


我们申请一块内存时计算机内部发生了什么?看下这句代码:
int*p=(int*)malloc(sizeof(int));这里有两部分,一个是malloc,再一个是你写的代码。
malloc实际上属于标准库,标准库里有什么呢?数学相关的函数,sin、cos、绝对值、数幂函数等;字符相关函数,判断大小写等;字符串操作函数、字符串拷贝、拼接比较等;当然还有内存管理函数,就是这里提到的malloc/free,当然还有很多其它函数,这就是标准库。 从math的sin,cos,pow到string的strcmp,strcat,strcpy,或者malloc和free,islower,isupper,isalpha,isdigit
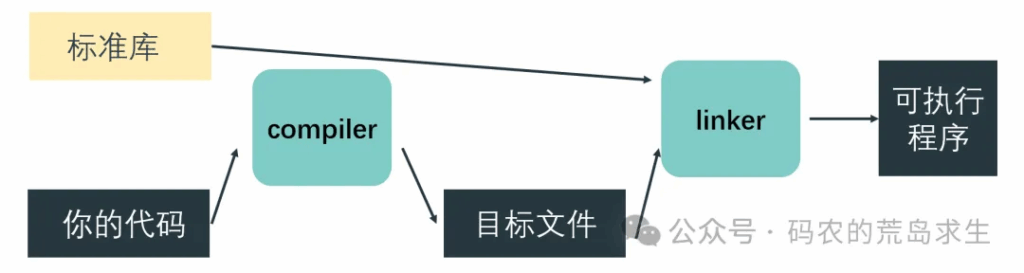
再来看你写的代码,什么是你写的代码呢?以c语言为例,.c文件就是你写的代码,这包括你写的hello world程序、练习程序,还有各种项目。这就是你写的代码。这些代码怎么变成最终的可执行程序呢?当然是借助编译器。编译器会把你的代码编译成目标文件。接着链接器出场,连接器会把目标文件和标准库打包成可执行程序:
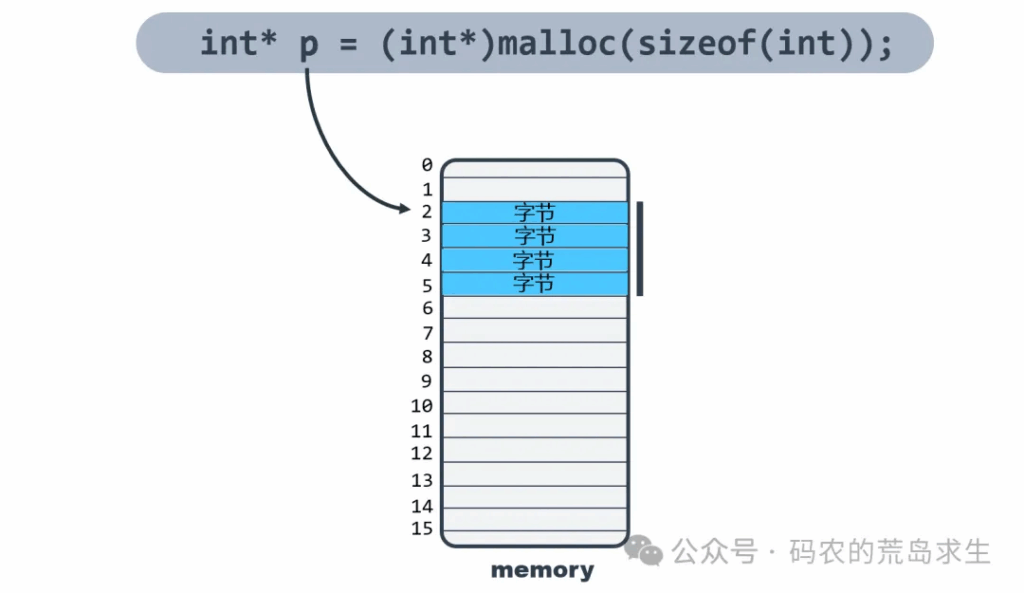
这就是代码部分,接下来我们看内存分配。到底什么是内存呢?内存实际上和储物柜非常相似,储物柜会划分成了一个一个大小相同的隔间,每个隔间可以存储东西,内存的道理也一样,内存也被划分成了一个一个大小相同的隔间,我们来仔细看一下。内存中的每个隔间存储的是一个字节,8比特位一字节。比如这里申请的一块int大小的内存,一个int占据4个字节。
