


意图识别与多路由调度策略
为什么需要意图识别
1. 一根筋的 RAG 系统会出什么问题
不做意图识别,所有消息都走 RAG 检索,会遇到三类问题:
| 用户消息类型 | 走 RAG 检索的结果 | 实际应该怎么处理 |
|---|---|---|
| 闲聊(你好、谢谢、哈哈) | 召回不相关的 chunk,模型基于不相关内容强行回答,比不检索还差 | 模型直接回答,不需要检索 |
| 工具调用(查我的订单、我还剩几天年假) | 知识库里没有用户的个人数据,检索不到有用信息,模型说“找不到相关信息” | 调 Function Call / MCP 查实时数据 |
| 模糊问题(有什么推荐的吗、怎么办) | 检索结果分散在多个主题,模型乱答一通 | 反问用户补充信息,明确意图后再处理 |
闲聊走检索,比不检索还差 ——这一点很多人没意识到。RAG 系统的生成策略里通常有一条规则:“基于以下参考资料回答用户问题”。如果检索到的 chunk 和用户问题完全不相关,模型要么硬着头皮基于不相关的内容回答(答案很奇怪),要么触发兜底回复“抱歉,找不到相关信息”(用户只是说了句你好,你说找不到相关信息?)。
如果不走检索,模型直接回答“你好”,反而更自然。
四种意图类型
在电商客服场景下,用户消息可以分为四种意图类型。这个分类体系不是固定的——不同业务场景可能有不同的分类方式,但这四类覆盖了大多数场景。
1. 知识检索(Knowledge Retrieval)
用户在问一个知识库能回答的问题。这类问题的特点是:答案存在于你的知识库文档里,是“静态”的、通用的知识。
典型问题:
- iPhone 16 Pro 的退货政策是什么?
- 保修期内屏幕碎了能免费换吗?
- 你们的配送范围覆盖哪些城市?
- 会员等级有什么权益?
处理方式:走完整的 RAG 检索流程——Query 改写 → 向量检索 → 重排序 → 生成答案。
2. 工具调用(Tool Invocation)
用户想查询个人数据、实时信息,或者执行某个操作。这类问题的特点是:答案不在知识库里,需要调用外部系统的 API 才能获取。
典型问题:
- 帮我查一下订单 #12345 的物流状态(查个人订单数据)
- 我还剩几天年假?(查 HR 系统)
- 帮我申请退货(执行操作)
- 今天有什么优惠活动?(查实时数据)
处理方式:走 Function Call / MCP 流程——识别出需要调用哪个工具,传入参数,执行工具,把结果返回给模型生成最终答案。
怎么区分知识检索和工具调用?关键看答案的来源。如果答案在你的知识库文档里(退货政策、保修条款、产品参数),就是知识检索;如果答案需要查数据库、调 API、访问外部系统(某个订单的状态、某个人的年假余额、实时库存),就是工具调用。
3. 闲聊对话(Chitchat)
用户在闲聊、打招呼、表达感谢、开玩笑,不涉及具体的业务问题。
典型问题:
- 你好
- 谢谢你的帮助
- 你是 AI 还是真人?
- 今天心情不好
- 哈哈,你真有趣
处理方式:模型直接回答,不走检索,也不调工具。System Prompt 里定义好闲聊时的回复风格就行。
前面说过,闲聊消息走 RAG 检索反而更差。模型自己就能很好地处理这类对话,不需要知识库的辅助。
4. 引导澄清(Clarification)
用户的问题太模糊,系统无法确定该走哪条路。这时候不应该硬答,而是反问用户补充信息。
典型问题:
- 有什么推荐的吗?(推荐什么?手机?配件?)
- 怎么办?(什么怎么办?退货?维修?)
- 帮我看看(看什么?订单?产品?)
- 出问题了(什么产品?什么问题?)
处理方式:不检索也不调工具,直接返回一个引导性的问题,让用户补充关键信息。
引导澄清不是万能的,不能动不动就反问用户。如果用户的问题虽然简短但意图明确(比如“价格呢”,在聊 iPhone 16 Pro 的上下文中意图很清楚),就不应该反问,而是结合对话历史直接处理。只有在真的无法判断意图时才引导澄清。
实际业务中,意图分类体系可能更细。比如电商场景可能拆出“投诉”“催单”“比价”等专门的意图类别。但核心思路不变:先分类,再路由。从这四种基础类型开始,根据业务需要逐步细化。
意图识别的三种方案
知道了要分哪几类意图,接下来的问题是:怎么判断一条用户消息属于哪个类别?
1. 规则匹配方案
最简单直接的方案:用关键词和正则表达式判断意图。
public class RuleBasedClassifier {
/** 闲聊关键词 */
private static final Set<String> CHITCHAT_KEYWORDS = Set.of(
"你好", "您好", "谢谢", "感谢", "再见", "拜拜",
"哈哈", "嗯嗯", "好的", "收到", "明白了"
);
/** 工具调用关键词 */
private static final Set<String> TOOL_KEYWORDS = Set.of(
"我的订单", "查订单", "订单号", "物流状态",
"年假", "余额", "申请退货", "提交",
"修改地址", "取消订单"
);
public String classify(String query) {
// 完全匹配闲聊关键词(短消息)
if (query.length() <= 6 && CHITCHAT_KEYWORDS.contains(query)) {
return "chitchat";
}
// 包含工具调用关键词
for (String keyword : TOOL_KEYWORDS) {
if (query.contains(keyword)) {
return "tool";
}
}
// 消息太短且不是闲聊,可能需要澄清
if (query.length() < 5) {
return "clarification";
}
// 默认走知识检索
return "knowledge";
}
}规则匹配的优缺点很明显:速度极快 ,只能匹配写死的关键词,覆盖不了用户的各种表达方式
成本零 (不调模型)
维护每发现一个 bad case 就要加一条规则,越加越多越加越乱
规则方案最大的问题是无法理解语义 。“帮我看看剩几天假”没有命中“年假”关键词,就会被错分为知识检索。“能退吗”——是问退货政策(知识检索)还是想发起退货(工具调用)?规则无法区分。
规则方案适合做第一层快速过滤 ——把最明确的意图快速识别出来(“你好”就是闲聊,“查订单 #12345”就是工具调用),不确定的交给大模型处理。
2. 大模型分类方案
用大模型做意图分类,核心是设计好分类 Prompt。
2.1 分类 Prompt 的设计
你是一个意图分类助手。根据对话历史和用户的最新消息,判断用户的意图类别。
意图类别定义:
1. knowledge - 知识检索:用户在询问产品信息、政策规定、操作指南等知识库中的内容。
示例:"iPhone 16 Pro 的退货政策是什么""保修期多久""配送范围覆盖哪些城市"
2. tool - 工具调用:用户想查询个人数据、实时信息,或执行某个操作。
示例:"查一下我的订单状态""帮我申请退货""我还剩几天年假"
3. chitchat - 闲聊对话:用户在打招呼、感谢、闲聊,不涉及具体业务问题。
示例:"你好""谢谢""你是AI吗""今天心情不好"
4. clarification - 引导澄清:用户的问题太模糊,缺少关键信息,无法确定意图。
示例:"有什么推荐的""怎么办""帮我看看""出问题了"
判断规则:
- 结合对话历史判断,相同的话在不同上下文中意图可能不同
