


JDK 线程池的问题痛点难题是只要你用线程池,就势必会遇到这几道问题
| 痛点 | 本质归因 | oneThread 设计指针 |
|---|---|---|
| 线程池随意 new,资源失控 | 缺乏统一注册表 | 线程池注册中心 + 统一管控 |
| 参数难估算、只能重发 | 静态配置 & 无监控 | 运行中热刷新 + 实时指标采集 |
| 队列堵塞 / 拒绝策略“黑盒” | 无告警 & 无追踪 | 三重告警触发器 (活跃度 / 队列 / 拒绝) |
| 下线时任务丢失 | 线程池生命周期缺口 | 优雅关闭 Hook (awaitTerminationMillis) |
JDK 的线程池是一个基础组,而生产环境需要的是一个“治理平台”;也就是说要么你在项目中注意到线程池的缺点并在自己程序中注意到合理使用,要么就换成动态线程池
1. 痛点一:线程池随意 new,资源失控
线程池随意 new,资源失控 -> 缺乏统一注册表 -> 线程池注册中心 + 统一管控。
- 在大型项目中,开发人员 A 在用户服务里 new 了一个线程池,开发人员 B 在订单服务里也 new 了一个。大家各写各的,参数随意填(有的填最大线程数 200,有的填 Integer.MAX_VALUE)。
- 由于缺乏统一视角,整个系统的线程数可能暴涨,导致 CPU 频繁上下文切换,甚至导致内存溢出(OOM)。这就像一个公司里,每个部门经理都随意招人,最后公司人满为患,连工位都不够坐,发工资都发不出来。
- 解决方案(注册中心):
- 收权:禁止代码里随意 new。
- 登记:所有的线程池必须在一个“中央系统”里注册。系统知道你叫什么名字、在哪个服务、归谁管。
- 上帝视角:管理员可以看到当前应用里到底起了多少个线程池,是否合理,从而进行全局的资源管控。
2. 痛点二:参数难估算、只能重发
参数难估算、只能重发 -> 静态配置 & 无监控 -> 运行中热刷新 + 实时指标采集。
设定线程池参数(核心线程数、最大线程数、队列长度)是一门玄学。你填了 core=10,上线后发现流量激增,队列积压了,这时候你想改成 20。原生 JDK 你必须修改代码或配置文件 -> 提交代码 -> 打包 -> 重启服务。这个过程可能需要 20 分钟,这期间系统可能已经崩了。
- 解决方案(动态调整):
- 像调节音量一样:结合配置中心(如 Nacos、Apollo),你在配置中心把 10 改成 20,服务不需要重启,线程池立马感知并扩容。
- 有据可依:配合“实时指标采集”,你能看到当前的活跃线程数是多少。如果看到长期维持在 10,你才敢放心地扩容到 20。
3. 痛点三:队列堵塞 / 拒绝策略“黑盒”
队列堵塞 / 拒绝策略“黑盒” -> 无告警 & 无追踪 -> 三重告警触发器(活跃度 / 队列 / 拒绝)。
JDK 线程池是一个“闷葫芦”。当任务处理不过来,堆积在队列里时,它不说话;当队列满了,开始抛弃任务(触发拒绝策略)时,它往往也只是默默抛个异常(如果开发没捕获并打印日志,就彻底没人知道了)。直到用户投诉“怎么点不动了”,运维才发现系统卡死了。这叫“黑盒”,里面发生了什么完全看不见。
- 解决方案(监控告警):
- 装上仪表盘:我们要实时监控三个指标:
- 活跃度:干活的线程是不是忙疯了?
- 队列容量:等候室是不是快挤满了?
- 拒绝量:是不是已经开始赶人了?
- 自动报警:一旦队列超过 80%,或者每秒拒绝了 1 个任务,立马发钉钉/邮件给负责人:“出事了,快去动态调整参数!”
- 装上仪表盘:我们要实时监控三个指标:
4. 痛点四:下线时任务丢失
下线时任务丢失 -> 线程池生命周期缺口 -> 优雅关闭 Hook (awaitTerminationMillis)。
当你发布新版本,需要重启服务时(通常是 kill 进程)。此时,线程池里可能还有 5 个任务正在跑,队列里还有 100 个任务在排队。原生 JDK 如果处理不当,进程一杀,这些内存里的任务瞬间全丢了。如果是涉及资金或重要数据的任务,这就是生产事故。
- 解决方案(优雅关闭):
- Hook(钩子):利用 Java 的 ShutdownHook 机制。
- 缓冲期:当收到关闭信号时,线程池不接新客(拒绝新任务),但保证送走老客(执行完正在运行的和队列里排队的任务)。
- 超时控制:设置一个 awaitTerminationMillis(比如 10秒),如果 10秒还没处理完,再强制关闭,兼顾数据安全和发布效率。
线程池问题解决思路
1. 线程池资源管理
我们的做法是把线程池的声明全部收敛到配置中心:先在配置中心登记,再由应用按需装配。这样不仅能一眼看到每个线程池的参数与使用场景,还能快速判断是否可复用,从源头上杜绝盲目新建、浪费服务器资源。项目统一约定:如需新增线程池,必须先在配置中心完成登记,再由应用自动装配,确保规范一致、可追溯:知道谁在用、参数是多少,杜绝了“野线程池”。
2. 线程池参数动态变更
Nacos 既是配置中心也是注册中心。只要把线程池参数集中存放在 Nacos,Spring Boot 客户端即可持续监听。当检测到线程池配置有更新时,立即拉取最新参数并触发动态线程池刷新流程,做到配置一改、线上秒生效;JDK 的 ThreadPoolExecutor 其实本身就支持通过 setCorePoolSize 等方法动态修改参数,只是原生代码没法远程触发。
看起来只是“监听-刷新”,真正落地却有两座大山:
- 1.YAML → Java 映射:Spring Boot 监听器拿到的仅是一段纯 YAML 字符串——如何优雅地反序列化成线程池配置对象?
- 2.多配置中心的代码复用:作为通用组件,我们势必要同时适配 N 个配置中心。怎样抽象公共逻辑,既避免 if-else 轰炸,又能随时 plug-in 新配置中心?
