


我选择在本地已有的ubuntu22版本中配置nacos,其实这台虚拟机中包含了mq,redis,pgsql,minio等等中间件,还有一点就是千万不要在ubuntu桌面操作,因为不知道什么程序占用大量资源卡的要命
将当前用户加入 docker 用户组 sudo usermod -aG docker $USER
刷新权限(无需重启)newgrp docker
docker run -d \
--name nacos \
-p 8848:8848 \
-p 9848:9848 \
-e TIME_ZONE='Asia/Shanghai' \
-e MODE=standalone \
-e JVM_XMS=128m \
-e JVM_XMX=256m \
nacos/nacos-server:v2.1.0Docker 启动配置参数说明:
-d后台运行模式 :以守护进程方式运行容器,不占用当前终端窗口。--name nacos容器名称标识 :指定容器名称为nacos,便于后续管理操作。-p 8848:8848关键端口映射 :将宿主机的 8848端口 映射到 Nacos 容器的 HTTP 接口和控制台端口。-p 9848:9848gRPC通信端口 :Nacos 2.0+ 必需端口(用于客户端与服务器通信),不开放会导致服务不可用。-e TIME_ZONE='Asia/Shanghai'时区 :强制容器使用 中国时区(GMT+8) 。-e MODE=standalone运行模式配置 :设置环境变量启动 单机模式 (集群模式需改为cluster)。-e JVM_XMS=128m初始堆内存分配 :Nacos 启动时立即占用的内存。-e JVM_XMX=128m最大堆内存上限 :允许 Nacos JVM 使用的最大内存。nacos/nacos-server:2.1.0镜像定义 :指定使用的官方 Nacos 镜像及版本号。
将配置适配到本地 Ubuntu 虚拟机中的 Nacos,核心在于将**服务器地址(Server Addr)**从公网域名改为你虚拟机的 IP 地址。
以下是具体的修改步骤和 IDEA 中的配置写法:
第一步:获取虚拟机 IP 地址
在你的 Ubuntu 虚拟机终端中输入:
ip addr
# 或者
ifconfig
找到类似 192.168.x.x 或者 10.x.x.x 的 IPv4 地址(假设你的 IP 是 192.168.50.10)。
第二步:修改 IDEA 中的 VM Options
你需要修改两个应用的启动参数。建议将 unique-name 改为一个本地特定的后缀(例如 -local),以示区分。
1. NacosCloudExampleApplication
在 IDEA 的 Run/Debug Configurations 中,找到该应用,在 VM options 中填入: code Textdownloadcontent_copyexpand_less
-Dunique-name=-local
-Dspring.cloud.nacos.server-addr=192.168.50.10:8848
--add-opens=java.base/java.util.concurrent=ALL-UNNAMED
- 注意:请将 192.168.50.10 替换为你第一步获取的真实虚拟机 IP。
- unique-name 我改为了 -local,你也可以用其他的,只要和下面 Nacos 建配置时保持一致即可。
2. DashboardDevApplication
同样在 VM options 中填入:
-Donethread.nacos.server-addr=192.168.50.10:8848
- 同样替换 IP 地址。
第三步:在本地 Nacos 新建配置
- 访问 Nacos 控制台:
在宿主机(你运行 IDEA 的电脑)浏览器访问:http://192.168.50.10:8848/nacos- 如果访问不通,请检查 Ubuntu 的防火墙是否放行了 8848 端口(见文末提示)。
- 新建配置:
点击“配置管理” -> “配置列表” -> “+”号新建。- Data ID: onethread-nacos-cloud-example-local.yaml
- 注意:这里的后缀 -local 必须与你在 IDEA VM Options 里写的 -Dunique-name 的值保持一致。
- Group: DEFAULT_GROUP
- 配置格式: 选择 YAML
- Data ID: onethread-nacos-cloud-example-local.yaml
- 配置内容:
复制教程中的 YAML 内容,并根据本地情况做如下微调(粘贴进去):
onethread:
nacos:
# 这里的 data-id 要和你当前创建的文件名一致
data-id: onethread-nacos-cloud-example-local.yaml
group: DEFAULT_GROUP
config-file-type: yaml
web:
core-pool-size: 10
maximum-pool-size: 200
keep-alive-time: 60
notify:
