


大模型的五大局限性
- 幻觉问题:一本正经地胡说八道,生成看起来很合理、但实际上完全错误的内容。
- 知识时效性:活在过去,知识是冻结在训练截止日期的。
- 专业领域深度不足,专业内容相对有限,模型对垂直领域的理解远不如领域专家。
- 大模型是在公开数据上训练的,它无法访问:内部文档和私有信息
- 大模型的回答是不可追溯来源的
RAG检索增强生成
先查资料,再回答,
- 1.把公司的产品文档数据存到一个能理解语义的知识库里;
- 2.用户提问时,先从知识库检索相关内容;
- 3.把检索到的内容和用户问题一起发给大模型;
- 4.大模型基于这些参考资料来回答。
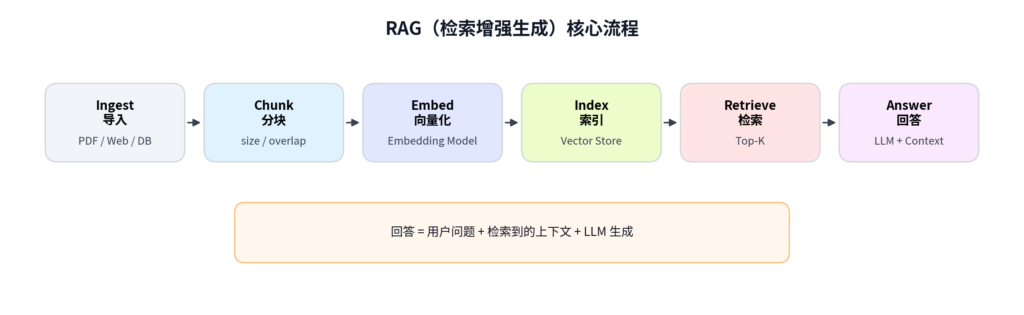
全链路图:ingest → chunk → embed → index → retrieve → answer。
Ingest:把数据导进来
不同格式用不同的解析方式:PDF 要提取文字,Word 要读取内容,网页要爬取并清洗。
Chunk:把长文档切成小块
常见做法是 500-1000 字一块,相邻块之间有一定重叠(比如重叠 100 字),防止重要信息正好被切断。
Embed:把文字变成向量
这步是整个 RAG 的核心。把文字转成向量。
向量就是一串数字,比如 [0.23, -0.45, 0.67, ...]。这串数字编码了这段文字的语义信息,意思相近的文字,向量在空间中的距离也近。
这个转换由专门的 Embedding 模型完成,比如 Qwen3 的 Qwen3-Embedding-8B,或者开源的 bge、m3e。
Index:存进向量数据库
向量数据库专门存向量,做相似度搜索——给一个向量,找出距离最近的 N 个。
常见的向量数据库有 Milvus、Pinecone、Weaviate,轻量级的有 Faiss、Chroma。
以 Milvus 作为示例工具进行讲解与演示。
存的时候,向量和原文要一起存。后面检索出来,得把原文拿给大模型看。同时还要有元数据(简单理解是个 JSON)的概念,方便检索时进行筛选精准数据。
Retrieve:检索相关内容
用户提问了,比如"打印机墨盒怎么换"。
这时候做两件事:
- 1.把用户问题也转成向量;
- 2.拿这个向量去向量数据库搜,找出最相似的几个文档块。
Answer:大模型生成回答
最后一步,把检索到的内容和用户问题打包发给大模型。
大模型看到这些资料,就能给出准确的回答,而不是自己编。
| 阶段 | 步骤 | 做什么 |
|---|---|---|
| 准备阶段(离线) | Ingest | 导入原始文档 |
| Chunk | 切成小块 | |
| Embed | 转成向量 | |
| Index | 存进向量数据库 | |
| 运行阶段(在线) | Retrieve | 检索相关文档 |
| Answer | 大模型生成回答 |
优点:相对微调成本低,上手快,知识更新方便,答案可追溯
缺点:效果看知识库质量,链式系统复杂,检索比较耗时
但是rag非常麻烦啊,
用Apache Tika解析文档
同样是 .pdf 后缀,内部结构可能完全不同:
- 文字型 PDF:内部存储的是文字编码,可以直接提取。
- 扫描型 PDF:内部存储的是图片,文字只是“画”上去的。
- 混合型 PDF:部分页是文字,部分页是扫描图。
一份 .docx 文件,打开看起来就是几段文字。表格被拆成了莫名其妙的换行。页眉页脚混进了正文,多余的空行和空格。文档属性(作者、创建时间)你根本没拿到。你在学校拿word写论文也是这样的
还有故意混淆的编码问题,中文乱码编码问题
你需要一个工具:
- 能自动识别文件的真实类型(不靠后缀)
- 能处理几十种文档格式(PDF、Word、PPT、Excel、HTML、邮件...)
