


不要把所有活儿都丢给“Tools(工具)”去干,要学会用“Resources(资源)”和“Prompts(提示词)”。
我用通俗的比喻给你翻译一下这三个概念,你就全懂了:
假设你雇了一个非常聪明的 AI 助理,你要怎么让他帮你干活?MCP 协议为他提供了三种帮忙的方式:
1. Tools(工具):让 AI 去“做事”(动词)
- 概念:你可以给 AI 提供各种工具,AI 在需要的时候会自己决定拿哪个工具去干活。
- 比喻:相当于你给 AI 助理发了计算器、车钥匙、发邮件的账号。
- 场景:你让 AI “帮我给老板发封邮件”,或者“把数据库里的某条记录删掉”。这会产生实际的操作或改变。
2. Resources(资源):让 AI 去“看资料”(名词)
- 概念:提供给 AI 阅读的只读数据或背景信息。
- 文章里的痛点:以前很多开发者习惯用 Tools 来做一切。比如写一个叫 获取配置信息 的工具,让 AI 去调用。文章指出这样很别扭——这就像你去餐厅点菜(调用 Tool),服务员不给你上菜,却给你端来了一本菜单(只读信息)。
- 正确的做法:直接把菜单作为 Resources(资源) 给 AI。
- 比喻:相当于你给 AI 助理扔过去一本公司员工手册、一份参考文件、或者当前的系统配置文件。AI 只是“看”这些资料,不会改变任何东西。
3. Prompts(提示词):让 AI 按“标准流程”工作(说明书)
- 概念:预先写好的、结构化的指令模板。
- 文章里的痛点:有些复杂的任务,需要给 AI 设定很长、很复杂的规则(比如扮演什么角色、分几步回答、失败了怎么办)。如果每个接入 AI 的软件(Client)都要自己写一遍这套复杂的规则,不仅麻烦还容易出错。
- 正确的做法:把这套规则固化成 Prompts(提示词模板) 放在服务端。
- 比喻:相当于公司的 SOP(标准作业程序)或者“填空题表格”。比如你们有一套完美的“翻译文章模板”,以后所有人(多个 Client)只要告诉 AI 助理:“用那套‘翻译模板’,把这篇英文放进去”,AI 就能按最高标准产出,不需要每个人再重新教 AI 怎么翻译。
在简单的 AI 项目里,大家习惯只用 Tools(工具),让 AI 自己去调接口就完事了。
但在大型的、正规的项目里:
- 想让 AI 办事,用 Tools(执行动作)。
- 想让 AI 看资料,用 Resources(提供只读数据)。
- 想让 AI 按固定套路发话,用 Prompts(提供填空模板)。
Resources:让 Server 暴露数据给模型
1. Resources 是什么
Resources(资源)是 MCP 协议提供的三类能力之一。一句话概括:Server 暴露数据,Client 来读取,给模型提供上下文。
和 Tools 的区别很关键,用餐厅来打比方:
- Tools 像点菜——你告诉厨房要做一道红烧肉,厨房开火炒菜,这个过程有副作用(消耗食材、产生一道菜)。对应到系统里就是:下订单(写数据库)、发邮件(触发外部操作)、提交退货申请(修改订单状态)
- Resources 像看菜单——你拿起菜单翻了翻,看看有什么菜、价格多少。这个过程没有任何副作用,菜单不会因为你看了一眼就少一页。对应到系统里就是:获取应用配置、查看数据库表结构、读取系统状态
协议层面的定义也很直接:
| 维度 | Tools | Resources |
|---|---|---|
| 本质 | 执行操作 | 提供数据 |
| 副作用 | 可能有(可读可写) | 无(只读) |
| 谁来决定调用 | 模型决定(model-controlled) | 用户/应用决定(application-controlled) |
| 协议方法 | tools/call | resources/read |
| 类比 | 点菜 | 看菜单 |
注意谁来决定调用这一行。Tools 是模型驱动的——模型分析用户意图后自己决定要不要调工具。而 Resources 是应用驱动的——通常由 Host 应用或用户手动选择要读取哪些资源,作为上下文提供给模型。
2. 实际场景理解 Resources
2.1 客服系统的上下文预加载
光看定义可能还是觉得抽象,用一个企业客服场景来感受一下 Resources 的价值。
用户打开在线客服对话窗口,还没开口说话,你的系统就已经知道了这个用户是谁。这时候,程序员在 Host 应用的代码里预设好逻辑:用户进入对话时,主动从 MCP Server 读取一批 Resources,作为上下文提供给模型:(包括ip地址历史个人信息等都可以获得)
customer://users/user_12345/profile→ 这个用户的会员等级、注册时间、历史投诉记录customer://users/user_12345/recent-orders→ 最近 3 笔订单信息docs://return-policy→ 当前退货政策docs://vip-privileges→ VIP 会员专属权益
Host 代码大致长这样:
// 程序员在 Host 应用里写的编排逻辑publicvoidonUserEnterChat(String userId){// 主动读取这个用户相关的 ResourcesString profile = mcpClient.readResource("customer://users/"+ userId +"/profile");String orders = mcpClient.readResource("customer://users/"+ userId +"/recent-orders");String policy = mcpClient.readResource("docs://return-policy");// 把这些内容拼到上下文里,发给模型String context = profile +"\n"+ orders +"\n"+ policy;callLLM(systemPrompt, context, userMessage);}用户开口说:“我买的东西有问题想退”,模型已经知道他是金卡会员、上周刚买了一台 iPhone、享受 15 天无理由退货——一轮对话就能给出精准回答。
注意:这里读取 Resources 后塞进上下文是 Host 应用的编排策略,不是 MCP Resources 协议自动完成的。MCP 协议定义了资源如何被列出(