# 这里改成你的手机号或随意填,本地测试不重要
receives: 13800000000
notify-platforms:
platform: DING
# 如果本地测试不需要发钉钉消息,这里可以不管,或者填个假的
url: https://oapi.dingtalk.com/robot/send?access_token=xxx
executors:
- thread-pool-id: onethread-producer
core-pool-size: 12
maximum-pool-size: 24
keep-alive-time: 19999
work-queue: ResizableCapacityLinkedBlockingQueue
queue-capacity: 10000
rejected-handler: CallerRunsPolicy
allow-core-thread-time-out: false
notify:
receives: 13800000000
interval: 5
alarm:
enable: true
queue-threshold: 80
active-threshold: 80
- thread-pool-id: onethread-consumer
core-pool-size: 10
maximum-pool-size: 20
keep-alive-time: 9999
work-queue: LinkedBlockingQueue
queue-capacity: 1024
rejected-handler: AbortPolicy
allow-core-thread-time-out: true
notify:
receives: 13800000000
interval: 5
alarm:
enable: true
queue-threshold: 80
active-threshold: 80
重要提示:网络连通性
Ubuntu 默认可能开启了防火墙。你需要放行 8848 和 9848 端口,确保 Ubuntu 里的 Nacos 是以单机模式启动 sh startup.sh -m standalone
你的虚拟机网络模式是 Bridged (桥接) 或者 NAT 模式且做了端口转发,保证宿主机能 ping 通虚拟机的 IP。或者你足够有钱可以买个4C8G的云服务器(或者用校企合作的hwtx送的代金券,不要白不要避免时间过期了)
依次启动 NacosCloudExampleApplication 和 DashboardDevApplication 服务 VM options
-Dunique-name=-local -Dspring.cloud.nacos.server-addr=192.168.50.10:8848 --add-opens=java.base/java.util.concurrent=ALL-UNNAMEDQ:unique-name 参数是什么?
A:我们通过 Nacos 配置中心读取各自对应的配置,如果不使用 unique-name 区分,大家的 配置名称是一致的,那么就会出现配置读取错乱的情况。各自改个不会和别人冲突的,比如自己名称英文加数字之类的。
Q:--add-opens 参数是什么?
A:在 Java 9+ 中,模块需要显式声明它们导出了哪些包(exports)以及开放哪些包允许深度反射(opens)。java.base 默认只 exports 了它的公共API(如 java.util.concurrent 包的公共类和方法),但不会自动opens任何包 。这里放开 JUC 包下的权限,方便后续业务进行
前端
如果你是 Windows 电脑,可以通过 Nginx 快速启动的方式部署 oneThread 前端工程。下载这个 Nginx 压缩包,并解压。http://localhost:5176/ 跳转 oneThread 登录页面,既为前端启动成功,可以正常使用系统。
或者下载 onethread-dashboard 前端项目,依次执行下述命令。
1. 通过 npm 安装依赖
进入 onethread-dashboard 项目的根目录。
# 使用项目指定的pnpm版本进行依赖安装
npm i -g corepack
# 安装依赖
pnpm install2. 启动项目
# 启动项目
pnpm devoneThread 是基于 配置中心 构建的动态可观测 Java 线程池框架,这种设计是没有前端控制台的,所有操作围绕配置中心展开。为了帮助大家更好理解动态线程池,oneThread 在基于配置中心的基础上,抽象了一层控制台。简单一句话说明就是,基于 Nacos 配置中心和注册中心实现的控制台。
大家看咱们项目结构时候,如果 module 命名后面跟着
-dev就是基于控制台的个性化开发。常规公司使用基于配置中心的动态线程池是没有这块设计的。
因为 Nginx 启动和前端源码启动访问方式不同,这里再补充下:
- Nginx 一键启动:http://localhost:5176
- 前端源码启动:http://localhost:5777
用户名和密码配置在 dashboard-dev 模块的 application.yaml 中修改:
