


第16小节:用户查询优惠券之缓存击穿
Git 分支
20240826_dev_coupon-template-query_cache_ding.ma
业务背景
在分发服务中,我们需要调用优惠券模板的相关信息。为了避免各个服务中重复实现模板查询功能,我们首先编写了一个通用的引擎层模板查询方法,以支持 C 端用户和内部应用的查询。像这种大流量的接口,肯定是需要放到缓存的。
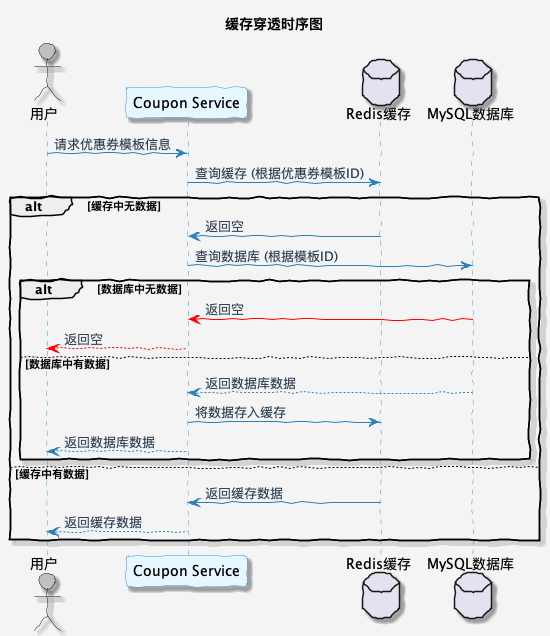
用户常规访问优惠券模板时序图如下:
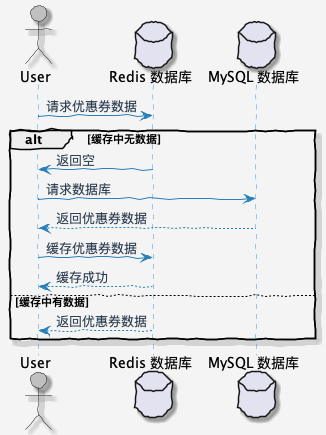
什么是缓存击穿?
缓存击穿指在高并发的系统中,一个热点数据缓存过期或者在缓存中不存在,导致大量并发请求直接访问数据库,从而给数据库造成巨大压力,甚至可能引起宕机。
具体来说,当某个热点数据在缓存中过期时,如果此时有大量并发请求同时访问这个数据,由于缓存中不存在,所有请求都会直接访问数据库,导致数据库负载急剧增加。
伪代码如下所示:
public String selectTrain(String id) { String cacheData = cache.get(id); // 查询缓存不存在,去数据库查询并放入到缓存 if (StrUtil.isBlank(cacheData)) { // 获取数据库中存在的数据 String dbData = trainMapper.selectId(id); if (StrUtil.isNotBlank(dbData)) { // 将查询到的数据放入缓存,下次查询就有数据了 cahce.set(id, dbData); cacheData = dbData; } } return cacheData; }
缓存击穿解决方案
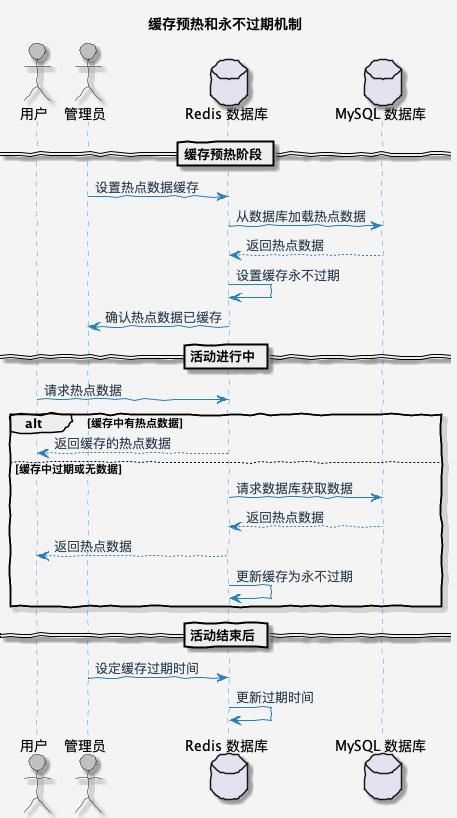
1. 预热和缓存永不过期
一般来说,我们会通过预热和缓存永不过期的机制让缓存不击穿,这样即使再大的流量也可以通过缓存去抗。
- 缓存预热:热点数据预加载,指的是在活动或者大促开始前,针对已知的热点数据从数据库加载到缓存中,这样可以避免海量请求第一次访问热点数据需要从数据库读取的流程。
- 永不过期:热点数据永不过期,指的就是可以预知的热点数据,在活动开始前,设置过期时间为 -1。这样的话,就不会有缓存击穿的风险。
上面两个一般都是搭配一起使用的。等对应热点缓存的活动结束后,这些数据访问量就比较低了,可以通过后台任务的方案对指定缓存设置过期时间,这样可以有效降低 Redis 存储压力。
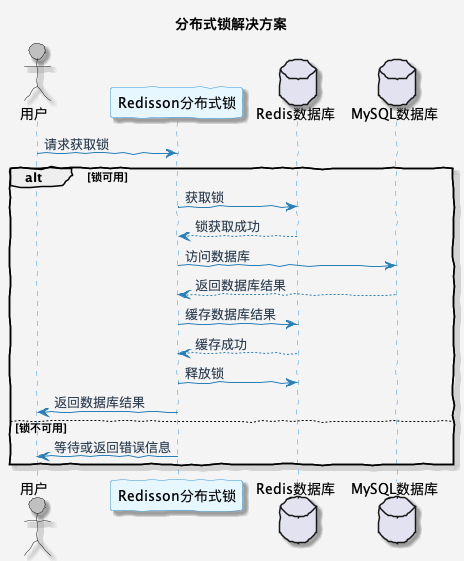
2. 分布式锁之双重判定锁
分布式锁的解决方案就是保证只有一个请求可以访问数据库,其它请求等待结果。这样可以避免大量的请求同时访问数据库。
在原有基础上继续改进,伪代码如下:
public String selectTrain(String id) {
String cacheData = cache.get(id); // 查询缓存
if (StrUtil.isBlank(cacheData)) { // 缓存不存在,去数据库查询并放入缓存
Lock lock = getLock(id); // 获取分布式锁
lock.lock();
try {
String dbData = trainMapper.selectId(id); // 查询数据库
if (StrUtil.isNotBlank(dbData)) { // 数据库中有数据
cache.set(id, dbData); // 将数据放入缓存
cacheData = dbData;
}
} finally {
lock.unlock(); // 释放锁
}
}
return cacheData;
}但是这种的话有一个弊端,那就是获取分布式锁的请求,都会执行一遍查询数据库,并更新到缓存。理论上只有第一个加载数据库记录请求是有效的。
针对这个问题,可以通过双重判定锁的形式,在获取到分布式锁之后,再次查询一次缓存是否存在。如果缓存中存在数据,就直接返回;如果不存在,才继续执行查询数据库的操作。这样就可以避免大量请求访问数据库。
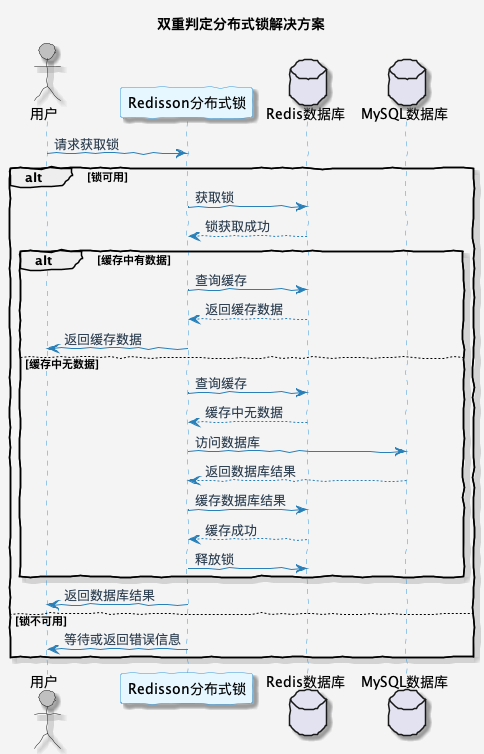
伪代码如下:
public String selectTrain(String id) {
// 查询缓存
String cacheData = cache.get(id);
// 查询缓存不存在,去数据库查询并放入到缓存
if (StrUtil.isBlank(cacheData)) {
// 为避免大量请求同时访问数据库,通过分布式锁减少数据库访问量
Lock lock = getLock(id);
lock.lock();
try {
// 获取锁后双重判定
cacheData = cache.get(id);
// 理论上只有第一个请求加载数据库是有效的,因为它加载后会把数据放到缓存
// 后面的请求再请求数据库加载缓存就没有必要了
if (StrUtil.isBlank(cacheData)) {
// 获取数据库中存在的数据
String dbData = trainMapper.selectId(id);
if (StrUtil.isNotBlank(dbData)) {
// 将查询到的数据放入缓存,下次查询就有数据了
cache.set(id, dbData);
cacheData = dbData;
}
}
} finally {
lock.unlock();
}
}
return cacheData;
}下面是这种场景下解决方案的一般步骤:
- 1. 获取锁:在查询数据库前,首先尝试获取一个分布式锁。只有一个线程能够成功获取锁,其他线程需要等待;
- 2. 查询数据库:如果双重判断确认数据确实不存在于缓存中,那么就执行查询数据库的操作,获取数据;
- 3. 写入缓存:获取到数据后,将数据写入缓存,并设置一个合适的过期时间,以防止缓存永远不会被更新;
- 4. 释放锁:最后,释放获取的锁,以便其他线程可以继续使用这个锁。
3. 高并发极端情况
很多同学认为到这里就结束了,但这恰恰只是开始,真正难得是接下来要讲的。
我举个场景,有一万个请求同一时间访问触发了缓存击穿,如果用双重判定锁,逻辑是这样的:
- 1. 第一个请求加锁、查询缓存是否存在、查询数据库、放入缓存、解锁,假设我们用了50毫秒;
- 2. 第二个请求拿到锁查询缓存、解锁用了1毫秒;
- 3. 那最后一个请求需要等待10049毫秒后才能返回,用户等待时间过长,极端情况下可能会触发应用的内存溢出。
3.1 尝试获取锁 tryLock
像上面这种场景,类似于秒杀的架构,我们要做的就是不让用户请求在服务端阻塞过长时间。那就可以使用尝试获取锁 tryLock API,它的语义是如果拿锁失败直接返回,而不是阻塞等待直到获取锁。
public String selectTrain(String id) {
// 查询缓存不存在,去数据库查询并放入到缓存
String cacheData = cache.get(id);
if (StrUtil.isBlank(cacheData)) {
// 为避免大量请求同时访问数据库,通过分布式锁减少数据库访问量
Lock lock = getLock(id);
// 尝试获取锁,获取失败直接返回用户请求,并提醒用户稍后再试
if (!lock.tryLock()) {
throw new RuntimeException("当前访问人数过多,请稍候再试...");
}
try {
// 获取数据库中存在的数据
String dbData = trainMapper.selectId(id);
if (StrUtil.isNotBlank(dbData)) {
// 将查询到的数据放入缓存,下次查询就有数据了
cache.set(id, dbData);
cacheData = dbData;
}
} finally {
lock.unlock();
}
}
return cacheData;
}通过这种方式我们可以快速失败,告诉用户网络异常请稍后再试,等用户再尝试刷新的时候,其实获取锁的线程已经把数据放到了缓存。
因为这种方案对用户操作体验不友好,所以也只是适用于部分场景。在实际开发中,需要灵活变更。
3.2 分布式锁分片
还有一种比较优雅的解决方案是通过分布式锁分片的形式,让并行的线程更多一些。因为同一时间有多个线程能同时操作,所以理论上,设置分片量的多少,也就是性能提升了近多少倍。
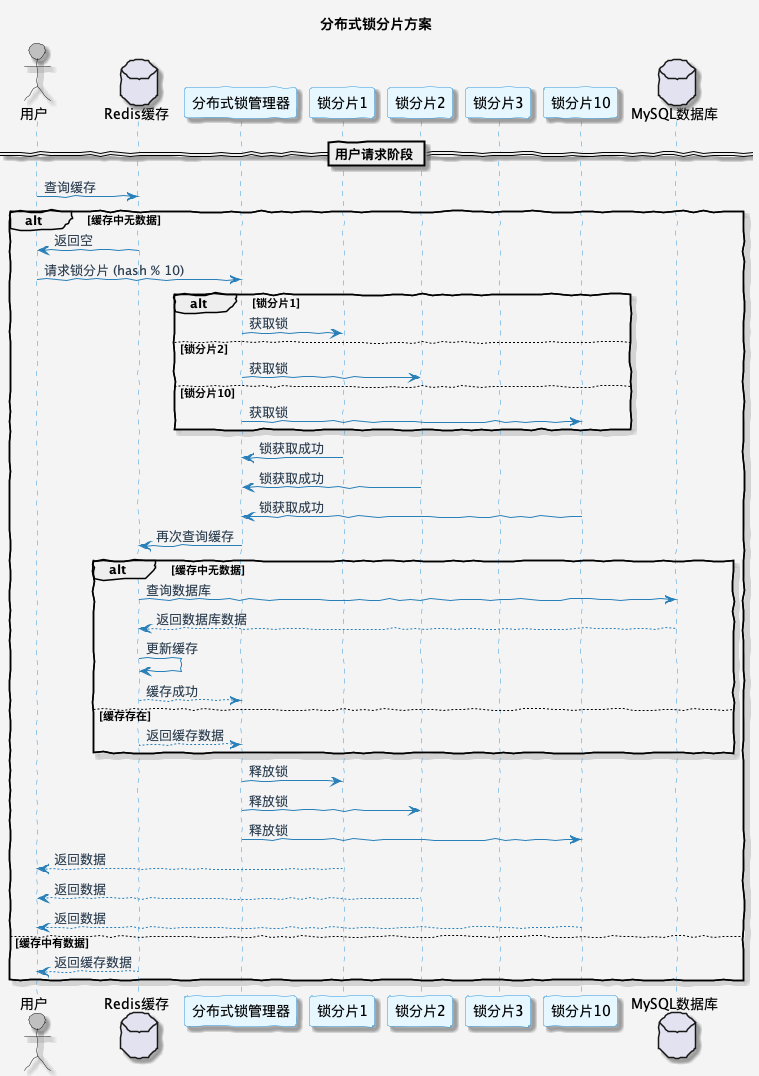
伪代码如下所示:
public String selectTrain(String id, String userId) {
// 查询缓存不存在,去数据库查询并放入到缓存
String cacheData = cache.get(id);
if (StrUtil.isBlank(cacheData)) {
// 假设设置10把分布式锁,那么就通过唯一标识(这里取用户ID)进行取模获取分片下标
int idx = Math.abs(userId.hashCode()) % 10;
// 为避免大量请求同时访问数据库,通过分布式锁减少数据库访问量
Lock lock = getLock(id + idx);
lock.lock();
try {
// 获取锁后双重判定
cacheData = cache.get(id);
// 理论上只有第一个请求加载数据库是有效的,因为它加载后会把数据放到缓存
// 后面的请求再请求数据库加载缓存就没有必要了
if (StrUtil.isBlank(cacheData)) {
// 获取数据库中存在的数据
String dbData = trainMapper.selectId(id);
if (StrUtil.isNotBlank(dbData)) {
// 将查询到的数据放入缓存,下次查询就有数据了
cache.set(id, dbData);
cacheData = dbData;
}
}
} finally {
lock.unlock();
}
}
return cacheData;
}开发优惠券模板查询
1. 常规优惠券模板查询
第一版本的代码是最为原始的直接查询数据库,数据量大的时候,肯定是没办法扛住的,所以我们接下来引入解决了缓存击穿的版本。
package com.nageoffer.onecoupon.engine.service.impl;
import cn.hutool.core.bean.BeanUtil;
import com.baomidou.mybatisplus.core.conditions.query.LambdaQueryWrapper;
import com.baomidou.mybatisplus.core.toolkit.Wrappers;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.nageoffer.onecoupon.engine.common.enums.CouponTemplateStatusEnum;
import com.nageoffer.onecoupon.engine.dao.entity.CouponTemplateDO;
import com.nageoffer.onecoupon.engine.dao.mapper.CouponTemplateMapper;
import com.nageoffer.onecoupon.engine.dto.req.CouponTemplateQueryReqDTO;
import com.nageoffer.onecoupon.engine.dto.resp.CouponTemplateQueryRespDTO;
import com.nageoffer.onecoupon.engine.service.CouponTemplateService;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Service;
/**
* 优惠券模板业务逻辑实现层
* <p>
* 作者:马丁
* 加项目群:早加入就是优势!500人内部项目群,分享的知识总有你需要的 <a href="https://t.zsxq.com/cw7b9 " />
* 开发时间:2024-07-08
*/
@Slf4j
@Service
@RequiredArgsConstructor
public class CouponTemplateServiceImpl extends ServiceImpl<CouponTemplateMapper, CouponTemplateDO> implements CouponTemplateService {
private final CouponTemplateMapper couponTemplateMapper;
@Override
public CouponTemplateQueryRespDTO findCouponTemplate(CouponTemplateQueryReqDTO requestParam) {
LambdaQueryWrapper<CouponTemplateDO> queryWrapper = Wrappers.lambdaQuery(CouponTemplateDO.class)
.eq(CouponTemplateDO::getShopNumber, Long.parseLong(requestParam.getShopNumber()))
.eq(CouponTemplateDO::getId, Long.parseLong(requestParam.getCouponTemplateId()))
.eq(CouponTemplateDO::getStatus, CouponTemplateStatusEnum.ACTIVE.getStatus());
CouponTemplateDO couponTemplateDO = couponTemplateMapper.selectOne(queryWrapper);
return BeanUtil.toBean(couponTemplateDO, CouponTemplateQueryRespDTO.class);
}
}2. 查询优惠券模板缓存
我们省去了简单的分布式过程,上面已经有简单的示例,直接用较常见的双重判定锁。
@Override
public CouponTemplateQueryRespDTO findCouponTemplate(CouponTemplateQueryReqDTO requestParam) {
// 查询 Redis 缓存中是否存在优惠券模板信息
String couponTemplateCacheKey = String.format(EngineRedisConstant.COUPON_TEMPLATE_KEY, requestParam.getCouponTemplateId());