resources/list)、如何被读取(resources/read),但读到之后怎么用、要不要放进模型上下文,由 Host 应用自己决定。
如果这些信息全用 Tools 来做会怎样?模型需要先判断“我该查什么”,然后依次调用工具,能跑通,但有两个问题:一是额外的推理和调用延迟——模型要先推理出需要调哪些工具,每个工具调用都有网络开销;二是漏调用的风险——模型不一定每次都能意识到要查这三样东西,它可能只查了订单,忘了查会员等级,给出的答案就少了 VIP 专属权益这块。
Resources 的价值就在这里:应用提前把该给的上下文全给了,模型不用猜,没有额外的推理链路和工具调用延迟,也不会漏掉关键信息。
2.2 Java 微服务项目里 Resources 可能有点鸡肋
如果你是 Java 程序员,项目本身就是微服务架构——用户服务、订单服务、内容服务各自独立部署,通过 Feign / Dubbo / gRPC 互相调用。那上面这个场景,你完全可以这么写:直接通过微服务远程调用获取数据;调用链路清晰,类型安全,还有现成的熔断、重试、监控。绕一圈走 MCP Resources 协议,反而多了一层抽象,没有明显收益。
所以结论是:如果你的 AI 应用只有一个 Client(你自己的后端服务),而且已经有成熟的微服务体系,Resources 确实不是必选项,直接用现有的远程调用就好。
MCP Resources 真正有优势的场景是跨 Client 共享数据源——同一个 MCP Server 暴露的资源,Claude Desktop 能读、Cursor 能读、你自己的 Web 应用也能读,大家通过统一的 resources/read 协议获取数据,数据获取逻辑写在 Server 端一次,不用每个 Client 各写一套。如果你的系统只有一个 Client,这个优势就不存在了。
MCP 协议定义了两种资源类型:直接资源(Direct Resources)和资源模板(Resource Templates)。
3.1 直接资源(Direct Resources)
直接资源有一个固定的 URI,指向一个确定的数据。就像一个固定的文件路径,任何时候访问都是同一份数据(内容可能更新,但地址不变)。
docs://product-manual → 产品手册
config://app/settings → 应用配置
file:///var/log/app.log → 应用日志直接资源适合那些数量有限、相对固定的数据——你的系统里有哪些资源是明确的,可以在 Server 启动时就注册好。
3.2 资源模板(Resource Templates)
资源模板使用 URI 模板(遵循 RFC 6570 规范),URI 里有参数占位符。Client 填入具体参数后,才能访问到对应的资源。
order://users/{userId}/orders/{orderId} → 某用户的某个订单详情
file:///logs/{date}/error.log → 某天的错误日志
db://tables/{tableName}/schema → 某张表的表结构资源模板适合那些数量不固定、需要动态生成的数据——比如你不可能为每个订单都注册一个直接资源,但你可以注册一个模板,让 Client 传入订单号来获取具体数据。
3.3 怎么选
判断标准很简单:
| 场景 | 选择 | 理由 |
|---|---|---|
| 系统公告、服务条款、编码规范 | 直接资源 | 内容固定,数量有限 |
| 应用配置、系统状态 | 直接资源 | 地址固定,不依赖参数 |
| 用户订单详情、用户个人信息 | 资源模板 | 需要用户 ID / 订单号作为参数 |
| 日期维度的日志文件 | 资源模板 | 需要日期作为参数 |
| 数据库表结构 | 资源模板 | 需要表名作为参数 |
4. 协议层面怎么交互
Client 和 Server 之间关于 Resources 的交互,涉及四个协议方法:
| 协议方法 | 用途 | 返回内容 |
|---|---|---|
resources/list | 列出所有可用的直接资源 | 资源描述数组(uri、name、mimeType 等) |
resources/templates/list | 列出所有资源模板 | 资源模板定义数组(uriTemplate、name 等) |
resources/read | 读取指定资源的内容 | 资源数据(文本或二进制),附带元信息 |
resources/subscribe | 订阅资源变更通知 | 订阅确认(可选能力,非必须支持) |
前三个是核心,第四个是可选的高级能力(后面会单独说)。交互流程如下:
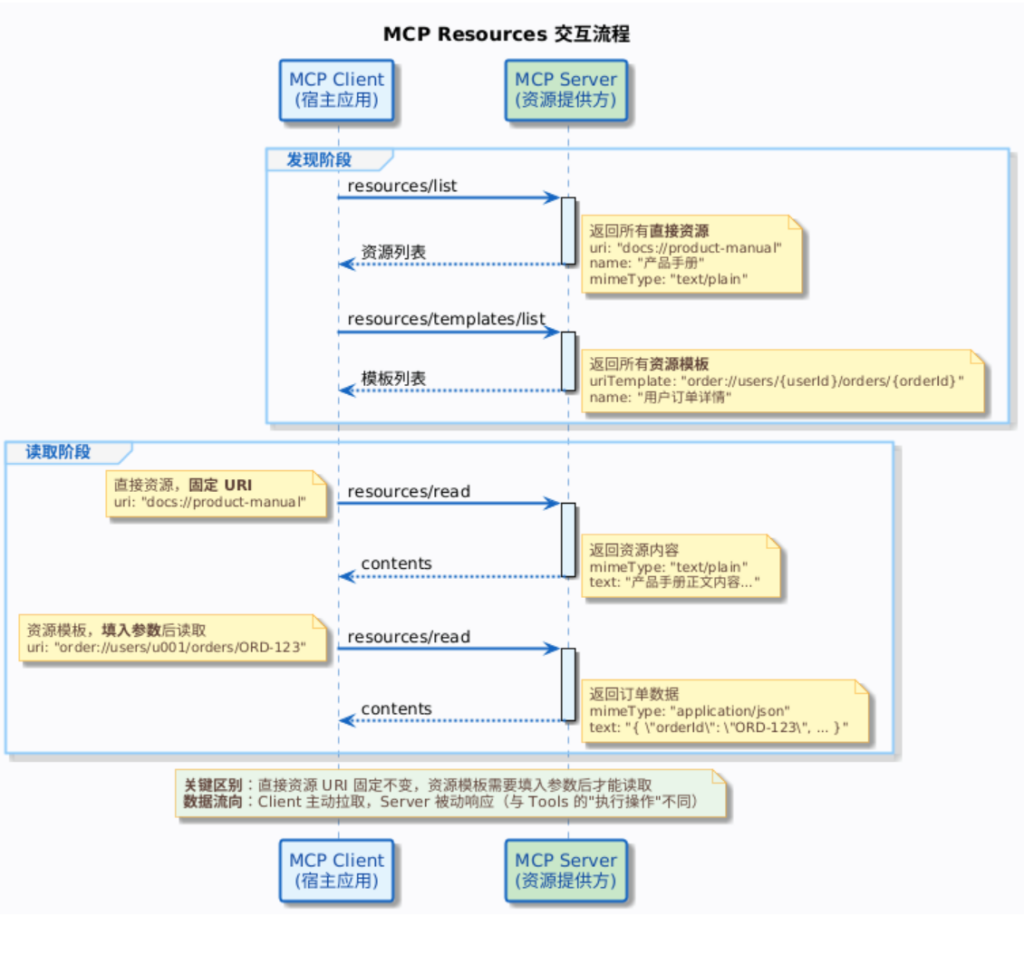
展开说一下前三个方法:
resources/list:Client 问 Server:“你有哪些直接资源?”,Server 返回资源列表,每个资源包含uri(资源地址)、name(资源名称)、description(描述)、mimeType(内容类型,比如text/plain、application/json)resources/templates/list:Client 问:“你有哪些资源模板?”,Server 返回模板列表,每个模板包含uriTemplate(URI 模板,如order://users/{userId}/orders/{orderId})resources/read:Client 传入具体的 URI,Server 返回资源内容
资源内容的返回格式是一个 contents 数组,支持两种内容类型:
// 文本内容{"uri":"docs://product-manual","mimeType":"text/plain","text":"退货政策:自收货之日起 7 天内可无理由退货..."}// 二进制内容(Base64 编码){"uri":"diagrams://architecture","mimeType":"image/png","blob":"iVBORw0KGgo..."}大多数场景用文本内容就够了。二进制内容主要用于图片、PDF 这类非文本数据。
你可能注意到了,
resources/read一次可以返回多个内容(contents是数组)。比如读取一个目录时,Server 可以把目录下所有文件的内容一次性返回。
几个要注意的点:
- 1.