oneThread 项目中使用了 SaToken 框架来实现登录功能,一款非常优秀的开源框架。由于我们并未使用 Redis 或 JWT 等持久化存储方案
控制台界面
实例数量 :表示该项目在 Nacos 注册中心注册的实例数量。例如,本地仅启动一个实例时,显示为 1;若启动两个实例,则显示为 2。
线程池数量 :配置文件中定义的线程池实例数量。
Web线程池 :标识配置文件中是否包含 Web 线程池配置;若包含,则支持 Web 线程池的动态调整。
线程池管理
1. 线程池列表
当前页面展示所有命名空间和服务中包含的线程池配置,也是登录后的默认页面。页面可以向右滑动,因为配置较多,所以才用了滑动方式展示。刚登录没什么项目
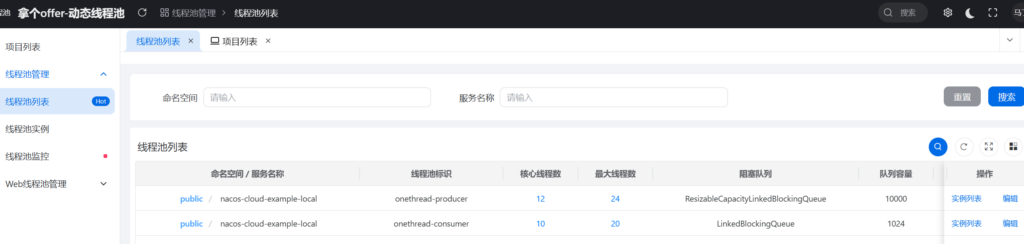
列表字段说明:
- 线程池标识 :对应线程池配置项
onethread.executors[x].thread-pool-id的值。 - 实例数量 :当前线程池关联的已启动服务实例数量。
编辑功能:
若修改上述参数,变更请求会通过 dashboard-dev 服务组装参数并调用 Nacos 接口,更新对应的配置文件。各客户端应用通过监听 Nacos 配置中心,可实现线程池配置的实时刷新。
实例列表功能:点击可跳转至线程池实例详情页面;若实例数量为 0,则无法跳转。
2. 线程池实例
该列表用于展示当前线程池在各服务实例中的实时运行参数。这个刚开始没什么东西
查看详情功能:
线程池所在服务中最新的全量参数展示,点击“刷新”按钮,可向线程池实例所在的应用发起请求,获取并展示最新的运行时参数。
线程池监控
该页面依托 Prometheus 存储和采集线程池监控数据,并通过 Grafana 进行可视化展示。
目前默认调用我封装的 Grafana 服务。如果需要使用自定义的 Grafana 实例,可通过修改 dashboard-dev 服务 application.yaml 文件中的 grafana.url 参数进行配置。
onethread:users:# 避免再使用数据库,用户名直接固定写到配置文件- admin,admin
- test,test
nacos:
server-addr: http://127.0.0.1:8848user-login:
exclude:
interfaces:|-
/api/onethread-dashboard/auth/login
namespaces:# 需要从 Nacos 中读取以下命名空间(自定义)配置文件检索动态线程池- public
- framework
- common
- test
- prod
grafana:# 如果本地有安装 Grafana 展示,可以替换为本地路径
url: http://grafana.nageoffer.com/d/gxBvKxYNz/7adffa3?orgId=1&from=now-6h&to=now&timezone=browser&var-application_name=nacos-cloud-example&var-dynamic_thread_pool_id=onethread-consumer&refresh=5s&theme=light&kiosk=trueWeb 线程池管理
1. 线程池列表
当前页面展示所有命名空间和服务中包含的 Web 线程池配置。
列表字段说明:
- 命名空间/服务名称 :含义同上,已在前文说明。
- 数据ID :对应 Nacos 中的 data-id 字段。
- 分组标识 :对应 Nacos 中的 group 字段。
- Web容器名称 :见名知意。
- 实例数量 :当前 Web 线程池关联的已启动服务实例数量。
编辑功能:
若修改上述参数,变更请求会通过 dashboard-dev 服务组装参数并调用 Nacos 接口,更新对应的配置文件。各客户端应用通过监听 Nacos 配置中心,可实现 Web 线程池配置的实时刷新。
实例列表功能:点击可跳转至 Web 线程池实例详情页面;若实例数量为 0,则无法跳转。
2. 线程池实例
该列表用于展示当前 Web 线程池在各服务实例中的实时运行参数。
查看详情功能:
Web 线程池所在服务中最新的全量参数展示,点击“刷新”按钮,可向 Web 线程池实例所在的应用发起请求,获取并展示最新的运行时参数。
相关概念
其实这玩意章在第一片文章中已经参数过了,大体意思就是线程池线程池可以减少创建销毁线程的开销,方便短时间内的大量请求处理。有两个常见的应用场景,分别是:快速响应用户请求和一个快速处理批量任务。
快速响应用户请求
通过线程池的方式并行查询,那查询全部商品信息的时间就取决于多个流程中最慢的那一条。然后是 两个代码,我们仔细看一下
这是一个非常经典的高并发低延迟(Low Latency)场景优化案例,通常被称为“Scatter-Gather”(分散-聚合)模式。
在电商详情页(PDP)、首页聚合接口等场景中,后端往往需要调用多个下游服务(库存、价格、评论、推荐、优惠券等)并将结果汇总返回给前端。
下面我将从核心原理、线程池配置玄机、代码执行流程、以及生产环境注意事项四个方面,为你详细、通透地讲解这段代码背后的逻辑。
一、 核心原理:串行 vs 并行
1. 串行模式(Serial)
也就是你第一段代码的逻辑。
