


AutoDL服务器部署训练
注册过程不予显示,简单的yolov5其实不需要什么高级卡,毕竟远道1050-4G版,近到4060-8g都可以部署
选择后,看到镜像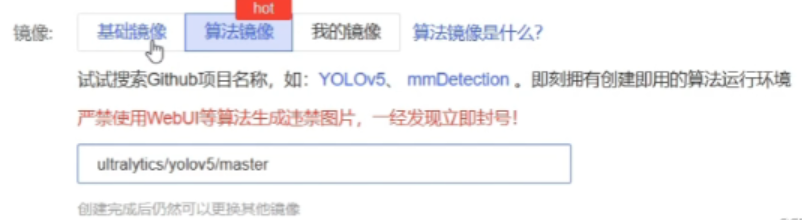
不要选择!!!因为训练的分数是0 ,选择基础版本,pytorch1.9 ubantu扩大版本11.1以上
立刻创建!!!jupyter lab的方式打开,直接把github的yolov5的文件夹拖入即可
如果是zip,终端输入 unzip 文件夹名 解压 cd进入后,和原来一样环境等等等等
conda activate base
conda init退出后再进入即可
pip install -r requirements.txt根据信息合理修改txt内容,可以尝试将处理的pt文件上传测试是否正常
python detect.py同上一章操作方法
Downloading https:/ultralytics.com/assets/Arial.ttf to/root/.config/Ultralytics/Arial.ttf...
可以选择直接上传字体到文件夹中,节省报错
mv Arial.ttf /root/.config/U1tralytics/
python train.py
tar -cvf runs.tar.gz runs/就可以下载了
pycharm基本使用方法
自己找一个pycharm professional破解版或者为他花点钱
本人下载的是2023.3版本,创建编译器环境,选择你的conda即可
就是可以更直接的找到那个conda的python.exe
有一个NLP常用的包
pip install jieba在文件中import jieba,发现返回了'没有找到jieba包'
这是因为默认的terminal在windows的powershell运行,和cmd有点问题,将图纸内容改为cmd即可
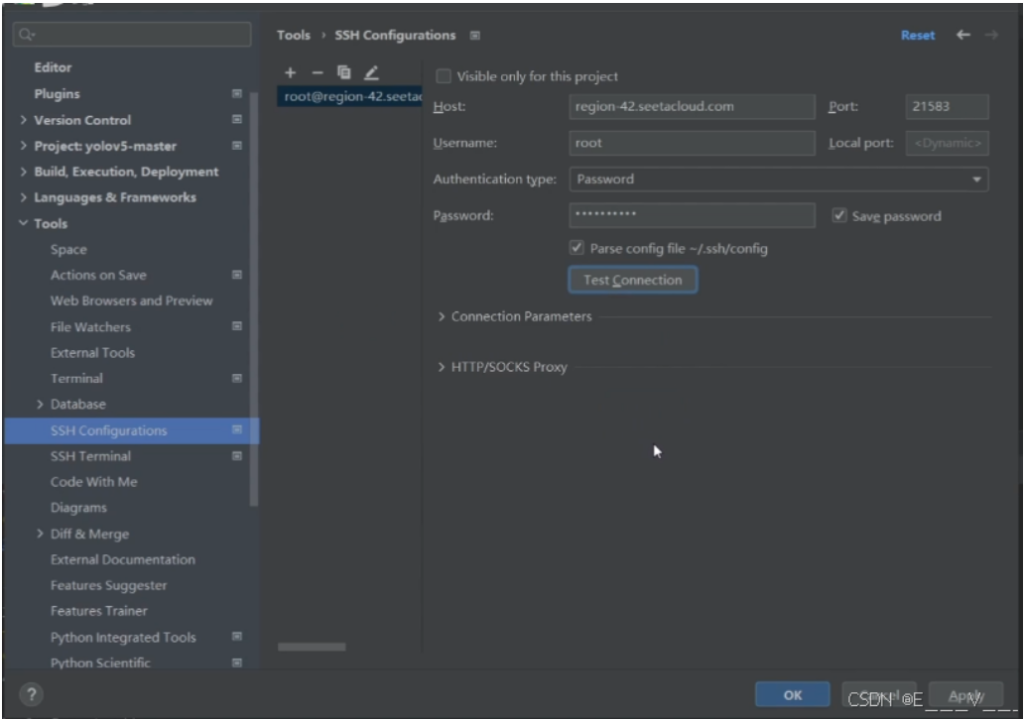
如何链接auto服务器?