uri属性:直接资源写固定 URI(如docs://return-policy),资源模板写带占位符的 URI(如order://{orderId})。框架会根据 URI 中是否包含{...}来自动判断是直接资源还是资源模板 - 2.返回类型是
ReadResourceResult:里面包一个TextResourceContents(文本内容)或BlobResourceContents(二进制内容)。注意构造TextResourceContents时要传入实际的 URI(模板参数已填入的),不是模板 URI - 3.方法参数自动映射:如果 URI 模板是
order://{orderId},方法参数名写orderId就能自动接收到 Client 传入的值
5.2 和 Tools 对比:同一个需求用两种方式实现
拿查订单详情来说,用 Tools 和 Resources 都能实现。区别在于:
Tools 方式(之前那篇的做法):
@McpTool(description ="查询订单的物流状态和详细信息")publicStringgetOrderStatus(@ToolParam(description ="订单号")String orderId){return"{\"orderId\": \""+ orderId +"\", \"status\": \"运输中\"}";}模型在对话过程中自己决定要不要调这个工具。用户问“我的订单到哪了”,模型分析后输出 tool_calls,你的代码执行,结果返回给模型。
Resources 方式(本篇的做法):
@McpResource(uri ="order://{orderId}", name ="订单详情", description ="...")publicReadResourceResultgetOrderDetail(String orderId){returnnewReadResourceResult(List.of(newTextResourceContents("order://"+ orderId,"application/json", content)));}Host 应用或用户主动选择要读取哪个资源,把资源内容作为上下文提供给模型。模型不参与是否读取的决策。
怎么选:如果这个操作会产生副作用(下单、退款、发邮件),或者需要模型根据对话内容自主判断要不要执行——用 Tools。如果只是给模型提供参考资料,由应用或用户决定要不要看——用 Resources。
实际项目中,两者经常配合使用。比如:先通过 Resources 把应用配置加载到上下文,再通过 Tools 让模型在需要时查询具体订单状态。
6. 资源变更订阅
6.1 资源变更订阅流程
MCP 协议支持资源变更订阅:Client 通过 resources/subscribe 订阅某个资源,资源内容发生变化时,Server 发送 notifications/resources/updated 通知;Client 收到通知后,再调用 resources/read 获取最新内容。
注意:通知的是“这个资源更新了”这个事件,不是直接把新内容推给 Client。Client 收到通知后需要自己重新读一次。
这个机制适合配置热更新、缓存失效通知、实时数据看板等场景。
6.2 什么时候需要订阅,什么时候不需要
你可能会想:前面 Java 实战里的资源内容都是代码里写死的,怎么通知?
关键区分是:URI 写死 ≠ 内容写死。判断要不要支持订阅,看的是同一个 URI 在运行期是否会返回不同内容:
| 场景 | 是否需要订阅 | 理由 |
|---|---|---|
| 资源内容写在代码常量里 | 不需要 | 内容是编译期常量,进程不重启就不会变 |
| 配置项存在数据库 / Nacos / Apollo | 需要 | URI 固定(如 config://app/settings),但底层数据会被运维修改 |
| 实时销售看板 | 需要 | URI 固定(如 dashboard://sales/today),但聚合数据持续变化 |
| 用户资料缓存 | 看情况 | 用户改了个人信息后,customer://users/{id}/profile 的内容就变了 |
换句话说,订阅通知的触发点不在资源定义代码本身,而在资源背后的数据源变化事件——可能是文件变化(WatchService)、数据库配置变化(轮询 / CDC / 消息队列)、配置中心回调(Nacos Listener)、或者业务代码主动触发事件。
6.3 是否支持订阅能力?
是否支持订阅,取决于 Server 和 Client 的 capabilities 声明以及各自实现情况。在当前生态里,订阅相关的 API 仍在迭代中,不少客户端对资源订阅的支持还不算完善。如果你的资源内容本身就是常量,不需要强行上订阅。
我写这篇文档的时候,是 2026.3.16 号,MCP Java SDK 1.1.0 是 3.13 号发布,我看才支持了 Resources 支持订阅功能。至于像 SpringAI 或者 LangChain4j 集成的话,可能又得晚个一段时间。
Prompts:把最佳实践封装成可复用模板
1. Prompts 是什么
在 Tools、Resources 之外,MCP 还定义了第三类能力:Prompts(提示词模板)。一句话概括:Server 预定义 Prompt 模板,Client 传入参数后获取一组可直接用于模型调用的 messages。
用公司内部的文档模板来类比:公司有标准的周报模板、请假单模板、项目复盘模板。你写周报时不用从零开始,打开模板填空就行——项目名称填这里、本周进展填那里、下周计划填那里。格式统一,内容完整,新员工也不会漏写关键信息。
Prompts 做的就是这件事,只不过模板不是给人用的,是给模型用的。Server 定义好一套经过验证的 Prompt 模板(角色定义、回答规则、引用要求、兜底策略都写好了),Client 只需要传入参数(比如检索到的 chunk 和用户问题),就能拿到一组完整的 messages 数组,可直接用于模型调用。
1.1 和直接写 Prompt 有什么区别
你可能会问:我在 Client 端直接拼 Prompt 不也一样吗?为什么要通过 MCP Server 来获取?
区别在于管理和复用:
| 维度 | Client 端自己写 Prompt | Server 端 MCP Prompts |
|---|---|---|
| 版本统一 | 每个 Client 各写各的,版本不一致 | 统一维护,所有 Client 拿到同一版本 |
| 更新方式 | 改 Prompt 要改每个 Client 的代码 | 只改 Server 端,Client 下次获取就是新版 |
| 最佳实践沉淀 | 经验散落在各处 | 集中沉淀在 Server 端 |
| 参数校验 | 各 Client 自行校验 | Server 端统一定义参数和校验规则 |
如果你的系统只有一个 Client,直接写 Prompt 完全没问题。但如果有多个 Client(比如 Claude Desktop、Cursor、你自己的 Web 应用都接入了同一个 MCP Server),Prompts 的价值就体现出来了。
1.2 Prompts 的控制模式
和 Tools、Resources 一样,Prompts 也有自己的控制模式:Client 驱动(通常由用户选择)。
三种能力的控制模式对比:
- Tools:模型驱动——模型自己决定什么时候调用什么工具
- Resources:应用驱动——Host 应用决定加载哪些资源作为上下文
- Prompts:Client 驱动——Client 决定何时获取哪个模板(通常由用户在 UI 里通过斜杠命令或菜单选择触发,但也可以是自动化流程调用)
比如在 Claude Desktop 里,用户输入 /knowledge-qa 就能触发知识库问答模板,输入 /doc-summary 就能触发文档摘要模板。
2. 协议层面怎么交互
Prompts 的交互很简单,就两个核心请求:
prompts/list:Client 问 Server:“你有哪些 Prompt 模板?”,Server 返回模板列表prompts/get:Client 传入模板名称和参数,Server 返回填好参数的完整 messages 数组
prompts/list 返回的每个模板包含:
{
"name": "knowledge-qa",
"description": "知识库问答模板,基于检索到的内容回答用户问题",
"arguments": [
{
"name": "context",
"description": "检索到的知识片段,多个片段用换行分隔",
"required": true
},
{
"name": "question",
"description": "用户的原始问题",
"required": true
}
]
}prompts/get 的请求和响应:
// 请求
{
"method": "prompts/get",
"params": {
"name": "knowledge-qa",
"arguments": {
"context": "[1] AirPods Pro 保修期为 1 年\n[2] AppleCare+ 可延长至 2 年",
"question": "AirPods Pro 的保修期多久?"