- 如果用户的问题涉及"我的""查一下"等个人化表述,通常是工具调用
- 如果问题在问通用的规则、政策、产品信息,通常是知识检索
- 只有在真的无法判断意图时才分类为 clarification
- 以 JSON 格式输出,格式为:{"intent": "分类结果", "confidence": 置信度}
- 不要输出 JSON 以外的任何内容
对话历史:
{history}
用户最新消息:{query}几个设计要点:
- 1.每种意图都有明确定义和示例 :这是 Few-shot 的典型用法,给模型足够的参考。定义要写清楚边界——什么算知识检索,什么算工具调用,不能让模型猜
- 2.强调结合对话历史判断 :同样一句“能退吗”,在不同的对话上下文中意图不同。第一轮对话时大概率是问退货政策(知识检索),前面在聊某个具体订单时大概率是想发起退货(工具调用)
- 3.输出JSON格式 :方便程序解析。加 confidence 字段可以在置信度低时触发兜底策略
- 4.clarification要谨慎使用 :Prompt 里明确说“只有在真的无法判断时才分类为 clarification”,避免模型动不动就要求澄清
边界情况是必然存在的。不要追求 100% 的分类准确率,而是要做好兜底策略——分类错了不要出大问题就行。比如把闲聊误分为知识检索,最多是检索了一下但没找到相关内容,模型给一个兜底回复,不会造成严重后果。但如果把工具调用误分为闲聊,用户想退货你回了个“好的呢”,那就有问题了。
3. 混合方案(推荐)
规则匹配速度快但准确率低,大模型分类准确但有延迟和成本。把两者结合起来,就是混合方案:规则做第一层快速过滤,大模型做第二层精确分类 。
规则层只处理高置信度 的明确场景:
- 短消息且完全匹配闲聊关键词(“你好”“谢谢”)→ 直接判定为闲聊
- 包含明确的工具触发词且带具体参数(“查订单 #12345”)→ 直接判定为工具调用
- 其他所有情况 → 交给大模型分类
这样做的好处是:
- 大部分闲聊消息不需要调模型 :用户打招呼、说谢谢这种高频场景,规则就能搞定,省了一次 API 调用
- 复杂场景有模型兜底 :语义模糊、上下文相关的消息,交给大模型判断,准确率有保障
- 成本可控 :实际场景中,闲聊和明确的工具调用大约占 30%~40% 的消息量,这部分都可以被规则层拦截
问题路由的架构设计
1. 路由器模式
意图识别完成后,需要一个路由器把请求分发到不同的处理流程。整体架构是这样的:拿到意图分类结果,调用对应的处理器。每个处理器各自负责自己的逻辑,互不干扰。
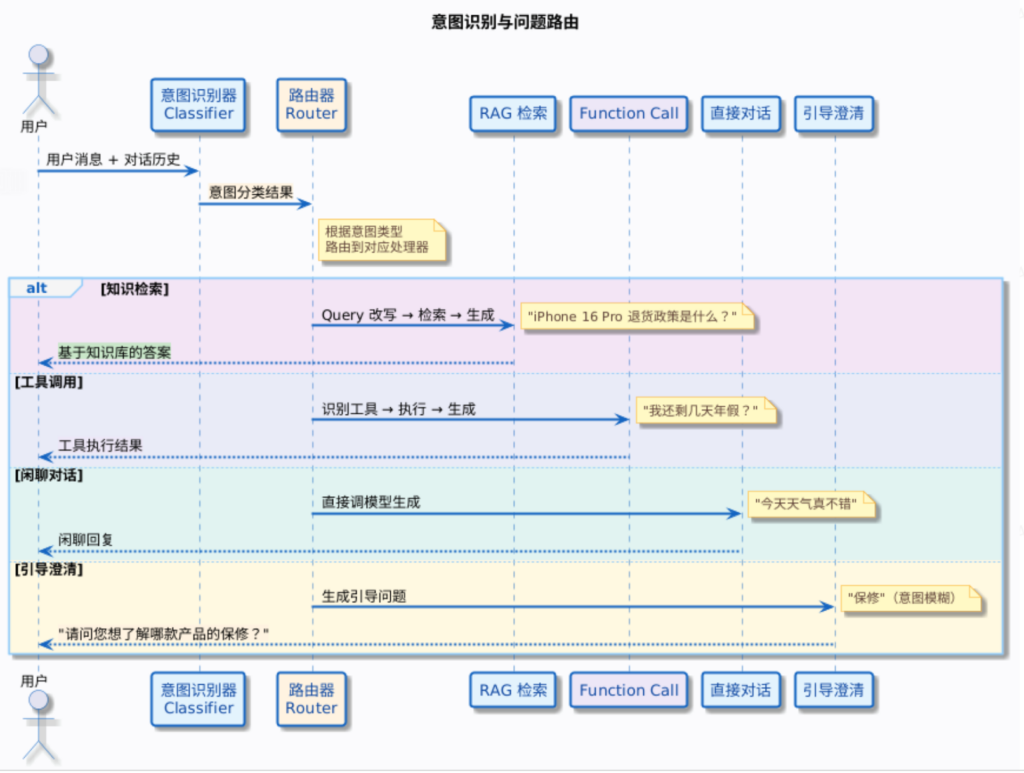
public String route(String intent, List<Message> history, String query) throws IOException {
switch (intent) {
case "knowledge":
// 知识检索路径:Query 改写 → 检索 → 生成答案
return handleKnowledgeRetrieval(history, query);
case "tool":
// 工具调用路径:Function Call / MCP
return handleToolInvocation(history, query);
case "chitchat":
// 闲聊路径:直接调模型生成回答
return handleChitchat(history, query);
case "clarification":
// 澄清路径:返回引导问题
return handleClarification(history, query);
default:
// 兜底:默认走知识检索
return handleKnowledgeRetrieval(history, query);
}
}default 分支走知识检索是一个安全的兜底策略。知识检索路径本身就有兜底机制——如果检索不到相关内容,模型会说“抱歉,找不到相关信息”。这比走错其他路径(比如误调了工具)要安全得多。
Java 实战:意图识别与路由的实现
1. 大模型意图分类器
下面是一个完整可运行的意图分类器,基于 Java + OkHttp 调用 SiliconFlow API:
publicclassIntentClassifier{privatestaticfinalStringAPI_URL="https://api.siliconflow.cn/v1/chat/completions";privatestaticfinalStringAPI_KEY="your api key";// 意图分类用小模型就够了privatestaticfinalStringMODEL="Qwen/Qwen2.5-7B-Instruct";privatestaticfinalOkHttpClient client =newOkHttpClient();privatestaticfinalGson gson =newGson();/**
* 意图分类 Prompt 模板
*/privatestaticfinalStringCLASSIFY_PROMPT="""
你是一个意图分类助手。根据对话历史和用户的最新消息,判断用户的意图类别。
意图类别定义:
1. knowledge - 知识检索:用户在询问产品信息、政策规定、操作指南等通用知识。
示例:"iPhone 16 Pro 的退货政策是什么""保修期多久""配送范围覆盖哪些城市"
2. tool - 工具调用:用户想查询个人数据、实时信息,或执行某个操作。
示例:"查一下我的订单状态""帮我申请退货""我还剩几天年假"
3. chitchat - 闲聊对话:用户在打招呼、感谢、闲聊,不涉及具体业务问题。
示例:"你好""谢谢""你是AI吗""今天心情不好"
4. clarification - 引导澄清:用户的问题太模糊,缺少关键信息,无法确定意图。
示例:"有什么推荐的""怎么办""帮我看看"
判断规则:
- 结合对话历史判断,相同的话在不同上下文中意图可能不同
- 如果用户的问题涉及"我的""查一下"等个人化表述,通常是工具调用
- 如果问题在问通用的规则、政策、产品信息,通常是知识检索
- 只有在真的无法判断意图时才分类为 clarification
- 以 JSON 格式输出:{"intent": "分类结果", "confidence": 置信度}
- 不要输出 JSON 以外的任何内容
对话历史:
%s
用户最新消息:%s""";/**
* 闲聊关键词(规则层快速过滤)
*/privatestaticfinalSet<String>CHITCHAT_KEYWORDS=Set.of("你好","您好","谢谢","感谢","再见","拜拜","哈哈","嗯嗯","好的","收到","明白了","ok");/**
* 混合方案:规则优先 + 大模型兜底
*/publicstaticIntentResultclassify(List<Message> history,String query)throwsIOException{// 第一层:规则快速过滤if(query.length()<=6&&CHITCHAT_KEYWORDS.contains(query)){returnnewIntentResult("chitchat",0.99);}// 第二层:大模型分类returnclassifyByLLM(history, query);}/**
* 调用大模型做意图分类