提前开机auto,有一个SSH登录指令如下填写。 test填写即可
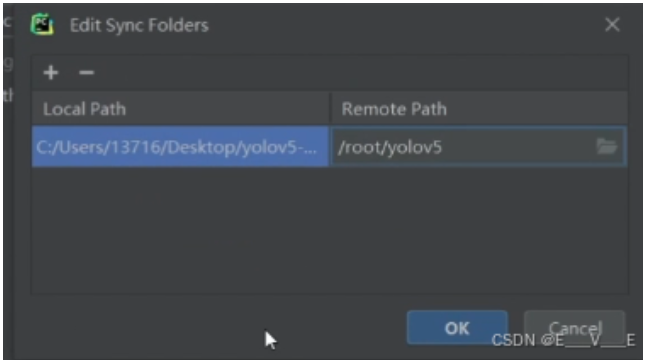
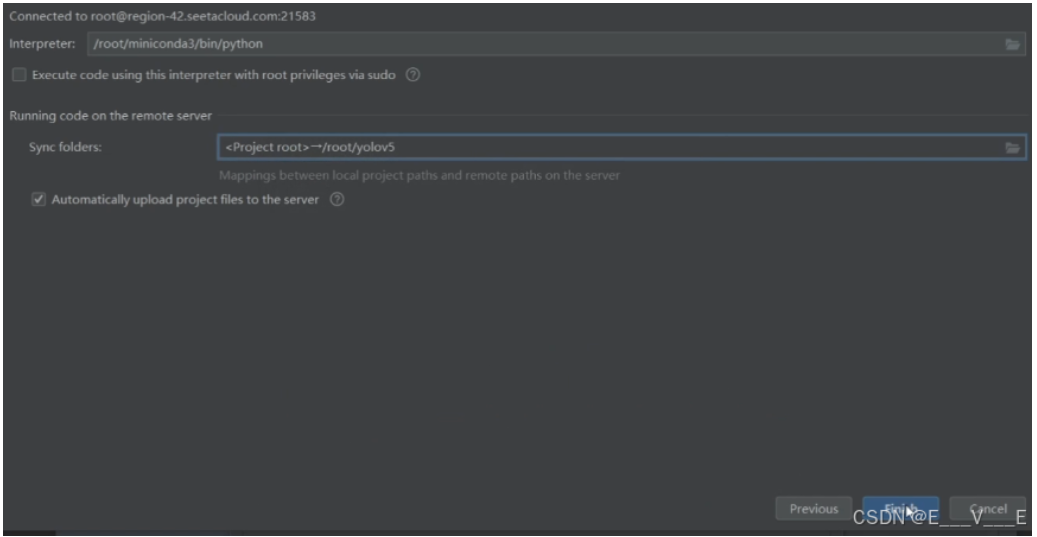
修改直接在本地修改代码,自动上传在tools----deployment-----Automatic---Update
自动获取tools----deployment-----brows remote host,就可以看到服务器里面文件,download forhere即可
想跑一些参数,编辑就连到终端上面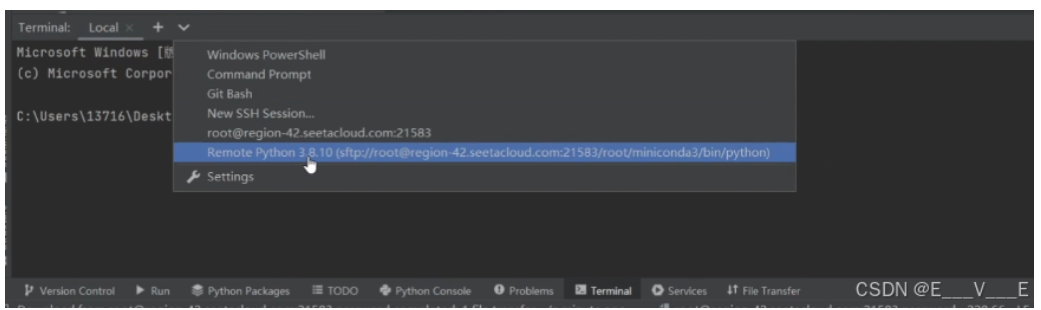
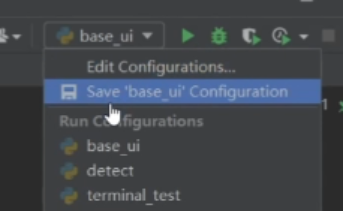
如果 想调整服务器和本地编译器,右上角 点击Edit Configurations 直接更换即可
点击Edit Configurations 直接更换即可
VsCode基本使用方法
直接安装后,选择python的插件,选择解释器,即右下角,选择你的conda环境就OK
由于powershell的影响,在右边有一个选项选择默认配置文件换成cmd
如何建立一个服务器呢?
