


这篇文章的内容主要围绕作者为项目 oneThread 选型前端框架的心路历程展开,并横向点评了五款市面上主流的 Vue 3 后台管理脚手架(Admin Templates)。
1. 核心决策:为什么最终选择了 Vben Admin?
作者在开篇明确了最终的选择是 Vben Admin,并给出了四个非常务实的理由,这也是企业级项目中选型的典型考量标准:
- 生态与功能(实用性): 强调功能覆盖面广。Vben 是目前 Vue 3 生态中功能最全的“巨无霸”型框架之一(动态路由、权限、Mock、国际化等一应俱全),能极大减少重复造轮子的时间。
- UI 风格(商业性): 选择了 Ant Design Vue。相比于 Element UI 的通用感,Ant Design 的设计语言更偏向严谨的“企业级”风格,非常适合 B 端复杂的后台系统。
- 类型系统(维护性): 强调 TS (TypeScript) 的支持。对于长期维护的大型项目,完善的 TS 类型定义是代码质量和协作效率的保障。
- 颜值(主观体验): 作者自称“颜控”,认为 Vben 的默认 UI 设计审美在线。
2. 竞品横向对比(五大脚手架点评)
作者根据“颜值”和“技术栈”对五款框架进行了排序和介绍。以下是更深度的技术视角解读:
第一梯队:作者最认可(颜值与功能并重)
- Vben Admin
- 特点: 基于 Vue 3 + Vite + TS + Ant Design Vue。
- 评价: 最现代化的解决方案,配置化程度极高(既是优点也是缺点,上手曲线较陡峭),适合需要快速落地且功能复杂的重型后台项目。
- Vuestic Admin
- 特点: 基于 Vuestic UI。
- 评价: 胜在“差异化”。Vuestic UI 的设计风格非常独特,色彩丰富,不像传统的后台那么死板。如果你想做一个看起来不那么像“传统ERP”的系统,这是一个很好的选择。
第二梯队:风格鲜明
- materio-vuetify-vuejs-admin-template-free
- 特点: 基于 Vuetify 3 (Material Design 风格)。
- 评价: Material Design 是 Google 的设计语言,交互动效强,但在国内企业级市场接受度不如 AntD 和 Element 高。这款适合面向国际用户的项目或喜欢 MD 风格的开发者。
第三梯队:轻量与现代
- Naive Ui Admin
- 特点: 基于 Naive UI。
- 评价: Naive UI 是 Vue 3 时代的“网红”组件库,以轻量、高性能和优秀的 TS 支持著称。相比 Vben,这个模板可能更轻量一些,更适合不喜欢过度封装、希望从轻开始搭建的开发者。
第四梯队:传统稳健(颜值排名垫底)
- vue-admin-better
- 特点: 基于 Element UI (Vue 2/3 混用或过渡)。
- 评价: 这是一个非常经典的“老牌”风格。Element UI 在国内统治力很强,但这套模板的设计感相对陈旧。它的优势在于稳和开箱即用,适合对审美要求不高、追求快速交付或团队习惯 Element 体系的项目。
3. 作者的“颜值”排序逻辑
作者给出的排序是:vue-admin-better < Naive Ui Admin < materio < Vben = Vuestic
这个排序反映了前端 UI 设计趋势的变化:
- 底层: 传统的 Element 风格(功能主义,视觉略显平庸)。
- 中层: 新兴的极简主义(Naive UI)和 动效丰富的 Material Design(Vuetify)。
- 顶层: 高级感的企业设计(Vben/AntD)和 高定制化的现代设计(Vuestic)。
- 如果你要做重型、复杂的企业中台,且团队熟悉 TS,Vben Admin 是首选(也是作者的选择)。
- 如果你追求极简、轻量,或者想自己把控更多代码逻辑,Naive Ui Admin 值得尝试。
- 如果你需要国际化风格或对 Google 设计语言情有独钟,选 Vuetify 系列。
- 如果你要求稳,或者团队成员技术栈较老,vue-admin-better 依然是安全牌。
oneThread与普通线程池性能测试
这是一个非常硬核且具有实战价值的性能测试案例。为了让你彻底理解“动态线程池”与“普通线程池”的性能差异,以及这段代码背后的测试逻辑,我将结合你提供的 项目目录结构 和 测试文章内容,分三个部分为你通透讲解。
这是第一部分,我们将聚焦于 核心原理分析与潜在的性能瓶颈点。
第一部分:动态线程池性能测试——原理与瓶颈分析
1. 为什么要测这个?(背景与冲突)
面试官问“动态线程池和普通线程池的性能有没有区别”,本质上是在问:引入了监控、告警、动态配置这些“外挂”功能后,会不会拖慢业务线程执行任务的速度?