*/privatestaticIntentResultclassifyByLLM(List<Message> history,String query)throwsIOException{// 构建对话历史文本StringBuilder historyText =newStringBuilder();if(history.isEmpty()){
historyText.append("(无历史对话)");}else{for(Message msg : history){String roleName ="user".equals(msg.role)?"用户":"助手";
historyText.append(roleName).append(":").append(msg.content).append("\n");}}// 构建分类请求String prompt =String.format(CLASSIFY_PROMPT,
historyText.toString(), query);JsonObject body =newJsonObject();
body.addProperty("model",MODEL);
body.addProperty("temperature",0.1);
body.addProperty("max_tokens",100);JsonArray messages =newJsonArray();JsonObject userMsg =newJsonObject();
userMsg.addProperty("role","user");
userMsg.addProperty("content", prompt);
messages.add(userMsg);
body.add("messages", messages);Request request =newRequest.Builder().url(API_URL).addHeader("Authorization","Bearer "+API_KEY).addHeader("Content-Type","application/json").post(RequestBody.create(body.toString(),MediaType.parse("application/json"))).build();try(Response response = client.newCall(request).execute()){assert response.body()!=null;String responseBody = response.body().string();JsonObject json = gson.fromJson(responseBody,JsonObject.class);String content = json.getAsJsonArray("choices").get(0).getAsJsonObject().getAsJsonObject("message").get("content").getAsString().trim();// 解析 JSON 结果returnparseIntentResult(content);}}/**
* 解析模型返回的意图分类 JSON
*/privatestaticIntentResultparseIntentResult(String content){try{JsonObject result = gson.fromJson(content,JsonObject.class);String intent = result.get("intent").getAsString();double confidence = result.has("confidence")? result.get("confidence").getAsDouble():0.8;// 校验意图是否合法Set<String> validIntents =Set.of("knowledge","tool","chitchat","clarification");if(!validIntents.contains(intent)){returnnewIntentResult("knowledge",0.5);}returnnewIntentResult(intent, confidence);}catch(Exception e){// JSON 解析失败,兜底走知识检索returnnewIntentResult("knowledge",0.5);}}/**
* 意图分类结果
*/publicstaticclassIntentResult{publicString intent;publicdouble confidence;publicIntentResult(String intent,double confidence){this.intent = intent;this.confidence = confidence;}@OverridepublicStringtoString(){returnString.format("{intent: \"%s\", confidence: %.2f}",
intent, confidence);}}/**
* 消息数据结构
*/publicstaticclassMessage{publicString role;publicString content;publicMessage(String role,String content){this.role = role;this.content = content;}}}几个关键设计点:
- 混合方案 :
classify方法先用规则过滤短消息中的闲聊,命中了就不调模型,直接返回。没命中才调大模型 - JSON解析兜底 :模型偶尔会输出格式不规范的 JSON,
parseIntentResult方法做了异常处理,解析失败时默认走知识检索 - 意图合法性校验 :如果模型返回了未定义的意图类别(比如自己编了个 “complaint”),也兜底走知识检索
2. 路由器实现
路由器根据意图分类结果,把请求分发到不同的处理逻辑:
publicclassIntentRouter{/**
* 路由到对应的处理流程
*/publicstaticStringroute(IntentClassifier.IntentResult intentResult,List<IntentClassifier.Message> history,String query)throwsIOException{returnswitch(intentResult.intent){case"tool"->handleTool(history, query);case"chitchat"->handleChitchat(query);case"clarification"->handleClarification(query);default->handleKnowledge(history, query);};}/**
* 知识检索路径
* 实际项目中:Query 改写 → 向量检索 → 重排序 → 生成答案
*/privatestaticStringhandleKnowledge(List<IntentClassifier.Message> history,String query){// 这里简化处理,实际项目中要走完整的 RAG 流程return"[知识检索] 正在从知识库检索「"+ query +"」相关内容并生成答案...";}/**