安装remote-ssh插件,connect to host,add new ssh host,copy一下auto服务器上的ssh,密码即可
vscode其实是直接处理服务器,因此就像网页端的Auto使用即可,第二次打开很容易出来
YOLOV5模型结构和构建原理
结构定义在文件夹中
1.models/yolov5*.yaml 2.models/yolo.py 3.models/commons.py
比如我们打开yolov5s.yaml的文件,如此代码借助注释和ai可以知道到底是干什么用的
实在不理解提供Tensorboard可视化帮助,,在终端输入如下代码
tensorboard --logdir runs 
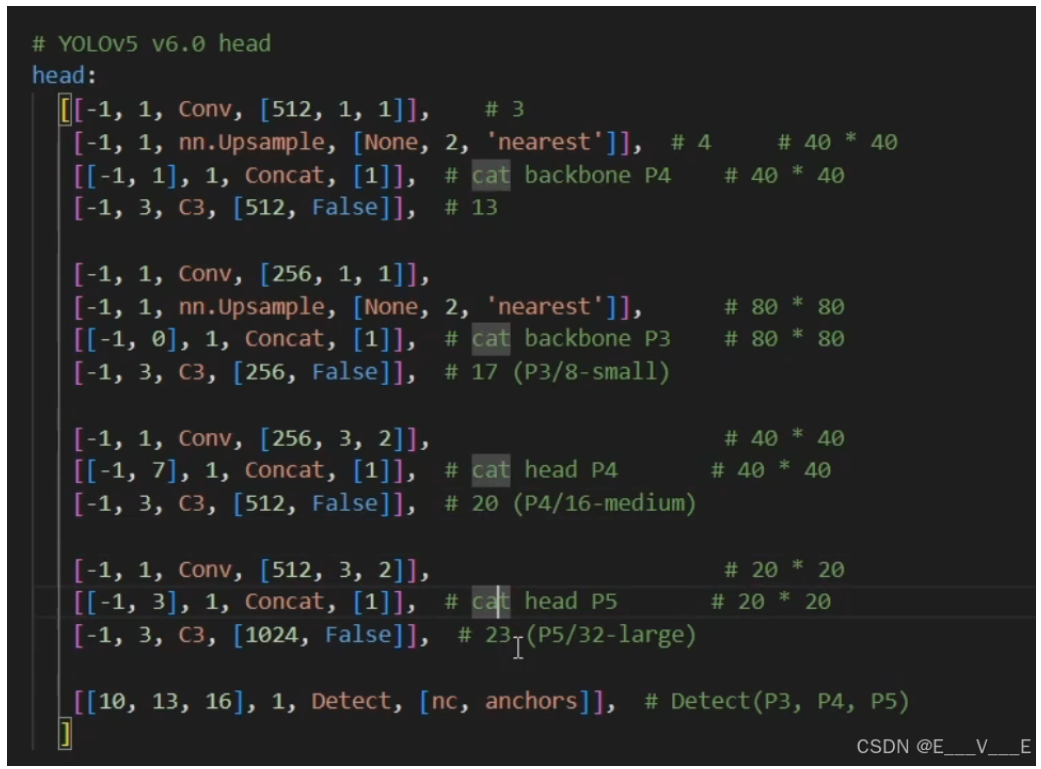
点击 GRAPHS 就可以看见了,那他现在的话是非常简单的,就是只有一个输入,然后一个 detection model,然后一个 output,然后我们只要双击这个 detection model,它就可以把整个网络结构展开了,然后我的鼠标滚轮的话,拖滚轮滚动的话,它就是放大缩小,然后按住的话拖动它,就会把这个图就可以进行拖动了,那我们现现在的话就对着这个图以及刚才的这个结构,然后来把 YOLOV 我的整体的结构过一下,过渡过程中呢,我也会根据 tt bot 中的这个提示啊或者这个信息吧,告诉大家,就是这个数据在网络中经过每一层之后,它都是怎么变换的,OK 那让我们开始,那首先前面可能比较简单了,在 BACKBALL 里面的话,你会发现他前面的话就是按照顺序走下来,每一层的这个输入都是一对吧,那其实说白了就是上一层的输出就是当前层的输入,那我们看一下实际的这个结构,那我们有一个输入 input 就是原始的这个图片,那它的结构它的维度的话就是 1×3 乘 640×640,然后紧接着输入第一层 CNV0,那这里的话可以看到它的输入是 1×3 乘以 640×640,然后经过它之后,整个的这个特征就变成了 1×32 乘三二 0×320,可以看到它比以前缩小了 1/2 对吧,那这个怎么在以前在这个压缩文件里面体现呢,所以就在这里面,就他最后除以二,就意思就是告诉我们,我们现在整个特征图变为了原来的 1/2,然后我们再往下看,其实它在里面标记了很多处啊,就除以 4÷8,除以 16,除以 32 对吧,我们可以看一下,那下一次他说下次又变成除以四,那说明特征图又变小了,那么原始值 640×640,然后经过一次除以二,变成 320×320,然后再除以四,然后我们再来看一下,就这个 CV 一点一下可以看到,那这个时候他的这个输入就是 1×32 乘 320×320,他的这个输出的话就是 1×64 乘 100,6×160 对吧,可以看到它确实是变成了呃原始图像的这个多少分之一,这里的话还要再数点,就看它它前面是什么意思呢,前面这个零的话,大家可以理解就是他是对这个网络的一个编号,为什么他有这么一个编号呢,是因为他后面的话要用到,因为它的虽然前面 backbone 的这个网络结构,是上一层的输出就是下一层的输入,但是他在后面的时候,它就不是这样的结构了,它可能会引用前面的那个,他可能会把前几层的输出连接直接连到后面去,就是不经过其他的操作,直接连到后面去,所以说他要对他进行记录,包括后面我们在改结构的时候,这个编号也是非常重要的,我们要把它记清楚,那第一层的话就是从零开始标,然后 01234567 这样走下来,然后其实可以,我们在这个图上也是可以清晰看到的,那我的这个比如这个第一层卷积,那就是零,第二层卷积就是一,第三层就是第三套,这个 C3 就是二对吧,就他这里没有标出来的这个二,那紧接着,然后我们继续再往下走,又是一层的这个卷积对吧,那可以看到那这一层的时候,他的输出就是 160×160,然后他在输出的时候啊,这里可能它因为它输出了两个 