- 生活类比:你去快餐店点餐。你先去排队买汉堡(50ms),拿到后再去排队买可乐(80ms),拿到后再去排队买薯条(50ms)。
- 总耗时:50ms + 80ms + 50ms = 180ms(理论最小值)。
- 缺点:CPU 在等待 I/O(如网络请求、数据库查询)时是空闲的,没有利用好资源,用户等待时间长。
2. 并行模式(Parallel)
也就是你第二段代码的逻辑。
- 生活类比:你带了两个朋友一起去快餐店。你排队买汉堡,朋友A排队买可乐,朋友B排队买薯条。大家同时开始排队。
- 总耗时:取决于最慢的那个人。虽然汉堡和薯条50ms就拿到了,但必须等买可乐的朋友(80ms)回来了,大家才能一起吃饭。
- 公式:Max(TaskA, TaskB, TaskC)。
- 优点:大幅压缩了响应时间(RT),提升用户体验。
二、 线程池配置的玄机(核心考点)
你提到的配置如下:
new ThreadPoolExecutor(
6, // corePoolSize: 核心线程数
9, // maximumPoolSize: 最大线程数
1024, TimeUnit.SECONDS,
new SynchronousQueue<>() // workQueue: 任务队列
);
这段配置是为了响应优先”而设计的,有几个关键点需要深度解读:
1. 为什么使用 SynchronousQueue?
这是这段配置的灵魂所在。
- 普通队列(如 LinkedBlockingQueue):当任务数量超过核心线程数时,新任务会被放入队列等待。这在追求吞吐量的后台批处理任务中没问题,但在追求低延迟的 Web 接口中是致命的。任务进队列意味着它在“排队”,这会增加接口的响应时间。
- SynchronousQueue:这是一个容量为 0 的队列。它不存储任务。
- 当一个任务提交时,如果有空闲线程,直接由空闲线程接手。
- 如果没有空闲的核心线程,它不会缓冲任务,而是尝试创建新的线程(直到达到 maximumPoolSize)。
- 效果:任务要么立即被执行,要么因为线程池满而被拒绝(抛出异常),绝对不会在队列里浪费时间排队。这正是“最快时间将结果响应给用户”的体现。
2. 核心线程数(6)与最大线程数(9)
- corePoolSize = 6:你的业务场景有3个任务(库存、优惠、评论)。设置6意味着系统在负载较低时,完全有能力利用核心线程直接处理并发请求,无需创建新线程的开销。
- maximumPoolSize = 9:结合 SynchronousQueue,这意味着系统同一时刻最多只能处理 9 个并发任务。
- 注意:如果第 10 个任务同时到来,因为队列不缓冲,且线程数已达上限,线程池会执行拒绝策略(默认抛出 RejectedExecutionException)。在生产环境中,这里需要根据压测结果谨慎设置,通常会调大这个数值,或者配合降级策略。
三、 代码执行流程深度解析
我们来看看代码具体是怎么跑的:
- 提交任务 (submit): code Javadownloadcontent_copyexpand_less
Future<Object> future = threadPoolExecutor.submit(Main::getProductInventory);- 主线程将任务丢给线程池,线程池分配一个线程去执行 getProductInventory。
- 关键点:submit 方法是非阻塞的,它会立刻返回一个 Future 对象。主线程并没有等待,而是立刻往下走,去提交第二个、第三个任务。
- 此时,3个子线程正在服务端并行“跑”着。
- 获取结果 (result.get()): code Javadownloadcontent_copyexpand_less
for (Future<Object> result : results) { result.get(); // 阻塞点 }- 这是一个同步屏障(Barrier)。
- 主线程遍历 Future 列表。当调用 future.get() 时,如果该任务还没运行完,主线程会阻塞在这里等待。
- 时间分析:
- 假设遍历顺序是:库存(50ms) -> 优惠(80ms) -> 评论(50ms)。
- 主线程等待库存:等待50ms。此时优惠任务已经跑了50ms,还剩30ms。
- 主线程等待优惠:再等待30ms(因为前50ms是重叠的)。此时总耗时80ms。
- 主线程等待评论:评论任务耗时50ms,早在主线程等优惠的时候就已经结束了,所以这里立马返回结果,不耗时。
- 最终耗时:就是最慢的那个任务(80ms)加上极少量的上下文切换开销。
四、 生产环境的进阶建议(通透版)
虽然上面的代码演示了原理,但在真实的生产级代码(如阿里的双11场景)中,还有几个大坑需要填:
1. 必须设置超时时间 (Timeout)
你现在的代码是 result.get(),这是无限等待。
- 风险:如果“获取优惠信息”的服务挂了,或者网络卡顿导致一直不返回,你的主线程就会一直卡死在这里,最终导致整个 Web 容器线程耗尽,服务雪崩。
- 修正:
// 最多等 100ms,超时就抛异常,执行降级逻辑(比如返回无优惠)