先把这两个疑问放在脑海里,下面的方案章节将逐一拆解。
利用 Spring Boot 强大的 Binder API(Spring Boot 2.0+)。它可以优雅地将松散绑定的配置(YAML/Properties)绑定到强类型的 Java Bean 上,不用自己写复杂的解析逻辑。
今天要 Nacos,明天可能要 Apollo 或 Zookeeper。抽象 + 策略模式/SPI。定义一个标准接口 ConfigRefresher,然后针对 Nacos、Apollo 分别写实现类。启动时根据配置文件决定加载哪个实现类。这叫“面向接口编程,对修改关闭,对扩展开放”。
3. 运行时通知告警
如果让大家来设计线程池告警,会关注哪些维度?oneThread 目前提炼出三条“高命中”告警策略,并给出默认阈值与触发逻辑:
| 维度 | 触发条件 | 检测含义 |
|---|---|---|
| 活跃度 | activeCount / maximumPoolSize 连续高于阈值(默认 80%) | 线程资源已逼近瓶颈,需扩容或对入口流量做限流 |
| 队列负载 | queueSize / queueCapacity 超过阈值 | 排队任务激增,处理能力被入口流量压制,易引发大面积超时 |
| 拒绝异常 | 监控到新的 RejectedExecutionException | 线程池已无法接收新任务,属于阻断场景,应立刻介入 |
活跃度和队列负载的监控规则较为简单,通过定时任务扫描即可实现。不过需要注意的是,定时任务的执行间隔需合理设置:过短会因监控 API 加锁导致与线程池其他操作竞争锁资源,过长则可能错过重要的告警时机。oneThread 在充分权衡后,默认将扫描间隔设置为 5 秒。
/**
* 检查线程活跃度(活跃线程数 / 最大线程数)
*/privatevoidcheckActiveRate(ThreadPoolExecutorHolder holder){ThreadPoolExecutor executor = holder.getExecutor();ThreadPoolExecutorProperties properties = holder.getExecutorProperties();
int activeCount = executor.getActiveCount();// API 有锁,避免高频率调用int maximumPoolSize = executor.getMaximumPoolSize();
if(maximumPoolSize ==0){return;}
int activeRate =(int)Math.round((activeCount *100.0)/ maximumPoolSize);int threshold = properties.getAlarm().getActiveThreshold();
if(activeRate >= threshold){sendAlarmMessage("Activity", holder);}}线程池获取活跃线程方法源代码如下所示:
publicintgetActiveCount(){// 获取了线程池核心主锁finalReentrantLock mainLock =this.mainLock;
mainLock.lock();try{int n =0;for(Worker w : workers)if(w.isLocked())++n;return n;}finally{
mainLock.unlock();}}拒绝策略的告警机制是通过动态代理实现的:每当线程池触发一次拒绝策略,对应的计数器就自增一次。在定时任务扫描时,会比较当前的拒绝次数与上次扫描记录的次数,如果出现新增,则立即触发告警。
privatefinalMap<String, Long> lastRejectCountMap =newConcurrentHashMap<>();
/**
* 检查拒绝策略执行次数
*/privatevoidcheckRejectCount(ThreadPoolExecutorHolder holder){ThreadPoolExecutor executor = holder.getExecutor();String threadPoolId = holder.getThreadPoolId();
// 只处理自定义线程池类型if(!(executor instanceofOneThreadExecutor)){return;}
OneThreadExecutor oneThreadExecutor =(OneThreadExecutor) executor;long currentRejectCount = oneThreadExecutor.getRejectCount().get();long lastRejectCount = lastRejectCountMap.getOrDefault(threadPoolId,0L);
// 首次初始化或拒绝次数增加时触发if(currentRejectCount > lastRejectCount){sendAlarmMessage("Reject", holder);// 更新最后记录值
lastRejectCountMap.put(threadPoolId, currentRejectCount);}}1. 活跃度监控(Active Count)
- 代码解读:
activeRate = (activeCount / maximumPoolSize) * 100 - 你看源码片段:mainLock.lock()。JDK 获取活跃线程数时,需要获取全局锁!
- 这意味着,当你去数有多少人在干活时,所有想进出在这个线程池的任务都得暂停等待。
- 监控不能喧宾夺主。如果每 10毫秒监控一次,线程池光忙着给你汇报人数了,正事都干不了。5秒是一个在“实时性”和“性能损耗”之间平衡的经验值。
2. 拒绝策略告警(Rejection)
- 痛点:JDK 的拒绝策略(如 AbortPolicy)只会抛异常,或者静默丢弃,不会主动告诉你“我拒单了”。
- 解法:装饰器模式(Proxy)。
- 原理:不直接使用 JDK 的 AbortPolicy,而是包一层,做一个 RejectHandlerWrapper。
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
// 1. 记账:计数器 +1
atomicCounter.incrementAndGet();
// 2. 报警:如果配置了实时报警,发个钉钉
// 3. 原路放行:执行原来的拒绝逻辑(抛异常等)
originalHandler.rejectedExecution(r, e);
}4. 线程池运行监控
线程池监控并非锦上添花,而是高并发应用的核心基础设施之一。日常开发中,线程池虽然提升了系统性能,但隐藏的风险却不容忽视:
- 线程池任务排队过长、拒绝任务时,业务可能出现大面积超时甚至瘫痪,但如果缺乏监控机制,开发人员很难在故障初期发现问题根源。
- 监控能及时识别异常,帮助技术人员第一时间介入处理,降低业务受损程度。
- 未经监控的线程池往往存在资源浪费(线程数过多)或性能瓶颈(线程数过少)。
明确线程池监控的核心需求,一般分为:
| 指标 | 需求点 | 需要程度 |
|---|---|---|
| 活跃线程数 | 判断线程池是否逼近性能瓶颈 | ⭐️⭐️ |
| 队列负载 | 识别任务堆积风险 | ⭐️⭐️⭐️ |
| 拒绝策略触发 | 及时发现线程池溢出异常 | ⭐️⭐️⭐️⭐️ |
通常『拒绝策略』相对更复杂,因为需要额外设计机制(如动态代理等)进行统计。