Map couponTemplateCacheMap = stringRedisTemplate.opsForHash().entries(couponTemplateCacheKey);
// 如果存在直接返回,不存在需要通过双重判定锁的形式读取数据库中的记录
if (MapUtil.isEmpty(couponTemplateCacheMap)) {
// 获取优惠券模板分布式锁
// 关于缓存击穿更多注释事项,欢迎查看我的B站视频:https://www.bilibili.com/video/BV1qz421z7vC
RLock lock = redissonClient.getLock(String.format(EngineRedisConstant.LOCK_COUPON_TEMPLATE_KEY, requestParam.getCouponTemplateId()));
lock.lock();
try {
// 通过双重判定锁优化大量请求无意义查询数据库
couponTemplateCacheMap = stringRedisTemplate.opsForHash().entries(couponTemplateCacheKey);
if (MapUtil.isEmpty(couponTemplateCacheMap)) {
LambdaQueryWrapper<CouponTemplateDO> queryWrapper = Wrappers.lambdaQuery(CouponTemplateDO.class)
.eq(CouponTemplateDO::getShopNumber, Long.parseLong(requestParam.getShopNumber()))
.eq(CouponTemplateDO::getId, Long.parseLong(requestParam.getCouponTemplateId()))
.eq(CouponTemplateDO::getStatus, CouponTemplateStatusEnum.ACTIVE.getStatus());
CouponTemplateDO couponTemplateDO = couponTemplateMapper.selectOne(queryWrapper);
// 优惠券模板不存在或者已过期直接抛出异常
if (couponTemplateDO == null) {
throw new ClientException("优惠券模板不存在或已过期");
}
// 通过将数据库的记录序列化成 JSON 字符串放入 Redis 缓存
CouponTemplateQueryRespDTO actualRespDTO = BeanUtil.toBean(couponTemplateDO, CouponTemplateQueryRespDTO.class);
Map<String, Object> cacheTargetMap = BeanUtil.beanToMap(actualRespDTO, false, true);
Map<String, String> actualCacheTargetMap = cacheTargetMap.entrySet().stream()
.collect(Collectors.toMap(
Map.Entry::getKey,
entry -> entry.getValue() != null ? entry.getValue().toString() : ""
));
// 通过 LUA 脚本执行设置 Hash 数据以及设置过期时间
String luaScript = "redis.call('HMSET', KEYS[1], unpack(ARGV, 1, #ARGV - 1)) " +
"redis.call('EXPIREAT', KEYS[1], ARGV[#ARGV])";
List<String> keys = Collections.singletonList(couponTemplateCacheKey);
List<String> args = new ArrayList<>(actualCacheTargetMap.size() * 2 + 1);
actualCacheTargetMap.forEach((key, value) -> {
args.add(key);
args.add(value);
});
// 优惠券活动过期时间转换为秒级别的 Unix 时间戳
args.add(String.valueOf(couponTemplateDO.getValidEndTime().getTime() / 1000));
// 执行 LUA 脚本
stringRedisTemplate.execute(
new DefaultRedisScript<>(luaScript, Long.class),
keys,
args.toArray()
);
couponTemplateCacheMap = cacheTargetMap.entrySet()
.stream()
.collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue));
}
} finally {
lock.unlock();
}
}
return BeanUtil.mapToBean(couponTemplateCacheMap, CouponTemplateQueryRespDTO.class, false, CopyOptions.create());}
看了上面缓存击穿理论知识后,这个代码就比较容易理解。其中因为我们要进行准换 Hash putAll 方法所以需要进行多次 Map 转换,这个属于是业务复杂性导致,如果只是简单放个 String 代码流程会简单很多。
优惠券模板缓存击穿查询时序图如下所示:
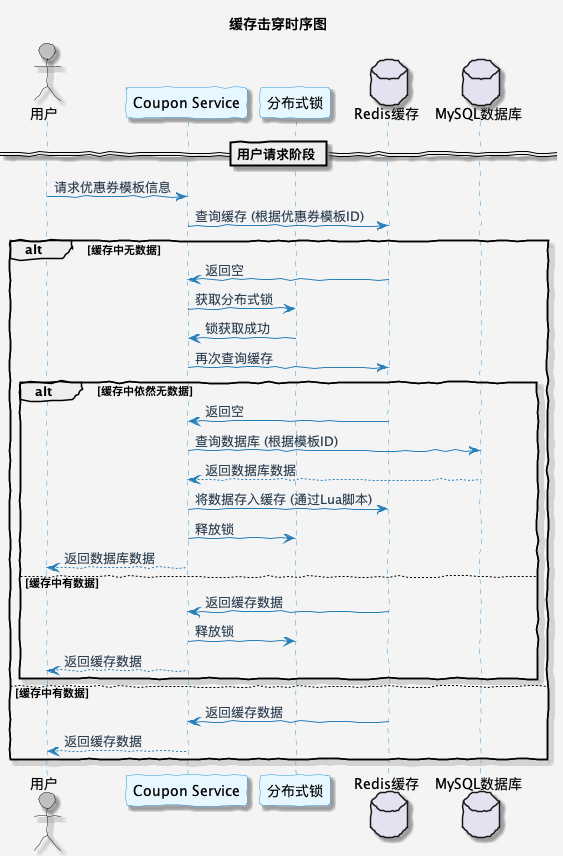
文末总结
虽然我们讲了多种缓存击穿的方案,其中说到的 tryLock 和分布式锁分片一般只会出现在面试中,因为国内 99.99% 的公司不存在存在高并发极端的情况,写个双重判定锁已经是对业务的尊重了。可以背八股,但别被八股带进去。
优惠券模板有有效期开始时间、结束时间两个字段,所以把缓存的过期时间设置成和优惠券模板有效期的结束时间一致,查不到缓存就直接提示用户优惠券模板已经失效,是不是就能不用考虑缓存击穿问题了
我想可能有些场景下某个优惠券只能在有效期时间内的指定时间使用,所以考虑到这点就没用你说的方法?
如果Redis的内存超出最大内存,仍有效优惠券模板 存在被淘汰的风险
缓存中的优惠券模板记录过期时间在创建的时候就已经设置了 为了预防redis特定热点key失效(不一定是到达过期时间) 导致缓存击穿问题 所以才需要考虑
@Slf4j
@Service
@RequiredArgsConstructor
public class CouponTemplateServiceImpl extends ServiceImpl<CouponTemplateMapper, CouponTemplateDO> implements CouponTemplateService {
private final CouponTemplateMapper couponTemplateMapper;
private final StringRedisTemplate stringRedisTemplate;
private final RedissonClient redissonClient;
@Override
public CouponTemplateQueryRespDTO findCouponTemplate(CouponTemplateQueryReqDTO requestParam) {
// 查询 Redis 缓存中是否存在优惠券模板信息
String couponTemplateCacheKey = String.format(EngineRedisConstant.COUPON_TEMPLATE_KEY, requestParam.getCouponTemplateId());
Map<Object, Object> couponTemplateCacheMap = stringRedisTemplate.opsForHash().entries(couponTemplateCacheKey);
// 如果存在直接返回,不存在需要通过双重判定锁的形式读取数据库中的记录
if (MapUtil.isEmpty(couponTemplateCacheMap)) {
// 获取优惠券模板分布式锁
// 关于缓存击穿更多注释事项,欢迎查看我的B站视频:https://www.bilibili.com/video/BV1qz421z7vC
RLock lock = redissonClient.getLock(String.format(EngineRedisConstant.LOCK_COUPON_TEMPLATE_KEY, requestParam.getCouponTemplateId()));
lock.lock();
try {
// 通过双重判定锁优化大量请求无意义查询数据库
couponTemplateCacheMap = stringRedisTemplate.opsForHash().entries(couponTemplateCacheKey);
if (MapUtil.isEmpty(couponTemplateCacheMap)) {
LambdaQueryWrapper<CouponTemplateDO> queryWrapper = Wrappers.lambdaQuery(CouponTemplateDO.class)
.eq(CouponTemplateDO::getShopNumber, Long.parseLong(requestParam.getShopNumber()))
.eq(CouponTemplateDO::getId, Long.parseLong(requestParam.getCouponTemplateId()))
.eq(CouponTemplateDO::getStatus, CouponTemplateStatusEnum.ACTIVE.getStatus());
CouponTemplateDO couponTemplateDO = couponTemplateMapper.selectOne(queryWrapper);
// 优惠券模板不存在或者已过期直接抛出异常
if (couponTemplateDO == null) {
throw new ClientException("优惠券模板不存在或已过期");
}
// 通过将数据库的记录序列化成 JSON 字符串放入 Redis 缓存
CouponTemplateQueryRespDTO actualRespDTO = BeanUtil.toBean(couponTemplateDO, CouponTemplateQueryRespDTO.class);
Map<String, Object> cacheTargetMap = BeanUtil.beanToMap(actualRespDTO, false, true);
Map<String, String> actualCacheTargetMap = cacheTargetMap.entrySet().stream()
.collect(Collectors.toMap(
Map.Entry::getKey,
entry -> entry.getValue() != null ? entry.getValue().toString() : ""
));
// 通过 LUA 脚本执行设置 Hash 数据以及设置过期时间
String luaScript = "redis.call('HMSET', KEYS[1], unpack(ARGV, 1, #ARGV - 1)) " +
"redis.call('EXPIREAT', KEYS[1], ARGV[#ARGV])";
List<String> keys = Collections.singletonList(couponTemplateCacheKey);
List<String> args = new ArrayList<>(actualCacheTargetMap.size() * 2 + 1);
actualCacheTargetMap.forEach((key, value) -> {
args.add(key);
args.add(value);
});
// 优惠券活动过期时间转换为秒级别的 Unix 时间戳
args.add(String.valueOf(couponTemplateDO.getValidEndTime().getTime() / 1000));
// 执行 LUA 脚本
stringRedisTemplate.execute(
new DefaultRedisScript<>(luaScript, Long.class),
keys,
args.toArray()
);
couponTemplateCacheMap = cacheTargetMap.entrySet()
.stream()
.collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue));
}
} finally {
lock.unlock();
}
}
return BeanUtil.mapToBean(couponTemplateCacheMap, CouponTemplateQueryRespDTO.class, false, CopyOptions.create());
}
}
public final class EngineRedisConstant {
/**
* 优惠券模板缓存 Key
*/
public static final String COUPON_TEMPLATE_KEY = "one-coupon_engine:template:%s";
/**
* 优惠券模板缓存分布式锁 Key
*/
public static final String LOCK_COUPON_TEMPLATE_KEY = "one-coupon_engine:lock:template:%s";
}
第17小节:用户查询优惠券之缓存穿透
业务背景
在上一节中,我们讨论了正常用户在访问优惠券时可能遇到的缓存击穿问题,并介绍了缓存预热、缓存永不过期、分布式锁、双重判定锁、分片分布式锁等技术来应对这些问题。然而,还有一个问题需要解决:如果用户频繁访问数据库中不存在的数据,就无法有效使用缓存,每次都需要访问数据库,这将导致数据库承受较大的压力。这也就是缓存穿透问题。
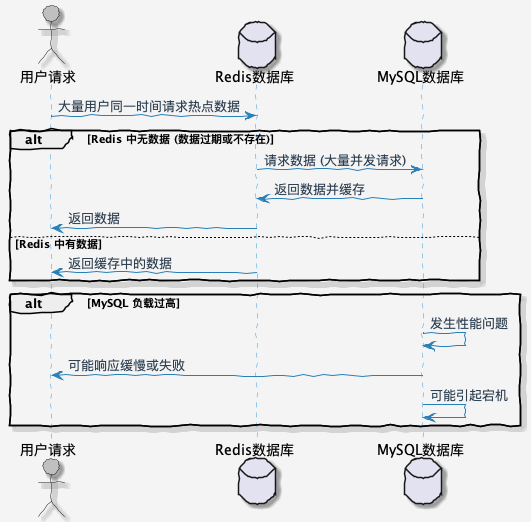
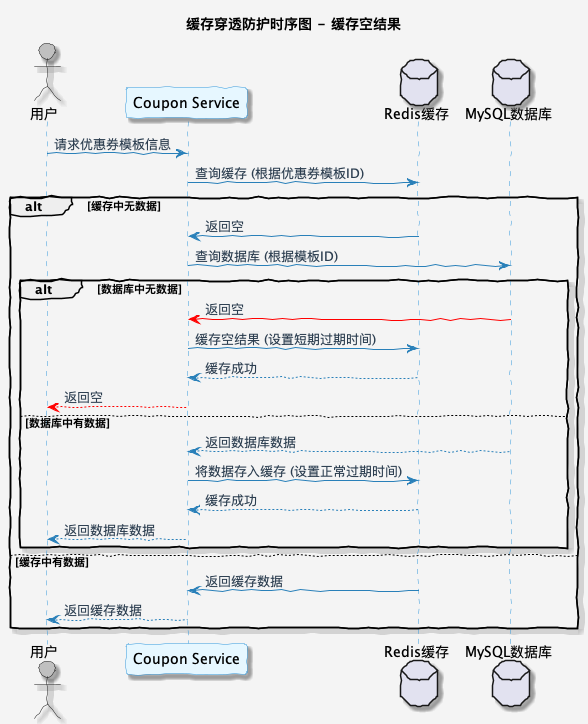
缓存穿透问题时序图如下所示:
Git 分支
20240827_dev_coupon-template-querypv-v2_cache_ding.ma
什么是缓存穿透?