tensor,然后他俩就没标出来,我们可以把它嗯取消一下,双击的话就可以打开这个网络的细节啊,我们可以双击它,然后可以看到他这一步有越来越模糊,但是可以看到它最终变成了,就是 128×80 乘 80 这样的一个结构,现在就是又往下缩了一层,正规四卷积的话,他就往下,他就做了一次,当于做了一次下采样,然后再继续往下走到 C3 的这个第四层 C3,然后一次一次你会发现,然后到第四层的时候,它就分叉了,那我们先不走它分叉这个路线,我们先按照 backbone 这个路线把它走下去,就是 C3,紧接着后面再接一层卷积,然后到这个第五层,然后再 C3 到第六层,那这段话,然后再继续,然后到第七层,第八层,然后接下来紧接着过了一个 SPPF 是第九层,直到这个第九层啊,或者说应该是整个的第十层了啊,就是正好应该是我们这个 backbone 结束的这一层,那我们可以看啊,就它有几个关键的点,他做了一些特征的变换,就是每次卷积的话,就每一次单独的卷积层,其实他都是做了一次下采样,从第一次卷积,然后让它变成整体的一半,就是就是 640 再除以二三百二,然后再一次卷积,然后再除以二变成 160,然后再一次是 80,再过一次是 40,然后经过 CNV7 之后,它现在就变成了 20×20 了,对还有个特征图是这样变换的,OK 那我们继续往下,继续往下走的话,就到了这个 head 的部分,head 的部分的话呃,其实解析下肯定前面是类似的,就是说他第一层这个 head,我们也是按照这个序号走吧,他第一层的这个 head 其实就是先还是一个卷积,就对应的是图里面的这个位置,然后紧接着一次 on sample,就是一次上采样 on sample,然后下面的话他做了一次拼接,可以看到它这里的话他告诉你,他要把这个 backbone p4 的这个地方给他拼过来,那所以说它里的输入的话就变成了一个 list,那就是说这里的是一,是指上一层六的话,就是说我第六层的这个输出,然后做了一个拼接,那我们来看一下是不是原始也是这样,就说他在这一次的时候,可以看到,它是把第六层 C3 的这个输出做了一下拼接,那为什么他们可以拼在一起呢,是因为呃 C3 之后的就是这个 CNV7,就是第七层,这次卷积他又做了一次下采样,但是在我们这里的话,第 11 层他又做了一次上采样,相于那我的这个就上采样之后,和我做下采样之前的这个维度,他们两个是一样的,所以说我们还可以把它拼起来,然后紧接着再过一层这个 C3,然后到实际 13 层下面的话继续往下走,然后又经过一层卷积,那那这里的卷积我们看一眼,就他这里的卷积,其实你会发现它并没有再去做采样,就是说在做下采样,而是让它维度保持不变,然后我们在这这个基础上再去做一次上采样,就是说在 P7 的时候还变成了 2020,那 20×20 我们再做一次上采样,变成 40×40,那 40×40 再做上采样之后,现在就会变成 80×80,就这里的这个上采样变成 80×80,然后这里的这个 contact16 就是第就这个第 16 层,他是把第 15 层的输出,以及第四层的输出拼起来了,就是说我们往前面去倒这个 C3 对吧,然后把它拼接起来,然后紧接着继续往下走到,然后又到了一层,这个 C3C3 完之后,他又做了一次卷积,但这次卷积的时候他又做了一次下采样,然后再拼接,然后再 C3,然后再 CNV,然后把它看开了起来,然后他一直一直到 C23,然后就相当于所有的前面的这个,这一部分就都结束了,就不管它怎么拼吧,但是它的原理是一样的,那最后一层到了这个 detect 层,它是把第 17 层的这个特征图,还有第 20 层,还有第 23 层的特征都都拿出来了,那可以看到他这里有介绍,就是说我第 17 层的这个输出,其实他是做了八倍下采样,那整个特征图就变成了 80×80,然后这个的话是做了 16 倍下采样,这个第二三层的话,他是做了 32 倍下采样,那后面这个 small 和这个 media,还有这个 large 是干什么的,是什么意思呢,就是说我们可以用用这一层,就是说第 17 层这个 800 下采样的特征图,是用来检测小目标的,然后这一层 40×40 的话,它是用来检测这个中等大小的目标的,最后一层 32 倍下采样的这个特征图,它是用来检测这些比较大的物体的结构的话,大概就是这样的一个结构,那我们其实后续要修改这个模型的话,其实就是在这里面修改了。