- 普通线程池 (
ThreadPoolExecutor):专注于任务执行,逻辑纯粹。 - 动态线程池 (
OneThreadExecutor/ Wrapper):在原生基础上加了“装饰器”。
我们必须深入源码层面,看看这些“装饰器”到底加在哪里,以及它们是否在“关键路径”上。
2. 潜在的性能瓶颈点(结合代码目录)
动态线程池引入了以下三个主要功能,它们是潜在的性能杀手:
A. 监控采集 (ThreadPoolMonitor)
- 代码位置:
core/.../monitor/ThreadPoolMonitor.java - 功能:定时采集核心指标(如
ActiveCount,QueueSize)。 - 性能风险点:
文章中非常敏锐地提到了getActiveCount()。在 JDK 的ThreadPoolExecutor源码中:java public int getActiveCount() { final ReentrantLock mainLock = this.mainLock; mainLock.lock(); // 【关键瓶颈】这里加了全局锁! try { // ... 遍历 Worker 统计 } finally { mainLock.unlock(); } } private void micrometerMonitor(ThreadPoolRuntimeInfo runtimeInfo) { // 采集核心指标 Metrics.gauge(metricName("core.size"), tags, registerRuntimeInfo, ThreadPoolRuntimeInfo::getCorePoolSize); Metrics.gauge(metricName("active.size"), tags, registerRuntimeInfo, ThreadPoolRuntimeInfo::getActivePoolSize); // ... 还有很多其他指标 }- 这里有个细节需要注意:
getActiveCount()、getPoolSize()这些方法在 JDK 源码里是加锁的。翻了下ThreadPoolExecutor的源码:public int getActiveCount() { final ReentrantLock mainLock = this.mainLock; mainLock.lock(); // 这里会加锁! try { int n = 0; for (Worker w : workers) if (w.isLocked()) ++n; return n; } finally { mainLock.unlock(); } }
深度解析:如果你的监控采集频率非常高(例如每 10ms 一次),或者告警检查非常频繁,这个mainLock就会频繁被持有。而线程池提交新任务(execute)或销毁线程时,也常常需要获取mainLock。监控线程和业务线程会产生锁竞争。
B. 告警检查 (ThreadPoolAlarmChecker)
- 代码位置:
core/.../alarm/ThreadPoolAlarmChecker.java - 功能:定期检查队列是否满了,线程是否不够用了。
- 性能风险点:
同上,检查队列水位和活跃度时,依然会调用 JDK 的底层方法。如果项目中有几百个线程池,这个Checker每次循环都会挨个获取锁,会对系统造成 CPU 脉冲压力。
private void checkAlarm() {
Collection<ThreadPoolExecutorHolder> holders = OneThreadRegistry.getAllHolders();
for (ThreadPoolExecutorHolder holder : holders) {
if (holder.getExecutorProperties().getAlarm().getEnable()) {
checkQueueUsage(holder); // 检查队列
checkActiveRate(holder); // 检查活跃度
checkRejectCount(holder); // 检查拒绝次数
}
}
}C. 拒绝策略包装 (RejectedExecutionHandler)
- 代码位置:
core/.../executor/support/RunnableWrapper.java或动态代理逻辑 - 功能:为了统计“拒绝次数”,对原生拒绝策略进行了包装(Wrapper)。