result.get(100, TimeUnit.MILLISECONDS); } catch (TimeoutException e) { // 记录日志,返回默认值 return new DefaultPromotion(); }2. 使用 CompletableFuture (Java 8+)
Future 和 ThreadPoolExecutor 是 Java 5 的产物。现代 Java 开发通常使用 CompletableFuture,它功能更强大,代码更优雅。
优化后的代码示例:
public static void main(String[] args) {
long startTime = System.currentTimeMillis();
// 1. 定义任务
CompletableFuture<Object> task1 = CompletableFuture.supplyAsync(Main::getProductInventory, threadPoolExecutor);
CompletableFuture<Object> task2 = CompletableFuture.supplyAsync(Main::getProductPromotions, threadPoolExecutor);
CompletableFuture<Object> task3 = CompletableFuture.supplyAsync(Main::getProductReviews, threadPoolExecutor);
// 2. 等待所有任务完成 (allOf)
CompletableFuture<Void> allTasks = CompletableFuture.allOf(task1, task2, task3);
// 3. 阻塞直到所有完成(或者设置超时)
try {
allTasks.get(200, TimeUnit.MILLISECONDS);
// 4. 获取结果(此时 join 不会阻塞,因为已经确认完成了)
Object inventory = task1.join();
Object promotion = task2.join();
Object review = task3.join();
} catch (Exception e) {
// 异常处理逻辑
}
System.out.println("总耗时:" + (System.currentTimeMillis() - startTime));
}
3. 线程池参数的计算 (IO密集型)
- 你的任务全是 Thread.sleep,模拟的是网络 I/O。这是典型的 IO密集型 任务。
- 公式:线程数 = CPU核数 * (1 + 线程等待时间 / 线程CPU时间)。
- 因为等待时间(80ms)远大于CPU计算时间(可能不到1ms),所以你需要配置远大于 CPU 核数的线程池。如果你的机器是 4核,配置 6 或 9 个线程可能偏少(取决于并发量),生产环境可能需要几十甚至上百个线程来处理高并发的 IO 等待。
并行化(Parallelism)利用了多核 CPU 的优势,通过SynchronousQueue 避免了任务排队带来的额外延迟,通过调大线程数应对 IO 密集型的阻塞。这套组合拳是提升 Web 接口响应速度的标准范式。只要加上超时控制和异常降级,这就是一个生产级的解决方案。
快速处理批量任务
快速处理批量任务场景比较多,包括不限于以下举得例子:
- 公司举办周年庆,需要给每个员工发送邮件说明。
- 短信平台后台通过上传 Excel 给一批用户发送短信
主线程需要阻塞的等待所有任务执行完成,因此必须要尽可能减少等待时间,而前者的使用场景中则完全不需要考虑这个问题,因此我们可以设置一个合适的阻塞队列用来缓冲任务。
大量任务堆积线程池阻塞队列场景下,可能会遇到项目发布重启或者意外宕机等情况,进而导致任务丢失风险。
这是一个典型的高吞吐量、异步解耦”场景。
与上一个“商品详情页”场景(追求低延迟、用户在线等待结果)完全不同,批量发送短信属于后台任务或“Fire-and-Forget”(发送即不管)模式。我们不需要立即告诉用户“短信已发送成功”,只需要保证系统能吞下所有请求并最终处理完即可。
下面我将从核心设计理念、阻塞队列的作用、执行流程、以及与上一场景的对比四个维度,为你通过透彻讲解。
一、 核心设计理念:削峰填谷与解耦
1. 串行模式的瓶颈
在第一段代码中:
- 逻辑:你拿着一份名单,给第一个人发短信(等50ms),发完后再给第二个人发。
- 公式:总耗时 = 任务数 N * 50ms。
- 问题:如果名单有 10,000 人,主线程将被阻塞 10000 * 0.05s = 500秒。在这 500 秒内,主线程无法做任何其他事情,且 CPU 利用率极低(大部分时间在等 I/O)。
2. 线程池+缓冲队列模式
在第二段代码中:
- 逻辑:你是一个老板(主线程),手里有 10,000 个发短信的任务。你不需要自己去发,而是把这些任务全部扔到一个**巨大的收件箱(阻塞队列)**里。
- 解耦:你扔任务的速度非常快(纳秒级),扔完你就可以去干别的了(比如响应前端“发送请求已受理”)。
- 消费者:线程池里雇佣了 10 个工人(线程),他们盯着收件箱,一旦里面有信,就拿出来去发。
二、 为什么选择 LinkedBlockingQueue?