YOLOv5s 网络结构概览
输入层:
输入尺寸: 1x3x640x640 (批量大小 x 通道数 x 高度 x 宽度)
Backbone (主干网络):
Conv0: 初始卷积层, 将输入从 3x640x640 转换为 32x320x320。此步骤进行了1/2的下采样。
C3模块:
C3_1: 输入 32x320x320 -> 输出 64x160x160 (1/4下采样)
C3_2: 输入 64x160x160 -> 输出 128x80x80 (1/8下采样)
C3_3: 输入 128x80x80 -> 输出 256x40x40 (1/16下采样)
C3_4: 输入 256x40x40 -> 输出 512x20x20 (1/32下采样)
SPPF (Spatial Pyramid Pooling - Fast): 在最后一个C3模块后应用,增强模型对不同尺度特征的捕捉能力。
Neck (颈部网络):
上采样与拼接:
第一次上采样: 512x20x20 -> 256x40x40,与C3_3的输出拼接,形成 512x40x40。
第二次上采样: 256x40x40 -> 128x80x80,与C3_2的输出拼接,形成 256x80x80。
C3模块:
C3_5: 输入 512x40x40 -> 输出 256x40x40
C3_6: 输入 256x80x80 -> 输出 128x80x80
Head (头部网络):
检测层:
第17层: 输入 256x40x40 -> 输出 255x40x40 (用于检测中等大小目标)
第20层: 输入 128x80x80 -> 输出 255x80x80 (用于检测小目标)
第23层: 输入 512x20x20 -> 输出 255x20x20 (用于检测大目标)
每个阶段的输出尺寸反映了不同尺度下的特征图,这些特征图被用于多尺度目标检测,从而提高了模型对于不同大小目标的检测能力。通过上采样和特征图拼接,YOLOv5s能够有效地利用来自多个尺度的信息,这对于提升检测精度至关重要。
我们从train.py看起,直接看Model,第132行就是创建yaml的文件代码,看到创建了yolo.py里面的DetectionModel,下方有178行和nc。
理论写起来太麻烦啦! 鄙人没有基础很难全写出来!此处暂未完工!!!
修改网络结构-以C2f为例
我们借鉴v8的代码https://github.com/ultralytics/ultralytics (YOLOv8)
修改顺序如下
models/commons.py------>加入新增网络结构
models/yolo.py—---------->设定网络结构的传参细节
models/yolov5*.yaml----->修改现有模型结构配置文件 train.py---------------------->训练时指定模型结构配置文件
打开v8下的nn网络结构文件夹。我们注意到yolov5里面在common.py中写了这个结构的定义,在v8中,全部写在了module中
我们可以把modules.py的C2f完全复制到commons.py的C3前面:在最新版2023.8中,modules.py以及变成了包含多个文件的文件夹,打开block.py找到C2f
class C2f(nn.Module):
"""Faster Implementation of CSP Bottleneck with 2 convolutions."""
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):