}
}
}
// 响应
{
"description": "知识库问答",
"messages": [
{
"role": "user",
"content": {
"type": "text",
"text": "你是一个企业知识库助手。请严格基于以下参考资料回答问题...\n\n参考资料:\n[1] AirPods Pro 保修期为 1 年\n[2] AppleCare+ 可延长至 2 年\n\n问题:AirPods Pro 的保修期多久?"
}
}
]
}注意返回的是 messages 数组,不是纯文本字符串。这意味着 Server 可以精确控制消息的结构——把角色定义、回答规则、参考资料和问题组装成完整的对话。Client 拿到这个数组后,可以直接用于模型调用,也可以根据自己的需要做进一步处理(比如把指令部分放进 system 消息)。
注意:MCP 协议规范中,PromptMessage 的 role 只支持
"user"和"assistant"两种角色,不支持"system"。如果你需要设置 system 级别的指令,可以把指令内容放在第一条 user 消息里,或者由 Client 拿到 messages 后自行拆分到 system 消息中——这属于 Client 的编排策略,不是 MCP Prompts 协议负责的。
注意:MCP 协议规范中,PromptMessage 的 role 只支持 "user" 和 "assistant" 两种角色,不支持 "system"。如果你需要设置 system 级别的指令,可以把指令内容放在第一条 user 消息里,或者由 Client 拿到 messages 后自行拆分到 system 消息中——这属于 Client 的编排策略,不是 MCP Prompts 协议负责的。
- 1.
@McpPrompt注解:name是模板的唯一标识(Client 用这个名字来获取模板),description是模板的描述 - 2.
@McpArg注解:定义模板的参数。required = true表示必填参数,required = false表示可选参数 - 3.返回类型是
GetPromptResult:包含一个描述和一个PromptMessage列表。每个PromptMessage有Role(USER / ASSISTANT)和内容(TextContent)。注意 MCP 协议只支持user和assistant两种角色,不支持system——如果需要设置系统指令,把它放在 user 消息的开头即可 - 4.参数类型都是
String:即使语义上是数字(如maxLength),MCP 协议传递的参数都是字符串,需要在方法内自行转换
3.2 Prompts 和系列前面讲的 Prompt 工程的关系
你可能注意到了,knowledge-qa 模板里的那些规则(限定知识来源、引用标注、兜底指令),和系列中讲 RAG 之 Prompt 工程里讲的内容一模一样。
没错,MCP Prompts 就是把你在 Prompt 工程中沉淀的最佳实践,封装成可复用的模板。以前这些 Prompt 写在每个 Client 的代码里,现在集中放到 MCP Server 上,所有 Client 共用一套。
Prompt 工程解决的是怎么写好 Prompt,MCP Prompts 解决的是怎么把好 Prompt 分发出去。
拿到一个需求时,用这个决策流程来判断:
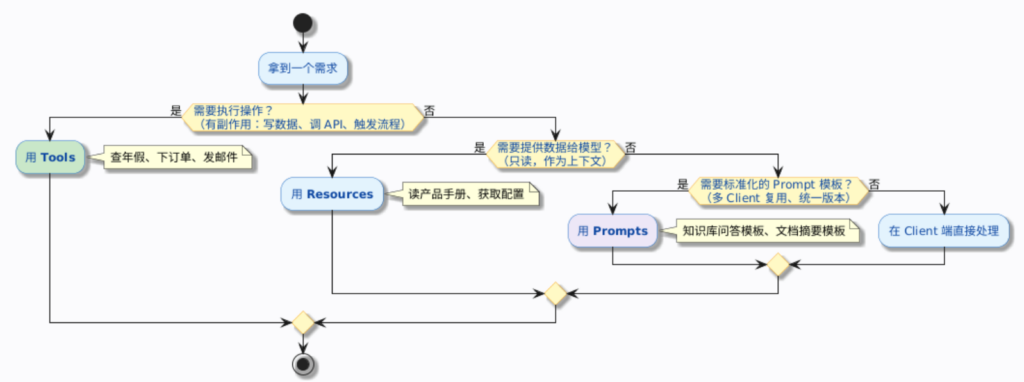
一个成熟的 MCP Server 通常会同时提供三种能力。拿企业知识库助手来说:
- Tools:查年假(
getUserAnnualLeave)、查订单状态(getOrderStatus)——需要调用外部系统,可能有副作用 - Resources:应用配置(
config://app/settings)、数据库表结构(db://tables/{tableName}/schema)、系统运行状态(status://health)——不走检索,作为固定上下文提供 - Prompts:知识库问答模板(
knowledge-qa)、文档摘要模板(doc-summary)——标准化的交互流程
三者各司其职,配合使用。
MCP之官方Java-SDK深度解析
- 1.
@McpPrompt注解:name是模板的唯一标识(Client 用这个名字来获取模板),description是模板的描述 - 2.