- 能提取文本内容。
- 能提取元数据(作者、创建时间、标题...)
- 能处理编码问题。
- 能对接 OCR(处理扫描件)
- 最好是开源免费的。
这个工具就是 Apache Tika。专门用于内容检测和内容提取,支持 1000+ 种 MIME 类型
元数据(Metadata)是“关于数据的数据”,描述文档本身的属性。
常见的元数据:
| 字段 | 说明 | 示例 |
|---|---|---|
Content-Type | MIME 类型 | application/pdf |
title | 文档标题 | 2024年度报告 |
creator | 作者/创建者 | 张三 |
created | 创建时间 | 2024-01-15T10:30:00 |
modified | 修改时间 | 2024-03-20T14:00:00 |
pageCount | 页数 | 15 |
wordCount | 字数 | 5000 |
添加 Tika 依赖,在 pom.xml 中添加:
<dependencies>
<!-- Spring Boot Web -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- Apache Tika 核心 -->
<dependency>
<groupId>org.apache.tika</groupId>
<artifactId>tika-core</artifactId>
<version>${tika.version}</version>
</dependency>
<!-- Apache Tika 解析器(包含各种格式支持) -->
<dependency>
<groupId>org.apache.tika</groupId>
<artifactId>tika-parsers-standard-package</artifactId>
<version>${tika.version}</version>
</dependency>
</dependencies>Tika 选择嵌入式还是独立部署运行
更适合嵌入式的场景:
- 课程/作业/小项目:就一个 Spring Boot 服务,上传一些 doc/pdf,规模不大
- 部署环境简单:不想多维护一个容器服务
- 解析量不高:偶尔解析、文件不大、并发低
更适合 Tika Server 独立部署的场景:
- 你在做 知识库入库/RAG 数据准备:大量文件、批处理、并发高
- 文件来源更“野”:各种 PDF(含扫描件)、各种 Office、各种编码
- 你希望解析失败/卡死不影响主业务:把解析从业务进程剥离
- 你有多种语言/多个服务要复用同一套解析能力
| 维度 | 嵌入 Spring Boot(依赖库) | 单独部署(Tika Server) |
|---|---|---|
| 上手成本 | ✅ 最快:加依赖写代码就能跑 | ⚠️ 多一步:起容器 + 配服务地址 |
| 依赖/体积 | ⚠️ 依赖树大,fat jar 变大;可能遇到依赖冲突 | ✅ 依赖都在容器里,应用更“干净” |
| OCR/系统依赖 | ⚠️ OCR、字体、图像库等可能需要装系统包,环境差异多 | ✅ 镜像通常把 OCR 等打包好了,环境一致 |
| 资源隔离(CPU/内存) | ⚠️ 解析大文件很吃内存/CPU,可能拖慢甚至打挂你的业务进程 | ✅ 解析吃资源在容器里;Tika 挂了业务不一定跟着挂(可重启/限额) |
| 安全隔离(不可信文件) | ⚠️ 风险直接进你的业务 JVM | ✅ 解析“危险面”隔离到独立服务更合理;但仍要做版本升级/限制策略 |
| 扩展性 | ⚠️ 每个业务实例都要带一份解析能力,横向扩展成本高 | ✅ 多个业务共享一组 Tika;可以单独水平扩容 |
| 性能 | ✅ 少一次网络传输,延迟更低 | ⚠️ 多一次 HTTP 传输(但局域网一般可接受);吞吐可靠扩容补 |
| 多语言/多项目复用 | ⚠️ 主要服务于 Java 项目 | ✅ 任意语言都能 HTTP 调,复用性强 |
| 运维复杂度 | ✅ 少一个组件 | ⚠️ 多一个组件(监控、日志、限流、鉴权等) |
编写文档解析服务
2.1 创建解析结果 DTO
/**
* 文档解析结果
*/@Setter@GetterpublicclassParseResult{/**
* 是否解析成功
*/privateboolean success;/**
* 检测到的 MIME 类型
*/privateString mimeType;/**
* 提取的文本内容
*/privateString content;/**
* 提取的元数据
*/privateMap<String, String> metadata;/**
* 文本长度(字符数)
*/privateint contentLength;/**