缓存穿透是指由于请求没有办法命中缓存,因此就会直接打到数据库,当请求量较大时,大量的请求就可能会直接把数据库打挂。
通常情况下,缓存是为了提高数据访问速度,避免频繁查询数据库。但如果攻击者故意请求缓存中不存在的数据,就会导致缓存不命中,请求直接访问数据库。
没有经过缓存穿透处理的业务伪代码如下:
public String selectUser(String userId) {
String cacheData = cache.get(userId);
if (StrUtil.isBlank(cacheData)) {
String dbData = userMapper.selectId(userId);
if (StrUtil.isNotBlank(dbData)) {
cahce.set(userId, dbData);
cacheData = dbData;
} else {
throw new RuntimeException();
}
}
return cacheData;
}缓存穿透常见解决方案
1. 空对象缓存
当查询结果为空时,也将结果进行缓存,但是设置一个较短的过期时间。这样在接下来的一段时间内,如果再次请求相同的数据,就可以直接从缓存中获取,而不是再次访问数据库,可以一定程度上解决缓存穿透问题。
缓存空值逻辑伪代码实现如下:
public String selectUser(String userId) {
String cacheData = cache.get(userId);
if (StrUtil.isBlank(cacheData)) {
// 判断 Key 是否包含空值缓存,存在直接返回,不存在继续流程
Boolean cacheIsNull = cache.hasKey("is-null_" + userId);
if (cacheIsNull) {
throw new RuntimeException();
}
String dbData = userMapper.selectId(userId);
if (StrUtil.isNotBlank(dbData)) {
cahce.set(userId, dbData);
cacheData = dbData;
} else {
// 查询数据库中不存在数据,添加空值缓存并返回
cache.set("is-null_" + userId, 较短过期时间);
throw new RuntimeException();
}
}
return cacheData;
}这种方式是比较简单的一种实现方案,会存在一些弊端。那就是当短时间内存在大量恶意请求,缓存系统会存在大量的内存占用。
2. 布隆过滤器
2.1 什么是布隆过滤器
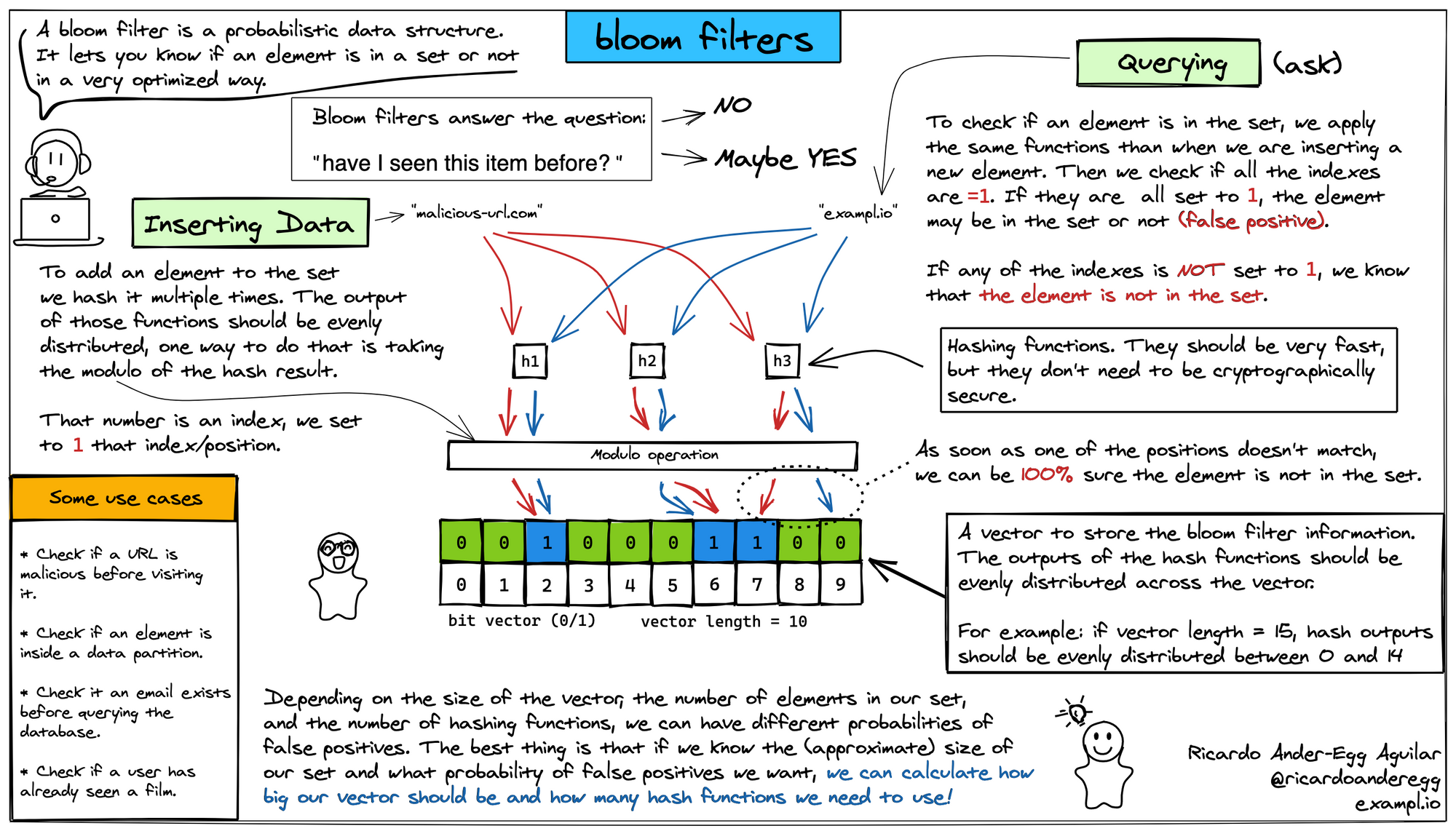
布隆过滤器是一种数据结构,用于快速判断一个元素是否存在于一个集合中。它以牺牲一定的准确性为代价,换取了存储空间的极大节省和查询速度的显著提升。
具体来说,布隆过滤器包含一个位数组和一组哈希函数。位数组的初始值全部置为 0。在插入一个元素时,将该元素经过多个哈希函数映射到位数组上的多个位置,并将这些位置的值置为 1。
因为每个元素存储都是以位来存储,而不是字节,所以元素的占用空间非常小。
1 字节(Byte)= 8 位(Bit)在计算机科学中,数据存储的最小单位是位(Bit),而字节(Byte)则是一个常用的数据存储单位,通常由8个位组成。
在查询一个元素是否存在时,会将该元素经过多个哈希函数映射到位数组上的多个位置,如果所有位置的值都为 1,则认为元素存在;如果存在任一位置的值为 0,则认为元素不存在。
2.2 布隆过滤器优缺点
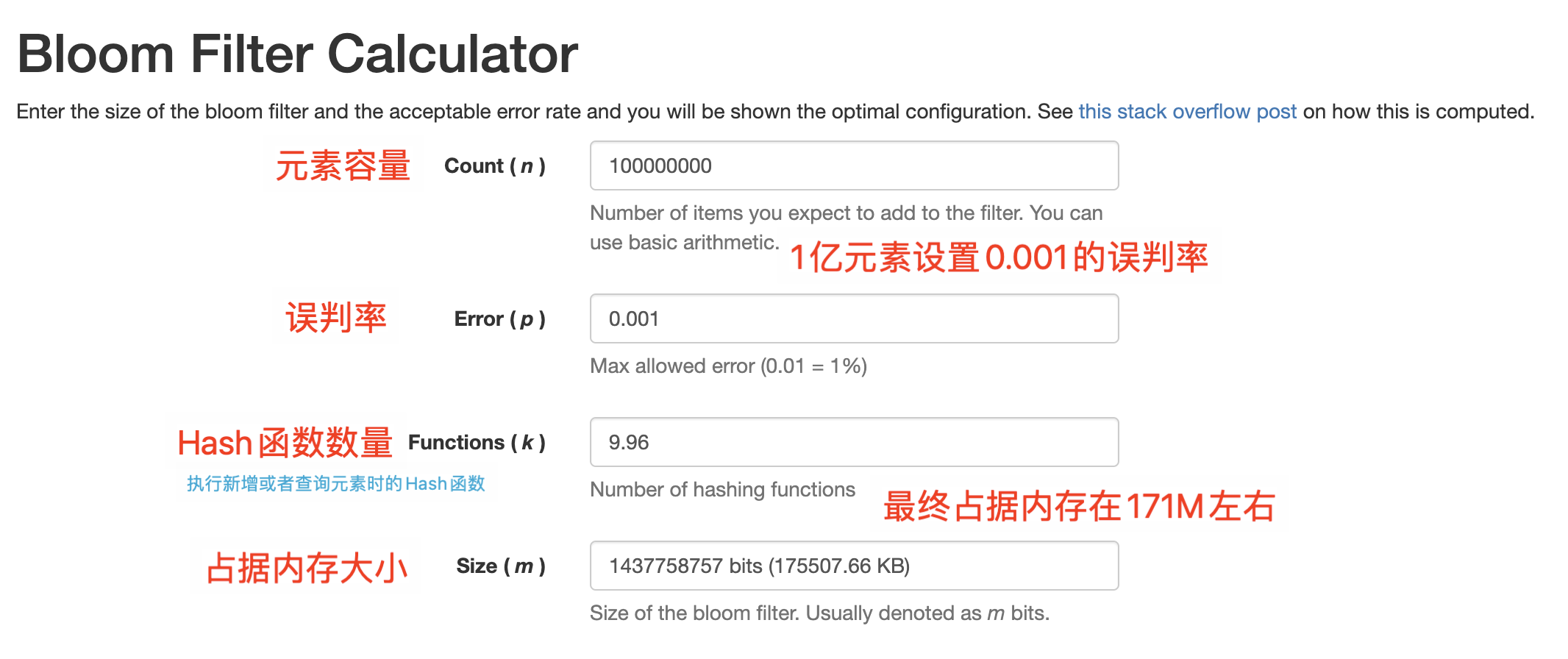
布隆过滤器的优点在于它可以高效地判断一个元素是否属于一个大规模集合,且具有极低的存储空间要求。如果存储 1亿元素,误判率设置为 0.001 也就是千分之一,仅需要占用 171M 左右的内存。
缺点在于可能会存在一定的误判率。
它在实际应用中常用于缓存场景下缓存穿透问题,对访问请求做一个快速判断机制。使用布隆过滤器能够有效减轻对底层存储系统的访问以及缓存系统的存储压力。
但是布隆过滤器本身也存在一些“弊端”,那就是不支持删除元素。因为它是一种基于哈希的数据结构,删除元素会涉及到多个哈希函数之间的冲突问题,这样会导致删除一个元素可能会影响到其他元素的正确性。
总的来说,布隆过滤器是一种非常高效的数据结构,适用于那些可以容忍一定的误判率的场合。
2.3 布隆过滤器解决缓存穿透
可以将所有存量数据全部放入布隆过滤器,然后如果缓存中不存在数据,紧接着判断布隆过滤器是否存在,如果存在访问数据库请求数据,如果不存在直接返回错误响应即可。
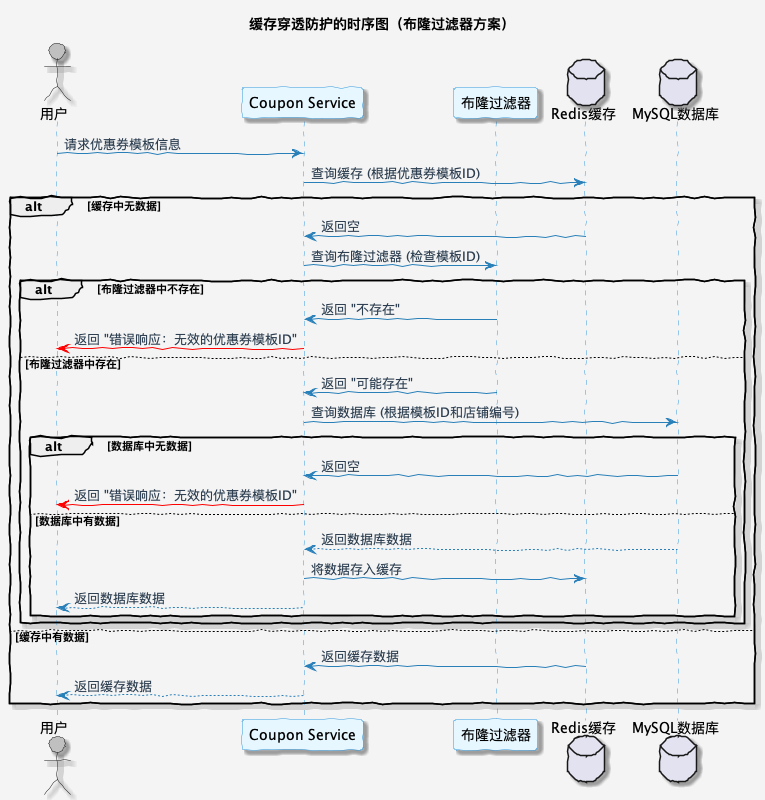
使用布隆过滤器解决缓存穿透伪代码如下:
public String selectUser(String userId) {
String cacheData = cache.get(userId);
if (StrUtil.isBlank(cacheData)) {
if (!bloomFilter.contains(fullShortUrl)) {
throw new RuntimeException();
}
String dbData = userMapper.selectId(userId);
if (StrUtil.isNotBlank(dbData)) {
cahce.set(userId, dbData);
cacheData = dbData;
}
}
return cacheData;
}但是这种问题还是会有一些小概率问题,那就是如果使用一种小概率误判的缓存进行攻击,依然会对数据库造成比较大的压力。这个怎么理解呢?