java new RejectedExecutionHandler() { @Override public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) { rejectCount.incrementAndGet(); // 额外操作:CAS 自增 handler.rejectedExecution(r, executor); // 原生操作 } }; - 性能风险点:这个影响极小。只有在任务被拒绝时才会触发,而且
AtomicLong.incrementAndGet()是 CAS 操作,纳秒级开销,基本可以忽略。
@Override
public void setRejectedExecutionHandler(RejectedExecutionHandler handler) {
RejectedExecutionHandler handlerWrapper = new RejectedExecutionHandler() {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
rejectCount.incrementAndGet(); // 计数
handler.rejectedExecution(r, executor);
}
};
super.setRejectedExecutionHandler(handlerWrapper);
}3. 架构设计的“解耦”智慧
为了避免上述瓶颈拖垮业务,作者在架构图(PlantUML)中展示了一个关键设计:异步化。
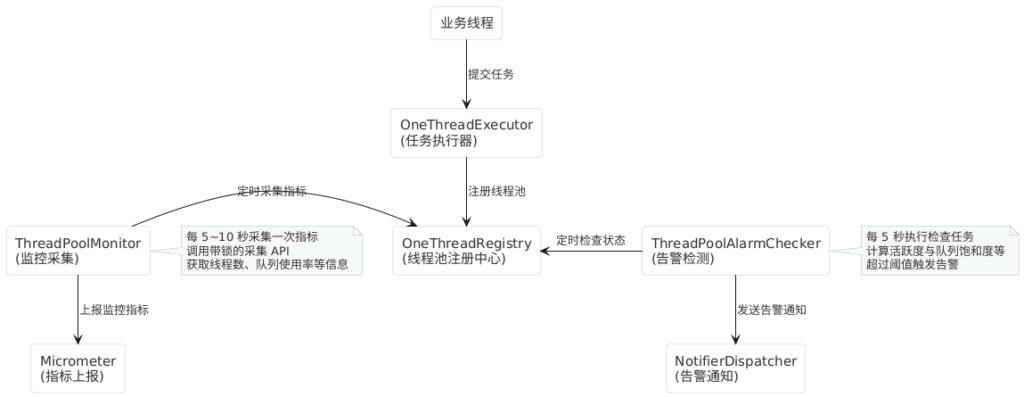
- 业务线程(提交任务):
- 走
OneThreadExecutor->JDK ThreadPoolExecutor。 - 关键点:除了拒绝策略稍微包了一层,业务提交任务的主流程(Happy Path)没有任何额外的锁或阻塞逻辑。
- 走
- 管理线程(监控与告警):
- 由
ThreadPoolMonitor和ThreadPoolAlarmChecker负责。 - 关键点:它们是独立的定时任务(Scheduled Thread),与处理业务的线程池是物理隔离的。
- 由
结论预判:只要监控采集的频率(Interval)不是极高(比如 < 100ms),它对主流程的影响仅仅是偶尔抢占一下 mainLock,对 TPS(吞吐量)的影响应该是微乎其微的。
第二部分:测试方案设计的深度解析
既然理论上影响不大,怎么用代码证明?作者放弃了 JMH,选择了基于 Spring Boot 的实战压测,这个选择非常精明。
1. 为什么不用 JMH?
JMH (Java Microbenchmark Harness) 是做基准测试的神器,但它通常是方法级的微基准测试。
- 缺陷:JMH 运行在隔离环境中,默认不会启动 Spring 容器。
- 本例需求:动态线程池依赖 Spring 的
BeanPostProcessor进行注册(参考目录spring-base/.../processor/OneThreadBeanPostProcessor.java),依赖 Nacos/Apollo 的监听器(参考starter/.../listener)。 - 决策:必须在 Spring Boot 启动后的真实环境中测,才能包含定时任务、事件监听等后台线程的开销。
2. 核心测试代码解析 (ThreadPoolPerformanceTestController)
这段测试代码写得非常标准,使用了 CountDownLatch 闭锁模式 来模拟高并发。我们逐行拆解其核心逻辑:

A. 预热(Warm-up)—— 至关重要
warmUp(normalPool, 1000, taskDuration);
warmUp(onethreadProducer, 1000, taskDuration);
Thread.sleep(3000);- 目的:
- 类加载:确保相关类已被 ClassLoader 加载。
- JIT 编译:让 JVM 的 C2 编译器介入,将热点代码编译为机器码。
- 线程池扩容:让核心线程(Core Threads)预先创建好,避免测试阶段把时间浪费在
new Thread()上。
B. 并发控制(Start/End Gate 模式)
// 控制并发开始
CountDownLatch startLatch = new CountDownLatch(1);
// 控制等待结束
CountDownLatch endLatch = new CountDownLatch(taskCount);
// ... 在提交线程中 ...