* 错误信息(如果失败)
*/privateString errorMessage;// 静态工厂方法publicstaticParseResultsuccess(String mimeType,String content,Map<String, String> metadata){ParseResult result =newParseResult();
result.setSuccess(true);
result.setMimeType(mimeType);
result.setContent(content);
result.setContentLength(content !=null? content.length():0);
result.setMetadata(metadata);return result;}publicstaticParseResultfailure(String errorMessage){ParseResult result =newParseResult();
result.setSuccess(false);
result.setErrorMessage(errorMessage);return result;}}2.2 创建 Tika 解析服务
@Slf4j@ServicepublicclassTikaParseService{/**
* Tika 实例(用于简单操作,如 MIME 检测)
*/privatefinalTika tika =newTika();/**
* 自动检测解析器
*/privatefinalParser parser =newAutoDetectParser();/**
* 最大文本长度限制(-1 表示无限制,但可能导致内存问题)
* 这里设置为 10MB 字符
*/privatestaticfinalintMAX_TEXT_LENGTH=10*1024*1024;/**
* 解析文件,提取文本和元数据
*
* @param file 上传的文件
* @return 解析结果
*/publicParseResultparseFile(MultipartFile file){// 1. 基本校验if(file ==null|| file.isEmpty()){returnParseResult.failure("文件为空");}String originalFilename = file.getOriginalFilename();
log.info("开始解析文件: {}, 大小: {} bytes", originalFilename, file.getSize());try(InputStream inputStream = file.getInputStream()){// 2. 检测 MIME 类型// 注意:这里需要重新获取流,因为检测会消费流String mimeType;try(InputStream detectStream = file.getInputStream()){
mimeType = tika.detect(detectStream, originalFilename);}
log.info("检测到 MIME 类型: {}", mimeType);// 3. 准备解析器组件// BodyContentHandler: 用于接收解析出的文本内容// 参数 MAX_TEXT_LENGTH 限制最大文本长度,防止内存溢出BodyContentHandler handler =newBodyContentHandler(MAX_TEXT_LENGTH);// Metadata: 用于存储元数据Metadata metadata =newMetadata();// 设置文件名,帮助解析器识别
metadata.set(TikaCoreProperties.RESOURCE_NAME_KEY, originalFilename);// ParseContext: 解析上下文,可以配置额外选项ParseContext context =newParseContext();// 4. 执行解析try(InputStream parseStream = file.getInputStream()){
parser.parse(parseStream, handler, metadata, context);}// 5. 获取解析结果String content = handler.toString();// 6. 清洗文本(去除多余空白)
content =cleanText(content);// 7. 提取元数据Map<String, String> metadataMap =extractMetadata(metadata);// 8. 检查解析质量if(content.isEmpty()){