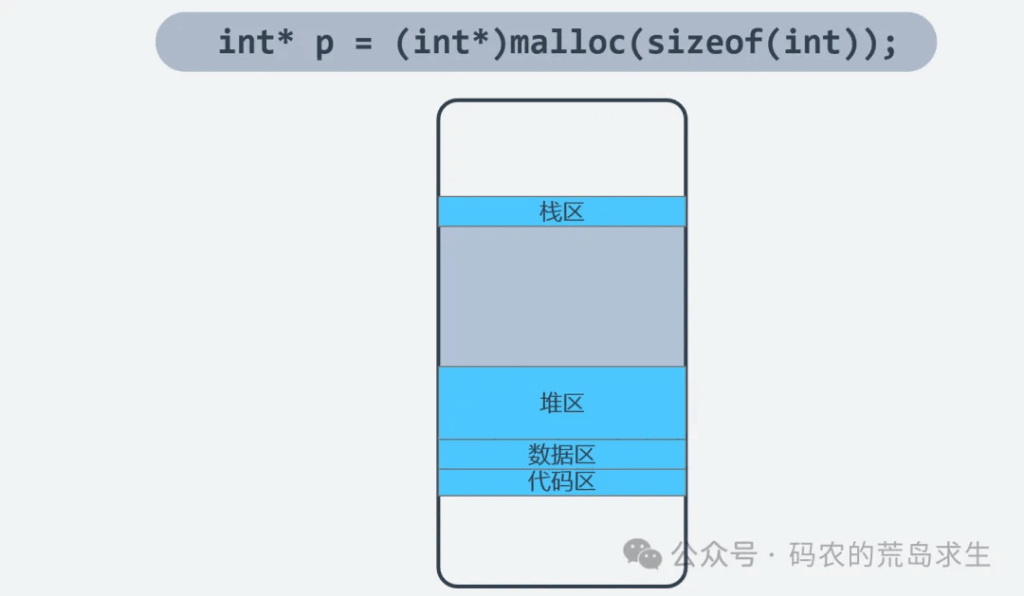
和储物柜一样,内存中的每个隔间也有一个编号,这个编号叫做内存地址。在我们的实例中,申请的这块内存位于内存地址2这个位置,这意味着什么嗯?这意味着变量p等于数字2,或者说等于内存地址2,这里的p就是所谓的指针。
接着我们看内存分配过程。这段代码当然属于编译后生成的可执行程序,可执行程序是在内存中运行的,当然我们需要为整个程序分配一块内存。程序的运行依赖栈区,这里存放着局部变量等信息;依赖堆区,这里存放着程序员自己管理的动态申请的内存,关于堆区和栈区,主要区别在于内存分配方式和生命周期:栈区由系统自动管理(如函数局部变量随函数退出自动释放),而堆区需程序员手动申请(malloc/new)和释放(free/delete),其生命周期持续到显式释放为止
除此之外还依赖代码区,这里保存的就是编译后的之类;还有数据区,这里保存着全局变量等信息。
这些区域在内存中的布局是这样的:
栈区 :向下增长,存储局部变量和函数调用信息,内存分配释放遵循后进先出原则
堆区 :向上增长,存储动态分配的内存块,需通过指针操作且需手动管理
代码区 :存放编译后的二进制指令,通常为只读保护
数据区 :存放全局变量和静态变量,生命周期贯穿整个程序运行
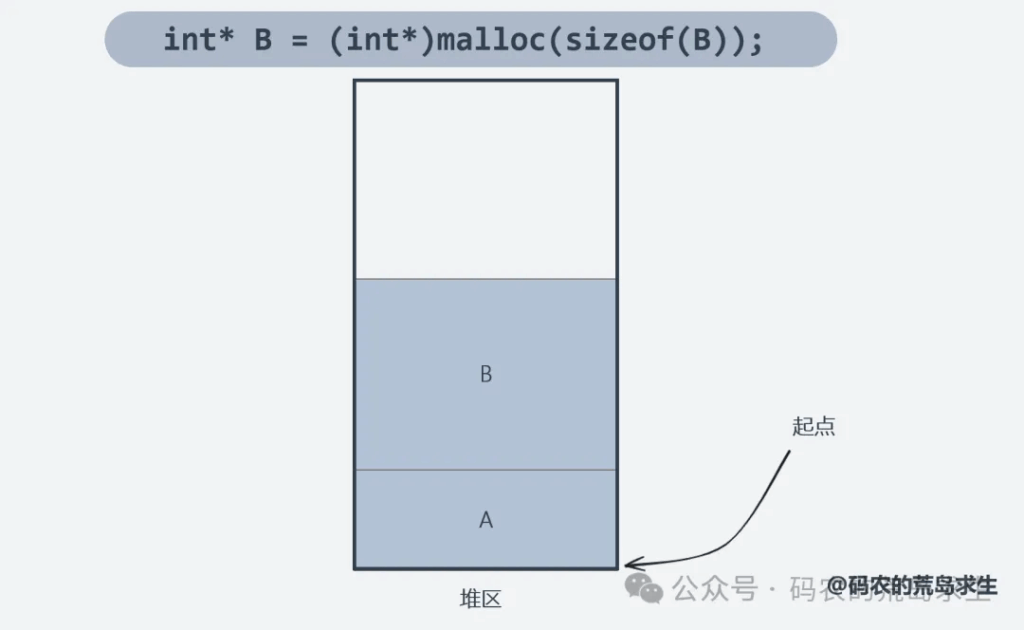