@McpArg注解:定义模板的参数。required = true表示必填参数,required = false表示可选参数 - 3.返回类型是
GetPromptResult:包含一个描述和一个PromptMessage列表。每个PromptMessage有Role(USER / ASSISTANT)和内容(TextContent)。注意 MCP 协议只支持user和assistant两种角色,不支持system——如果需要设置系统指令,把它放在 user 消息的开头即可 - 4.参数类型都是
String:即使语义上是数字(如maxLength),MCP 协议传递的参数都是字符串,需要在方法内自行转换
Java SDK 全景:6 个模块各司其职
1. 模块总览
打开 Java SDK 的仓库,你会看到它不是一个单体模块项目,而是拆成了 6 个 Maven 模块:
| 模块 | Maven ArtifactId | 作用 |
|---|---|---|
mcp-bom | mcp-bom | BOM(Bill of Materials),统一管理所有模块的版本号,引入后不用逐个指定版本 |
mcp-core | mcp-core | 核心实现,Client、Server、Transport、Schema 全部核心代码都在这里 |
mcp-json-jackson2 | mcp-json-jackson2 | Jackson 2.x 的 JSON 序列化实现 |
mcp-json-jackson3 | mcp-json-jackson3 | Jackson 3.x 的 JSON 序列化实现 |
mcp | mcp | 便捷包,等于 mcp-core + mcp-json-jackson3,引入这一个就够了 |
mcp-test | mcp-test | 测试工具和集成测试 |
大多数场景下,你只需要在 pom.xml 里引入一个依赖:
<dependency><groupId>io.modelcontextprotocol.sdk</groupId><artifactId>mcp</artifactId><version>1.1.0</version></dependency>这个 mcp 便捷包已经帮你打包了 mcp-core(核心实现)和 mcp-json-jackson3(JSON 序列化),拿来就能用。
SDK 核心架构:四层分明
了解完模块划分,接下来看 SDK 内部的代码结构。整个 mcp-core 模块的代码分成四层,从下往上依次是:
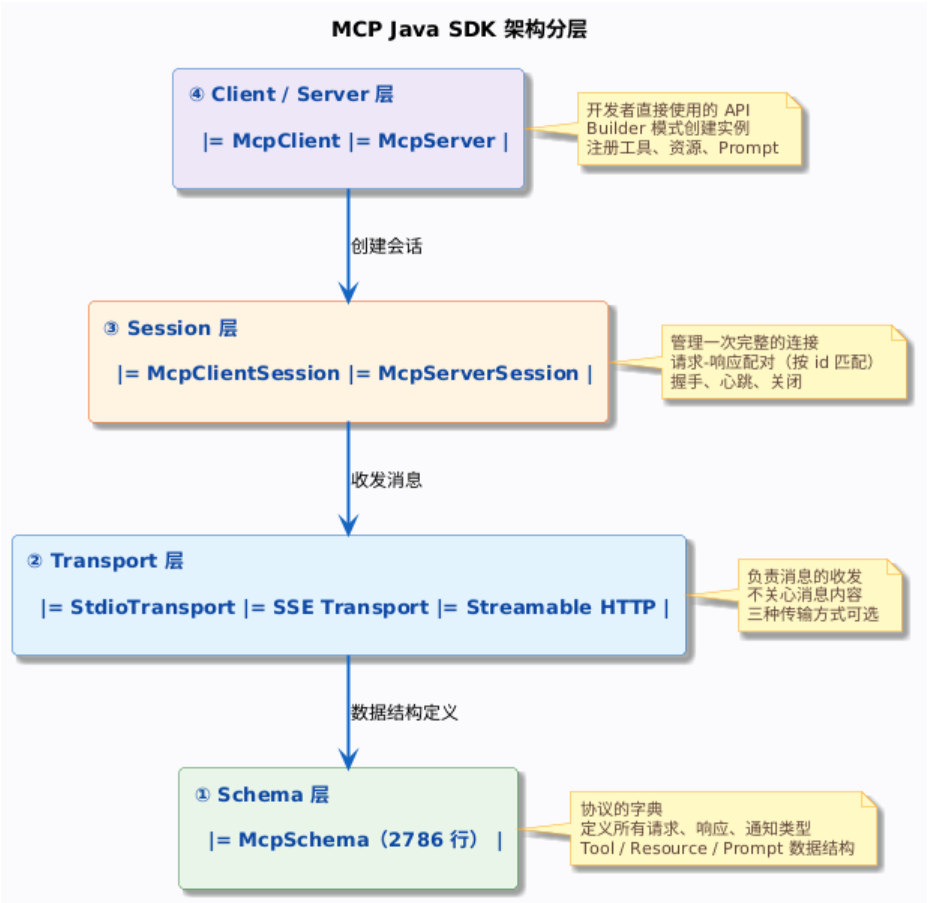
每一层的职责很清晰,从下往上看:Schema 层定义协议里有哪些消息类型,Transport 层负责把消息送达,Session 层管理一次完整的连接会话,Client/Server 层是开发者直接打交道的 API。
1. Schema 层:协议的字典
McpSchema 是整个 SDK 里最大的一个类——2786 行代码,全是数据结构定义。它就像一本字典,规定了 Client 和 Server 之间能说哪些话、每句话的格式是什么。
之前讲 MCP 协议规范 JSON-RPC 2.0 那篇文章里,大家已经知道 MCP 底层用 JSON-RPC 2.0 通信。McpSchema 做的事情就是把协议规范里定义的所有消息类型,都变成了 Java 的 Record 类(Java 16+ 的不可变数据类)。
挑几个你最常接触的类型:
| 类型 | 对应的协议操作 | 说明 |
|---|---|---|
McpSchema.Tool | 工具定义 | 包含工具名称、描述、参数的 JSON Schema |
McpSchema.CallToolRequest | tools/call 请求 | Client 调用工具时发的请求,包含工具名和参数 |
McpSchema.CallToolResult | tools/call 响应 | Server 执行工具后返回的结果 |
McpSchema.Resource | 资源定义 | 包含资源 URI、名称、描述、MIME 类型 |
McpSchema.Prompt | Prompt 模板定义 | 包含模板名称、描述、参数列表 |
McpSchema.InitializeRequest | initialize 请求 | 连接建立时的握手请求 |
McpSchema.InitializeResult | initialize 响应 | 握手响应,包含 Server 的能力声明 |
这些类型最终会被包装成 JSON-RPC 的 Request / Response 在 Client 和 Server 之间传输。比如 Client 调用工具时,实际发出的 JSON-RPC 消息长这样:
{"jsonrpc":"2.0","id":1,"method":"tools/call","params":{"name":"getUserAnnualLeave","arguments":{"employeeId":"E001"}}}其中 params 部分就是 McpSchema.CallToolRequest 对象序列化后的结果。
2. Transport 层:消息的快递公司
Transport 层的职责很单一:把 JSON-RPC 消息从一端送到另一端。它不关心消息内容是什么(工具调用还是资源读取),只管送达。
SDK 提供了三种 Transport 实现,可以理解为三家不同的快递公司,各有各的配送方式:
2.1 Stdio Transport
通过进程的 stdin / stdout 传输消息。MCP Server 作为子进程启动,Client(Host 应用)通过标准输入输出和它通信。每条消息是一行 JSON 文本,用换行符分隔。
你在 Claude Desktop 里配置本地 MCP Server 时,用的就是这种方式。Claude Desktop 启动你的 Java 进程,然后通过 stdin 发请求、从 stdout 读响应。
关键类:
- 客户端:
StdioClientTransport - 服务端:
StdioServerTransportProvider
2.2 SSE Transport
基于 Server-Sent Events 的传输。如果你读过之前的 SSE 系列文章,对这个应该不陌生。
SSE 本身是单向的(只能 Server 向 Client 推送),所以 MCP 的 SSE Transport 实际上走了两条路:
- Server → Client:通过 SSE 长连接推送事件(响应、通知)
- Client → Server:通过单独的 HTTP POST 请求发送(请求)
关键类:
- 客户端:
HttpClientSseClientTransport(基于 JDK 内置的HttpClient,不依赖第三方 HTTP 库) - 服务端:
HttpServletSseServerTransportProvider(基于 Jakarta Servlet)
2.3 Streamable HTTP Transport
SSE Transport 的进化版。双向都走 HTTP,Client 的请求和 Server 的响应都可以流式传输,不需要维持一个额外的 SSE 长连接,按需建立连接即可。
这是 MCP 协议较新引入的传输方式,也是官方推荐的远程传输方案。
关键类:
- 客户端:
HttpClientStreamableHttpTransport - 服务端:
HttpServletStreamableServerTransportProvider
2.4 三种 Transport 怎么选
| 维度 | Stdio | SSE | Streamable HTTP |
|---|---|---|---|
| 通信方式 | stdin / stdout | SSE 推送 + HTTP POST | 双向 HTTP 流 |
| 适用范围 | 仅本地 | 本地 + 远程 | 本地 + 远程 |
| 网络要求 | 无(进程间通信) | HTTP | HTTP |
| 实现复杂度 | 低 | 中 | 中 |
| 生产就绪度 | 适合本地开发 | 可用于生产 | 推荐生产使用 |
| 典型场景 | Claude Desktop 本地工具 | 传统 Web 环境 | 企业级远程部署 |
简单来说:本地开发调试用 Stdio,生产环境远程部署用 Streamable HTTP,SSE 作为兼容性较好的过渡方案。
3. Session 层:对话的窗口
Transport 只管送消息,但一次完整的 MCP 通信不只是单条消息的收发——Client 和 Server 建立连接后,需要先握手(initialize),交换各自的能力声明(我支持哪些功能、你支持哪些功能),然后才能正式收发请求。
Session 层管理的就是这整个连接生命周期。它负责三件事:
- 1.维护连接状态:是否已初始化、是否已关闭
- 2.请求-响应配对:每个 JSON-RPC 请求有一个
id,Session 要把收到的响应按id路由回对应的请求(因为可能同时有多个请求在等待响应) - 3.处理通知消息:JSON-RPC 除了请求-响应,还有通知(Notification)——不需要响应的单向消息,比如工具列表变更通知
关键类:McpClientSession(客户端会话)、McpServerSession(服务端会话)。