log.warn("文件 {} 解析结果为空,可能是扫描件或加密文档", originalFilename);returnParseResult.failure("解析结果为空,可能是扫描件或加密文档");}
log.info("文件 {} 解析成功,提取文本长度: {}", originalFilename, content.length());returnParseResult.success(mimeType, content, metadataMap);}catch(IOException e){
log.error("读取文件失败: {}", originalFilename, e);returnParseResult.failure("读取文件失败: "+ e.getMessage());}catch(TikaException e){
log.error("Tika 解析失败: {}", originalFilename, e);returnParseResult.failure("文档解析失败: "+ e.getMessage());}catch(SAXException e){
log.error("XML 解析失败: {}", originalFilename, e);returnParseResult.failure("文档结构解析失败: "+ e.getMessage());}catch(Exception e){
log.error("未知错误: {}", originalFilename, e);returnParseResult.failure("解析过程中发生未知错误: "+ e.getMessage());}}/**
* 仅检测文件的 MIME 类型
*
* @param file 上传的文件
* @return MIME 类型字符串
*/publicStringdetectMimeType(MultipartFile file)throwsIOException{try(InputStream inputStream = file.getInputStream()){return tika.detect(inputStream, file.getOriginalFilename());}}/**
* 清洗文本内容
* - 将多个连续空白字符替换为单个空格
* - 将多个连续换行替换为最多两个换行(保留段落)
* - 去除首尾空白
*/privateStringcleanText(String text){if(text ==null){return"";}return text
// 将 \r\n 统一为 \n.replaceAll("\\r\\n","\n")// 将 \r 统一为 \n.replaceAll("\\r","\n")// 去除每行首尾的空格.replaceAll("(?m)^[ \\t]+|[ \\t]+$","")// 将 3 个及以上连续换行替换为 2 个换行.replaceAll("\\n{3,}","\n\n")// 将多个连续空格/制表符替换为单个空格.replaceAll("[ \\t]+"," ")// 去除首尾空白.trim();}/**
* 从 Metadata 对象提取元数据为 Map
*/privateMap<String, String>extractMetadata(Metadata metadata){Map<String, String> result =newHashMap<>();for(String name : metadata.names()){String value = metadata.get(name);if(value !=null&&!value.isEmpty()){
result.put(name, value);}}return result;}}2.2.1 核心代码解释
BodyContentHandler:
BodyContentHandler handler =newBodyContentHandler(MAX_TEXT_LENGTH);这是 Tika 的 SAX 内容处理器,负责接收解析器输出的文本。参数是最大字符数限制,超过会抛出异常。设为 -1 表示无限制(危险,可能 OOM)。
Metadata:
Metadata metadata =newMetadata();
metadata.set(TikaCoreProperties.RESOURCE_NAME_KEY, originalFilename);Metadata 对象会在解析过程中被填充。提前设置文件名可以帮助解析器做更准确的判断。
AutoDetectParser:
Parser parser =newAutoDetectParser();