startLatch.await(); // 所有提交线程卡在这里,等发令枪
// ...
startLatch.countDown(); // 发令枪响,瞬间爆发压力- 解析:如果不这么做,循环提交任务时,第 1 个任务可能已经执行完了,第 1000 个任务还没提交,这就变成了“细水长流”而不是“洪水猛兽”。
startLatch保证了瞬时并发压力。
C. 隔离环境
System.out.println("等待系统恢复...");
Thread.sleep(5000);- 解析:在测完普通线程池后,强制休息 5 秒。这是为了让上一轮测试产生的垃圾对象(GC)清理干净,且让 CPU 冷却,防止上一轮的残余负载影响下一轮的结果。
3. 负载场景的设计逻辑
作者设计了三种场景,覆盖了线程池使用的主要情况:
- 轻负载 (Light Load):任务多,但在排队,单任务快。主要测任务提交的开销。
- 中负载 (Medium Load):模拟日常业务。
- 高负载 (Heavy Load):并发高,任务耗时长。主要测线程上下文切换和队列饱和时的表现。
真正执行前还需要调整两步流程,分别是:
4.1 调整动态线程池参数
调整 Nacos 配置文件中的线程池参数,保持和上述普通线程池一致。
onethread:
executors:
- thread-pool-id: onethread-producer
core-pool-size: 40
maximum-pool-size: 40
queue-capacity: 100000
work-queue: ResizableCapacityLinkedBlockingQueue
rejected-handler: CallerRunsPolicy
keep-alive-time: 60
allow-core-thread-time-out: false
notify:
receives: # 修改为自己的手机号
interval: 2
alarm:
enable: true
queue-threshold: 80
active-threshold: 804.2 注释测试代码
将 RuntimeThreadPoolTest#init 方法上的注解进行注释,这里也会用到一部分的线程池运行能力,避免测试结果和实际有出入。
将 RuntimeThreadPoolTest#init 方法上的注解进行注释,这里也会用到一部分的线程池运行能力,避免测试结果和实际有出入。
@Slf4j
@Component
@RequiredArgsConstructor
public class RuntimeThreadPoolTest {
// @PostConstruct
public void init() {
// ......
}4.3 执行测试接口
通过浏览器或 API 调用工具发起 HTTP 接口调用即可。注意,调用完单个接口后,等任务执行完再调用下一个,不然会有资源争抢导致结果不准的情况。
# 触发轻负载性能测试
# 测试参数:任务数=1000,并发数=10,任务耗时=100ms
http://localhost:18080/test/light-load
# 触发中负载性能测试
# 测试参数:任务数=50000,并发数=50,任务耗时=50ms
http://localhost:18080/test/medium-load
# 触发高负载性能测试
# 测试参数:任务数=100000,并发数=100,任务耗时=10ms
http://localhost:18080/test/heavy-load第三部分:结果解读与综合评价
在所有测试场景下,动态线程池与普通线程池性能几乎一致,性能损耗均在 ±0.3% 以内,可以认为动态扩展机制未带来明显开销。
| 负载类型 | 指标 | 普通线程池 | 动态线程池 | 差异 | 评估结果 |
|---|---|---|---|---|---|
| 轻负载 | 总耗时 (ms) | 2606 | 2600 | -0.23% | ✓ 可忽略 |
| TPS (req/s) | 383.73 | 384.62 | -0.23% | ||
| 平均延迟 (ms) | 1346.24 | 1345.25 | -0.07% | ||
| 中负载 | 总耗时 (ms) | 66652 | 66684 | +0.05% | ✓ 可忽略 |
| TPS (req/s) | 750.17 | 749.81 | +0.05% | ||
| 平均延迟 (ms) | 33330.72 | 33347.84 | +0.05% | ||
| 高负载 | 总耗时 (ms) | 29335 | 29409 | +0.25% | ✓ 可忽略 |
| TPS (req/s) | 3408.90 | 3400.32 | +0.25% | ||
| 平均延迟 (ms) | 14654.13 | 14671.31 | +0.12% |
其实这个结果是预期之内的——毕竟动态线程池在设计上做了较多异步化与解耦处理,本身不会对线程池主流程造成明显负载影响。
如果后续在线程池的主执行流程中增加了新的增强逻辑,可以再重新跑一次测试接口,验证整体性能表现。
从日志来看,告警机制在后台是正常运行的,如下图所示(附上告警截图):
1. 数据解读:为什么几乎没区别?