- 1. 比如说一个优惠券 ID 是 1827975299049058306,我通过优惠券 ID 规则,模拟一个不存在的但很相近的,比如 1827975299049058307,去碰撞那个误判的概率;
- 2. 怎么判断这个数据是不是存在?就是看接口的响应时间,直接查询缓存和布隆过滤器是绝对的毫秒级,比如 5 毫秒,而且性能基本上比较恒定。那我们就可以根据相应时间是否大于 5 毫秒,因为误判了还会查一次数据库;
- 3. 如果查询第一次大于 5 毫秒且数据返回为空,那就证明这是个碰撞漏网之鱼,直接拿高并发访问即可,还是会请求到数据库。
3. 布隆过滤器+空值缓存+分布式锁
如果说缓存不存在,那么就通过布隆过滤器进行初步筛选,然后判断是否存在缓存空值,如果存在直接返回失败。如果不存在缓存空值,使用锁机制避免多个相同请求同时访问数据库。最后,如果请求数据库为空,那么将为空的 Key 进行空对象值缓存。

多重方案伪代码如下所示:
public String selectUser(String userId) {
String cacheData = cache.get(userId);
if (StrUtil.isBlank(cacheData)) {
// 判断 Key 是否存在布隆过滤器,存在则继续流程,否则直接返回
if (!bloomFilter.contains(fullShortUrl)) {
throw new RuntimeException();
}
// 判断 Key 是否包含空值缓存,存在直接返回,不存在继续流程
Boolean cacheIsNull = cache.hasKey("is-null_" + userId);
if (cacheIsNull) {
throw new RuntimeException();
}
// 获取分布式锁
Lock lock = getLock(userId);
lock.lock();
try {
// 拿到锁之后进行双重判定,如果缓存已经存在则直接返回即可
cacheData = cache.get(userId);
if (StrUtil.isBlank(cacheData)) {
String dbData = userMapper.selectId(userId);
if (StrUtil.isNotBlank(dbData)) {
cahce.set(userId, dbData);
cacheData = dbData;
} else {
// 查询数据库中不存在数据,添加空值缓存并返回
cache.set("is-null_" + userId, 较短过期时间);
throw new RuntimeException();
}
}
} finally {
lock.unlock();
}
}
return cacheData;
}之前我考虑到这就结束了,得益于我开源的 SaaS 短链接项目,有很多细心的同学给我提了一些建议。那就是在获取到锁后,不止对正常缓存双重判定,同时也要对空值缓存对象做双重判定。
public String selectUser(String userId) {
String cacheData = cache.get(userId);
if (StrUtil.isBlank(cacheData)) {
// 判断 Key 是否存在布隆过滤器,存在则继续流程,否则直接返回
if (!bloomFilter.contains(fullShortUrl)) {
throw new RuntimeException();
}
// 判断 Key 是否包含空值缓存,存在直接返回,不存在继续流程
Boolean cacheIsNull = cache.hasKey("is-null_" + userId);
if (cacheIsNull) {
throw new RuntimeException();
}
// 获取分布式锁
Lock lock = getLock(userId);
lock.lock();
try {
// 拿到锁之后进行双重判定,如果缓存已经存在则直接返回即可
cacheData = cache.get(userId);
if (StrUtil.isNotBlank(cacheData)) {
return cacheData;
}
// 拿到锁之后进行双重判定,如果空值缓存已经存在则直接终止流程即可
cacheIsNull = cache.hasKey("is-null_" + userId);
if (!cacheIsNull) {
throw new RuntimeException();
}
// 根据用户标识查询数据库记录
String dbData = userMapper.selectId(userId);
if (StrUtil.isNotBlank(dbData)) {
cahce.set(userId, dbData);
cacheData = dbData;
} else {
// 查询数据库中不存在数据,添加空值缓存并返回
cache.set("is-null_" + userId, 较短过期时间);
throw new RuntimeException();
}
} finally {
lock.unlock();
}
}
return cacheData;
}至此,缓存穿透解决方案完美结束。
上面写得缓存穿透代码思路,只要不出现极端场景,大概率能涵盖 90% 工作当中的业务场景。
优惠券模板引入缓存穿透解决方案
1. 创建布隆过滤器
下面这个配置需要在优惠券后管和引擎模块都需要添加,以后管中配置代码举例:
@Configuration
public class RBloomFilterConfiguration {
/**
* 优惠券查询缓存穿透布隆过滤器
*/
@Bean
public RBloomFilter<String> couponTemplateQueryBloomFilter(RedissonClient redissonClient) {
RBloomFilter<String> bloomFilter = redissonClient.getBloomFilter("couponTemplateQueryBloomFilter");
bloomFilter.tryInit(640L, 0.001);
return bloomFilter;
}
}
其中 tryInit 有两个参数,代表预估插入量和错误概率,因为会根据这两个参数进行初始化布隆过滤器的位数组,不建议大家设置太大。
2.1 预计插入量 expectedInsertions
这是一个估计值,表示布隆过滤器预期将会插入的元素总数。
通过知道预期的插入量,布隆过滤器可以根据这个估计值来合理地配置位数组的大小和哈希函数的数量。这样可以在达到指定错误率的情况下,最大限度地节省内存。插入的元素数量如果超出预期,会增加误判的概率。
2.2 错误概率 falseProbability
表示布隆过滤器在给定条件下可能返回错误结果的概率。
错误概率用于在布隆过滤器初始化时确定其位数组的大小和哈希函数的数量。较低的误判率意味着需要更大的位数组和更多的哈希函数,从而占用更多的内存和计算时间。反之,较高的误判率则意味着更少的内存占用和计算成本,但错误判定的概率也会增加。
2. 创建优惠券模板添加布隆过滤器
我们创建优惠券模板方法里,需要将优惠券模板 ID 存一份到布隆过滤器中,代码如下:
@Slf4j
@Service
@RequiredArgsConstructor
public class CouponTemplateServiceImpl extends ServiceImpl<CouponTemplateMapper, CouponTemplateDO> implements CouponTemplateService {
// ......
private final RBloomFilter<String> couponTemplateQueryBloomFilter;
@Override
public void createCouponTemplate(CouponTemplateSaveReqDTO requestParam) {
// ......
// 添加优惠券模板 ID 到布隆过滤器
couponTemplateQueryBloomFilter.add(String.valueOf(couponTemplateDO.getId()));
}
}3. 改造优惠券模板查询缓存穿透
我们先写一个单独的缓存穿透解决方案,后面再和击穿逻辑结合一起。
查询优惠券模板请求第一步,判断布隆过滤器是否存在指定模板 ID,不存在直接返回错误。
@Slf4j
@Service
@RequiredArgsConstructor
public class CouponTemplateServiceImpl extends ServiceImpl<CouponTemplateMapper, CouponTemplateDO> implements CouponTemplateService {
private final RBloomFilter<String> couponTemplateQueryBloomFilter;
@Override
public CouponTemplateQueryRespDTO findCouponTemplate(CouponTemplateQueryReqDTO requestParam) {
if (!couponTemplateQueryBloomFilter.contains(requestParam.getCouponTemplateId())) {
throw new ClientException("优惠券模板不存在");
}
LambdaQueryWrapper<CouponTemplateDO> queryWrapper = Wrappers.lambdaQuery(CouponTemplateDO.class)
.eq(CouponTemplateDO::getShopNumber, Long.parseLong(requestParam.getShopNumber()))
.eq(CouponTemplateDO::getId, Long.parseLong(requestParam.getCouponTemplateId()))
.eq(CouponTemplateDO::getStatus, CouponTemplateStatusEnum.ACTIVE.getStatus());
CouponTemplateDO couponTemplateDO = couponTemplateMapper.selectOne(queryWrapper);
return BeanUtil.toBean(couponTemplateDO, CouponTemplateQueryRespDTO.class);
}
}4. 改造组合方案
我们在这个方法里,引入缓存布隆过滤器、空值以及分布式锁逻辑,应用到我们的优惠券模板查询解决方案中。
代码看着挺多,但是都是按照我们上面讲的布隆过滤器、控制缓存、分布式锁逻辑一步步来的。
@Slf4j
@Service
@RequiredArgsConstructor
public class CouponTemplateServiceImpl extends ServiceImpl<CouponTemplateMapper, CouponTemplateDO> implements CouponTemplateService {
private final CouponTemplateMapper couponTemplateMapper;
private final StringRedisTemplate stringRedisTemplate;
private final RedissonClient redissonClient;
private final RBloomFilter<String> couponTemplateQueryBloomFilter;
@Override
public CouponTemplateQueryRespDTO findCouponTemplate(CouponTemplateQueryReqDTO requestParam) {
// 查询 Redis 缓存中是否存在优惠券模板信息
String couponTemplateCacheKey = String.format(EngineRedisConstant.COUPON_TEMPLATE_KEY, requestParam.getCouponTemplateId());
Map<Object, Object> couponTemplateCacheMap = stringRedisTemplate.opsForHash().entries(couponTemplateCacheKey);
// 如果存在直接返回,不存在需要通过布隆过滤器、缓存空值以及双重判定锁的形式读取数据库中的记录
if (MapUtil.isEmpty(couponTemplateCacheMap)) {
// 判断布隆过滤器是否存在指定模板 ID,不存在直接返回错误
if (!couponTemplateQueryBloomFilter.contains(requestParam.getCouponTemplateId())) {
throw new ClientException("优惠券模板不存在");
}
// 查询 Redis 缓存中是否存在优惠券模板空值信息,如果有代表模板不存在,直接返回
String couponTemplateIsNullCacheKey = String.format(EngineRedisConstant.COUPON_TEMPLATE_IS_NULL_KEY, requestParam.getCouponTemplateId());
Boolean hasKeyFlag = stringRedisTemplate.hasKey(couponTemplateIsNullCacheKey);
if (hasKeyFlag) {
throw new ClientException("优惠券模板不存在");
}
// 获取优惠券模板分布式锁
// 关于缓存击穿更多注释事项,欢迎查看我的B站视频:https://www.bilibili.com/video/BV1qz421z7vC
RLock lock = redissonClient.getLock(String.format(EngineRedisConstant.LOCK_COUPON_TEMPLATE_KEY, requestParam.getCouponTemplateId()));
lock.lock();
try {
// 双重判定空值缓存是否存在,存在则继续抛异常
hasKeyFlag = stringRedisTemplate.hasKey(couponTemplateIsNullCacheKey);
if (hasKeyFlag) {
throw new ClientException("优惠券模板不存在");
}
// 通过双重判定锁优化大量请求无意义查询数据库
couponTemplateCacheMap = stringRedisTemplate.opsForHash().entries(couponTemplateCacheKey);
if (MapUtil.isEmpty(couponTemplateCacheMap)) {
LambdaQueryWrapper<CouponTemplateDO> queryWrapper = Wrappers.lambdaQuery(CouponTemplateDO.class)
.eq(CouponTemplateDO::getShopNumber, Long.parseLong(requestParam.getShopNumber()))
.eq(CouponTemplateDO::getId, Long.parseLong(requestParam.getCouponTemplateId()))
.eq(CouponTemplateDO::getStatus, CouponTemplateStatusEnum.ACTIVE.getStatus());
CouponTemplateDO couponTemplateDO = couponTemplateMapper.selectOne(queryWrapper);
// 优惠券模板不存在或者已过期加入空值缓存,并且抛出异常
if (couponTemplateDO == null) {
stringRedisTemplate.opsForValue().set(couponTemplateIsNullCacheKey, "", 30, TimeUnit.MINUTES);
throw new ClientException("优惠券模板不存在或已过期");
}
// 通过将数据库的记录序列化成 JSON 字符串放入 Redis 缓存