parser.parse(inputStream, handler, metadata, context);AutoDetectParser 会自动根据 MIME 类型选择合适的底层解析器(PDF 用 PDFParser,Word 用 OOXMLParser 等)。
2.3 创建 Controller
@RestController@RequestMapping("/api/document")publicclassDocumentController{@AutowiredprivateTikaParseService tikaParseService;/**
* 解析上传的文档,返回文本和元数据
*
* POST /api/document/parse
* Content-Type: multipart/form-data
*/@PostMapping(value ="/parse", consumes =MediaType.MULTIPART_FORM_DATA_VALUE)publicResponseEntity<ParseResult>parseDocument(@RequestParam("file")MultipartFile file){ParseResult result = tikaParseService.parseFile(file);if(result.isSuccess()){returnResponseEntity.ok(result);}else{returnResponseEntity.badRequest().body(result);}}/**
* 仅检测文件的 MIME 类型
*
* POST /api/document/detect
* Content-Type: multipart/form-data
*/@PostMapping(value ="/detect", consumes =MediaType.MULTIPART_FORM_DATA_VALUE)publicResponseEntity<Map<String, String>>detectMimeType(@RequestParam("file")MultipartFile file){try{String mimeType = tikaParseService.detectMimeType(file);Map<String, String> response =newHashMap<>();
response.put("filename", file.getOriginalFilename());
response.put("mimeType", mimeType);
response.put("size",String.valueOf(file.getSize()));returnResponseEntity.ok(response);}catch(IOException e){Map<String, String> error =newHashMap<>();
error.put("error","无法检测文件类型: "+ e.getMessage());returnResponseEntity.badRequest().body(error);}}}2.4 配置文件上传限制
在 src/main/resources/application.yml 中:
spring:application:name: tika-demo
servlet:multipart:# 单个文件最大大小max-file-size: 50MB
# 整个请求最大大小max-request-size: 50MB
server:port:80802.5 主启动类
@SpringBootApplicationpublicclassTika3xApplication{publicstaticvoidmain(String[] args){SpringApplication.run(Tika3xApplication.class, args);}}3. 验证与测试
3.1 使用 curl 测试
测试 MIME 检测:
# 创建一个测试文件
echo "Hello World"> test.txt
# 检测类型
curl -XPOST \
-F"file=@test.txt" \
http://localhost:8080/api/document/detect输出:
{"filename":"test.txt","mimeType":"text/plain","size":"12"}测试文档解析:
# 解析文本文件
curl -XPOST \
-F"file=@test.txt" \
http://localhost:8080/api/document/parse输出:
{"success":true,"mimeType":"text/plain","content":"Hello World","metadata":{"X-TIKA:Parsed-By":"org.apache.tika.parser.DefaultParser","X-TIKA:Parsed-By-Full-Set":"org.apache.tika.parser.DefaultParser","Content-Encoding":"ISO-8859-1","resourceName":"test.txt","X-TIKA:detectedEncoding":"ISO-8859-1","X-TIKA:encodingDetector":"UniversalEncodingDetector","Content-Type":"text/plain; charset=ISO-8859-1"},"contentLength":11,"errorMessage":null}测试解析 PDF(如果你有的话):
curl -XPOST \
-F"file=@your-document.pdf" \
http://localhost:8080/api/document/parse3.2 使用 Postman 或 ApiFox 测试
- 1.打开 API 测试工具,创建新请求
- 2.方法选择
POST - 3.URL 输入
http://localhost:8080/api/document/parse - 4.选择
Body→form-data - 5.Key 输入
file,类型选择File - 6.Value 选择你要上传的文件
- 7.点击
Send
数据分块Chunk策略
由于大模型的上下文窗口限制,检索精度的问题,我们接下来要分块,纯文本只是原材料,还不能直接用于检索。分块是紧接着文本提取之后的一步,它把长文本切成适合检索的小段。把每个文本块转成一组数字(向量),方便计算机做相似度检索。
几个关键参数:chunkSize、overlap
在动手切之前,有两个参数你必须搞清楚:chunkSize(块大小)和 overlap(重叠量)。
chunkSize 就是每个块的长度上限。比如你设 chunkSize = 200,意思是每个块最多包含 200 个字符,没有标准答案
overlap(重叠)是指相邻两个块之间共享的文本长度。帮你保持了上下文的连贯性。不加 overlap,相邻块的边界处一定会丢失上下文。如果用户恰好问的问题涉及到边界处的内容,检索就可能找不到完整的答案。
1. 固定大小分块(Fixed Size Chunking)
1.1 原理
这是最简单粗暴的方式:不管文本内容是什么,每隔固定数量的字符就切一刀。
假设 chunkSize = 100,overlap = 0,上面那段示例文本会被100个字的切
优缺点
| 维度 | 说明 |
|---|---|
| 优点 | 实现极其简单,性能好,不需要任何 NLP 处理 |
| 缺点 | 完全忽略文本结构,容易把句子、段落从中间切断,导致语义不完整 |
| 适合 | 文本结构不重要的场景,比如日志文件、纯数据文本;或者作为其他策略的兜底方案 |
| 不适合 | 有明确段落结构的文档(知识库、产品手册、政策文件),因为切断语义会严重影响检索质量 |
2. 重叠分块(Overlapping Chunking)
重叠分块是对固定大小分块的直接改进。核心思路很简单:切块的时候,相邻两个块之间留一段重叠区域,这样即使切割点落在句子中间,重叠部分也能保证关键信息不会被完全切断。
| 维度 | 说明 |
|---|---|
| 优点 | 实现简单,有效缓解边界处的语义断裂问题 |
| 缺点 | 仍然不看文本内容,只是用重叠来弥补;overlap 会导致存储量增加 |
| 适合 | 大多数通用场景的入门方案,尤其是你还没确定用什么策略的时候 |
| 不适合 | 对语义完整性要求很高的场景,比如法律条款、合同文本 |
递归分块(Recursive Chunking)
递归分块是目前实践中最常用的策略。它的思路可以用一句话概括:先尝试用最大的分隔符切,切完如果某个块还是太大,就换一个更小的分隔符继续切,直到所有块都在 chunkSize 以内。
具体来说,它维护一个分隔符列表,按优先级从高到低排列,比如:
["\n\n", "\n", "。", ",", " ", ""]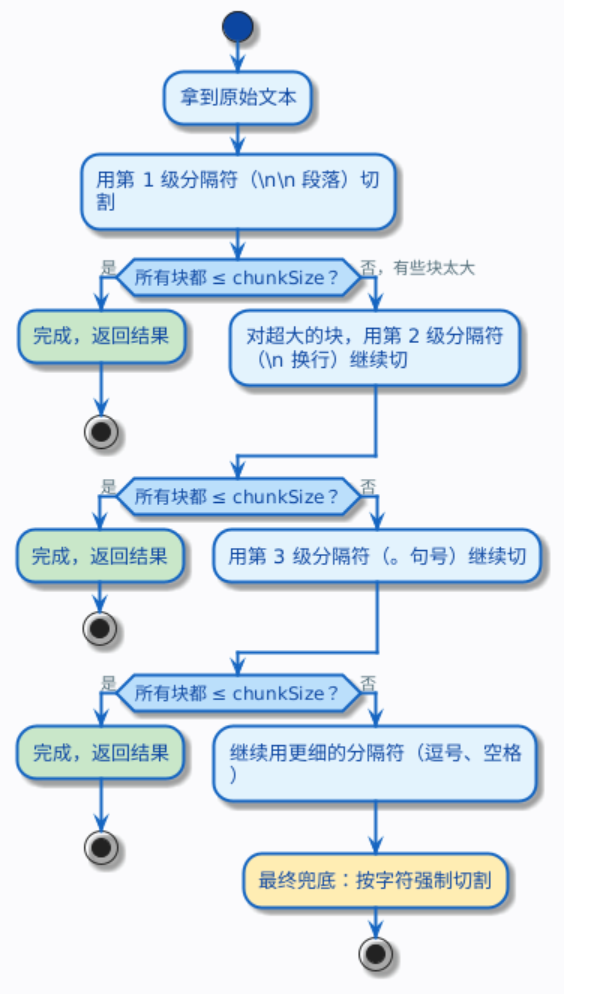
这个先粗后细的过程就是递归的含义——不是一刀切到底,而是逐层细化。
为什么这种方式好?因为它尽最大努力保留文本的结构。能按段落切就按段落切,段落太长了才按句子切,句子还太长才按逗号切……只有在万不得已的时候才会像固定大小分块那样按字符硬切。