* 工具调用路径
* 实际项目中:识别工具 → 传入参数 → 执行 → 返回结果
*/privatestaticStringhandleTool(List<IntentClassifier.Message> history,String query){// 这里简化处理,实际项目中要走 Function Call / MCP 流程return"[工具调用] 正在调用相关工具处理「"+ query +"」...";}/**
* 闲聊路径
* 直接调模型生成回复,不带检索上下文
*/privatestaticStringhandleChitchat(String query){// 简单的闲聊回复映射,实际项目中可以调模型生成if(query.contains("你好")|| query.contains("您好")){return"[闲聊] 您好!请问有什么可以帮您的?";}if(query.contains("谢谢")|| query.contains("感谢")){return"[闲聊] 不客气,还有其他问题随时问我。";}return"[闲聊] 好的,如果您有任何产品或服务相关的问题,随时告诉我。";}/**
* 引导澄清路径
* 返回引导性问题,让用户补充信息
*/privatestaticStringhandleClarification(String query){return"[引导澄清] 您的问题我还不太明确,"+"能否告诉我您想了解哪方面的信息?"+"比如:产品信息、订单查询、退换货政策等。";}}3. 多场景效果展示
把分类器和路由器串起来,跑几个典型场景看看效果:
publicstaticvoidmain(String[] args)throwsIOException{// ===== 场景 1:知识检索 =====System.out.println("===== 场景 1:知识检索 =====");List<Message> history1 =List.of();String query1 ="iPhone 16 Pro 的退货政策是什么?";IntentResult result1 =IntentClassifier.classify(history1, query1);System.out.println("用户消息:"+ query1);System.out.println("意图分类:"+ result1);System.out.println("路由结果:"+IntentRouter.route(result1, history1, query1));// ===== 场景 2:工具调用 =====System.out.println("\n===== 场景 2:工具调用 =====");List<Message> history2 =List.of();String query2 ="帮我查一下订单 #12345 的物流状态";IntentResult result2 =IntentClassifier.classify(history2, query2);System.out.println("用户消息:"+ query2);System.out.println("意图分类:"+ result2);System.out.println("路由结果:"+IntentRouter.route(result2, history2, query2));// ===== 场景 3:闲聊(规则层命中) =====System.out.println("\n===== 场景 3:闲聊(规则命中) =====");List<Message> history3 =List.of();String query3 ="你好";IntentResult result3 =IntentClassifier.classify(history3, query3);System.out.println("用户消息:"+ query3);System.out.println("意图分类:"+ result3);System.out.println("路由结果:"+IntentRouter.route(result3, history3, query3));// ===== 场景 4:引导澄清 =====System.out.println("\n===== 场景 4:引导澄清 =====");List<Message> history4 =List.of();String query4 ="有什么推荐的吗?";IntentResult result4 =IntentClassifier.classify(history4, query4);System.out.println("用户消息:"+ query4);System.out.println("意图分类:"+ result4);System.out.println("路由结果:"+IntentRouter.route(result4, history4, query4));// ===== 场景 5:上下文相关的意图判断 =====System.out.println("\n===== 场景 5:上下文相关 =====");List<Message> history5 =List.of(newMessage("user","iPhone 16 Pro 的退货政策是什么?"),newMessage("assistant","iPhone 16 Pro 支持七天无理由退货,拆封后如有质量问题可联系售后。"),newMessage("user","我买的那台屏幕有亮点,想退货"),newMessage("assistant","屏幕亮点属于质量问题,可以申请退货。请问您需要我帮您发起退货申请吗?"));String query5 ="好的,帮我退了吧";IntentResult result5 =IntentClassifier.classify(history5, query5);System.out.println("对话历史:(用户在聊 iPhone 16 Pro 退货,助手问是否发起退货申请)");System.out.println("用户消息:"+ query5);System.out.println("意图分类:"+ result5);System.out.println("路由结果:"+IntentRouter.route(result5, history5, query5));}运行结果(示意):
===== 场景 1:知识检索 =====
用户消息:iPhone 16 Pro 的退货政策是什么?
意图分类:{intent: "knowledge", confidence: 0.95}
路由结果:[知识检索] 正在从知识库检索「iPhone 16 Pro 的退货政策是什么?」相关内容并生成答案...
===== 场景 2:工具调用 =====
用户消息:帮我查一下订单 #12345 的物流状态
意图分类:{intent: "tool", confidence: 0.95}
路由结果:[工具调用] 正在调用相关工具处理「帮我查一下订单 #12345 的物流状态」...
===== 场景 3:闲聊(规则命中) =====
用户消息:你好
意图分类:{intent: "chitchat", confidence: 0.99}
路由结果:[闲聊] 您好!请问有什么可以帮您的?
===== 场景 4:引导澄清 =====
用户消息:有什么推荐的吗?