这是本场景与上一场景最大的区别。
1. 缓冲(Buffering)
- 上一个场景(商品详情):我们用 SynchronousQueue(容量为0),因为用户在等,任务必须立即处理,处理不过来就报错,不能让用户干等。
- 本场景(批量短信):我们用 LinkedBlockingQueue(有界队列)。
- 流量洪峰:假设瞬间来了 10,000 个请求,但线程池只有 10 个线程,一秒钟只能处理 10 * (1000/50) = 200 个。
- 蓄水池作用:剩下的 9,800 个任务不会被丢弃,也不会报错,而是乖乖在队列里排队。
- 削峰填谷:队列像一个水库,把瞬间的高并发请求存起来,让 10 个线程以稳定的速度慢慢消化。
2. 生产者-消费者模式
- 生产者(Main线程):生产速度极快(循环塞入队列)。
- 消费者(线程池):消费速度受限于网络 I/O(50ms 一个)。
- 阻塞队列:是两者之间的缓冲区,保证了生产者不会因为消费者慢而被拖死。
三、 线程池配置深度解析
new ThreadPoolExecutor(
10, // corePoolSize
10, // maximumPoolSize
1024, TimeUnit.SECONDS,
new LinkedBlockingQueue<>(100000) // 巨大的缓冲队列
);
1. 固定线程数(Fixed Size)
这里核心线程数和最大线程数都是 10。
- 原因:这是一种资源管控策略。发送短信是 IO 密集型任务,但由于不需要实时响应,我们没必要为了瞬间的流量去创建几百个线程(线程切换和资源占用也是成本)。我们希望机器以一个稳定的负载长期运行,慢慢处理队列里的积压任务。
2. 队列容量 (100,000)
- 有界队列的重要性:虽然用无界队列(不传参数默认是 Integer.MAX_VALUE)看似省事,但在生产环境极其危险。如果任务堆积过多,会撑爆内存导致 OOM(Out Of Memory)。
- 设置 10万:意味着系统能容忍 10万条短信的积压。如果超过 10万,才会触发拒绝策略(抛出异常或由调用者运行)。
四、 代码执行流程透视图
- 提交阶段:
- 主线程执行 for 循环。
- threadPoolExecutor.execute(...):这个方法是非阻塞的(除非队列满了)。
- 任务被封装成 Runnable 对象,瞬间被塞入 LinkedBlockingQueue 的尾部。
- 循环结束后,主线程任务完成(此时短信可能一条都没发出去,但任务都在队列里了)。
- 执行阶段(异步):
- 线程池中的 10 个核心线程处于活跃状态。
- 它们不断轮询 LinkedBlockingQueue 头部。
- 线程 A 拿到一个任务 -> 调用 sendPhoneSms -> 睡眠 50ms -> 任务结束 -> 回到队列取下一个。
- 10 个线程并行工作,整体处理能力是单线程的 10 倍。
五、 生产环境的隐患与进阶(通透版)
虽然这种方式比串行强得多,但在企业级开发中,直接用内存队列(LinkedBlockingQueue)做批量任务有致命弱点:数据丢失风险。
1. 宕机丢数据
- 场景:主线程把 10,000 个任务塞进了队列。此时系统才处理了 100 个,突然服务器断电或进程崩溃(Kill -9)。
- 后果:内存中的队列瞬间消失。剩下的 9,900 个用户永远收不到短信,而且你还没法恢复(因为没有持久化)。
2. 优雅关闭(Graceful Shutdown)
如果你要重启服务,不能直接杀进程。必须保证队列里的任务发完。
// 停止接收新任务
threadPoolExecutor.shutdown();
try {
// 等待现有任务执行完(包括队列里的)
if (!threadPoolExecutor.awaitTermination(60, TimeUnit.SECONDS)) {
threadPoolExecutor.shutdownNow(); // 超时强制关闭
}
} catch (InterruptedException e) {
threadPoolExecutor.shutdownNow();
}
3. 架构演进:使用消息队列 (MQ)
对于重要的通知类业务,生产环境通常不会只用线程池队列,而是引入中间件(如 RabbitMQ, RocketMQ, Kafka)。
- 流程:Main线程 -> 发送消息到 MQ (持久化到磁盘) -> 消费者服务监听 MQ -> 提交给线程池执行。
- 优势:即使服务挂了,消息还在 MQ 里。服务重启后,继续从 MQ 拉取消费,保证消息不丢失。
总结对比
| 特性 | 上一场景(商品详情) | 本场景(批量短信) |
| 目标 | 低延迟 (Latency) <br> 用户要立刻看到结果 | 高吞吐 (Throughput) <br> 系统要在后台慢慢处理完 |