CouponTemplateQueryRespDTO actualRespDTO = BeanUtil.toBean(couponTemplateDO, CouponTemplateQueryRespDTO.class);
Map<String, Object> cacheTargetMap = BeanUtil.beanToMap(actualRespDTO, false, true);
Map<String, String> actualCacheTargetMap = cacheTargetMap.entrySet().stream()
.collect(Collectors.toMap(
Map.Entry::getKey,
entry -> entry.getValue() != null ? entry.getValue().toString() : ""
));
// 通过 LUA 脚本执行设置 Hash 数据以及设置过期时间
String luaScript = "redis.call('HMSET', KEYS[1], unpack(ARGV, 1, #ARGV - 1)) " +
"redis.call('EXPIREAT', KEYS[1], ARGV[#ARGV])";
List<String> keys = Collections.singletonList(couponTemplateCacheKey);
List<String> args = new ArrayList<>(actualCacheTargetMap.size() * 2 + 1);
actualCacheTargetMap.forEach((key, value) -> {
args.add(key);
args.add(value);
});
// 优惠券活动过期时间转换为秒级别的 Unix 时间戳
args.add(String.valueOf(couponTemplateDO.getValidEndTime().getTime() / 1000));
// 执行 LUA 脚本
stringRedisTemplate.execute(
new DefaultRedisScript<>(luaScript, Long.class),
keys,
args.toArray()
);
couponTemplateCacheMap = cacheTargetMap.entrySet()
.stream()
.collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue));
}
} finally {
lock.unlock();
}
}
return BeanUtil.mapToBean(couponTemplateCacheMap, CouponTemplateQueryRespDTO.class, false, CopyOptions.create());
}
/**
* 缓存击穿解决方案
*/
public CouponTemplateQueryRespDTO findCouponTemplateV1(CouponTemplateQueryReqDTO requestParam) {
// 查询 Redis 缓存中是否存在优惠券模板信息
String couponTemplateCacheKey = String.format(EngineRedisConstant.COUPON_TEMPLATE_KEY, requestParam.getCouponTemplateId());
Map<Object, Object> couponTemplateCacheMap = stringRedisTemplate.opsForHash().entries(couponTemplateCacheKey);
// 如果存在直接返回,不存在需要通过双重判定锁的形式读取数据库中的记录
if (MapUtil.isEmpty(couponTemplateCacheMap)) {
// 获取优惠券模板分布式锁
// 关于缓存击穿更多注释事项,欢迎查看我的B站视频:https://www.bilibili.com/video/BV1qz421z7vC
RLock lock = redissonClient.getLock(String.format(EngineRedisConstant.LOCK_COUPON_TEMPLATE_KEY, requestParam.getCouponTemplateId()));
lock.lock();
try {
// 通过双重判定锁优化大量请求无意义查询数据库
couponTemplateCacheMap = stringRedisTemplate.opsForHash().entries(couponTemplateCacheKey);
if (MapUtil.isEmpty(couponTemplateCacheMap)) {
LambdaQueryWrapper<CouponTemplateDO> queryWrapper = Wrappers.lambdaQuery(CouponTemplateDO.class)
.eq(CouponTemplateDO::getShopNumber, Long.parseLong(requestParam.getShopNumber()))
.eq(CouponTemplateDO::getId, Long.parseLong(requestParam.getCouponTemplateId()))
.eq(CouponTemplateDO::getStatus, CouponTemplateStatusEnum.ACTIVE.getStatus());
CouponTemplateDO couponTemplateDO = couponTemplateMapper.selectOne(queryWrapper);
// 优惠券模板不存在或者已过期直接抛出异常
if (couponTemplateDO == null) {
throw new ClientException("优惠券模板不存在或已过期");
}
// 通过将数据库的记录序列化成 JSON 字符串放入 Redis 缓存
CouponTemplateQueryRespDTO actualRespDTO = BeanUtil.toBean(couponTemplateDO, CouponTemplateQueryRespDTO.class);
Map<String, Object> cacheTargetMap = BeanUtil.beanToMap(actualRespDTO, false, true);
Map<String, String> actualCacheTargetMap = cacheTargetMap.entrySet().stream()
.collect(Collectors.toMap(
Map.Entry::getKey,
entry -> entry.getValue() != null ? entry.getValue().toString() : ""
));
// 通过 LUA 脚本执行设置 Hash 数据以及设置过期时间
String luaScript = "redis.call('HMSET', KEYS[1], unpack(ARGV, 1, #ARGV - 1)) " +
"redis.call('EXPIREAT', KEYS[1], ARGV[#ARGV])";
List<String> keys = Collections.singletonList(couponTemplateCacheKey);
List<String> args = new ArrayList<>(actualCacheTargetMap.size() * 2 + 1);
actualCacheTargetMap.forEach((key, value) -> {
args.add(key);
args.add(value);
});
// 优惠券活动过期时间转换为秒级别的 Unix 时间戳
args.add(String.valueOf(couponTemplateDO.getValidEndTime().getTime() / 1000));
// 执行 LUA 脚本
stringRedisTemplate.execute(
new DefaultRedisScript<>(luaScript, Long.class),
keys,
args.toArray()
);
couponTemplateCacheMap = cacheTargetMap.entrySet()
.stream()
.collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue));
}
} finally {
lock.unlock();
}
}
return BeanUtil.mapToBean(couponTemplateCacheMap, CouponTemplateQueryRespDTO.class, false, CopyOptions.create());
}
/**
* 缓存穿透解决方案之布隆过滤器
*/
public CouponTemplateQueryRespDTO findCouponTemplateV2(CouponTemplateQueryReqDTO requestParam) {
// 判断布隆过滤器是否存在指定模板 ID,不存在直接返回错误
if (!couponTemplateQueryBloomFilter.contains(requestParam.getCouponTemplateId())) {
throw new ClientException("优惠券模板不存在");
}
LambdaQueryWrapper<CouponTemplateDO> queryWrapper = Wrappers.lambdaQuery(CouponTemplateDO.class)
.eq(CouponTemplateDO::getShopNumber, Long.parseLong(requestParam.getShopNumber()))
.eq(CouponTemplateDO::getId, Long.parseLong(requestParam.getCouponTemplateId()))
.eq(CouponTemplateDO::getStatus, CouponTemplateStatusEnum.ACTIVE.getStatus());
CouponTemplateDO couponTemplateDO = couponTemplateMapper.selectOne(queryWrapper);
return BeanUtil.toBean(couponTemplateDO, CouponTemplateQueryRespDTO.class);
}
}
如果我们按照正常逻辑,是没有办法触发缓存空值等操作的。所以需要在正常逻辑下,加一些人工破坏,流程如下:
- 1. 确保商家后管系统已经接入了布隆过滤器流程,通过商家后管系统添加新的优惠券;
- 2. 去数据库把刚才那一条记录删除或者 status 设置为 1 也就是已结束状态。
通过这种方式,大家就能触发类似于布隆过滤器误判,然后触发缓存空值和分布式锁等流程。
常见问题答疑
1. 布隆过滤器设置多大容量?
布隆过滤器的容量就取决于业务的数量,我们之前在分库分表的章节上说,可能有 300 亿的优惠券模板数量,是不是直接设置为布隆过滤器的容量就好了?
不行的,你可以尝试下设置 300 亿预估元素以及千分之一的误判率,绝对会报错。因为
Bloom filter size can't be greater than 4294967294. But calculated size is 431327626981
简单梳理了下,意思是:布隆过滤器大小不能超过 4294967294,但是咱们的参数 300 亿预估值和 千分之一的误判率,已经超过了这个数据。
如果设置 300 亿数据预估值但是设置百分之一的误判率,那么报错就换了一个。可以看到布隆过滤器给我们设置了上限,不能超过。
Bloom filter size can't be greater than 4294967294. But calculated size is 287551751321
小知识点,一个亿的元素,如果千分之一的误判率,那么实际容量大概在 170M 左右。另外在对布隆过滤器进行初始化的时候,会一次性申请对应的内存,这个需要额外注意下,避免初始化超大容量布隆过滤器时内存不足问题。
那这种情况下如何解决布隆过滤器不能设置 300 亿数据问题?
可以像之前在处理缓存击穿时所用的分片逻辑一样,设置多个布隆过滤器,使得这些分片的布隆过滤器总容量能达到 300 亿。然后根据模板 ID 进行分片,确定要操作的布隆过滤器,从而在该分片上进行操作。
2. 分布式锁 lock 会触发长时间阻塞么?
这个逻辑和缓存击穿里的逻辑是一样的,大家可以参考缓存击穿章节中的 tryLock 和分布式锁分片处理方案。
第18小节:如何设置Redis内存淘汰策略?
业务背景
在之前讨论缓存击穿的问题时,有一个关键点没有详细介绍,那就是如何与 Redis 的内存淘汰策略结合使用。仅仅依靠缓存预热和设置数据永不过期并不是一个全面的解决方案,还需要考虑合适的内存淘汰策略来保障缓存击穿方案有效执行。
什么是内存淘汰?
内存总是有限的,因此当 Redis 内存超出最大内存时,就需要根据一定的策略去主动的淘汰一些 Key,来腾出内存,这就是内存淘汰策略。我们可以在配置文件中通过 maxmemory-policy 配置指定策略。
与到期删除策略不同,内存淘汰策略主要目的则是为了防止运行时内存超过最大内存,所以尽管最终目的都是清理内存中的一些 Key,但是它们的应用场景和触发时机是不同的。
算上在 4.0 添加的两种基于 LFU 算法的策略, Redis 一共提供了八种策略供我们选择:
noeviction,不淘汰任何 key,直接报错。它是默认策略。volatile-random:从所有设置了到期时间的 Key 中,随机淘汰一个 Key。volatile-lru: 从所有设置了到期时间的 Key 中,淘汰最近最少使用的 Key。volatile-lfu: 从所有设置了到期时间的 Key 中,淘汰最近最不常用使用的 Key(4.0 新增)。volatile-ttl: 从所有设置了到期时间的 Key 中,优先淘汰最早过期的 Key。allkeys-random:从所有 Key 中,随机淘汰一个键。allkeys-lru: 从所有 Key 中,淘汰最近最少使用的 Key。allkeys-lfu: 从所有 Key 中,淘汰最近最不常用使用的键(4.0 新增)。
从淘汰范围来说可以分为不淘汰任何数据、只从设置了到期时间的键中淘汰和从所有键中淘汰三类。而从淘汰算法来分,又主要分为 Random(随机),LRU(最近最少使用),以及 LFU(最近最不常使用)三种。
其中,关于 LRU 算法,它是一种非常常见的缓存淘汰算法。我们可以简单理解为 Redis 会在每次访问 Key 的时候记录访问时间,当淘汰时,优先淘汰最后一次访问距离现在最早的 Key。
而对于 LFU 算法,我们可以理解为 Redis 会在访问 Key 时,根据两次访问时间的间隔计算并累加访问频率指标,当淘汰时,优先淘汰访问频率指标最低的 key。相比 LRU 算法,它避免了低频率的大批量查询造成的缓存污染问题。
什么是缓存污染问题?
LRU 有个最大问题,就是它只认最近一次访问时间。而如果出现系统偶尔需要一次性读取大量数据的时候,会大规模更新 Key 的最近访问时间,从而导致真正需要被频繁访问的 Key 因为最近一次访问时间更早而被直接淘汰。这种情况被称为缓存污染。为此,我们需要使用 LFU 算法来解决。
淘汰策略对缓存击穿的影响?
举个例子,我们操作了缓存预热和设置 Redis 永不过期,如果说设置 Redis 内存淘汰策略是以下类型:
allkeys-random:从所有 Key 中,随机淘汰一个键。allkeys-lru: 从所有 Key 中,淘汰最近最少使用的 Key。allkeys-lfu: 从所有 Key 中,淘汰最近最不常用使用的键(4.0 新增)。
因为是从所有键中去执行淘汰算法,是否有可能将咱们设置的热 Key 或者说访问较多的 Key 给淘汰掉?第一种绝对有可能,第二三种虽然概率比较小,但是也不是没可能。
所以,我们只能从这几个淘汰算法中进行选择:
noeviction,不淘汰任何 Key,直接报错。volatile-random:从所有设置了到期时间的 Key 中,随机淘汰一个 Key。volatile-lru: 从所有设置了到期时间的 Key 中,淘汰最近最少使用的 Key。volatile-lfu: 从所有设置了到期时间的 Key 中,淘汰最近最不常用使用的 Key(4.0 新增)。volatile-ttl: 从所有设置了到期时间的 Key 中,优先淘汰最早过期的 Key。
牛券选择哪个淘汰策略?