意图分类:{intent: "clarification", confidence: 0.90}
路由结果:[引导澄清] 您的问题我还不太明确,能否告诉我您想了解哪方面的信息?比如:产品信息、订单查询、退换货政策等。
===== 场景 5:上下文相关 =====
对话历史:(用户在聊 iPhone 16 Pro 退货,助手问是否发起退货申请)
用户消息:好的,帮我退了吧
意图分类:{intent: "tool", confidence: 0.95}
路由结果:[工具调用] 正在调用相关工具处理「好的,帮我退了吧」...几个关键观察:
- 场景1 :典型的知识检索问题,问的是产品退货政策,应该去知识库里找答案
- 场景2 :包含“查订单”“物流状态”等个人化表述,正确识别为工具调用
- 场景3 :“你好”被规则层直接命中,没有调用大模型,响应更快
- 场景4 :“有什么推荐的吗”太模糊,正确识别为需要澄清
- 场景5 :这个最有意思——“好的,帮我退了吧”这句话单独看可能是闲聊(“好的”)或模糊表述,但结合对话历史(前面在聊退货,助手刚问了“要不要发起退货申请”),模型正确判断为工具调用。这就是对话历史在意图识别中的价值
生产环境的注意事项
1. 意图分类的准确率监控
意图分类的错误通常不会被用户直接感知到——用户只知道系统回答得不好,不知道是因为意图分错了导致走了错误的处理路径。所以需要主动监控。
建议记录每次分类的完整信息:
{"session_id":"session-001","query":"好的,帮我退了吧","intent":"tool","confidence":0.92,"method":"llm","history_length":4,"latency_ms":280,"timestamp":"2025-03-07T14:30:00Z"}定期抽检分类日志,关注几个指标:
- 分类准确率 :人工标注后计算,目标 90% 以上
- 各意图的分布比例 :如果某类意图占比异常(比如 clarification 占了 30%),可能是 Prompt 太保守,动不动就要求澄清
- 误分类的典型案例 :哪些消息被分错了?错分为什么类别?原因是什么?针对性调整 Prompt 或补充规则
- 规则层命中率 :规则层拦截了多少比例的请求?如果太低(不到 10%),说明规则太少;如果太高(超过 60%),检查一下规则是否太激进导致误分
2. 意图分类失败的兜底
大模型返回结果可能出现几种异常情况:
- 返回了格式不规范的 JSON(比如多了个换行或注释)
- 返回了未定义的意图类别(比如模型自己编了个 complaint)
- API 调用超时或失败
这些情况都需要兜底。前面代码里已经做了处理——解析失败或意图不合法时,默认走知识检索。
publicIntentResultsafeClassify(List<Message> history,String query){try{IntentResult result =classify(history, query);// 置信度太低也走兜底if(result.confidence <0.5){returnnewIntentResult("knowledge",0.5);}return result;}catch(Exception e){
log.warn("意图分类失败,默认走知识检索: {}", e.getMessage());returnnewIntentResult("knowledge",0.5);}}为什么兜底走知识检索而不是引导澄清?因为知识检索路径自带兜底——如果检索不到相关内容,生成策略里有兜底回复(“抱歉,未找到相关信息,建议您联系人工客服”)。而引导澄清会让用户觉得系统“太笨了,什么都要问”,体验更差。
3. 意图边界的动态调整
业务发展过程中,意图分类体系可能需要扩展。比如:
- 初期:knowledge / tool / chitchat / clarification 四类
- 中期:加入 complaint(投诉)、urgent(催单)等细分类别
- 后期:不同产品线可能有不同的意图体系
建议把意图分类体系做成配置化 的:
// 意图定义配置(可以放在数据库或配置文件中)List<IntentDefinition> intents =List.of(newIntentDefinition("knowledge","知识检索","用户在询问产品信息、政策规定、操作指南等通用知识",List.of("退货政策是什么","保修期多久")),newIntentDefinition("tool","工具调用","用户想查询个人数据、实时信息,或执行某个操作",List.of("查我的订单","帮我申请退货")),// 新增意图只需加配置,不改代码newIntentDefinition("complaint","投诉","用户在表达不满或投诉",List.of("我要投诉","态度太差了")));意图定义配置化之后,加新意图只需要修改配置,不需要改代码,也不需要重新部署。Prompt 模板从配置中动态生成,规则层的关键词也从配置中加载。
RAG模型检索生成评估与优化
分层评估的思路
RAG 系统是一个多环节的流水线,如果只看最终结果——用户的问题有没有被正确回答——你知道答错了,但不知道错在哪个环节。
打个比方,就像工厂的质检。一个产品从流水线下来不合格,你不能只说产品坏了就完事了。你得搞清楚是原材料有问题(检索到的 chunk 不对),还是加工工序出了问题(模型基于正确的 chunk 生成了错误的答案),还是设计本身就有缺陷(知识库里根本没有这个信息)。
RAG 系统的评估也一样,要分层:
三层评估的核心逻辑:
- 检索阶段:召回的 chunk 对不对?正确答案有没有在召回的 Top-K 里?排在第几位?——这层出了问题,后面全白搭,模型再厉害也没法基于错误的 chunk 生成正确的答案。
- 生成阶段:给了正确的 chunk,模型有没有忠实地基于 chunk 内容回答?有没有编出 chunk 里没有的信息(幻觉)?有没有答非所问?——这层出了问题,说明 Prompt 或模型需要调整。
- 端到端:不管中间过程,最终答案正确吗?用户满意吗?——这是最终的结果指标,但光看这个定位不了具体问题。
检索阶段的评估指标
检索阶段是 RAG 系统的基础,chunk 都没召回来,后面的生成再好也是空中楼阁。检索阶段的评估核心问题就一个:Top-K 个召回的 chunk 里,有没有包含正确答案对应的 chunk?
围绕这个问题,有四个常用指标。
1. 命中率(Hit Rate)
最简单的指标:Top-K 个召回的 chunk 里,有没有包含正确答案?有就是 1,没有就是 0。多个问题取平均值。
用电商客服的例子来算。假设评测集有 5 个问题,每个问题的 Top-3 召回结果:
| 问题 | Top-3 召回的 chunk | 正确 chunk 有没有在里面 | 命中 |
|---|---|---|---|
| iPhone 16 Pro 的退货政策? | chunk_12, chunk_05, chunk_33 | chunk_12 是正确答案 ✓ | 1 |
| AirPods Pro 的保修期? | chunk_21, chunk_07, chunk_44 | chunk_21 是正确答案 ✓ | 1 |
| 退货运费谁承担? | chunk_18, chunk_29, chunk_55 | 正确答案是 chunk_41,不在里面 ✗ | 0 |
| 跨境商品能退吗? | chunk_41, chunk_03, chunk_67 | chunk_03 是正确答案 ✓ | 1 |
| 质量问题怎么换货? | chunk_08, chunk_15, chunk_22 | chunk_08 是正确答案 ✓ | 1 |