4. Client/Server 层:开发者直接打交道的 API
最上层就是你实际使用的 API 了。SDK 提供了 Builder 模式来创建 Client 和 Server,API 设计简洁清晰。
4.1 McpServer
McpServer 是服务端的入口类,提供两个静态方法:
McpServer.sync(transportProvider)——创建同步 ServerMcpServer.async(transportProvider)——创建异步 Server
通过 Builder 链式调用注册工具、资源、Prompt:
McpSyncServer server = McpServer.sync(transportProvider)
.serverInfo(new McpSchema.Implementation("my-server", "1.0.0"))
.tool(
new McpSchema.Tool("getUserAnnualLeave", "查询员工剩余年假天数", jsonSchema),
(exchange, request) -> {
String employeeId = request.arguments().get("employeeId").toString();
String result = "员工 " + employeeId + " 剩余年假:5 天";
return new McpSchema.CallToolResult(
List.of(new McpSchema.TextContent(result)), false
);
}
)
.build();4.2 McpClient
McpClient 是客户端的入口类,同样提供同步和异步两个版本:
McpSyncClient client = McpClient.sync(transport)
.clientInfo(new McpSchema.Implementation("my-client", "1.0.0"))
.build();
// 建立连接,完成握手
client.initialize();
// 发现 Server 端有哪些工具
McpSchema.ListToolsResult toolsResult = client.listTools();
for (McpSchema.Tool tool : toolsResult.tools()) {
System.out.println("工具:" + tool.name() + " - " + tool.description());
}
// 调用工具
Map<String, Object> args = Map.of("employeeId", "E001");
McpSchema.CallToolResult result = client.callTool(
new McpSchema.CallToolRequest("getUserAnnualLeave", args)
);
// 关闭连接
client.closeGracefully();4.3 同步 vs 异步怎么选
SDK 提供了同步和异步两套 API,分别对应 McpSyncClient / McpAsyncClient 和 McpSyncServer / McpAsyncServer。
异步 API 基于 Project Reactor(一个响应式编程库),返回 Mono<T> 和 Flux<T> 类型。如果你用过 Spring WebFlux,对这套东西应该不陌生。
实际上同步 API 内部就是对异步 API 的 .block() 封装——调用异步方法然后阻塞等待结果。所以两套 API 的底层实现是同一套代码。
怎么选:
- 传统 Spring MVC 项目(阻塞式):用同步 API,简单直观
- Spring WebFlux 项目(响应式)或需要处理大量并发连接:用异步 API
- 不确定:用同步,等遇到性能瓶颈再切异步
实战:用纯 SDK 构建 MCP Server
光看架构图不够直观,下面用纯 SDK(不依赖 Spring AI)来搭一个 MCP Server,实现两个工具:getUserAnnualLeave(查年假)和 getOrderStatus(查订单状态)。和之前 Spring AI 版本做个对比,你就能感受到 Spring AI 帮你省了多少事。
2. 完整代码
importio.modelcontextprotocol.server.McpServer;importio.modelcontextprotocol.server.McpSyncServer;importio.modelcontextprotocol.server.transport.StdioServerTransportProvider;importio.modelcontextprotocol.spec.McpSchema;importjava.util.List;importjava.util.Map;importjava.util.concurrent.CountDownLatch;publicclassEnterpriseMcpServer{publicstaticvoidmain(String[] args)throwsInterruptedException{// 1. 创建 Transport:使用 Stdio 方式(通过 stdin/stdout 通信)StdioServerTransportProvider transportProvider =newStdioServerTransportProvider();// 2. 构建 Server,注册工具McpSyncServer server =McpServer.sync(transportProvider).serverInfo(newMcpSchema.Implementation("enterprise-server","1.0.0"))// 注册工具:查年假.tool(buildAnnualLeaveTool(),(exchange, request)->handleAnnualLeave(request))// 注册工具:查订单状态.tool(buildOrderStatusTool(),(exchange, request)->handleOrderStatus(request)).build();System.err.println("Enterprise MCP Server 已启动,等待 Client 连接...");// 3. 注册关闭钩子,进程退出时优雅关闭 ServerRuntime.getRuntime().addShutdownHook(newThread(server::close));// 4. 阻塞主线程,保持进程存活// build() 内部的 stdin 监听线程是守护线程,如果 main 方法结束,JVM 会直接退出// 所以必须手动阻塞主线程,让 Server 持续运行newCountDownLatch(1).await();}// ========== 工具定义 ==========/**
* 构建查年假工具的定义
* 需要手动拼 JSON Schema 来描述参数
*/privatestaticMcpSchema.ToolbuildAnnualLeaveTool(){// 参数的 JSON SchemaString inputSchema ="""
{
"type": "object",
"properties": {
"employeeId": {
"type": "string",
"description": "员工工号,如 E001"
}
},
"required": ["employeeId"]
}
""";returnnewMcpSchema.Tool("getUserAnnualLeave","查询员工剩余年假天数,包括总天数、已使用天数、剩余天数",McpSchema.JsonSchema.fromJson(inputSchema));}/**
* 构建查订单状态工具的定义
*/privatestaticMcpSchema.ToolbuildOrderStatusTool(){String inputSchema ="""
{
"type": "object",
"properties": {
"orderId": {
"type": "string",
"description": "订单编号,如 ORD-20260301-001"
}
},
"required": ["orderId"]
}
""";returnnewMcpSchema.Tool("getOrderStatus","查询订单的物流状态和详细信息",McpSchema.JsonSchema.fromJson(inputSchema));}// ========== 工具处理函数 ==========privatestaticMcpSchema.CallToolResulthandleAnnualLeave(McpSchema.CallToolRequest request){// 从请求中提取参数String employeeId = request.arguments().get("employeeId").toString();// 实际项目中这里调用 HR 系统查询String result =String.format("员工 %s 的年假信息:总年假 15 天,已使用 10 天,剩余 5 天", employeeId