在当前主流的监控中间件中,Prometheus + Grafana 是一套成熟、易用且稳定的组合方案,广泛应用于各类系统的指标监控场景。选择它们作为线程池监控的基础,主要基于以下考虑:
- Prometheus 采用主动拉取(Pull)模型,能够定时抓取线程池的核心运行指标,如活跃线程数、队列长度、拒绝次数等。同时内置时序数据库,部署简单、性能可靠,已在大量场景中验证其稳定性。
- Grafana 与 Prometheus 深度集成,配置数据源即可使用,支持丰富的图表类型和灵活的仪表盘定制,能够清晰展示线程池的运行状态与历史趋势,便于问题定位与运维决策。
通过 Prometheus 采集与存储指标,配合 Grafana 的可视化能力,构建完整的线程池监控体系,既适用于开发调试,也适用于生产环境的持续观测。
5. 优雅关闭防任务丢失
如果仅按示例代码直接创建并使用线程池,而 没有补充任何优雅停机逻辑,一旦应用关闭或重启,线程池中尚未处理完的任务必然丢失。原因在于:应用停机流程里缺少“兜底”步骤——先检测线程池是否仍有待执行任务,再在设定的宽限期内等待其完成。
@ServicepublicclassThreadPoolHookTest{
privateThreadPoolExecutor executor =ThreadPoolExecutorBuilder.builder().corePoolSize(2).maximumPoolSize(4).keepAliveTime(9999L).awaitTerminationMillis(5000L).workQueueType(BlockingQueueTypeEnum.LINKED_BLOCKING_QUEUE).threadFactory("onethread-producer_").rejectedHandler(newThreadPoolExecutor.CallerRunsPolicy()).build();publicvoidsendMessage(){// xxx
executor.execute(()->System.out.println("Test..."));}}这种兜底通常依赖 Shutdown Hook:当进程收到停止信号时,系统会调用预先注册的 Hook,在真正退出前执行自定义清理代码。若未注册 Hook,线程池会被立即终止,残余任务也随之丢弃。
Hook 在当前应用层面可以分为三类:
| 层次 | 触发方式 | 典型用法 |
|---|---|---|
| 操作系统信号 | SIGTERM / SIGINT / SIGKILL | 容器编排、CI/CD 滚动发布会发 SIGTERM 通知应用退出 |
| JVM ShutdownHook | Runtime.getRuntime().addShutdownHook() | 最后时刻执行 Java 线程,处理自定义清理逻辑 |
| 框架 / 容器 Hook | Spring、Tomcat、Netty 等框架生命周期回调 | 在 Bean 级别或 组件 级别做收尾工作 |
这三层 Hook 自上而下串联:SIGTERM → JVM 捕获并触发 ShutdownHook → Spring 发布 ContextClosedEvent → Bean 销毁回调。
在 oneThread 中,我们利用 Spring Bean 级 Hook(DisposableBean 接口或 @PreDestroy 注解)完成线程池的任务检测与等待:收到停机信号后,先检查线程池中是否仍有未完成任务,再在设定的宽限期内调用 awaitTermination,确保任务尽量执行完毕后再退出。
切断入口:告诉线程池 shutdown(),不再接收新任务(商场挂上“停止营业”牌子)。
耐心等待:调用 awaitTermination(5000),给正在跑的任务 5秒钟时间做完(保安等顾客走完)。
强制驱逐:如果 5秒还没干完,不管了,强制关闭(shutdownNow),防止服务这就卡死停不下来。
基础组件开发经验
这是一段经验之谈,核心逻辑是“不能只有 Starter”; oneThread 比作一台高性能电脑:
- core 是 CPU:它负责真正的计算和逻辑(动态调整参数、监控采集)。这部分代码应该是纯净的 Java 代码,不应该关心你是插在 Windows的Spring Boot上,还是 Linux的纯 Spring无第三方上,甚至是裸机(纯 Java Main)上运行。
- spring-base 是驱动程序接口:它负责把 CPU 对接到操作系统内核(Spring Context)。
- starter 是即插即用的 USB 协议(自动装配):它负责检测环境,“哦,你用了 Spring Boot,那我自动帮你把 CPU 驱动装好”。
如果做成一个大包的后果:就像把 CPU、主板、显示器焊死在一起,变成20年以前的那种主板了
- 用户只想换个显示器(换配置中心):不行,必须整机换。
- 用户想装个老系统(非 Spring Boot 项目):不行,接口不兼容,插不进去。
.
├── core # 动态线程池核心模块包,实现动态线程池相关基础类定义
├── dashboard-dev # 应广大同学要求,以后每个项目尽量有前端页面方便查看和调试
├── example # 动态线程池示例包,演示线程池动态参数变更、监控和告警等功能
│ ├── apollo-example
│ └── nacos-cloud-example
├── spring-base # 动态线程池基础模块包,包含Spring扫描动态线程池、是否启用以及Banner打印等
└── starter # 动态线程池配置中心组件包,实现线程池结合Spring框架和配置中心动态刷新
├── adapter # 动态线程池适配层,比如对接 Web 容器 Tomcat 线程池等
│ └── web-spring-boot-starter # Web 容器线程池组件库
├── apollo-spring-boot-starter # Apollo 配置中心动态监控线程池组件库
├── common-spring-boot-starter # 配置中心公共监听等逻辑抽象组件库
├── dashboard-dev-spring-boot-starter # 控制台 API 组件库
└── nacos-cloud-spring-boot-starter # Nacos 配置中心动态监控线程池组件库第一层:core纯 Java 实现 0 依赖,
有些老系统可能还在用 SSH(Struts+Spring+Hibernate)甚至只是简单的 Java 守护进程。如果你的逻辑里夹杂了 @Configuration这种Spring Boot 专属注解,这些老系统直接报错,根本引不进来。
价值:保证了最大兼容性。只要有 JDK,就能跑。
第二层:spring-base(桥梁)
- 定位:适配 Spring Framework(也就是 Spring 的核心 IoC 容器),但不依赖 Spring Boot。
- 为什么:Spring 和 Spring Boot 是两码事。
- 很多遗留系统是 Spring 4.x 或 5.x,但没有用 Boot。
- 这一层负责把 core 里的 Java 对象变成 Spring Bean,利用 ApplicationContext 发挥作用。
- 价值:兼容了“旧时代的王”——传统的 Spring MVC 项目。
第三层:starter(薄皮/胶水)
- 定位:极薄的自动装配层。
- 为什么:这里面几乎没有业务逻辑,只有 META-INF/spring.factories 和一堆 @ConditionalOnXxx。
- 它的作用仅仅是:“如果你引入了 Nacos,我就帮你把 Nacos 的适配器初始化;如果你没引入,我就不动。”
- 价值:用户体验。Boot 用户引入它,一行代码不用写就能跑,但它底层调用的还是 core 和 spring-base 的能力。