拿我们的电商知识库来说,如果 chunkSize 设成 200,递归分块会先尝试按章节(空行)切割。退货政策那一段大约 150 字,没超过 200,就完整保留为一个块。如果某个章节特别长超过了 200 字,才会进一步按句号切成更小的块。
| 维度 | 说明 |
|---|---|
| 优点 | 兼顾了语义完整性和块大小控制,是目前最通用的分块策略 |
| 缺点 | 分隔符列表需要根据语言调整(中文和英文的标点不同);依赖文本中存在合理的分隔符 |
| 适合 | 绝大多数场景,尤其是你不确定该用什么策略的时候,递归分块是最安全的默认选择 |
| 不适合 | 对分块有特殊要求的场景,比如代码文件(需要按函数/类来切)、表格数据(需要按行来切) |
语义分块(Semantic Chunking)
语义分块换了一个完全不同的思路:用 Embedding 模型来判断文本的语义相似度,在语义发生明显变化的地方切割。
具体过程是这样的: 先把文本按句子拆开(这一步可以简单地按句号切)对每个句子生成一个向量(Embedding)计算相邻句子之间的向量相似度 .当相邻句子的相似度低于某个阈值时,说明话题发生了转换,在这里切一刀
最直接的思路:把文本交给大模型,让它找出主题切换的位置。
对比 Embedding vs LLM 分块:
| 维度 | Embedding 语义分块 | LLM 辅助分块 |
|---|---|---|
| 原理 | 计算相邻句子的向量相似度 | 大模型直接理解文本语义 |
| 分块质量 | 依赖 Embedding 模型质量 | 通常更准确,能处理复杂语境 |
| 速度 | 快(毫秒级) | 慢(秒级) |
| 成本 | 低 | 高 |
| 适用场景 | 大批量文档处理 | 高价值文档、需要精细分块 |
| 维度 | 说明 |
|---|---|
| 优点 | 切割点基于语义而非规则,分块质量最高,每个块的主题高度内聚 |
| 缺点 | 需要调用 Embedding 或者 Chat 模型,有额外的计算成本和延迟;阈值需要调参;对模型的质量有依赖 |
| 适合 | 对检索精度要求很高的场景,比如法律文档问答、医疗知识库、金融合规文档 |
| 不适合 | 文档量特别大且对延迟敏感的场景;文本本身结构已经很清晰的场景(用递归分块就够了,没必要上语义分块) |
5. 混合分块(Hybrid Chunking)
实际项目中,单一的分块策略往往不够用。不同类型的文档、甚至同一份文档的不同部分,可能适合不同的分块方式。混合分块的思路就是:把多种策略组合起来用,取长补短。
常见的组合方式有几种:
第一种,递归分块 + 语义分块。先用递归分块做粗切,把文本按段落、章节切成大块;然后对每个大块再用语义分块做细切,确保每个最终的块在语义上是内聚的。
第二种,按文档类型选策略。比如在一个企业知识库系统中,产品手册用递归分块,FAQ 用按问答对切割,合同文本用语义分块。在代码层面,就是一个路由逻辑,根据文档的类型或来源选择不同的分块器。
第三种,分块 + 后处理。先用递归分块切完,然后对结果做一轮后处理:合并太短的块、拆分太长的块、给每个块补充元数据(比如所属章节标题、文档来源)。
拿我们的电商知识库来说,一个实际的混合方案可能是这样的:
- 知识库正文(退货政策、物流规则等):用递归分块,按章节切割
- FAQ 问答对:按问答对切割,每个 Q&A 是一个块
- 商品详情页:先提取结构化字段(价格、规格),再对描述文本用重叠分块
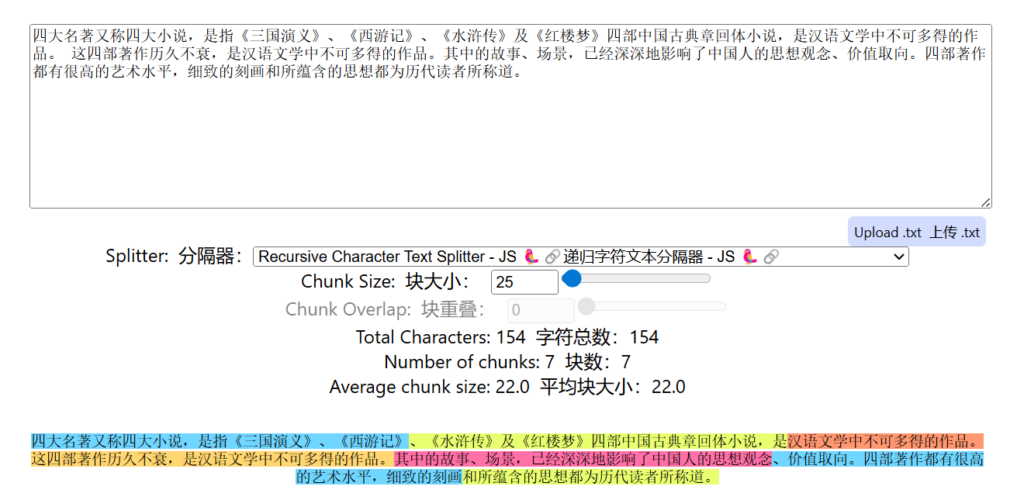
一个实用的调参思路:从 chunkSize=500、overlap=50 开始,跑几个测试 query 看检索效果,如果发现检索结果不够精准就调小 chunkSize,如果发现上下文经常断裂就调大 overlap。
真实项目里,分块效果不好,往往不只是 chunkSize 没调对,还有可能是上游抽取出来的文本就已经“脏”了 ——尤其是 PDF 这种格式:
- 页眉页脚、目录、页码混进正文,语义被大量噪音稀释
- 断行/连字把一句话拆成多段,导致按段落/句子递归分割失效
- 表格被打散成碎词或错位字段,检索命中但无法形成可读上下文
所以通常不会“抽完就切”。更稳妥的流程是:先用Tika等工具做文本抽取→再用清洗器做结构修复与去噪→最后才进入分块与向量化 。
分块层面也有类似的现实问题。像 Dify、RAGFlow 这类标准 RAG 方案,很多时候依赖单一分块策略,调参就容易出现“顾此失彼”:chunkSize 调大,A 类问题更容易召回完整上下文,但 B 类问题的检索精度可能下降;chunkSize 调小,B 类问题更精准了,A 类问题又容易被切断。
针对中小规模文档 ,更实用的做法是:先用基础策略把文档拆成初稿块,然后在此基础上做一轮人工二次编排 ——根据相邻块的语义关系进行补齐、合并或重分配,让最终的 chunk 更贴合真实问题类型。



Comments NOTHING