从常规上来说,如果大家公司 Redis 比较豪,也就是业务挣钱,在资源上不吝啬,必然毫不犹豫选择 noeviction 不淘汰任何任何数据。
简单的来说,如果你的业务数据的访问比较平均,不存在明显的冷热区别,那么 LRU 可以满足一般的使用需求。如果你的业务具备很强的时效性,而且是存在大促商品这种明显的热点数据,那么推荐你使用 LFU。
因为牛券里的一些模板也不全是常用的,适当内存吃紧的时候可以淘汰一部分带过期时间的 Key,再加上牛券中的优惠券存在明显的冷热数据现象,我建议使用 volatile-lfu,可以有效避免 LRU 的缓存污染问题。
以下内容了解即可,如不容易理解,可跳过知道如何应用即可。
内存淘汰底层原理
1. 淘汰过程
Redis 内存淘汰执行流程如下:
- 1. 每次当 Redis 执行命令时,若设置了最大内存大小
maxmemory,并设置了淘汰策略式,则会尝试进行一次 Key 淘汰; - 2. Redis 首先会评估已使用内存(这里不包含主从复制使用的两个缓冲区占用的内存)是否大于
maxmemory,如果没有则直接返回,否则将计算当前需要释放多少内存,随后开始根据策略淘汰符合条件的 Key;当开始进行淘汰时,将会依次对每个数据库进行抽样,抽样的数据范围由策略决定,而样本数量则由maxmemory-samples配置决定; - 3. 完成抽样后,Redis 会尝试将样本放入提前初始化好
EvictionPoolLRU数组中,它相当于一个临时缓冲区,当数组填满以后即将里面全部的 Key 进行删除。 - 4. 若一次删除后内存仍然不足,则再次重复上一步骤,将样本中的剩余 Key 再次填入数组中进行删除,直到释放了足够的内存,或者本次抽样的所有 Key 都被删除完毕(如果此时内存还是不足,那么就重新执行一次淘汰流程)。
在抽样这一步,涉及到从字典中随机抽样这个过程,由于哈希表的 Key 是散列分布的,因此会有很多桶都是空的,纯随机效率可能会很低。因此,Redis 采用了一个特别的做法,那就是先连续遍历数个桶,如果都是空的,再随机调到另一个位置,再连续遍历几个桶……如此循环,直到结束抽样。
你可以参照源码理解这个过程:
unsigned int dictGetSomeKeys(dict *d, dictEntry **des, unsigned int count) {
unsigned long j; /* internal hash table id, 0 or 1. */
unsigned long tables; /* 1 or 2 tables? */
unsigned long stored = 0, maxsizemask;
unsigned long maxsteps;
if (dictSize(d) < count) count = dictSize(d);
maxsteps = count*10;
// 如果字典正在迁移,则协助迁移
for (j = 0; j < count; j++) {
if (dictIsRehashing(d))
_dictRehashStep(d);
else
break;
}
tables = dictIsRehashing(d) ? 2 : 1;
maxsizemask = d->ht[0].sizemask;
if (tables > 1 && maxsizemask < d->ht[1].sizemask)
maxsizemask = d->ht[1].sizemask;
unsigned long i = random() & maxsizemask;
unsigned long emptylen = 0;
// 当已经采集到足够的样本,或者重试已达上限则结束采样
while(stored < count && maxsteps--) {
for (j = 0; j < tables; j++) {
if (tables == 2 && j == 0 && i < (unsigned long) d->rehashidx) {
if (i >= d->ht[1].size)
i = d->rehashidx;
else
continue;
}
// 如果一个库的到期字典已经处理完毕,则处理下一个库
if (i >= d->ht[j].size) continue;
dictEntry *he = d->ht[j].table[i];
// 连续遍历多个桶,如果多个桶都是空的,那么随机跳到另一个位置,然后再重复此步骤
if (he == NULL) {
emptylen++;
if (emptylen >= 5 && emptylen > count) {
i = random() & maxsizemask;
emptylen = 0;
}
} else {
emptylen = 0;
while (he) {
*des = he;
des++;
he = he->next;
stored++;
if (stored == count) return stored;
}
}
}
// 查找下一个桶
i = (i+1) & maxsizemask;
}
return stored;
}2. LRU 实现
LRU 的全称为 Least Recently Used,也就是最近最少使用。一般来说,LRU 会从一批 Key 中淘汰上次访问时间最早的 key。
它是一种非常常见的缓存回收算法,在诸如 Guava Cache、Caffeine等缓存库中都提供了类似的实现。我们自己也可以基于 JDK 的 LinkedHashMap 实现支持 LRU 算法的缓存功能。
2.1 近似 LRU
传统的 LRU 算法实现通常会维护一个链表,当访问过某个节点后就将该节点移至链表头部。如此反复后,链表的节点就会按最近一次访问时间排序。当缓存数量到达上限后,我们直接移除尾节点,即可移除最近最少访问的缓存。
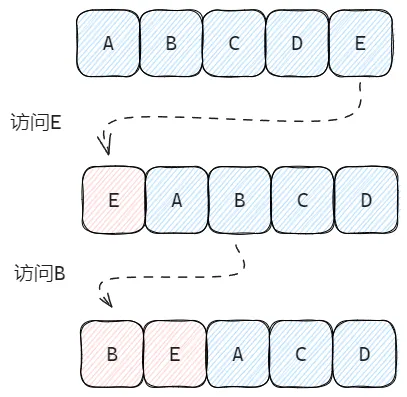
不过,对于 Redis 来说,如果每个 Key 添加的时候都需要额外的维护并操作这样一条链表,要额外付出的代价显然是不可接受的,因此 Redis 中的 LRU 是近似 LRU(NearlyLRU)。
当每次访问 Key 时,Redis 会在结构体中记录本次访问时间,而当需要淘汰 Key 时,将会从全部数据中进行抽样,然后再移除样本中上次访问时间最早的 key。
它的特点是:
- 仅当需要时再抽样,因而不需要维护全量数据组成的链表,这避免了额外内存消耗。
- 访问时仅在结构体上记录操作时间,而不需要操作链表节点,这避免了额外的性能消耗。
当然,有利就有弊,这种实现方式也决定 Redis 的 LRU 是并不是百分百准确的,被淘汰的 Key 未必真的就是所有 Key 中最后一次访问时间最早的。
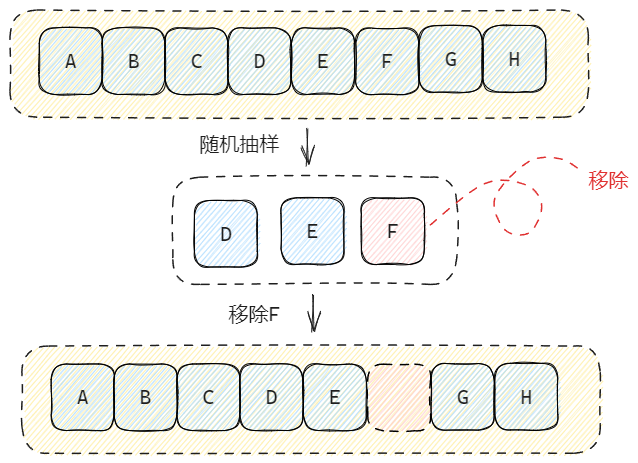
2.2 抽样大小
根据上述的内容,我们不难理解,当抽样的数量越大,LRU 淘汰 Key 就越准确,相对的开销也更大。因此,Redis 允许我们通过 maxmemory-samples 配置采样数量(默认为 5),从而在性能和精度上取得平衡。
3. LFU 实现
LFU 全称为 Least Frequently Used ,也就是最近最不常用。它的特点如下:
- 同样是基于抽样实现的近似算法,
maxmemory-samples对其同样有效。 - 比较的不是最后一次访问时间,而是数据的访问频率。当淘汰的时候,优先淘汰范围频率最低 Key。
它的实现与 LRU 基本一致,但是在计数部分则有所改进。
3.1 概率计数器
在 Redis 用来存储数据的结构体 redisObj 中,有一个 24 位的 lru数值字段:
- 当使用 LRU 算法时,它用于记录最后一次访问时间的时间戳。
- 当使用 LFU 算法时,它被分为两部分,高 16 位关于记录最近一次访问时间(
Last Decrement Time),而低 8 位作为记录访问频率计数器(Logistic Counter)。
LFU 的核心就在于低 8 位表示的访问频率计数器(下面我们简称为 counter),是一个介于 0 ~ 255 的特殊数值,它会每次访问 Key 时,基于时间衰减和概率递增机制动态改变。
这种基于概率,使用极小内存对大量事件进行计数的计数器被称为莫里斯计数器,它是一种概率计数法的实现。
3.2 时间衰减
每当访问 Key 时,根据当前实际与该 Key 的最后一次访问时间的时间差对 counter 进行衰减。
衰减值取决于 lfu_decay_time 配置,该配置表示一个衰减周期。我们可以简单的认为,每当时间间隔满足一个衰减周期时,就会对 counter 减一。
比如,我们设置 lfu_decay_time为 1 分钟,那么如果 Key 最后一次访问距离现在已有 3 分 30 秒,那么 counter 就需要减 3。
3.3 概率递增
在完成衰减后,Redis 将根据 lfu_log_factor 配置对应概率值对 counter 进行递增。
这里直接放上源码:
/* Logarithmically increment a counter. The greater is the current counter value * the less likely is that it gets really implemented. Saturate it at 255. */ uint8_t LFULogIncr(uint8_t counter) { // 若已达最大值 255,直接返回 if (counter == 255) return 255; // 获取一个介于 0 到 1 之间的随机值 double r = (double)rand()/RAND_MAX; // 根据当前 counter 减去初始值得到 baseval double baseval = counter - LFU_INIT_VAL; if (baseval < 0) baseval = 0; // 使用 baseval*server.lfu_log_factor+1 得到一个概率值 p double p = 1.0/(baseval*server.lfu_log_factor+1); // 当 r < p 时,递增 counter if (r < p) counter++; return counter; }
简而言之,直接从代码上理解,我们可以认为 counter和 lfu_log_factor 越大,则递增的概率越小:
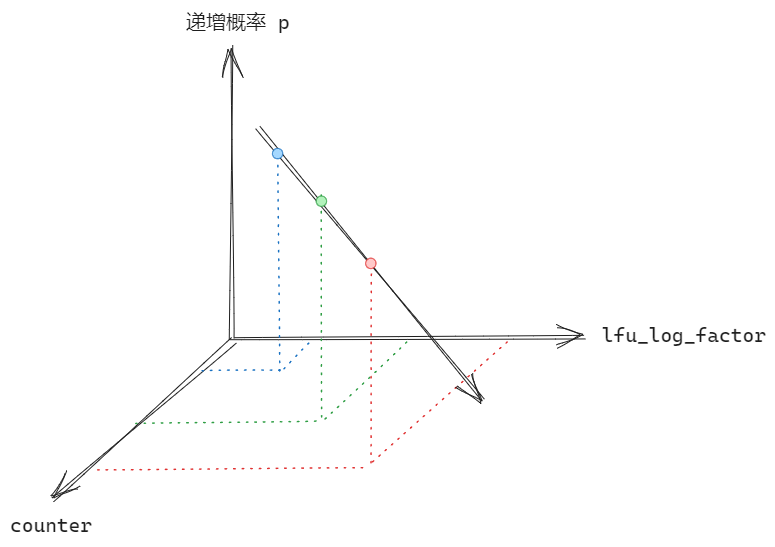
当然,实际上也要考虑到访问次数对其的影响,Redis 官方给出了相关数据:
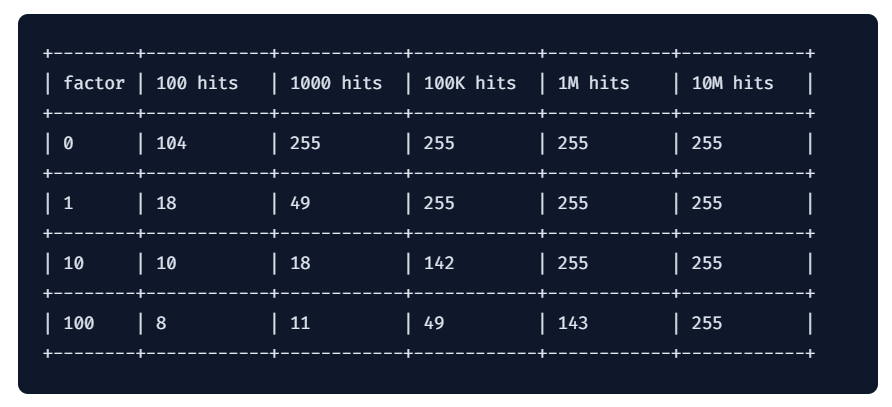
具体可直接参见:vivo LRU与LFU算法实现 sourl.cn/4yZ6e2
3.4 计数器的初始值
为了防止新的 Key 由于 counter 为 0 导致直接被淘汰,Redis 会默认将 counter设置为 5。
3.5 抽样大小的选择
值得注意的是,当数据量比较大的时候,如果抽样大小设置的过小,因为一次抽样的样本数量有限,冷热数据因为时间衰减导致的权重差异将会变得不明显,此时 LFU 算法的优势就难以体现,即使的相对较热的数据也有可能被频繁“误伤”。
所以,如果你选择了 LFU 算法作为淘汰策略,并且同时又具备比较大的数据量,那么不妨将抽样大小也设置的大一些。
完结,撒花 🎉
第19小节:开发用户优惠券分发功能(一)
业务背景
因为其实你是有一些信息的缺失的,那在我就是以我个人的经验来看,我们在学一部分内容的时候,首先大家可以把这一个事情然后总结成一些流程,然后整体的总结,而不是上来深入到某些细节方面去,在这里给大家一些建议,包括我们看一些源码,包括学习一些新的技术也都是这个样子。
开篇一张图,帮助大家梳理 v1 分发流程关键节点。
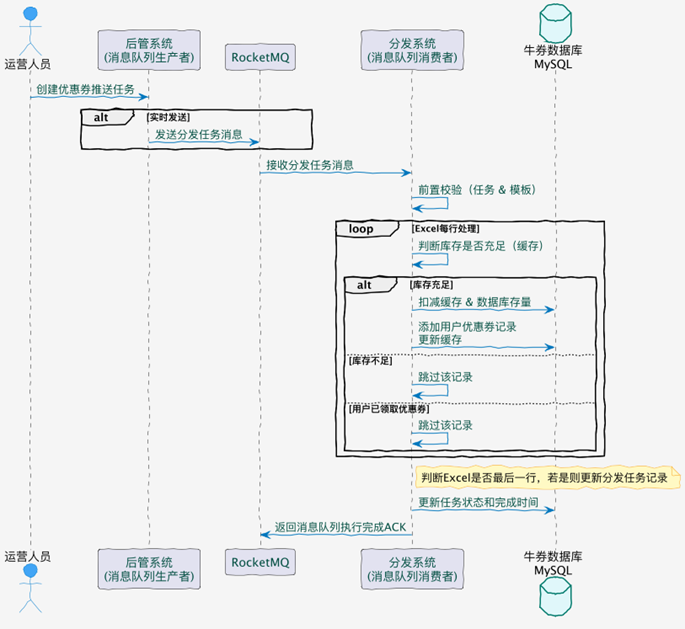
首先通过一个时序图的方式,帮大家梳理一下我们分发的一些关键节点。
然后发送了之后,它会把这个消息也推送给消息队列。然后消息队列的消费者是在分发系统里面,监听到这个消息之后,首先我们会对它进行一些前置校验。像这一步的话,是在每个系统里面都必不可少的。比如说,如果我们是定时的发送,它有可能用户运营人员觉得“我不需要了”,就把推送任务取消了。如果你没有判断任务的一些状态就去执行,其实系统就有问题。包括:这个模板是不是已经到期了?再或者说,这个模板的优惠券数量还有没有?等等,这些我们都要强制去进行一些判断。
再然后的话,我们本质上是通过优惠券分发,是通过 Excel 去进行处理的。我们去读取 Excel 的时候,它的每一行我们都要做一些处理。我们首先要判断数据库里面是否有我们对应的库存,包括缓存。然后,如果库存充足的情况下,我们会去在缓存和数据库里面进行相应的扣减,并且将用户的领券记录添加到我们的缓存当中。因为后续用户去使用时,我们肯定不能让用户直接去查数据库,对数据库的压力会有一点大。所以首先是加到缓存里面。
如果说当库存不足,或者说用户已经领取完优惠券的情况下,那么我们本条记录跳过即可。
最后,如果我们判断 Excel 已经到了最后一行了,那就证明我们的任务已经结束了。我们就要对分发的任务记录去修改它的一个任务状态,比如说从“执行中”变成“结束”,以及我们什么时候结束的,把它的完成时间也更新一下。
最后,我们把对应的消息队列的一个 ACK 响应返回给消息队列,我们整个流程就结束了。其实这样看起来是比较简单的——当然也是因为我们 V1 节点它的流程会偏简单一点,所以说这么看还好。
本篇文章更多聚焦在分发消息队列消费者,在执行消息消费时,应该首先读取 Excel 数据,然后按照用户分发流程进行操作。
具体的分发逻辑如下:
- 1.检查优惠券模板的状态是否正常;
- 2.验证优惠券模板的库存余量是否充足;
- 3.确认用户是否已领取相同的优惠券,若已领取则不再分发;
- 4.记录用户的领券信息。
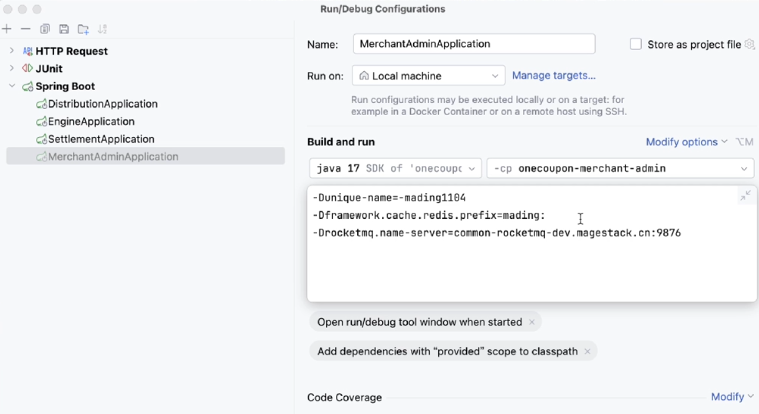
注意,如果前面商家后管服务添加了 vm 参数,分发服务记得也加上,要不然消费不到对应消息队列消息。后管的话,你看在这里面是有一些 VM 参数的。当然我自己在联调的时候,我其实是有一些改动的,大家按照之前我们在文档里面写的就可以了。然后我们这次起来了,分发服务其实也要把对应的一些东西给它加上
Git 分支
20240829_dev_coupon-distribute-v1_easyexcel-cache_ding.ma
数据库表设计
1. 用户优惠券表设计
用户优惠券表设计如下:
CREATE TABLE `t_user_coupon` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'ID',
`user_id` bigint(20) DEFAULT NULL COMMENT '用户ID',
`coupon_template_id` bigint(20) DEFAULT NULL COMMENT '优惠券模板ID',
`receive_time` datetime DEFAULT NULL COMMENT '领取时间',
`receive_count` int(3) DEFAULT NULL COMMENT '领取次数',
`valid_start_time` datetime DEFAULT NULL COMMENT '有效期开始时间',
`valid_end_time` datetime DEFAULT NULL COMMENT '有效期结束时间',
`use_time` datetime DEFAULT NULL COMMENT '使用时间',
`source` tinyint(1) DEFAULT NULL COMMENT '券来源 0:领券中心 1:平台发放 2:店铺领取',
`status` tinyint(1) DEFAULT NULL COMMENT '状态 0:未使用 1:锁定 2:已使用 3:已过期 4:已撤回',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '修改时间',
`del_flag` tinyint(1) DEFAULT NULL COMMENT '删除标识 0:未删除 1:已删除',
PRIMARY KEY (`id`),
UNIQUE KEY `idx_user_id_coupon_template_receive_count` (`user_id`,`coupon_template_id`,`receive_count`) USING BTREE,
KEY `idx_user_id` (`user_id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1815640588360376337 DEFAULT CHARSET=utf8mb4 COMMENT='用户优惠券表';其中有一个字段用于记录用户领取优惠券的次数,以标识这是用户第几次领取。通过设置唯一索引来限制用户的领取次数。因为用户他领取的优惠券,最终是要在数据库表里面进行一个保存的。比如说这里面会记录它的领取时间,以及它的领取次数——因为大家之前在学优惠券模板的时候,其实它里面是有限制用户能够领取多少次的,这个限制就通过我们这里去进行的一个校验。然后还有有效期的开始和结束时间,以及它如果使用的话一个使用时间,还有它的一个来源以及它的一个状态。这个的话会在我们后面章节会用到,默认的话领取完之后是一个“未使用”的状态。然后我们这里面其实还有一些唯一索引,也就是刚才我们讲的领取次数,在数据库做一层兜底。