);returnnewMcpSchema.CallToolResult(List.of(newMcpSchema.TextContent(result)),false// isError = false,表示执行成功);}privatestaticMcpSchema.CallToolResulthandleOrderStatus(McpSchema.CallToolRequest request){String orderId = request.arguments().get("orderId").toString();// 实际项目中这里调用订单系统查询String result =String.format("订单 %s 状态:已发货,快递单号 SF1234567890,预计明天送达", orderId
);returnnewMcpSchema.CallToolResult(List.of(newMcpSchema.TextContent(result)),false);}}3. 代码解读
对照代码,你可以看到用纯 SDK 构建 MCP Server 需要做四件事:
第一步:创建 Transport。这里用 StdioServerTransportProvider,表示通过 stdin/stdout 和 Client 通信。如果要远程部署,换成 HttpServletSseServerTransportProvider 或 HttpServletStreamableServerTransportProvider。
第二步:构建工具定义。这是最费劲的部分——你需要手动拼 JSON Schema 来描述每个工具的参数。参数名、参数类型、参数描述、是否必填,都要自己写。对比一下 Function Call 那篇文章里用 Gson 手动构建 JSON Schema 的代码,结构是一样的,只是 SDK 提供了 McpSchema.Tool 这个类来承载。
第三步:编写处理函数。每个工具需要一个处理函数,接收 McpSchema.CallToolRequest(包含工具名和参数),返回 McpSchema.CallToolResult(包含执行结果)。
第四步:阻塞主线程保活。这一步容易被忽略。build() 方法返回后不会阻塞主线程,而 SDK 内部监听 stdin 的线程是守护线程(Daemon Thread)——守护线程不会阻止 JVM 退出。如果 main 方法执行完就结束了,JVM 会立刻退出,Server 根本来不及处理任何请求。所以必须用 new CountDownLatch(1).await() 手动阻塞主线程,让进程一直活着。同时注册 ShutdownHook,在进程被终止时(比如 Ctrl+C)优雅关闭 Server。
注意
System.err.println而不是System.out.println。因为 Stdio Transport 用 stdout 传输 JSON-RPC 消息,如果你往 stdout 打日志,会和协议消息混在一起,Client 就解析不了了。日志输出要走 stderr。
4. 对比:SDK 直接写 vs Spring AI 注解
同一个查年假工具,两种方式的代码量对比:
Spring AI 方式——3 行搞定:
@McpTool(description ="查询员工剩余年假天数,包括总天数、已使用天数、剩余天数")publicStringgetUserAnnualLeave(@McpToolParam(description ="员工工号,如 E001")String employeeId){returnString.format("员工 %s 的年假信息:总年假 15 天,已使用 10 天,剩余 5 天", employeeId);}SDK 方式——需要 30+ 行:
// 1. 手动拼 JSON Schema(10+ 行)String inputSchema ="""
{
"type": "object",
"properties": {
"employeeId": {
"type": "string",
"description": "员工工号,如 E001"
}
},
"required": ["employeeId"]
}
""";McpSchema.Tool tool =newMcpSchema.Tool("getUserAnnualLeave","查询员工剩余年假天数,包括总天数、已使用天数、剩余天数",McpSchema.JsonSchema.fromJson(inputSchema));// 2. 手动编写处理函数,手动提取参数(5+ 行)BiFunction<McpSyncServerExchange, McpSchema.CallToolRequest, McpSchema.CallToolResult> handler =(exchange, request)->{String employeeId = request.arguments().get("employeeId").toString();String result =String.format("员工 %s 的年假信息:...", employeeId);returnnewMcpSchema.CallToolResult(List.of(newMcpSchema.TextContent(result)),false);};// 3. 注册到 Server BuilderMcpServer.sync(transport).tool(tool, handler).build();差距一目了然。Spring AI 帮你做了三件事:
- 1.从方法签名自动生成 JSON Schema:方法参数名变成 Schema 的
properties,参数类型变成type,@McpToolParam的description变成参数描述,方法名变成工具名 - 2.自动把请求参数映射到方法参数:Client 传过来的
arguments里的值,自动按名称匹配到方法参数上 - 3.自动把返回值包装成
CallToolResult:你返回一个String,框架帮你包成TextContent再包成CallToolResult
理解了这些,你就知道 @McpTool 注解不是魔法,而是对 SDK API 的工程封装。
实战:用纯 SDK 构建 MCP Client
Server 端写完了,再来看 Client 端。下面这段代码展示了一个 MCP Client 的完整生命周期:连接 Server → 发现工具 → 调用工具 → 关闭连接。
1. 完整代码
importio.modelcontextprotocol.client.McpClient;importio.modelcontextprotocol.client.McpSyncClient;importio.modelcontextprotocol.client.transport.StdioClientTransport;importio.modelcontextprotocol.spec.McpSchema;importjava.util.Map;publicclassEnterpriseMcpClient{publicstaticvoidmain(String[] args){// 1. 创建 Transport,指向 Server 进程// ServerParameters 定义了要启动的子进程命令StdioClientTransport transport =StdioClientTransport.builder("java").args("-jar","enterprise-mcp-server.jar").build();// 2. 创建 ClientMcpSyncClient client =McpClient.sync(transport).clientInfo(newMcpSchema.Implementation("enterprise-client","1.0.0")).build();try{// 3. 建立连接,完成握手