第四层:adapter(插件化)
- 定位:apollo-starter、nacos-starter。
- 为什么:避免依赖膨胀(Bloatware)。
- 如果不拆分,一个 Starter 里既有 Nacos 的 jar 包,又有 Apollo 的 jar 包。用户明明只用 Nacos,结果打包时莫名其妙多了一堆 Apollo 的废料,甚至可能导致 jar 包冲突(Dependency Hell)。
- 价值:按需加载。我想吃川菜就进川菜馆(Nacos),想吃粤菜就进粤菜馆(Apollo),不要给我端一锅大杂烩。
Boot 1.5 → 2.x → 3.x,每次 API 都大改Spring Boot 2.x 升级到 3.x(JDK 17强制,javax 变 jakarta)。大 Starter 的下场是如果你的核心业务逻辑代码和 Starter 的自动装配代码混在一起。你需要为了适配 Spring Boot 3 把整个项目翻修一遍,维护两套代码。
先说说项目级代码,比如公司内部自己做的 Starter 吧,这种东西的使用环境是固定的 —— 公司统一用 Spring Boot 2.7,也统一用 Nacos,所以完全可以怎么爽怎么来:直接打成一个包,把所有依赖都一股脑塞进去,只要大家用着方便就行。
但产品级组件就不一样了,比如开源的组件或者 oneThread 这类,面对的使用环境根本没个准儿 —— 有人还在用 Spring Boot 1.5,有人已经更到 3.0 了;有人用 Apollo 做配置中心,有人却用 Zookeeper。
这事儿其实跟 conda 包也挺像的,各种包用着用着总会出些奇奇怪怪的幺蛾子,最后逼得你不得不专门搞个特定版本出来才行。
自定义动态线程池基础类
1.core核心设计概览
core服务的核心就是尽可能减少对三方框架的依赖 。
该模块主要承担以下核心职责:
- 定义动态线程池的基础抽象类;
- 执行线程池运行时的告警扫描逻辑;
- 提供线程池运行状态的指标采集能力;
- 支持监听配置中心变更,并动态调整线程池参数及触发告警通知。
2. package 说明
本文将进一步说明 onethread-core 模块中各个包的具体作用,帮助大家更清晰地理解其内部结构与设计意图。
具体包划分与功能如下所示:
.
├── src
│ ├── main
│ │ └── java
│ │ └── com
│ │ └── nageoffer
│ │ └── onethread
│ │ └── core
│ │ ├── alarm # 告警扫描
│ │ ├── config # 组件库基础配置
│ │ ├── constant # 常量类
│ │ ├── executor # 最最核心的线程池基础包
│ │ │ └── support # 核心基础包至上增强的功能,如果不拆分这个也行,但是类会比较多
│ │ ├── monitor # 运行时指标监控
│ │ ├── notification # 线程池配置变更和告警通知
│ │ │ ├── dto
│ │ │ └── service
│ │ ├── parser # 解析配置内容字符串为键值对 Map
│ │ └── toolkit # 工具包,比如:线程池和线程工厂构建者
大家最需要关注的是 alarm、executor、monitor、notification 四个包。<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>com.nageoffer.onethread</groupId>
<artifactId>onethread-all</artifactId>
<version>0.0.1-SNAPSHOT</version>
</parent>
<artifactId>onethread-core</artifactId>
<dependencies>
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba.fastjson2</groupId>
<artifactId>fastjson2</artifactId>
</dependency>
<dependency>
<groupId>org.yaml</groupId>
<artifactId>snakeyaml</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
</dependency>
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-core</artifactId>
</dependency>
</dependencies>
</project>在项目的根目录(通常是 parent 项目的 pom.xml)中,已经通过 <dependencyManagement> 统一定义了各依赖的版本号
在 core 包中,有四个最核心的类,它们构成了整个动态线程池功能的基础。其关系如下所示:
关键类详解
1. OneThreadExecutor
有同学可能会问:为什么要单独定义一个线程池基类,而不是直接使用原生的ThreadPoolExecutor呢?
原因有很多,但为了循序渐进地展开说明,这里先讲其中一个最关键的点:
原生线程池并没有线程池 ID 或名称的概念。
在实际业务中,我们往往需要对线程池进行运行时变更、指标监控、告警通知等操作。而缺乏唯一标识,会让我们在面对多个线程池时难以准确定位、识别和管理。
因此,为了支持更强的可观测性与可运维性,我们抽象出了具备线程池标识能力的基类,作为后续扩展的统一入口。
值得一提的是,ThreadPoolExecutor 本身并不排斥继承,反而在设计上为继承扩展预留了几个关键的扩展点方法。通过继承并重写这些方法,我们可以轻松注入自定义行为,构建更智能的线程池体系:
/**
* 任务执行前钩子(可用于记录开始时间、设置线程上下文等)
*/
@Override
protected void beforeExecute(Thread t, Runnable r) {
super.beforeExecute(t, r);
// 自定义逻辑
}
/**
* 任务执行后钩子(可用于统计执行耗时、清理资源、日志记录等)
*/
@Override
protected void afterExecute(Runnable r, Throwable t) {
super.afterExecute(r, t);
// 自定义逻辑
}
/**
* 线程池终止钩子(可用于清理资源、发送通知等)
*/
@Override
protected void terminated() {
super.terminated();
// 自定义逻辑
}
下面是 oneThread 的线程池基类,目前我们只在其中集成了线程池唯一标识 这一核心能力。
在阅读源码时,建议大家暂时聚焦这一功能点。至于类中其他相对复杂的逻辑,如果一时看不太懂也没关系,与其陷入细节,不如先跟着马哥一起按“主线思路”一步步深入理解。
/**
* 增强的动态、报警和受监控的线程池 oneThread
* <p>
* 作者:马丁
* 加项目群:早加入就是优势!500人内部项目群,分享的知识总有你需要的 <a href="https://t.zsxq.com/cw7b9" />
* 开发时间:2025-04-20
*/
@Slf4j
public class OneThreadExecutor extends ThreadPoolExecutor {
/**
* 线程池唯一标识,用来动态变更参数等
*/
@Getter
private final String threadPoolId;
// ......