| 队列选择 | SynchronousQueue <br> (不缓冲,立即执行) | LinkedBlockingQueue <br> (大容量缓冲,慢慢消化) |
| 线程策略 | Core 小,Max 大 <br> (弹性伸缩,应对突发流量) | Core = Max <br> (固定工人数,稳定输出) |
| 关键点 | Future.get() 阻塞等待结果 | execute() 提交即走,不关心结果 |
你所展示的代码,正是利用了阻塞队列的缓冲能力,实现了任务提交与执行的解耦,完美适用于对实时性要求不高、但数据量较大的批处理场景。
线程池底层原理
核心在于ThreadPoolExecutor的三大组件:
- 工作线程(Worker)实现任务执行与复用
- 阻塞队列缓冲任务洪峰(它扮演者生产者消费者模型中缓冲区的角色。工作线程将会不断的从队列中获取并执行任务。)
- 位运算变量(ctl)统一管控状态与线程数(线程池本体负责维护运行状态、管理工作线程以及调度任务。)
狭义上指的是 ThreadPoolExectutor 及其子类,而广义上则指整个 Executor 大家族,下面是从上到下所有内容;JDK 基于 ThreadPoolExecutor 实现了 ScheduledThreadPoolExecutor 用于支持任务调度。Tomcat 基于 ThreadPoolExecutor 实现了一个同名的线程池,用于处理 Web 请求。Spring 基于 ExecutorService 接口提供了一个 ThreadPoolTaskExecutor 实现,它仍然基于内置的 ThreadPoolExecutor 运行,在这个基础上提供了不少便捷的方法。
Executor:整个体系的最上级接口,定义了 execute 方法。ExecutorService:它在Executor接口的基础上,定义了 submit、shutdown 与 shutdownNow 等方法,完善了对 Future 接口的支持。AbstractExecutorService:实现了ExecutorService中关于任务提交的方法,将这部分逻辑统一为基于 execute 方法完成,使得实现类只需要关系 execute 方法的实现逻辑即可。ThreadPoolExecutor:线程池实现类,完善了线程状态管理与任务调度等具体的逻辑,实现了上述所有的接口。
- 如果当前工作线程数小于 核心线程数,则启动一个工作线程 执行任务。
- 如果当前工作线程数大于等于 核心线程数,且阻塞队列未满 ,则将任务添加到阻塞队列 。
- 如果当前工作线程数大于等于 核心线程数,且阻塞队列已满 ,则启动一个工作线程 执行任务。
- 如果当前工作线程数已达最大值 ,且阻塞队列已满,则触发拒绝策略。
工作线程启动后重复下面逻辑
- 通过
getTask方法从工作队列中获取任务,如果拿不到任务就阻塞一段时间,直到超时或者获取到任务。如果成功获取到任务就进入下一步,否则就直接进入线程退出流程; - 调用
Worker的lock方法加锁,保证一个线程只被一个任务占用; - 调用
beforeExecute回调方法,随后开始执行任务,如果在执行任务的过程中发生异常则会被捕获; - 任务执行完毕或者因为异常中断,此后调用一次
afterExecute回调方法,然后调用unlock方法解锁; - 如果线程是因为异常中断,那么进入线程退出流程,否则回到步骤 1 进入下一次循环。
参数
public ThreadPoolExecutor 类一共提供了四个构造方法,告诉我们有如下参数
int corePoolSize, // 核心线程数,长期存在并处理工作
int maximumPoolSize, // 最大线程数,核心线程已满,工作队列已满,同时线程池中线程总数未超过最大线程数,会创建非核心线程
long keepAliveTime, // 非核心线程闲置存活时间
TimeUnit unit, // 时间单位
BlockingQueue<Runnable> workQueue, // 工作队列
ThreadFactory threadFactory, // 创建线程使用的线程工厂
RejectedExecutionHandler handler // 拒绝策略工作队列已满,且线程池中线程数已经达到最大线程数时,执行的兜底策略工作线程 Worker
ThreadPoolExecutor 中,每个工作线程都对应的一个内部类 Worker,它们都存放在一个 HashSet 中
private final HashSet<Worker> workers = new HashSet<Worker>();private final class Worker
extends AbstractQueuedSynchronizer
implements Runnable {
// 线程对象
final Thread thread;