"""Initializes a CSP bottleneck with 2 convolutions and n Bottleneck blocks for faster processing."""
super().__init__()
self.c = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)
self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))
def forward(self, x):
"""Forward pass through C2f layer."""
y = list(self.cv1(x).chunk(2, 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
def forward_split(self, x):
"""Forward pass using split() instead of chunk()."""
y = list(self.cv1(x).split((self.c, self.c), 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))其中 由于k参数未定义,我们需要copy定义地方Bottleneck,改名为C2f...,同时C2f中也要改
class C2fBottleneck(nn.Module):
"""Standard bottleneck."""
def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5):
"""Initializes a standard bottleneck module with optional shortcut connection and configurable parameters."""
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, k[0], 1)
self.cv2 = Conv(c_, c2, k[1], 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
"""Applies the YOLO FPN to input data."""
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))那么在原先传入C3的地方加入C2f就好了:在yolo.py parse_model下319行加C2f,325行同理
if m in {BottleneckCSP, C3, C3TR, C3Ghost, C3x,C2f}:接下来修改 yolov5s.yaml,把backbone中的C3全改成C2f,head部分可改可不改
修改train.py的435行,可以把yolov5s.yaml改为自定义名字
def parse_opt(known=False):
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default=ROOT / 'yolov5s.pt', help='initial weights path')
parser.add_argument('--cfg', type=str, default=ROOT / 'models/yolov5s.yaml', help='model.yaml path')直接python train.py即可
可能会好奇,我们这里传了CONFIG,是这个cf
,但是我们这个位置传的yolov5s.pt,他这两个结构也不一样,还能不能就是说预训练,或者说借用之前的权重?