/**
* Creates a new {@code ExtensibleThreadPoolExecutor} with the given initial parameters.
*
* @param threadPoolId thread-pool id
* @param corePoolSize the number of threads to keep in the pool, even
* if they are idle, unless {@code allowCoreThreadTimeOut} is set
* @param maximumPoolSize the maximum number of threads to allow in the
* pool
* @param keepAliveTime when the number of threads is greater than
* the core, this is the maximum time that excess idle threads
* will wait for new tasks before terminating.
* @param unit the time unit for the {@code keepAliveTime} argument
* @param workQueue the queue to use for holding tasks before they are
* executed. This queue will hold only the {@code Runnable}
* tasks submitted by the {@code execute} method.
* @param threadFactory the factory to use when the executor
* creates a new thread
* @param handler the handler to use when execution is blocked
* because the thread bounds and queue capacities are reached
* @param awaitTerminationMillis the maximum time to wait
* @throws IllegalArgumentException if one of the following holds:<br>
* {@code corePoolSize < 0}<br>
* {@code keepAliveTime < 0}<br>
* {@code maximumPoolSize <= 0}<br>
* {@code maximumPoolSize < corePoolSize}
* @throws NullPointerException if {@code workQueue} or {@code unit}
* or {@code threadFactory} or {@code handler} is null
*/
public OneThreadExecutor(
@NonNull String threadPoolId,
int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
@NonNull TimeUnit unit,
@NonNull BlockingQueue<Runnable> workQueue,
@NonNull ThreadFactory threadFactory,
@NonNull RejectedExecutionHandler handler,
long awaitTerminationMillis) {
super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, threadFactory, handler);
// ......
// 设置动态线程池扩展属性:线程池 ID 标识
this.threadPoolId = threadPoolId;
// ......
}
// ......
}
JDK 的原生线程池就像是外包团队,虽然能干活,但是没有编制,没有名字。出了问题(比如 CPU 飙高),你只知道是“某个线程池”干的,但不知道具体是哪一个。OneThreadExecutor 继承了 JDK 线程池,但它最大的升级是挂了工牌(threadPoolId)。它不仅能干活(execute 任务),还能随时被系统识别(通过 getThreadPoolId)。
它是动态调整的基础,因为只有给它起了名字,我们才能指定说:“把订单业务线程池的核心线程数从 10 改成 20”。
2. ThreadPoolExecutorProperties
有同学可能会问:线程池的参数明明已经在OneThreadExecutor中定义了,为什么还要单独拆分出一个属性实体类?
这是因为线程池中的参数通常分散在多个字段中 ,并且像告警阈值、通知规则等配置 在原生线程池中是根本不存在的。为了更好地支持动态配置和统一管理,我们通过 threadPoolId 将这些“外围参数”与线程池进行关联,形成一套完整的配置体系,便于在运行时查看、存储、变更和追踪。
另外,为了马哥写代码方便,告警和通知相关的参数类目前是以静态内部类 的形式存在。大家在实际开发中,也可以根据需要将其拆分为独立的外部类 ,以提升可复用性。
- 它和 OneThreadExecutor 的关系是 “理想 vs 现实”。
- Properties 记录的是:“老板希望这个部门有多少人”;
- Executor 记录的是:“目前实际上有多少人在干活”。
- 动态调整的过程,就是把 Properties 里的新值应用到 Executor 里的过程。
/**
* 线程池属性参数
* <p>
* 作者:马丁
* 加项目群:早加入就是优势!500人内部项目群,分享的知识总有你需要的 <a href="https://t.zsxq.com/cw7b9" />
* 开发时间:2025-04-20
*/
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
@Accessors(chain = true)
public class ThreadPoolExecutorProperties {
/**
* 线程池唯一标识
*/
private String threadPoolId;
/**
* 核心线程数
*/
private Integer corePoolSize;
/**
* 最大线程数
*/
private Integer maximumPoolSize;
/**
* 队列容量
*/
private Integer queueCapacity;
/**
* 阻塞队列类型
*/
private String workQueue;
/**
* 拒绝策略类型
*/
private String rejectedHandler;
/**
* 线程空闲存活时间(单位:秒)
*/
private Long keepAliveTime;
/**
* 是否允许核心线程超时
*/
private Boolean allowCoreThreadTimeOut;
/**
* 通知配置
*/
private NotifyConfig notify;
/**
* 报警配置,默认设置
*/
private AlarmConfig alarm = new AlarmConfig();
@Data
@NoArgsConstructor
@AllArgsConstructor
public static class NotifyConfig {
/**
* 接收人集合
*/
private String receives;
/**
* 告警间隔,单位分钟
*/
private Integer interval = 5;
}
@Data
@NoArgsConstructor
@AllArgsConstructor
public static class AlarmConfig {
/**
* 默认开启报警配配置
*/
private Boolean enable = Boolean.TRUE;
/**
* 队列阈值
*/
private Integer queueThreshold = 80;
/**
* 活跃线程阈值
*/
private Integer activeThreshold = 80;
}
}3. ThreadPoolExecutorHolder
线程池实例对象和线程池参数配置对象本质上是两个独立的实体。但在实际使用中,我们往往需要同时操作这两部分信息 ,例如在执行动态变更、状态监控或告警处理时。