client.initialize();System.out.println("已连接到 MCP Server");// 4. 发现工具McpSchema.ListToolsResult toolsResult = client.listTools();System.out.println("Server 提供了 "+ toolsResult.tools().size()+" 个工具:");for(McpSchema.Tool tool : toolsResult.tools()){System.out.println(" - "+ tool.name()+":"+ tool.description());}// 5. 调用工具:查年假McpSchema.CallToolResult leaveResult = client.callTool(newMcpSchema.CallToolRequest("getUserAnnualLeave",Map.of("employeeId","E001")));System.out.println("\n查年假结果:");for(McpSchema.Content content : leaveResult.content()){if(content instanceofMcpSchema.TextContent text){System.out.println(" "+ text.text());}}// 6. 调用工具:查订单McpSchema.CallToolResult orderResult = client.callTool(newMcpSchema.CallToolRequest("getOrderStatus",Map.of("orderId","ORD-20260301-001")));System.out.println("\n查订单结果:");for(McpSchema.Content content : orderResult.content()){if(content instanceofMcpSchema.TextContent text){System.out.println(" "+ text.text());}}}finally{// 7. 关闭连接
client.closeGracefully();System.out.println("\n连接已关闭");}}}运行输出:
已连接到 MCP Server
Server 提供了 2 个工具:
- getUserAnnualLeave:查询员工剩余年假天数,包括总天数、已使用天数、剩余天数
- getOrderStatus:查询订单的物流状态和详细信息
查年假结果:
员工 E001 的年假信息:总年假 15 天,已使用 10 天,剩余 5 天
查订单结果:
订单 ORD-20260301-001 状态:已发货,快递单号 SF1234567890,预计明天送达
连接已关闭整个流程和 HTTP 的请求-响应很像,只不过多了一个握手阶段。握手时双方交换能力声明——Server 告诉 Client 自己支持哪些功能(Tools?Resources?Prompts?),Client 也告诉 Server 自己支持哪些功能(比如是否支持 Sampling)。握手完成后才能正式通信。
在实际场景中,Server 端的工具列表可能会动态变化——比如运维人员通过管理后台新增了一个工具,或者某个工具因为故障被下线了。SDK 提供了 toolsChangeConsumer 来监听这种变化:
McpSyncClient client = McpClient.sync(transport)
.clientInfo(new McpSchema.Implementation("my-client", "1.0.0"))
.toolsChangeConsumer(tools -> {
System.out.println("工具列表已更新,当前工具数量:" + tools.size());
for (McpSchema.Tool tool : tools) {
System.out.println(" - " + tool.name());
}
})
.build();当 Server 端发出工具列表变更通知时,这个回调会被自动触发。在 Spring AI 注解方式中,这个监听是自动处理的,你不需要手动注册。
Server 需要主动发送通知,Client 才能感知到变化。如果 Server 端没有实现通知机制,这个回调不会触发。SDK 内部收到变更通知后会自动获取最新工具列表,然后传给回调。
Transport 机制详解
前面在架构分层里简单介绍了三种 Transport,这里展开说说它们各自的通信原理。
1. Stdio:进程间的传纸条
Stdio Transport 的原理最简单——两个进程之间通过标准输入输出传递消息:
- 发指令 (stdin): Host 通过标准输入流,向你的 Java 程序发送 JSON-RPC 请求(指令)。 注意:消息是一行一条,用换行符分隔。
- 回结果 (stdout): 你的 Java 程序处理完指令后,必须通过标准输出流,把 JSON-RPC 响应(结果)发回给 Host。 注意:同样是一行一条消息。
- 打日志 (stderr) —— 最重要的一点: 你的 Java 程序产生的调试信息、日志,必须走标准错误流 (stderr)。 图中红色便签特别强调:不要往 stdout 打日志! 否则 Host 会把你的日志当成指令去解析,导致通信崩溃。
优点是简单、安全(不暴露网络端口)。缺点是只能本地通信,而且进程的生命周期管理比较复杂——Host 要负责启动 Server 子进程、监控进程状态、在不需要时杀掉进程。
适合的场景:本地开发调试、Claude Desktop / Cursor 集成本地工具。
2. SSE:基于事件流的远程通信
SSE Transport 用于远程场景,通信走 HTTP 协议。和之前 SSE 系列文章里讲的一样,SSE 本身只支持服务端向客户端单向推送,所以 MCP 的 SSE Transport 实际上是两条路:
Client 先通过 GET 请求建立 SSE 长连接,Server 通过这条连接推送响应和通知。Client 发请求时走单独的 HTTP POST。
优点是基于标准 HTTP,穿越防火墙和反向代理方便,SSE 自带断线重连机制。缺点是 Client → Server 方向不是流式的,每次要发一个完整的 HTTP POST 请求。
3. Streamable HTTP:双向流式通信
Streamable HTTP 是 MCP 协议较新推出的传输方式,简化了 SSE Transport 的双通道架构:
- Client 的请求通过 HTTP POST 发送,响应体可以是普通 JSON(简单请求),也可以是 SSE 流(需要流式返回或服务器主动推送时)
- 不需要预先建立 SSE 长连接,按需建立连接
- Server 可以在响应头里返回 Session ID,Client 后续请求带上这个 ID 来关联会话
相比 SSE Transport,Streamable HTTP 更简洁——不需要维护一个额外的 SSE 长连接通道,每个 POST 请求的响应本身就可以是流式的。
这是 MCP 协议目前主推的远程传输方式,适合企业级生产环境部署。
Spring AI 与官方 SDK 的关系
1. 一张图看清层次
你用 Spring AI 写的 MCP Server,底层的依赖链条是这样的:
开发者直接面对的部分。你只需要声明式在 Java 方法上加上注解(如 @McpTool),告诉系统“这是一个工具”或“这是一个资源”。
Spring AI MCP Starter 层这是 Spring 官方提供的“增强包”。它负责把你在上层写的注解“翻译”成机器能懂的东西。自动扫描发现你的 @McpTool。自动把你的 Java 方法参数生成为 JSON Schema(让 AI 知道怎么调用你)。你的服务随 Spring Boot 生命周期绑定,不用手动管理进程
MCP Java SDK 层这是官方的底层库 (io.modelcontextprotocol.sdk)。Spring AI 其实是调用了这一层的 API 来干活的。
-
McpServer/McpClient:处理服务端或客户端逻辑。Transport:处理具体的传输方式(比如第一张图里的 Stdio,或者这里的 SSE、HTTP)。
底层通信层里面,这是物理层面的数据交换。所有的对象最终都被序列化成了 JSON-RPC 2.0 消息。 stdin/stdout 里传输的具体数据格式。
2. Spring AI 在 SDK 之上做了什么
具体来说,Spring AI MCP Starter 在官方 SDK 之上封装了三件事:
注解驱动的工具注册:扫描所有标注了 @McpTool / @McpResource / @McpPrompt 的 Bean 和方法,通过反射读取方法签名和注解属性,自动转换为 SDK 的 McpSchema.Tool / McpSchema.Resource / McpSchema.Prompt 对象,再调用 SDK 的 Builder API 注册到 Server 上。
自动配置 Transport:根据你引入的 Starter 依赖自动选择 Transport 实现:
| 引入的 Starter | 自动配置的 Transport |
|---|---|
spring-ai-starter-mcp-server | StdioServerTransportProvider |
spring-ai-starter-mcp-server-webmvc | HttpServletSseServerTransportProvider |
spring-ai-starter-mcp-server-webflux | WebFlux 版 Transport |
Spring Boot 生命周期管理:Server 的启动和关闭与 Spring 容器的生命周期绑定——容器启动时自动构建并启动 MCP Server,容器关闭时自动优雅关闭 Server。你不需要手动写 server.build() 和 server.closeGracefully()。
大多数 Java 项目直接用 Spring AI 就够了——省事,约定优于配置,和 Spring Boot 生态无缝集成。



Comments NOTHING