其实是可以的,我们可以先简单来看一下,这里其实这个参数也比较关键,就是说当我们传这个位置的时候,他就会去尝试从这个权重里面进行加载权重,那如果说我们不传,那它就相当于就是完全的从头开始训练这部分的逻辑,就是我们上次课讲的那个模型创建的一部分
他这里有一个参数,有一个判断叫这个PRETRAIN,如果pt结尾的话,说明是一个预训练权重,然后就会尝试去加载然后把它给拷贝过去,会做一下迁移,那如果说你不传就没有了
引入注意力机制-以SE为例
其中SE-block.py就是代码部分了,把他放到common.py 的C2f前,并且import
import torch.nn as nn
import torch.nn.functional as F
class SE(nn.Module):
def __init__(self, in_chnls, ratio):
super(SE, self).__init__()
self.squeeze = nn.AdaptiveAvgPool2d((1, 1))
self.compress = nn.Conv2d(in_chnls, in_chnls // ratio, 1, 1, 0)
self.excitation = nn.Conv2d(in_chnls // ratio, in_chnls, 1, 1, 0)
def forward(self, x):
out = self.squeeze(x)
out = self.compress(out)
out = F.relu(out)
out = self.excitation(out)
return x*F.sigmoid(out)这个SE它到底是做了什么?
它里面定义了三个模块,一个是适应的那种平均值化,一个是然后再加上两个卷积,一个是把这就是输入通道数,然后卷积之后把它压缩一点,压缩完之后,然后再把压缩再返回,再卷成之前的输入通道数,那具体做的话就是先进行这个直画,然后进行一次压缩,然后再进行一次就是怎么说呢再涨回来,然后紧接着我们把涨回来的那个结果,进行一个用用那个 sigmoid 参数进行激活,然后再去乘上原始这个 x,就是它的输入通道,输入通道以及它的这个参数,那可以看到在这个 SE 的这个结构里面,其实它只有两个参数,一个是 in channels,一个是这个 ratio,in channelse 的话其实它就是输入通道了,只不过在 SE1 这个里面它比较特殊一点,他的这个输入通道和输入通道其实是一样的,对吧,就是他这个先压缩,后来又给它转回去是一个值,这跟我们上次这个 cf 它有两个通道,这个其实是有些差异的对吧,然后接下来的话它还有个 ritual,这个值就是说我中间这个银层,就是我第一次卷积之后,他的那个输入通道数,应该是我这个 in china 除以这个 ratio,就是那个输入通道数,相当于整个的这个 SE 的这个结构,我们一共需要传递两个参数对吧,OK 我们要把这个记清楚。
接下来在yolov5s.yaml中backbone最后一行添加
[-1,1,SE,[1024,2]]那么这一层变成第10层,接下来head每一行都要加一层 ,其中大于10的都要进行修改+1
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 15], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 11], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[18, 21, 24], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
在yolo.py中添加343行
elif m is SE:
c1= ch[f]#这里要注意,为什么要设定C2,而不是用C1,因为parse_model中,c2是用来记录输出维度的,最后会将c2存入ch中,所以一定对c2的值进行设定
c2= args[0]
if c2 != no: # if not output
c2 = make_divisible(c2 * gw, 8)
args =[c1, args[1]
替换主干网络-以MobileNet为例
新建demo.ipynb文件并且pip install torchinfo
此处缺少部分完善
在替换主干网络的部分需要考虑的一点

编辑
其实是很有考究的对吧
一定要有它经过八倍采样以及16倍采样32倍的采样的输出为什么呢?因为首先啊你的这个八倍的采样会在这儿来用
会在就是第17层前面来用
然后以16倍的采样会在head的第一部分来用
然后你要想用它的话
你首先你保证你的这个进head之前
它一定是一个20×20
就是32倍下采样的一个结构
我们的主干网络替换完成之后,一定也是有经过这几次采样的,一定要有一层,它的那个结构对应的是八倍下采样,一定要有一层对应的是16倍下采样,还有一层要对应的是32倍下采样
只有这样的话才能完美的去继承整个结构,可以让这个high的部分直接就去复用.