为此,我们引入了 Holder 的设计思路,将线程池实例与其对应的属性配置,通过 threadPoolId 进行绑定和聚合,封装成一个统一的结构,便于后续统一管理与访问。在代码传递过程中,如果我们要去管理一个线程池,我们既需要操作它的活体对象(去执行 setCorePoolSize),又需要读取它的配置信息(看报警阈值是多少)。
如果没有这个类,你的方法参数可能就要写成 method(executor, properties, id),非常麻烦。它把 ID + Executor (活体) + Properties (配置) 捆绑在一起。拿到一个 Holder,你就拿到了关于这个线程池的一切。
/**
* 线程池执行器持有者对象
* <p>
* 作者:马丁
* 加项目群:早加入就是优势!500人内部项目群,分享的知识总有你需要的 <a href="https://t.zsxq.com/cw7b9" />
* 开发时间:2025-04-20
*/
@Data
@AllArgsConstructor
public class ThreadPoolExecutorHolder {
/**
* 线程池唯一标识
*/
private String threadPoolId;
/**
* 线程池
*/
private ThreadPoolExecutor executor;
/**
* 线程池属性参数
*/
private ThreadPoolExecutorProperties executorProperties;
}4. OneThreadRegistry
线程池实例与其参数配置的聚合问题解决后,接下来我们还需要考虑一个现实问题:单个项目中往往不止一个动态线程池实例 。
因此,我们需要一个全局统一的线程池管理容器 来进行集中存储和管理,这就是 OneThreadRegistry 的由来。
这个注册中心的设计非常简洁,主要提供了以下三类核心能力:
- 新增线程池实例 ;
- 根据线程池ID获取指定实例 ;
- 获取当前所有线程池实例 。
通过这一管理器,我们就可以以统一的方式对所有线程池进行注册、查询和维护。
内部有一个 ConcurrentHashMap,Key 是 threadPoolId,Value 是 Holder。代码中任何地方(比如 Controller 接收到修改配置请求,或者定时任务需要扫描监控数据),只要getHolder,注册中心就能立马把对应的 Holder 给出来。
它是整个动态线程池框架的入口和枢纽。
/**
* 动态线程池管理器,用于统一管理线程池实例
* <p>
* 作者:马丁
* 加项目群:早加入就是优势!500人内部项目群,分享的知识总有你需要的 <a href="https://t.zsxq.com/cw7b9" />
* 开发时间:2025-04-20
*/
public class OneThreadRegistry {
/**
* 线程池持有者缓存,key 为线程池唯一标识,value 为线程池包装类
*/
private static final Map<String, ThreadPoolExecutorHolder> HOLDER_MAP = new ConcurrentHashMap<>();
/**
* 注册线程池到管理器
*
* @param threadPoolId 线程池唯一标识
* @param executor 线程池执行器实例
* @param properties 线程池参数配置
*/
public static void putHolder(String threadPoolId, ThreadPoolExecutor executor, ThreadPoolExecutorProperties properties) {
ThreadPoolExecutorHolder executorHolder = new ThreadPoolExecutorHolder(threadPoolId, executor, properties);
HOLDER_MAP.put(threadPoolId, executorHolder);
}
/**
* 根据线程池 ID 获取对应的线程池包装对象
*
* @param threadPoolId 线程池唯一标识
* @return 线程池持有者对象
*/
public static ThreadPoolExecutorHolder getHolder(String threadPoolId) {
return HOLDER_MAP.get(threadPoolId);
}
/**
* 获取所有线程池集合
*
* @return 线程池集合
*/
public static Collection<ThreadPoolExecutorHolder> getAllHolders() {
return HOLDER_MAP.values();
}
}以上这四个类构成了动态线程池体系中最核心的基础代码,后续的所有功能设计几乎都是围绕它们展开的。
当大家对这些基础设施有了清晰的理解之后,再去阅读其他基于这些对象构建的 API,就能更容易把握其背后的上下文语义与设计动机,从而真正做到“知其然,也知其所以然”。
大概的全流程如下:
- 配置下发:配置中心(如 Nacos)推送到本地,包含最新的 Properties JSON 数据。
- 查找目标:程序调用 OneThreadRegistry.getHolder(threadPoolId),找到了对应的 档案袋 (Holder)。
- 提取对象:从档案袋里拿出 员工团队 (OneThreadExecutor)。
- 执行变更:调用 executor.setCorePoolSize(newProperties.getCorePoolSize())。
- 更新档案:将新的配置覆盖到 Holder 中的 executorProperties,确保档案和现状一致。
我们依次在idea里面完成如图内容
- OneThreadExecutor.java -> core/executor
- 这是核心业务对象,必须在 executor 包的根目录下。
- ThreadPoolExecutorProperties.java -> core/executor
- 虽然看起来像 config,但它是专属于 executor 的配置定义,不是 Spring 的 Configuration 类,所以通常紧挨着 Executor 放置,或者在 core/executor/domain(如果分层很细),但在马哥这个结构里,直接放在 core/executor 最合适。
- ThreadPoolExecutorHolder.java -> core/executor
- 这是 Executor 的容器,属于核心领域模型的一部分。
- OneThreadRegistry.java -> core/executor
- 这是 Executor 的管理器,与 Executor 处于同一层级或者是其上层入口,放在这里最为合理。
这个 support 包通常用来放那些为了让核心类跑起来而需要的辅助设施;只是猜想,例如:
- 自定义队列:JDK 的 LinkedBlockingQueue 默认不支持动态修改容量,动态线程池通常会把它的代码 copy 出来改一下(比如叫 ResizableCapacityLinkedBlockIngQueue),这个类就适合放在 support 包。
- 任务包装器:如果你需要对提交的 Runnable 进行包装(比如为了传递 ThreadLocal),这个 Wrapper 类放在 support。
- 工厂类:ThreadFactory 的自定义实现。
Builder 设计模式
1. 什么是 Builder 设计模式?
在 core 包中,我们也引入了一种常见的设计模式 —— Builder模式 。
随着线程池功能逐步增强,我们需要引入更多自定义参数,例如:动态线程池标识、项目关闭时等待任务完成的最大时长等。这些参数在构建过程中不仅需要进行合理性校验,还可能影响最终构造出的线程池类型(普通或动态线程池)。
为了解决上述构建灵活性与可维护性的问题,我们设计了 ThreadPoolExecutorBuilder,它采用了经典的 Builder模式 ,将线程池的各项配置参数封装为链式调用形式。
Builder 模式作用域:如果类的属性之间有一定的依赖关系或者约束条件(源自设计模式之美)
如果不使用 Builder 模式,你直接去买(调用构造函数),情况是这样的:
- 参数太多:JDK 原生线程池构造函数有 7 个参数,你的 OneThreadExecutor 可能有 9 个甚至更多。一旦写错顺序(比如把 keepAliveTime 和 poolSize 写反了),编译器不会报错,但程序运行会炸。
- 逻辑分散:你怎么保证“核心线程数”一定小于“最大线程数”?