用户优惠券领取——大家都用过一些像美团、饿了么、京东这些平台——它其实用户的领券量,它的数据量是很大的。所以说我们要对库进行分库分表的一个处理。
然后一般来讲,像这个量级或者说它的这种数据复杂度,说句实在话,只要你没有进行复杂的那些分组排序等逻辑,哪怕数据库表里面它是一个亿级,比如说 1 亿,对吧?其实没有“一般来说”,我们会取一个试用值,这个是没有绝对的好吧?
我上面说的是取决于不同系统的一个量级。这个不是我们在这里去预估的,而是说在系统的运行过程当中你要去评估,然后才能去进行分表,对不对?面试官我们在和他聊的时候,我们就可以说:“在未来多少年,我们的数据量大概推估有多少,然后根据我们表的一个复杂度,我们最终确定为多少张表。”这里我直接设置了 32 张表。
然后刚才我们讲到我们需要分库分表。数据量大,直接分表就行了。但是我们这里为什么要考虑分库?分库是因为对数据库用户领取的话,它的对数据库的操作还是蛮频繁的。分表是主要解决数据量大、查询慢的问题;分库的话,就是解决并发大、然后单库扛不住的问题;因为我们的分配策略和优惠券模板基本上是相同的,所以说我们这里面直接去加就好了。然后这是我们的用户优惠券表,然后可以看到都是采用哈希的方式,大家应该比较熟悉了。然后的话,就是我们去对应的数据库,创建我们对应的数据库表
2. 用户优惠券分库分表设计
由于用户优惠券记录的数据量非常大,需要对该表进行分库分表处理。不同于优惠券模板数据可以推衍估算,我们将直接分为 32 张表,以确保单表数据量保持在亿级以下,从而避免性能压力。
考虑到大量用户频繁领取优惠券导致写入操作较为频繁,因此也需要进行分库。分片策略与优惠券模板相同,采用 Hash 方式进行分库分表。
然后大家这里面有两点注意事项:
首先第一点的话,就是这个结束时间。因为我们现在是 25 年的 6 月份,所以说如果是 25 年默认时间好像是 25 年 9 月份——这个是我当时随便写的,26 年之前都可以。大家在学的时候,如果发现当前的时间已经大于这个时间,请大家改一下,要不然的话你创建完模板的时候它就会被过期。因为我们优惠券模板过期了之后是自动去给它销毁的,好吧?
然后第二个的话,就是它的库存量。因为我们接下来我们去执行,我们应该是 5000 条记录,这里我设置 5001 的一个库存,方便大家去看一下。好吧,这里的话我们直接执行。
执行完了之后,我们去看一下我们的数据库表。如果按照我们的分片规则,我们的优惠券模板应该在我们的一库和第十五张表里面。我们把 ID 给复制出来,大家可以看到我们的库存是 5001。然后我们相同的其实是相同的是模板。
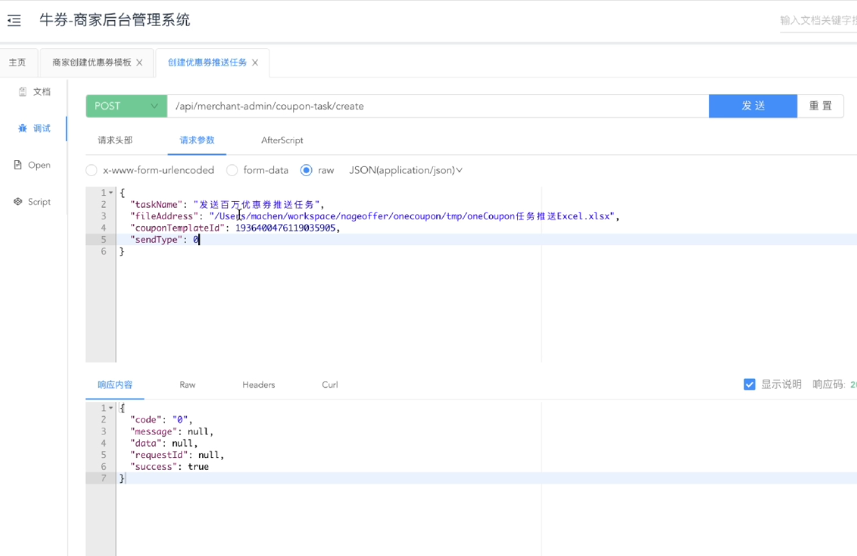
这个是我们对应的优惠券推送——创建分发任务这一块。把优惠券 ID 改一下。
然后这里面刚才我们有说,它是有两种发送方式:第一种的话就是立即发送,对吧?第二种的话是定时发送。如果是定时发送的话,这里 type 是 1,然后下面还有一个 systemTime。这里我们就不演示定时了,这个功能肯定是好的,然后我们这里面直接实时推送就好。
然后我们这里面……我看看有没有打debug?稍等。在第一步的话,它应该是在 service 里面有的。然后第二步的话应该是在我们的controller 里面。OK,没问题,然后我们点一下发送。
然后在这里面,因为判断我们的类型的话它是 0,所以说是立即发送。我们通过消息队列的方式,然后发送给我们对应的分发服务。然后这里面就到这里了。

# 数据源集合
dataSources:
# 自定义数据源名称,可以是 ds_0 也可以叫 datasource_0 都可以
ds_0:
dataSourceClassName: com.zaxxer.hikari.HikariDataSource
driverClassName: com.mysql.cj.jdbc.Driver
jdbcUrl: jdbc:mysql://127.0.0.1:3306/one_coupon_rebuild_0?useUnicode=true&characterEncoding=UTF-8&rewriteBatchedStatements=true&allowMultiQueries=true&serverTimezone=Asia/Shanghai
username: root
password: root
ds_1:
dataSourceClassName: com.zaxxer.hikari.HikariDataSource
driverClassName: com.mysql.cj.jdbc.Driver
jdbcUrl: jdbc:mysql://127.0.0.1:3306/one_coupon_rebuild_1?useUnicode=true&characterEncoding=UTF-8&rewriteBatchedStatements=true&allowMultiQueries=true&serverTimezone=Asia/Shanghai
username: root
password: root
rules:
- !SHARDING
tables: # 需要分片的数据库表集合
t_coupon_template: # 优惠券模板表
# 真实存在数据库中的物理表
actualDataNodes: ds_${0..1}.t_coupon_template_${0..15}
databaseStrategy: # 分库策略
standard: # 单分片键分库
shardingColumn: shop_number # 分片键
shardingAlgorithmName: coupon_template_database_mod # 库分片算法名称,对应 rules[0].shardingAlgorithms
tableStrategy: # 分表策略
standard: # 单分片键分表
shardingColumn: shop_number # 分片键
shardingAlgorithmName: coupon_template_table_mod # 表分片算法名称,对应 rules[0].shardingAlgorithms
t_user_coupon:
actualDataNodes: ds_${0..1}.t_user_coupon_${0..31}
databaseStrategy:
standard:
shardingColumn: user_id
shardingAlgorithmName: user_coupon_database_mod
tableStrategy:
standard:
shardingColumn: user_id
shardingAlgorithmName: user_coupon_table_mod
shardingAlgorithms: # 分片算法定义集合
coupon_template_database_mod: # 优惠券分库算法定义
type: CLASS_BASED # 根据自定义库分片算法类进行分片
props: # 分片相关属性
# 自定义库分片算法Class
algorithmClassName: com.nageoffer.onecoupon.distribution.dao.sharding.DBHashModShardingAlgorithm
sharding-count: 16 # 分片总数量
strategy: standard # 分片类型,单字段分片
coupon_template_table_mod: # 优惠券分表算法定义
type: CLASS_BASED # 根据自定义库分片算法类进行分片
props: # 分片相关属性
# 自定义表分片算法Class
algorithmClassName: com.nageoffer.onecoupon.distribution.dao.sharding.TableHashModShardingAlgorithm
strategy: standard # 分片类型,单字段分片
user_coupon_database_mod:
type: CLASS_BASED
props:
algorithmClassName: com.nageoffer.onecoupon.distribution.dao.sharding.DBHashModShardingAlgorithm
sharding-count: 32
strategy: standard
user_coupon_table_mod:
type: CLASS_BASED
props:
algorithmClassName: com.nageoffer.onecoupon.distribution.dao.sharding.TableHashModShardingAlgorithm
strategy: standard
props:
# 配置 ShardingSphere 默认打印 SQL 执行语句
sql-show: true3. 创建用户优惠券表 SQL
进入 one_coupon_rebuild_0 数据库,执行下述 SQL。
CREATE TABLE `t_user_coupon_0` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'ID',
`user_id` bigint(20) DEFAULT NULL COMMENT '用户ID',
`coupon_template_id` bigint(20) DEFAULT NULL COMMENT '优惠券模板ID',
`receive_time` datetime DEFAULT NULL COMMENT '领取时间',
`receive_count` int(3) DEFAULT NULL COMMENT '领取次数',
`valid_start_time` datetime DEFAULT NULL COMMENT '有效期开始时间',
`valid_end_time` datetime DEFAULT NULL COMMENT '有效期结束时间',
`use_time` datetime DEFAULT NULL COMMENT '使用时间',
`source` tinyint(1) DEFAULT NULL COMMENT '券来源 0:领券中心 1:平台发放 2:店铺领取',
`status` tinyint(1) DEFAULT NULL COMMENT '状态 0:未使用 1:锁定 2:已使用 3:已过期 4:已撤回',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '修改时间',
`del_flag` tinyint(1) DEFAULT NULL COMMENT '删除标识 0:未删除 1:已删除',
PRIMARY KEY (`id`),
UNIQUE KEY `idx_user_id_coupon_template_receive_count` (`user_id`,`coupon_template_id`,`receive_count`) USING BTREE,
KEY `idx_user_id` (`user_id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1815640588360376337 DEFAULT CHARSET=utf8mb4 COMMENT='用户优惠券表';
CREATE TABLE `t_user_coupon_1` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'ID',
`user_id` bigint(20) DEFAULT NULL COMMENT '用户ID',
`coupon_template_id` bigint(20) DEFAULT NULL COMMENT '优惠券模板ID',
`receive_time` datetime DEFAULT NULL COMMENT '领取时间',
`receive_count` int(3) DEFAULT NULL COMMENT '领取次数',
`valid_start_time` datetime DEFAULT NULL COMMENT '有效期开始时间',
`valid_end_time` datetime DEFAULT NULL COMMENT '有效期结束时间',
`use_time` datetime DEFAULT NULL COMMENT '使用时间',
`source` tinyint(1) DEFAULT NULL COMMENT '券来源 0:领券中心 1:平台发放 2:店铺领取',
`status` tinyint(1) DEFAULT NULL COMMENT '状态 0:未使用 1:锁定 2:已使用 3:已过期 4:已撤回',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '修改时间',
`del_flag` tinyint(1) DEFAULT NULL COMMENT '删除标识 0:未删除 1:已删除',
PRIMARY KEY (`id`),
UNIQUE KEY `idx_user_id_coupon_template_receive_count` (`user_id`,`coupon_template_id`,`receive_count`) USING BTREE,
KEY `idx_user_id` (`user_id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1815640588360376337 DEFAULT CHARSET=utf8mb4 COMMENT='用户优惠券表';
CREATE TABLE `t_user_coupon_2` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'ID',
`user_id` bigint(20) DEFAULT NULL COMMENT '用户ID',
`coupon_template_id` bigint(20) DEFAULT NULL COMMENT '优惠券模板ID',
`receive_time` datetime DEFAULT NULL COMMENT '领取时间',
`receive_count` int(3) DEFAULT NULL COMMENT '领取次数',
`valid_start_time` datetime DEFAULT NULL COMMENT '有效期开始时间',
`valid_end_time` datetime DEFAULT NULL COMMENT '有效期结束时间',
`use_time` datetime DEFAULT NULL COMMENT '使用时间',
`source` tinyint(1) DEFAULT NULL COMMENT '券来源 0:领券中心 1:平台发放 2:店铺领取',
`status` tinyint(1) DEFAULT NULL COMMENT '状态 0:未使用 1:锁定 2:已使用 3:已过期 4:已撤回',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '修改时间',
`del_flag` tinyint(1) DEFAULT NULL COMMENT '删除标识 0:未删除 1:已删除',
PRIMARY KEY (`id`),
UNIQUE KEY `idx_user_id_coupon_template_receive_count` (`user_id`,`coupon_template_id`,`receive_count`) USING BTREE,
KEY `idx_user_id` (`user_id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1815640588360376337 DEFAULT CHARSET=utf8mb4 COMMENT='用户优惠券表';
CREATE TABLE `t_user_coupon_3` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'ID',
`user_id` bigint(20) DEFAULT NULL COMMENT '用户ID',
`coupon_template_id` bigint(20) DEFAULT NULL COMMENT '优惠券模板ID',