Hit Rate = 命中次数 / 总问题数 = 4 / 5 = 0.8(80%)
命中率很好理解,但它有一个明显的缺点——不关心正确答案排在第几位。但实际使用中,排在第 1 位和排在第 3 位的差别很大——排在第 1 位意味着检索系统很自信地找到了正确答案,排在第 3 位可能只是凑巧混进来了。
2. MRR(Mean Reciprocal Rank,平均倒数排名)
MRR 在命中率的基础上,还关心正确答案排在第几位。
计算规则:如果正确答案排在第 1 位,得 1 分;排在第 2 位,得 1/2 = 0.5 分;排在第 3 位,得 1/3 ≈ 0.33 分……排在第 K 位,得 1/K 分。如果 Top-K 里没有正确答案,得 0 分。多个问题取平均。
还是用刚才的 5 个问题,这次多关注一下正确答案的排名位置:
| 问题 | 正确答案排在第几位 | 倒数排名(Reciprocal Rank) |
|---|---|---|
| iPhone 16 Pro 的退货政策? | 第 1 位 | 1/1 = 1.0 |
| AirPods Pro 的保修期? | 第 1 位 | 1/1 = 1.0 |
| 退货运费谁承担? | 没命中 | 0 |
| 跨境商品能退吗? | 第 2 位 | 1/2 = 0.5 |
| 质量问题怎么换货? | 第 1 位 | 1/1 = 1.0 |
MRR = (1.0 + 1.0 + 0 + 0.5 + 1.0) / 5 = 3.5 / 5 = 0.7
MRR 比 Hit Rate 更能反映检索质量。两个系统 Hit Rate 都是 80%,但一个系统的正确答案大部分排在第 1 位(MRR 接近 0.8),另一个系统的正确答案大部分排在第 3 位(MRR 可能只有 0.4)——后者的检索质量明显不如前者,因为排在第 3 位的 chunk 在实际使用中更容易被忽略或被不相关的 chunk 干扰模型生成。
MRR 的直觉理解:MRR = 0.7 意味着平均来看,正确答案大约排在第 1.4 位(1 / 0.7 ≈ 1.43)。MRR 越接近 1,说明正确答案越稳定地排在第 1 位。
3. 召回率与精确率(Recall & Precision)
命中率和 MRR 都是围绕一个正确答案来评估的。但现实中,一个问题的完整答案往往分散在多个 chunk 里。
比如用户问退货政策是什么,完整答案涉及三个 chunk:
- chunk_12:退货条件(7 天内、未拆封)
- chunk_13:退货流程(申请 → 审核 → 寄回 → 退款)
- chunk_14:退货运费(质量问题免运费,其他自付)
只命中其中一个,用户拿到的答案就是残缺的。这时候就需要召回率和精确率来衡量找全了没有和找准了没有。
继续用这个例子。系统 Top-5 召回了这些 chunk:
| 排名 | 召回的 chunk | 是否相关 |
|---|---|---|
| 1 | chunk_12(退货条件) | 相关 |
| 2 | chunk_05(会员等级说明) | 不相关 |
| 3 | chunk_13(退货流程) | 相关 |
| 4 | chunk_33(促销活动规则) | 不相关 |
| 5 | chunk_67(配送时效说明) | 不相关 |
召回率(Recall):该找的 chunk,找到了几个?分母是应该找到的总数,分子是实际命中的个数。
$$
Recall = \frac{命中的相关\ chunk\ 数}{标注的相关\ chunk\ 总数} = \frac{2}{3} = 66.7%
$$
3 个相关 chunk 里命中了 2 个(chunk_12 和 chunk_13),漏掉了 chunk_14(退货运费)。用户问退货政策,结果运费相关的信息丢了。
精确率(Precision):找回来的 chunk 里,有几个是真正有用的?分母是召回的总数,分子是其中相关的个数。
$$
Precision = \frac{命中的相关\ chunk\ 数}{召回的\ chunk\ 总数} = \frac{2}{5} = 40%
$$
召回了 5 个 chunk,但只有 2 个是相关的,另外 3 个(会员等级、促销活动、配送时效)都是噪音。这些不相关的 chunk 会干扰模型生成,还浪费 Token。
这两个指标往往是跷跷板关系:
- 召回率高但精确率低——Top-K 设得很大,找了一大堆回来,正确 chunk 确实都包含了,但噪音也很多。多余的 chunk 会干扰模型生成,增加 Token 消耗。
- 精确率高但召回率低——Top-K 设得很小,找回来的每个 chunk 都很相关,但遗漏了部分正确 chunk。答案可能不完整。
RAG 场景通常更关注召回率——宁可多召回几个不太相关的 chunk(后面可以用 Reranker 过滤掉噪音),也不要漏掉正确答案。因为漏掉了就彻底没了,模型不可能基于没看到的信息回答正确。
实际项目中,Hit Rate 和 MRR 更常用,因为它们计算简单,评测集标注也简单——每个问题只需要标注正确答案对应哪个 chunk ID 就行。Recall 和 Precision 需要标注所有相关的 chunk,标注成本更高。如果你的评测集每个问题只标了一个正确 chunk ID,那就用 Hit Rate 和 MRR;如果标了多个相关 chunk ID,可以再看 Recall 和 Precision。严格来说,Hit Rate 和 MRR 也可以标多个正确 chunk ID(命中其中任意一个就算 hit),但它们的核心关注点始终是有没有命中这一个判断,不需要像 Recall 那样算命中了几个占总共几个,所以标注工作量确实小得多。
生成阶段的评估指标
1. 忠实度(Faithfulness)
忠实度衡量的是:模型生成的答案是否忠实于检索到的 chunk 内容,有没有编出 chunk 里没有的信息?
看一个具体的例子。检索到的 chunk 内容是:
iPhone 16 Pro 保修期为 1 年,自购买之日起计算。保修范围包括硬件故障、制造缺陷,不包括人为损坏、进水。
模型的回答:
iPhone 16 Pro 保修期为 2 年,自购买之日起计算。保修范围包括硬件故障、制造缺陷,不包括人为损坏、进水。如需延长保修,可购买 AppleCare+ 服务。
这个回答有两个忠实度问题:
- 2 年——chunk 里明明写的是 1 年,模型篡改了事实
- AppleCare+ 服务——chunk 里压根没提到,模型自己编的
忠实度关注的是答案有没有超出 chunk 内容,跟答案本身对不对是两件事。这里有一个容易混淆的点:
忠实度 ≠ 正确率
chunk 里写的内容可能本身就是错的(比如知识库没有及时更新,保修期已经从 1 年改成了 2 年),模型忠实地转述了过时的信息,忠实度是高的,但答案是错的。这种情况说明问题出在知识库而不是生成环节——这恰恰体现了分层评估的价值,帮你精确定位问题出在哪一层。
在实际项目中,团队通常还会在忠实度的基础上统计幻觉率作为系统级的红线指标。具体做法是:用 LLM 对每条回答的忠实度打分(1~5 分,5 分表示完全忠实,1 分表示严重编造,后面 LLM-as-Judge 自动评测章节会详细讲评分方法),然后统计忠实度 ≤ 2 分的回答占总回答数的比例,就是幻觉率。
忠实度是给每条回答打分(这条答案有多忠实),幻觉率是看整体比例(100 条回答里有多少条出现了明显幻觉)。RAG 的核心价值就是基于检索到的知识回答,如果幻觉率居高不下,那 RAG 就失去了意义。一般来说,幻觉率控制在 15% 以下是一个参考基线。
2. 答案相关性(Answer Relevancy)
答案相关性衡量的是:模型生成的答案是否回答了用户的问题?有没有答非所问?