- 产出单一:构造函数只能产出一种对象。但在这里,我们需要根据配置决定是产出 “普通员工组” 还是 “带工牌的动态员工组”。
Builder 模式就是“定制配置单”;你不需要一次性把所有零件塞给老板,而是拿一张表,一项一项填。填错了可以改,填完了交给老板(调用 build()),老板在发货前会做最后一次全检。
2. 常见问题答疑
可能有同学会疑惑:Lombok不是也提供了@Builder注解吗?那为什么我们还要手动实现Builder模式呢?
为了帮助大家更直观地理解两者的差异,我整理了一张对比表格,列出了手动实现 Builder 与 Lombok @Builder 注解在使用上的主要区别和各自的适用场景:
| 对比项 | 常规 Builder 模式 | Lombok @Builder 注解 |
|---|---|---|
| 实现方式 | 手动编写 Builder 类和链式方法 | 自动生成 Builder 类、构造器和链式方法 |
| 代码控制力 | 高:可以自由控制构造逻辑、参数校验、默认值 | 低:逻辑复杂时不易插入中间处理 |
| 可读性/IDE体验 | 明确结构清晰,容易调试和导航 | 快速生成,省代码,但不易阅读、调试 |
| 默认值支持 | 易于通过构造器逻辑注入默认值 | 只能依赖字段定义处的初始化(或后处理) |
| 继承支持 | 支持更灵活的继承和扩展 | 不支持继承 Builder,复杂场景限制较多 |
| 方法重载控制 | 可精细设计多个构造路径 | 不支持多种构造方式,容易受限 |
| 生成额外构造器 | 自己控制 | 会自动生成 builder() 方法 |
| 学习/使用成本 | 高一些,但逻辑清晰,便于维护 | 非常低,上手快,适合简单场景 |
Lombok 提供的 @Builder 注解确实很方便,它的最大优势在于省代码、上手快 ,非常适合用于构建简单的 Java 对象。但相比之下,手写的 Builder 模式则具有更强的灵活性和可控性 ,能够支持复杂构建逻辑、参数校验、默认值注入等扩展场景 。
以我们当前的线程池构建器为例,如果单纯使用 Lombok 的 @Builder,只能构造出一个静态对象,无法根据构建过程中的参数动态决定是创建普通线程池还是动态线程池 ,也无法在构建过程中插入定制化校验或初始化逻辑 。Lombok @Builder 类似是复读机你给它什么属性,它就塞进对象里,它没有思考能力。
而在我们手写的构建器中,最终 build() 方法就是扩展能力的核心体现。目前我们只验证了部分核心参数,实际上还可以在这里加入更多校验逻辑,例如线程池容量是否匹配、拒绝策略是否合法、等待时长是否超长等。创建对象的最后一刻,根据你输入的参数,进行逻辑判断、运算和校验。
public ThreadPoolExecutor build() {
// 1. 智能转换:根据字符串类型的队列名称,创建出实际的阻塞队列对象
// Lombok 做不到这一点,它只能单纯传递字符串
BlockingQueue<Runnable> blockingQueue = BlockingQueueTypeEnum.createBlockingQueue(workQueueType.getName(), workQueueCapacity);
// 2. 默认值兜底:如果你没设拒绝策略,默认给你 AbortPolicy
RejectedExecutionHandler rejectedHandler = Optional.ofNullable(this.rejectedHandler)
.orElseGet(() -> new ThreadPoolExecutor.AbortPolicy());
// 3. 必填项校验:没有工厂怎么招人?报错!
Assert.notNull(threadFactory, "The thread factory cannot be null.");
ThreadPoolExecutor threadPoolExecutor;
// ==========================================
// 4. 【核心逻辑】决定产出物种(这是 Lombok 绝对做不到的)
// ==========================================
if (dynamicPool) {
// 如果标记了是动态线程池,就产出 OneThreadExecutor (带ID,带监控)
threadPoolExecutor = new OneThreadExecutor(
threadPoolId,
// ... 参数传入
);
} else {
// 否则,产出原生的 JDK ThreadPoolExecutor (省资源,简单)
threadPoolExecutor = new ThreadPoolExecutor(
// ... 参数传入
);
}
// 5. 后置处理:设置允许核心线程超时
threadPoolExecutor.allowCoreThreadTimeOut(allowCoreThreadTimeOut);
return threadPoolExecutor;
}可能有同学会问:像“等待时长是否超出限制”这样的参数校验,我在设置参数的时候直接校验不就行了吗?
从某些简单场景来看,这确实是可行的。但一旦出现参数之间存在依赖关系 ,就不适合在每个 Setter 方法中逐一校验了。
还有一点,有可能用户没有调用这个参数方法,但是最终是需要必填的。
举个典型例子:核心线程数不能大于最大线程数 。如果你在设置 corePoolSize 时就进行校验,而这时 maximumPoolSize 还未设置,显然校验是无效或错误的。这种跨字段的逻辑依赖,只有在 所有参数都配置完毕、准备构建实例的最后一步(即build()方法) 时才能统一判断。
- 假设默认 core=10, max=20。
- 你想改成 core=5, max=10。
- 你先调用 setMax(10) -> 此时 core(10) > max(10),报错!