import torchvision.models as models
from torchinfo import summary
model = models.mobilenet_v3_small(pretrained=True, progress=True)
summary(model.features, input_size=(1, 3, 640, 640))
model
type(model.features)
model.features[:4]
model.features[4:9]
model.features[9:]
import fiftyone as fo
import fiftyone.zoo as foz
dataset = foz.load_zoo_dataset(
"open-images-v7",
split="validation",
label_types=["detections"],
classes=["Mouse"],
max_samples=100,
seed=51,
shuffle=True,
dataset_name="mouse"
)
fo.launch_app(dataset)在common.py中添加如下
class MobileNetV3(nn.Module):
def init(self, slice):
super(MobileNetV3, self). init()
self.model =None
if slice == 1:
self.model= models.mobilenet_v3_small(pretrained=True).features[:4]
elif slice == 2:
self.model=models.mobilenet v3 small(pretrained=True).features[4:9]
else:
self.model=models.mobilenet_v3_small(pretrained=True).features[9:]
def forward(self, x):
return self.model(x)修改yaml
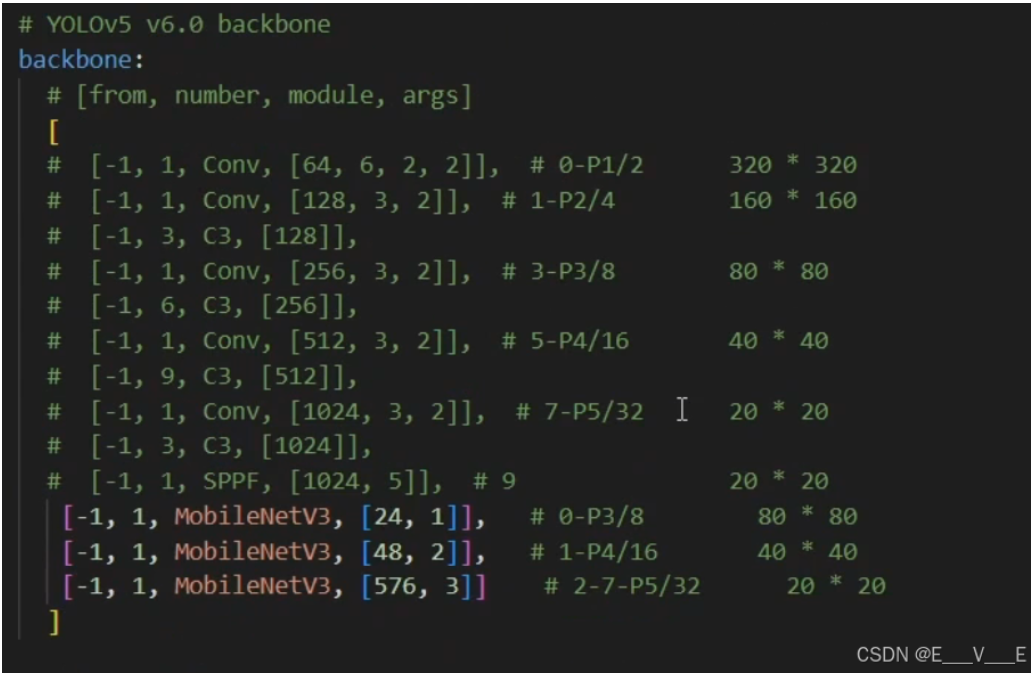
yolo.py添加Mobile的elif(如下),实现了模型轻量化的工作 ---------数据702w到373w的轻量化
elif m is SE:
c1 = ch[f]
c2 = args[0]
if c2 != no: # if not output
c2 = make_divisible(c2 * gw, 8)
args = [c1, args[1]]
elif m is MobileNetV3:
c2 = args[0]
args= args[1:]
else:
c2= ch[f]


Comments NOTHING