再次强调下,编译后的代码位于代码区,malloc动态申请的内存位于堆区,接下来我们只关注堆区。在程序开始运行时堆区当然是空的,那么所谓的内存分配到底是什么呢?如果让你实现内存分配器该怎么做到呢?很简单,其实内存分配就是划分地盘。
此时要分配第一块大小为A的内存,那么你应该把A放在哪里呢?因为此时堆区是空的,显然你可以把开始这个位置划分给A,作为A的地盘,找到A的地盘后malloc这个函数返回,内存分配过程结束,是不是很简单。

接着程序员又开始申请大小为B的内存,道理和A一样,把A之后的地盘给B即可。
程序员又开始申请大小为C的内存,同理。
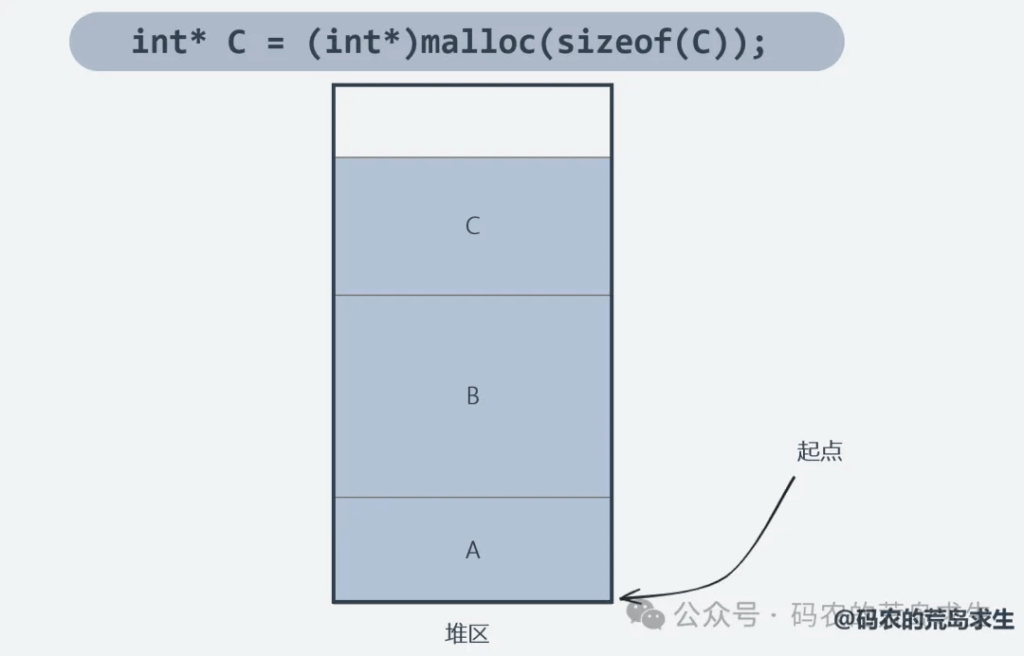
接着程序员说A占用的这块内存使用完毕,调用free释放,所谓释放就是把A占据的地盘重新标记为空闲,这时堆区里还有两块空闲内存。接着程序员开始申请大小为D,这时问题来了,你该从哪里给D划分地盘呢?
放到第一个空闲块吗?显然第一个空闲块大小不够。第二个呢,第二个也不够。但是你发现了一个问题,仔细看着两个空闲块,这两个空闲块的总大小实际上是超过D的。我们把这种空闲的但是不能用来分配出去的内存称之为内存碎片。
你可以想象一下经过不断的内存申请和释放,堆区中会存在无数这样空闲内存碎片。碎片化的内存显然不利于内存的充分利用,计算机科学历史上有无数论文试图来解决这个问题。现在堆区已经不足以为D申请出内存,该怎么办呢?让我们回到最初的布局,注意看堆区和栈区中间实际上还有一段空闲内存区域,这块区域就是为堆区或栈区来扩大地盘用的,那么该怎么扩大堆区呢?
