本地有安装 Grafana 展示,可以替换为本地路径
url: http://grafana.nageoffer.com/d/gxBvKxYNz/7adffa3?orgId=1&from=now-6h&to=now&timezone=browser&var-application_name=nacos-cloud-example&var-dynamic_thread_pool_id=onethread-consumer&refresh=5s&theme=light&kiosk=true如果你打算将项目部署到公网环境,可以将上述 URL 替换为你自己部署的 Grafana 地址。前端展示的线程池监控页面,就是通过接口动态获取该参数来完成跳转与展示的。根据图片的网站,我写下如此内容

onethread:
grafana:
# 格式: http://<你的IP:端口>/d/<你的DashboardID>/<名称>?<保留原有参数>
url: http://192.168.111.131:3000/d/gxBvKxYNz/na-ge-offershe-qun-onethreaddong-tai-xian-cheng-chi?orgId=1&from=now-6h&to=now&timezone=browser&var-application_name=nacos-cloud-example&var-dynamic_thread_pool_id=onethread-consumer&refresh=5s&theme=light&kiosk=true


Comments NOTHING