看作者给出的表格:
- 差异:仅在 ±0.3% 之间。
- TPS:动态线程池甚至在某些场景下 TPS 更高(误差范围内)。
原因汇总:
- 主流程无侵入:动态线程池没有在
execute()方法里加锁,也没有复杂的拦截器链。 - 锁竞争低频:监控每隔几秒才采一次,
mainLock的争用概率极低。 - 包装器开销忽略不计:
AtomicLong的自增在 CPU 密集型场景下可以忽略。
2. 只有在什么情况下会有明显区别?
虽然测试结果是“无区别”,但作为架构师,你需要知道边界在哪里。如果出现以下情况,动态线程池性能会下降:
- 监控频率极高:如果你在配置文件中把
notify.interval设置为 1秒甚至更低,mainLock竞争会加剧。 - 线程池数量巨大:如果你的应用里注册了 1000 个动态线程池,
OneThreadRegistry.getAllHolders()的遍历循环本身会消耗 CPU,且报警检查会变成重型操作。
3. 对现有代码的建议(基于目录结构)
结合文件目录,如果你想进一步优化或自己实现,可以关注以下几点:
- 优化采集锁:
在core/.../monitor/ThreadPoolMonitor.java中,尽量减少调用getActiveCount。部分指标可以通过AtomicInteger自己维护(类似 Tomcat 线程池的做法),从而绕过 JDK 的mainLock。 - 合并定时任务: 目前的架构中,Monitoring 是一个定时任务,Alarm 是另一个。
ThreadPoolMonitorThreadPoolAlarmChecker
建议将它们合并为一个ScheduledTask,一次遍历完成采集和检查,减少线程上下文切换。
针对生产环境实战和项目代码细节,我还有 3 点关键补充。
之前的测试主要关注的是“调度流程”的耗时,但在实际大规模落地的生产环境中,还有三个容易被忽略的性能损耗点:
1. 任务包装的 GC 压力(RunnableWrapper)
- 代码位置:
core/.../executor/support/RunnableWrapper.java - 补充说明:
在基准测试中,任务通常只是简单的Sleep。但在实际项目中,为了实现链路追踪(TraceId)或上下文传递(ThreadLocal/MDC),OneThread框架通常需要把提交的Runnable包装一层(即RunnableWrapper)。 - 潜在影响:
这意味着每提交一个任务,都会多创建一个对象。虽然在低并发下无感,但在高并发(如 TPS > 10,000)场景下,这会显著增加 YGC(Young GC) 的频率。如果你的服务对 GC 停顿非常敏感,需要关注这个包装类的实现是否轻量。
2. 可伸缩队列的实现代价(ResizableQueue)
- 代码位置:
core/.../executor/support/ResizableCapacityLinkedBlockingQueue.java - 补充说明:
JDK 原生的LinkedBlockingQueue的容量(capacity)是final的,不可修改。为了实现“动态调整队列大小”,框架必须自己重写一个队列。 - 潜在影响:
你需要确认这个自定义队列在修改容量(setCapacity)时,是否加了全局大锁。如果在扩容/缩容的瞬间,阻塞了put或take操作,可能会在动态调整参数的那一秒产生瞬间的业务抖动(Latency Spike)。虽然平时运行没问题,但“调参瞬间”的性能是测试盲区。
3. 指标上报的网络 I/O
- 代码位置:
starter/.../PrometheusMetricsExportAutoConfiguration.java - 补充说明:
测试代码中,指标只是打印在控制台。但在生产环境,指标需要序列化并发送给 Prometheus 或 Nacos。 - 潜在影响:
如果配置了大量的动态线程池(例如几百个),所有的指标(核心数、队列堆积、完成数)打包上报的网络开销和序列化 CPU 开销不可忽视。建议检查notify.interval(报警间隔)和采集频率,避免在网络带宽紧张时“抢占”业务带宽。
总结:
基准测试证明了“静态”运行时的低开销,而上述三点是“动态”运行时的隐形成本。在实际配置时,保持适度的监控频率,即可规避绝大部分问题。



Comments NOTHING