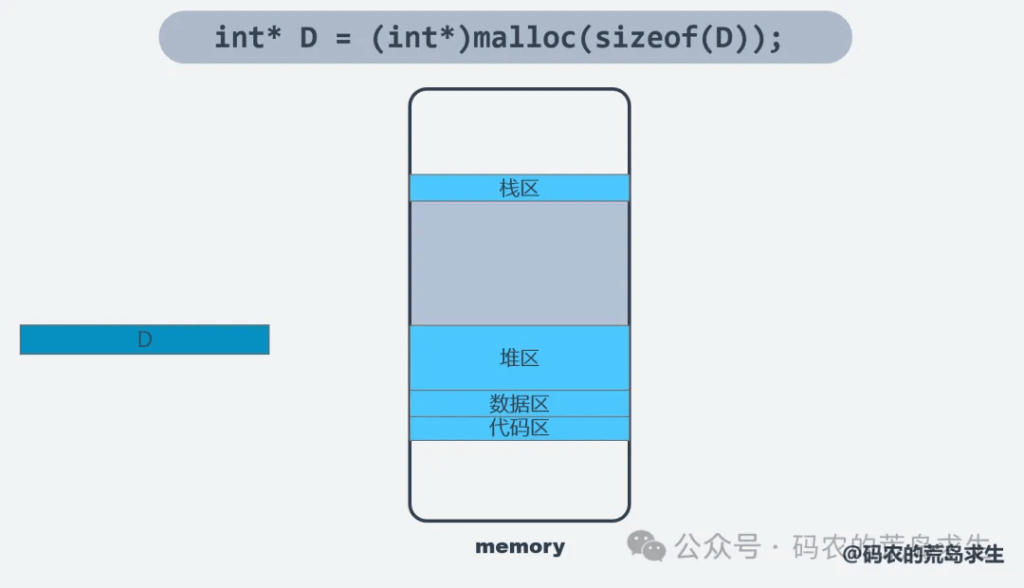
这就要借助操作系统的帮助了。在linux等系统中可以借助brk等系统调用向操作系统申请来扩大堆区。现在堆区扩容完毕,此时就可以在堆区中找出一块合适的空闲内存分配给D,到这时malloc这个过程才真正结束,这实际上是一个相当复杂的过程。
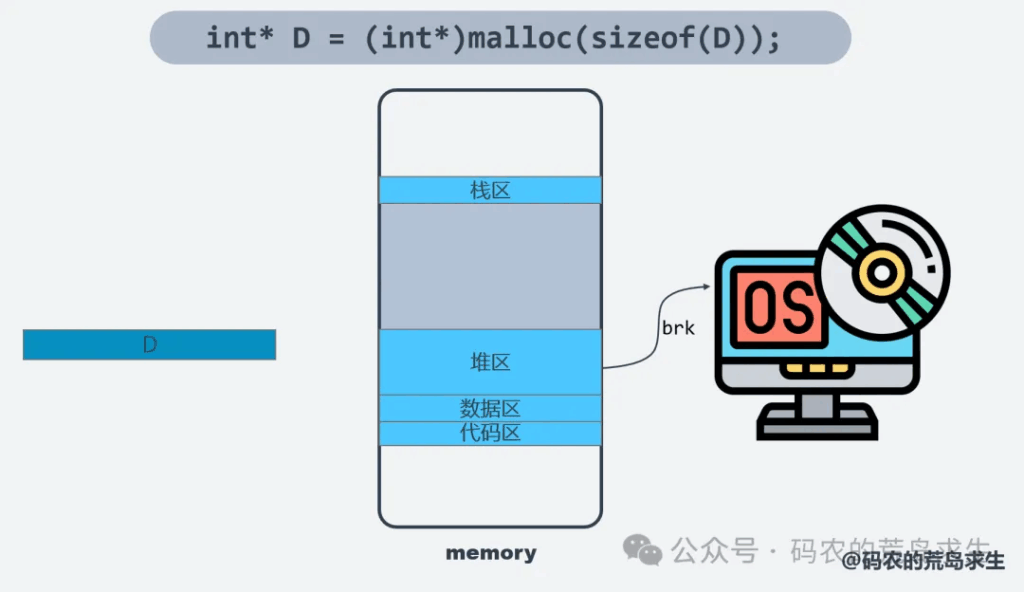
接下来我们仔细分析



Comments NOTHING