| 用户问题 | 模型回答 | 相关性 |
|---|---|---|
| 退货运费谁承担? | 退货运费由买家承担,质量问题由卖家承担 | ✓ 高——直接回答了问题 |
| 退货运费谁承担? | 退货流程如下:1. 提交退货申请 2. 等待审核…… | △ 中——相关但没回答运费问题 |
| iPhone 16 Pro 的价格? | 我们的退货政策非常完善…… | ✗ 低——完全答非所问 |
答案相关性和忠实度是两个独立的维度,别搞混了。举个例子,用户问退货运费谁承担,系统检索到了一个关于退货流程的 chunk,模型忠实地转述了退货流程的每一步——忠实度很高,但压根没回答运费问题,答案相关性很低。
反过来,模型编了一句运费由卖家承担——答案相关性高(确实在回答运费问题),但忠实度为零(chunk 里没这个信息)。所以这两个指标要分开看,一个管有没有编,一个管有没有答对题。
端到端的评估指标
1. 答案正确率
最直接的端到端指标:最终答案是否正确回答了用户的问题?
这个指标需要有标准答案作为对照。评判正确本身有一定主观性——模型回答的措辞跟标准答案不一样,但意思一样,算不算正确?通常采用语义匹配而不是字面匹配,让人工或 LLM 来判断模型答案的含义是否与标准答案一致。
2. 兜底率
系统回答“抱歉,找不到相关信息”的比例。在生成策略那篇里设计过兜底回答——当检索不到相关 chunk 或者模型判断无法回答时,返回兜底回复。
兜底率太高说明知识库覆盖不够,或检索效果差,大量问题找不到答案;太低也不正常,可能模型在强行回答不该回答的问题,编造答案。
参考范围:5%~15% 是比较合理的区间。低于 5% 要警惕是不是模型在硬答,高于 15% 要检查知识库覆盖度和检索配置。但这个范围跟业务场景强相关——如果你的知识库就是很垂直很小,只覆盖退货退款相关问题,那非退货问题触发兜底是完全正常的,兜底率高不代表系统差。反过来,如果你的知识库覆盖了所有业务场景,兜底率超过 15% 就要认真排查了。
3. 用户满意度
最终的北极星指标。前面所有指标都是技术指标,用户满意度才是业务指标。
可以通过两种方式收集:
- 显式反馈:在回答后面加点赞或点踩按钮,让用户主动评价。简单直接,但参与率低——大部分用户不会主动反馈,反馈的往往是特别满意或特别不满意的,有偏差。
- 隐式反馈:通过用户行为推断满意度。比如用户在得到回答后没有追问(可能满意了),或者用户重复问了同一个问题(说明对上次回答不满意),或者用户在对话后转了人工客服(说明 RAG 没解决问题)。
在实际项目中,用户满意度作为监控指标比作为评测指标更合适。因为它需要线上用户数据,没法在离线评测集上计算。离线评测主要看前面几个指标(Hit Rate、MRR、忠实度、正确率),上线后再关注用户满意度的变化趋势。
评测数据集的构建
评测数据集就是你的考试题库—一组预先准备好的问题和标准答案,用来系统性地检验 RAG 系统的效果。
1. 评测集的格式设计
一条评测数据需要包含以下字段:
{"query":"iPhone 16 Pro 的退货政策是什么?","expectedAnswer":"iPhone 16 Pro 支持 7 天无理由退货,需保持商品完好、配件齐全、包装完整。退货运费由买家承担,质量问题除外。","relevantChunkIds":["chunk_12","chunk_13"],"intent":"knowledge"}各字段的作用:
- query:用户问题,测试时输入给 RAG 系统
- expectedAnswer:标准答案,用来评估模型生成的答案是否正确
- relevantChunkIds:正确答案对应的 chunk ID 列表,用来评估检索阶段——系统检索到的 chunk 有没有包含这些 ID
- intent:意图类别,确保评测覆盖不同类型的问题
其中 relevantChunkIds 是评测数据集的关键。没有它,你只能评端到端的正确率,没法单独评检索阶段的效果。有了它,就可以算 Hit Rate、MRR——检索到的 Top-K 里有没有包含 relevantChunkIds 里的 chunk。
2. 三种标注方式
2.1 人工标注
让业务专家或客服人员标注:这个问题应该用哪几个 chunk 回答,标准答案是什么。
具体操作:给标注人员一份知识库 chunk 列表和一组问题,让他们标注每个问题对应的 chunk ID 和标准答案。
这是最准确的方式,标注出来的数据质量最高。缺点是成本高、速度慢。标注一条数据大概需要 5~10 分钟(需要在 chunk 列表里找对应的 chunk,还要写标准答案),50 条就是一两天的工作量。
标注时要注意一致性:如果多个人标注同一个问题,标准答案可能不一样。比如退货政策有人写得详细、有人写得简洁。需要提前约定标注规范,答案粒度保持一致。不一致的要讨论对齐。
2.2 用户反馈收集
从线上真实对话中收集评测数据:
- 用户点赞的对话 → 说明回答正确 → 可以作为正向评测数据(问题 + 模型回答作为标准答案)
- 用户点踩或转人工的对话 → 说明回答不好 → 可以用来分析 bad case,但不能直接作为评测数据(因为你不知道标准答案应该是什么,需要人工补标)
优点是数据最真实,来自真实用户的真实问题。缺点是用户反馈有偏差——满意的用户很少会主动点赞,不满意的用户有时候也懒得点踩。能收集到的数据量通常不多。
2.3 大模型辅助生成
用大模型根据知识库文档自动生成 QA 对。做法是:给模型一段 chunk 内容,让它根据 chunk 生成 2~3 个可能的用户问题和对应的标准答案。
优点是快速低成本,半小时就能生成上百条。缺点是模型生成的问题可能不够真实——真实用户不会这样问问题(真实用户可能会说“买了 iPhone 16 Pro 不想要了还能退吗”),而且模型可能会遗漏一些边界场景。
建议做法:大模型先批量生成,然后人工校验筛选——删掉质量差的、补充遗漏的边界场景、调整措辞让问题更贴近真实用户的表达方式。这样既快又能保证质量。
3. 评测集的规模与覆盖
50~100 条起步,但要注意覆盖度,不要全是简单直接的问题:
- 不同意图类型:知识检索、工具调用、闲聊、模糊问题都要覆盖
- 不同难度:简单直接的问题(保修期多久)和复杂问题(质量问题的退货流程和普通退货有什么区别)都要有
- 边界场景:知识库里没有答案的问题(应该触发兜底)、跨多个 chunk 的问题(需要综合多个来源)、模糊问题(有推荐的吗)
- 按问题类型均衡分布:如果 80% 的评测数据都是简单的产品信息查询,那评测结果只能说明简单查询效果不错,复杂场景的效果你还是不知道
建议按比例分配:简单问题 40%、中等问题 30%、复杂/边界问题 30%。
自动化评测:LLM-as-Judge
评测数据集有了,指标也定义好了,接下来的问题是——怎么算这些指标?