// 首个执行的任务,一般执行完任务后就保持为空
Runnable firstTask;
// 该工作线程已经完成的任务数
volatile long completedTasks;
Worker(Runnable firstTask) {
// 默认状态为 -1,禁止中断直到线程启动为止
setState(-1);
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this);
}
public void run() {
runWorker(this);
}
}Worker 本身实现了 Runnable 接口,创建一个 Worker 实例时,构造函数会通过我们在创建线程池时指定的线程工厂创建一个Thread对象,并把当前的Worker对象作为一个Runnable绑定到线程里面 。当调用它的 run 方法时,它会通过调用线程池的 runWorker反过来启动线程,此时 Worker 就开始运行了。
Worker 类继承了 AbstractQueuedSynchronizer,通过AQS的同步机制来保证对工作线程的访问是线程安全
主锁 mainLock
线程池直接使用一个 HashSet 来存储 Worker 示例,而 HashSet 本身却并非线程安全的,那在并发场景下要如何保证线程安全呢?实际上,除了 workers 以外,线程池中还有大量非线程安全的变量,这里再举几个例子:
ctl:记录线程池状态与工作线程数。largestPoolSize/corePoolSize:最大/核心工作线程数。completedTaskCount:已完成任务数。keepAliveTime:核心线程超时时间。
这些变量实际上环环相扣,因此很难通过分别将它们改为原子变量/并发容器来保证线程安全 ,因此 ThreadPoolExecutor 选择为整个线程池提供一把主锁 mainLock,每次操作或读取这种全局性变量的时候,都需要获取主锁才能进行:
privatefinalReentrantLock mainLock =newReentrantLock();比如获取当前工作线程数的时候:
public int getPoolSize() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// 如果线程已经开始停机,则返回 0,否则返回工作线程数量
return runStateAtLeast(ctl.get(), TIDYING) ? 0
: workers.size();
} finally {
mainLock.unlock();
}
}线程池通过mainLock来保证全局配置的线程安全,而每个工作线程再通过AQS来保证工作线程自己的线程安全。
状态控制
1. ctl
AtomicInteger 类型的成员变量 ctl ,它是 control 的缩写,线程池分别通过 ctl 的高位低位来管理两部分状态信息:
- 第一部分为高 3 位,用来记录线程池当前的运行状态。
- 第二部分为低 29 位,用来记录线程池中的工作线程数。
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
// 29(32-3)
private static final int COUNT_BITS = Integer.SIZE - 3;
// ======== 线程数相关常量 ========
// 允许的最大工作线程(2^29-1 约5亿)
private static final int CAPACITY = (1 << COUNT_BITS) - 1;
// ======== 线程状态相关常量 ========
// 运行状态。线程池接受并处理新任务
private static final int RUNNING = -1 << COUNT_BITS;
// 关闭状态。线程池不能接受新任务,处理完剩余任务后关闭。调用shutdown()方法会进入该状态。
private static final int SHUTDOWN = 0 << COUNT_BITS;
// 停止状态。线程池不能接受新任务,并且尝试中断旧任务。调用shutdownNow()方法会进入该状态。
private static final int STOP = 1 << COUNT_BITS;
// 整理状态。由关闭状态转变,线程池任务队列为空时进入该状态,会调用terminated()方法。
private static final int TIDYING = 2 << COUNT_BITS;
// 终止状态。terminated()方法执行完毕后进入该状态,线程池彻底停止。
private static final int TERMINATED = 3 << COUNT_BITS;


Comments NOTHING