- 你被迫必须先改 core,这使得调用顺序变得敏感,体验极差。
还有一点也值得注意:有些参数是必填的,但用户可能根本没有调用对应的Setter方法进行设置 。
比如线程池的 threadFactory 或 threadPoolId,在某些场景下是构造线程池所必需的核心参数。如果不在最终的 build() 方法中统一校验这些“必填但可能被遗漏”的字段,就可能导致线程池在运行时抛出异常或出现不可预期的行为。
因此,build()方法不仅是构建实例的入口,也是做“最终兜底校验”的最佳位置 ,可以最大程度地确保构造出来的对象是完整、合法、可用的。
ThreadPoolExecutorBuilder 工具/辅助构建类应该放在 core/toolkit.├── src
│ ├── main
│ │ └── java
│ │ └── com
│ │ └── nageoffer
│ │ └── onethread
│ │ └── core
│ │ ├── alarm
│ │ ├── config
│ │ ├── constant
│ │ ├── executor
│ │ ├── monitor
│ │ ├── notification
│ │ ├── parser
│ │ └── toolkit <-- 【就在这里】
│ │ ├── ThreadPoolExecutorBuilder.java (核心构建器)
│ │ └── ThreadFactoryBuilder.java (通常也会有一个线程工厂构建器)
Hutool如何使用Builder模式创建线程池
这篇文章很精彩,以 Hutool 工具包为例,深入浅出地讲解了 Builder 模式在线程池中的核心价值。
原生 JDK 线程池的构造方法是典型的“反人类”设计,主要体现在两个方面:
- 参数依赖与约束(逻辑炸弹)
- 依赖关系:maximumPoolSize 必须大于等于 corePoolSize。
- 数值约束:keepAliveTime 必须大于 0。
- 非空约束:workQueue、threadFactory 不能为 null。
- 痛点:如果你直接 new,一旦传错一个参数(比如核心数写了 10,最大数写了 5),代码编译时不会报错,运行时才会抛异常(IllegalArgumentException)。这就像你填了一张复杂的表格,提交到窗口才告诉你第一行填错了。
- 默认值的缺失(重复劳动)
- 很多时候,我们只想改一个参数(比如只改核心线程数),但原生构造函数强迫你把剩下 6 个参数都填一遍。
- 你不得不手动去 new LinkedBlockingQueue<>(),手动 new AbortPolicy(),代码由于冗余变得非常丑陋。
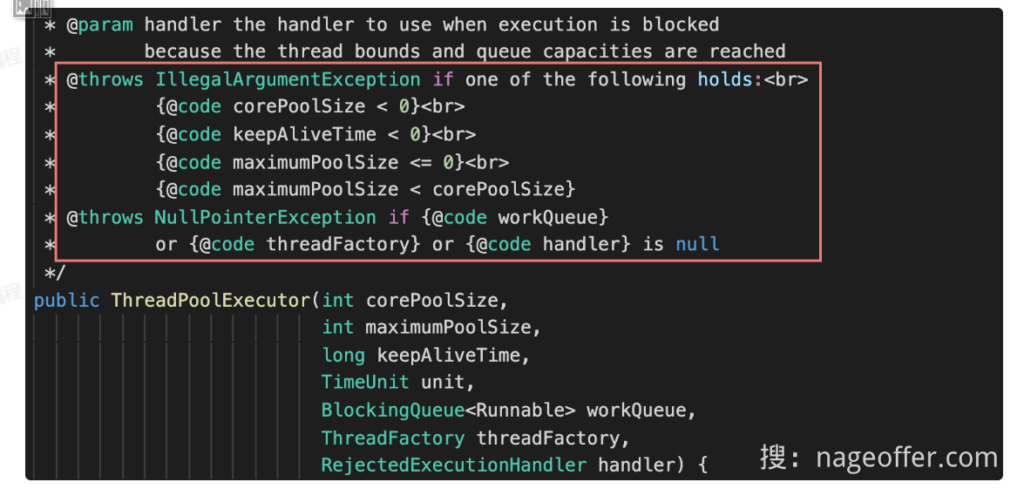
源码注释中如何解释此行详见图片
Hutool 的 ExecutorBuilder 充当了一个智能中介的角色。
1. 分步填写,暂存状态
它不急着创建真正的线程池,而是把你的要求先记在小本本上(成员变量)。
// ExecutorBuilder 内部持有的变量
private int corePoolSize;
private int maxPoolSize;
private BlockingQueue<Runnable> workQueue;
// ...当用户调用 .build() 后Builder 开始工作:
例如:Hutool 可以在 build() 里判断,如果用户设置了 allowCoreThreadTimeOut(true),那么它必须确保 keepAliveTime > 0。
自动补全默认值 文中代码:if(null != builder.workQueue){...} else { ... }
如果你没传队列,Builder 贴心地给你创建一个默认的 LinkedBlockingQueue;如果你没传拒绝策略,它默认给你 AbortPolicy。这就极大地降低了使用门槛。
统一校验 逻辑收口:虽然文中的 ExecutorBuilder 最终还是调用了 JDK 的构造函数来做校验,但 Builder 模式允许我们在调用之前做更高级的校验。
笔者着重提到两点,Hutool 的两处亮点
1. 泛型接口 Builder<T>public interface Builder extends Serializable {
T build();
}
Hutool 为了统一“构建行为”而定义的接口。如果你的系统里有很多复杂的对象(线程池、数据库连接池、HTTP请求),你可以让它们的构建器都实现这个接口。在某些高级场景下,你可以写一个方法接收 Builder<ThreadPoolExecutor> builder,延迟构建,直到真正需要对象时才调用 .build()。
2.create() 方法返回 this 链式调用
public static ExecutorBuilder create() {
return new ExecutorBuilder();
}
public ExecutorBuilder setCorePoolSize(int corePoolSize) {
this.corePoolSize = corePoolSize;
return this; // 返回当前对象,实现链式调用
}这是实现 ExecutorBuilder.create().setX().setY().build() 流畅语法的关键。
package com.nageoffer.onethread.core.toolkit;
// 你的 Builder 本质上就是 Hutool Builder 的思想,但是为了特定的业务(动态线程池)服务的
public class ThreadPoolExecutorBuilder implements Builder<ThreadPoolExecutor> {
// ... 属性定义 ...
public static ThreadPoolExecutorBuilder create() {
return new ThreadPoolExecutorBuilder();
}
// ... set 方法 ...
@Override
public ThreadPoolExecutor build() {
// 1. 默认值兜底 (类似 Hutool)
if (workQueue == null) { ... }
// 2. 核心业务分支
if (dynamicPool) {
// 创建带监控、带ID的动态线程池
return new OneThreadExecutor(threadPoolId, ...);
} else {
// 创建普通线程池
return new ThreadPoolExecutor(...);
}
}
}解决如何根据一个布尔值 (dynamicPool) 动态决定创建哪种线程池对象



Comments NOTHING