检索指标好算:对比一下检索返回的 chunk ID 和评测数据标注的 relevantChunkIds,程序就能自动计算 Hit Rate、MRR。
但生成指标怎么算?忠实度、答案相关性、答案正确率——这些都需要理解答案的语义。比如保修期是 1 年和保修期为一年,含义一样但字面不同,简单的字符串匹配根本不行。让人来评判准确但太慢太贵——100 条评测数据,每条要看 chunk 内容、模型回答、标准答案,逐个打分,一个人评一天都不一定评得完。
1. 用大模型做自动评分
思路很直接:用一个大模型来充当评委,对另一个大模型的回答打分。这就是 LLM-as-Judge。
给评委模型一个评分 Prompt,明确告诉它评分维度、评分标准,让它输出结构化的评分结果。设计三个评分 Prompt,分别评估忠实度、相关性和正确率。
忠实度评分 Prompt
答案相关性评分 Prompt
答案正确率评分 Prompt
三个 Prompt 的设计思路是一致的:明确角色 → 给出评分标准(5 分制,每个分数有清晰的定义)→ 提供评估所需的信息 → 要求 JSON 格式输出。JSON 格式输出很重要——程序需要解析评分结果,自由文本没法自动统计。
LLM 做评委不是 100% 准确的,有几个已知的偏差:
| 偏差类型 | 表现 | 影响 |
|---|---|---|
| 位置偏差 | 倾向于给排在前面的答案更高分 | 多组对比评分时,换一下顺序结果可能不同 |
| 冗长偏差 | 倾向于给更长的答案更高分 | 简洁但正确的答案可能被低估 |
| 自我偏好 | 某些模型对自己生成的内容评分偏高 | 评委模型和生成模型用同一个时,评分可能虚高 |
应对方式:定期用人工评分校准 LLM 评分的一致性。具体做法:
- 1.从评测结果中随机抽取 20~30 条
- 2.人工对这 20~30 条打分(用同样的评分标准)
- 3.对比人工评分和 LLM 评分的一致率
- 4.一致率低于 80% → 调整评分 Prompt(比如增加评分示例、细化评分标准的描述)
- 5.如果调了 Prompt 还是不行,考虑换一个评委模型
评委模型尽量用跟生成模型不同的模型。比如生成用 Qwen,评委用 DeepSeek,避免自我偏好问题。
评估驱动的优化
评估报告出来之后,不是看看就完了。评估的价值在于指导优化——根据指标表现定位问题环节,针对性地改进。
1. 根据评估结果定位问题
用一张决策表来理清哪个指标差、问题在哪、该怎么优化的逻辑:
拿前面的评估报告举例:
- Hit Rate 80%,低于 85% → 检索阶段有问题,退货运费谁承担没有命中正确 chunk。分析原因:可能是退货运费和 chunk_13 的文本退货运费由买家承担语义匹配度不够,或者 Top-3 太少了。优化思路:把 Top-K 从 3 调到 5,或者加入重排序。
- 忠实度 3.33,整体偏低,退货运费忠实度 1 分、跨境商品退货和 Apple Watch 防水各 3 分 → 生成阶段的 Prompt 需要加强限定。优化思路:在 System Prompt 里加一条严禁添加参考文档中未出现的信息,对未检索到内容的场景强化兜底指令。
2. 优化后的验证
每次优化之后,重新跑一遍评测集,对比优化前后的指标变化。这里有一个关键原则:不要只看改善的指标,还要检查有没有其他指标变差。
比如你把 Top-K 从 3 调到 5,Hit Rate 从 80% 提升到了 90%,看起来不错。但要同时检查:
- 忠实度有没有下降?多召回了 2 个 chunk,如果多出来的 chunk 质量不高,可能干扰模型生成,导致幻觉增加。
- 兜底率有没有变化?多召回可能让一些原本触发兜底的问题强行找到了不太相关的 chunk,模型基于不相关 chunk 编了个答案,兜底率下降了但正确率也下降了。
用表格记录每次优化的效果对比(预设结果):
| 指标 | 优化前 | 调整 Top-K 5 后 | 加 Reranker 后 |
|---|---|---|---|
| Hit Rate | 80.0% | 90.0% ↑ | 90.0% |
| MRR | 0.800 | 0.760 ↓ | 0.850 ↑ |
| 忠实度 | 3.33 | 3.10 ↓ | 4.20 ↑ |
| 正确率 | 83.3% | 83.3% | 91.7% ↑ |
| 兜底率 | 16.7% | 16.7% | 16.7% |
从这个表可以看到:单纯增加 Top-K 虽然 Hit Rate 提升了,但 MRR 下降(正确 chunk 排名变差了)、忠实度也下降了(多出来的不相关 chunk 干扰了生成)。加上 Reranker 之后,各项指标才全面改善——Reranker 本身改善的是检索排序,但排序变好意味着高相关的 chunk 排到前面、噪音 chunk 被过滤掉,模型看到的上下文质量更高,忠实度自然也跟着提升。这就是评估的价值——没有数据,你可能以为调 Top-K 就够了,实际上还需要配合 Reranker 才行。
3. 持续优化的闭环
评估不是做一次就完事的,而是一个持续迭代的过程:
- 1.跑评测 → 发现问题(Hit Rate 低、忠实度低、某类问题集中出错)
- 2.分析归因 → 定位到具体环节(检索?生成?知识库?)
- 3.针对性优化 → 调参数、改 Prompt、补知识库
- 4.重新评测 → 确认改善、检查回归
- 5.上线 → 收集线上用户反馈
- 6.扩充评测集 → 把线上发现的新 bad case 补充到评测集中
- 7.回到第 1 步
条件允许的话,把评测流程集成到你的 CI/CD 中。每次修改代码、更新 Prompt 或知识库后,自动跑评测集,评分低于阈值就阻止上线。这样可以在上线前发现回归问题,避免改了 A 问题、B 问题变差了的情况悄悄上线。



Comments NOTHING