`receive_time` datetime DEFAULT NULL COMMENT '领取时间',
`receive_count` int(3) DEFAULT NULL COMMENT '领取次数',
`valid_start_time` datetime DEFAULT NULL COMMENT '有效期开始时间',
`valid_end_time` datetime DEFAULT NULL COMMENT '有效期结束时间',
`use_time` datetime DEFAULT NULL COMMENT '使用时间',
`source` tinyint(1) DEFAULT NULL COMMENT '券来源 0:领券中心 1:平台发放 2:店铺领取',
`status` tinyint(1) DEFAULT NULL COMMENT '状态 0:未使用 1:锁定 2:已使用 3:已过期 4:已撤回',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '修改时间',
`del_flag` tinyint(1) DEFAULT NULL COMMENT '删除标识 0:未删除 1:已删除',
PRIMARY KEY (`id`),
UNIQUE KEY `idx_user_id_coupon_template_receive_count` (`user_id`,`coupon_template_id`,`receive_count`) USING BTREE,
KEY `idx_user_id` (`user_id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1815640588360376337 DEFAULT CHARSET=utf8mb4 COMMENT='用户优惠券表';
CREATE TABLE `t_user_coupon_4` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'ID',
`user_id` bigint(20) DEFAULT NULL COMMENT '用户ID',
`coupon_template_id` bigint(20) DEFAULT NULL COMMENT '优惠券模板ID',
`receive_time` datetime DEFAULT NULL COMMENT '领取时间',
`receive_count` int(3) DEFAULT NULL COMMENT '领取次数',
`valid_start_time` datetime DEFAULT NULL COMMENT '有效期开始时间',
`valid_end_time` datetime DEFAULT NULL COMMENT '有效期结束时间',
`use_time` datetime DEFAULT NULL COMMENT '使用时间',
`source` tinyint(1) DEFAULT NULL COMMENT '券来源 0:领券中心 1:平台发放 2:店铺领取',
`status` tinyint(1) DEFAULT NULL COMMENT '状态 0:未使用 1:锁定 2:已使用 3:已过期 4:已撤回',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '修改时间',
`del_flag` tinyint(1) DEFAULT NULL COMMENT '删除标识 0:未删除 1:已删除',
PRIMARY KEY (`id`),
UNIQUE KEY `idx_user_id_coupon_template_receive_count` (`user_id`,`coupon_template_id`,`receive_count`) USING BTREE,
KEY `idx_user_id` (`user_id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1815640588360376337 DEFAULT CHARSET=utf8mb4 COMMENT='用户优惠券表';
CREATE TABLE `t_user_coupon_5` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'ID',
`user_id` bigint(20) DEFAULT NULL COMMENT '用户ID',
`coupon_template_id` bigint(20) DEFAULT NULL COMMENT '优惠券模板ID',
`receive_time` datetime DEFAULT NULL COMMENT '领取时间',
`receive_count` int(3) DEFAULT NULL COMMENT '领取次数',
`valid_start_time` datetime DEFAULT NULL COMMENT '有效期开始时间',
`valid_end_time` datetime DEFAULT NULL COMMENT '有效期结束时间',
`use_time` datetime DEFAULT NULL COMMENT '使用时间',
`source` tinyint(1) DEFAULT NULL COMMENT '券来源 0:领券中心 1:平台发放 2:店铺领取',
`status` tinyint(1) DEFAULT NULL COMMENT '状态 0:未使用 1:锁定 2:已使用 3:已过期 4:已撤回',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '修改时间',
`del_flag` tinyint(1) DEFAULT NULL COMMENT '删除标识 0:未删除 1:已删除',
PRIMARY KEY (`id`),
UNIQUE KEY `idx_user_id_coupon_template_receive_count` (`user_id`,`coupon_template_id`,`receive_count`) USING BTREE,
KEY `idx_user_id` (`user_id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1815640588360376337 DEFAULT CHARSET=utf8mb4 COMMENT='用户优惠券表';
CREATE TABLE `t_user_coupon_6` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'ID',
`user_id` bigint(20) DEFAULT NULL COMMENT '用户ID',
`coupon_template_id` bigint(20) DEFAULT NULL COMMENT '优惠券模板ID',
`receive_time` datetime DEFAULT NULL COMMENT '领取时间',
`receive_count` int(3) DEFAULT NULL COMMENT '领取次数',
`valid_start_time` datetime DEFAULT NULL COMMENT '有效期开始时间',
`valid_end_time` datetime DEFAULT NULL COMMENT '有效期结束时间',
`use_time` datetime DEFAULT NULL COMMENT '使用时间',
`source` tinyint(1) DEFAULT NULL COMMENT '券来源 0:领券中心 1:平台发放 2:店铺领取',
`status` tinyint(1) DEFAULT NULL COMMENT '状态 0:未使用 1:锁定 2:已使用 3:已过期 4:已撤回',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '修改时间',
`del_flag` tinyint(1) DEFAULT NULL COMMENT '删除标识 0:未删除 1:已删除',
PRIMARY KEY (`id`),
UNIQUE KEY `idx_user_id_coupon_template_receive_count` (`user_id`,`coupon_template_id`,`receive_count`) USING BTREE,
KEY `idx_user_id` (`user_id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1815640588360376337 DEFAULT CHARSET=utf8mb4 COMMENT='用户优惠券表';
CREATE TABLE `t_user_coupon_7` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'ID',
`user_id` bigint(20) DEFAULT NULL COMMENT '用户ID',
`coupon_template_id` bigint(20) DEFAULT NULL COMMENT '优惠券模板ID',
`receive_time` datetime DEFAULT NULL COMMENT '领取时间',
`receive_count` int(3) DEFAULT NULL COMMENT '领取次数',
`valid_start_time` datetime DEFAULT NULL COMMENT '有效期开始时间',
`valid_end_time` datetime DEFAULT NULL COMMENT '有效期结束时间',
`use_time` datetime DEFAULT NULL COMMENT '使用时间',
`source` tinyint(1) DEFAULT NULL COMMENT '券来源 0:领券中心 1:平台发放 2:店铺领取',
`status` tinyint(1) DEFAULT NULL COMMENT '状态 0:未使用 1:锁定 2:已使用 3:已过期 4:已撤回',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '修改时间',
`del_flag` tinyint(1) DEFAULT NULL COMMENT '删除标识 0:未删除 1:已删除',
PRIMARY KEY (`id`),
UNIQUE KEY `idx_user_id_coupon_template_receive_count` (`user_id`,`coupon_template_id`,`receive_count`) USING BTREE,
KEY `idx_user_id` (`user_id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1815640588360376337 DEFAULT CHARSET=utf8mb4 COMMENT='用户优惠券表';
CREATE TABLE `t_user_coupon_8` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'ID',
`user_id` bigint(20) DEFAULT NULL COMMENT '用户ID',
`coupon_template_id` bigint(20) DEFAULT NULL COMMENT '优惠券模板ID',
`receive_time` datetime DEFAULT NULL COMMENT '领取时间',
`receive_count` int(3) DEFAULT NULL COMMENT '领取次数',
`valid_start_time` datetime DEFAULT NULL COMMENT '有效期开始时间',
`valid_end_time` datetime DEFAULT NULL COMMENT '有效期结束时间',
`use_time` datetime DEFAULT NULL COMMENT '使用时间',
`source` tinyint(1) DEFAULT NULL COMMENT '券来源 0:领券中心 1:平台发放 2:店铺领取',
`status` tinyint(1) DEFAULT NULL COMMENT '状态 0:未使用 1:锁定 2:已使用 3:已过期 4:已撤回',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '修改时间',
`del_flag` tinyint(1) DEFAULT NULL COMMENT '删除标识 0:未删除 1:已删除',
PRIMARY KEY (`id`),
UNIQUE KEY `idx_user_id_coupon_template_receive_count` (`user_id`,`coupon_template_id`,`receive_count`) USING BTREE,
KEY `idx_user_id` (`user_id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1815640588360376337 DEFAULT CHARSET=utf8mb4 COMMENT='用户优惠券表';
CREATE TABLE `t_user_coupon_9` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'ID',
`user_id` bigint(20) DEFAULT NULL COMMENT '用户ID',
`coupon_template_id` bigint(20) DEFAULT NULL COMMENT '优惠券模板ID',
`receive_time` datetime DEFAULT NULL COMMENT '领取时间',
`receive_count` int(3) DEFAULT NULL COMMENT '领取次数',
`valid_start_time` datetime DEFAULT NULL COMMENT '有效期开始时间',
`valid_end_time` datetime DEFAULT NULL COMMENT '有效期结束时间',
`use_time` datetime DEFAULT NULL COMMENT '使用时间',
`source` tinyint(1) DEFAULT NULL COMMENT '券来源 0:领券中心 1:平台发放 2:店铺领取',
`status` tinyint(1) DEFAULT NULL COMMENT '状态 0:未使用 1:锁定 2:已使用 3:已过期 4:已撤回',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '修改时间',
`del_flag` tinyint(1) DEFAULT NULL COMMENT '删除标识 0:未删除 1:已删除',
PRIMARY KEY (`id`),
UNIQUE KEY `idx_user_id_coupon_template_receive_count` (`user_id`,`coupon_template_id`,`receive_count`) USING BTREE,
KEY `idx_user_id` (`user_id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1815640588360376337 DEFAULT CHARSET=utf8mb4 COMMENT='用户优惠券表';
CREATE TABLE `t_user_coupon_10` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'ID',
`user_id` bigint(20) DEFAULT NULL COMMENT '用户ID',
`coupon_template_id` bigint(20) DEFAULT NULL COMMENT '优惠券模板ID',
`receive_time` datetime DEFAULT NULL COMMENT '领取时间',
`receive_count` int(3) DEFAULT NULL COMMENT '领取次数',
`valid_start_time` datetime DEFAULT NULL COMMENT '有效期开始时间',
`valid_end_time` datetime DEFAULT NULL COMMENT '有效期结束时间',
`use_time` datetime DEFAULT NULL COMMENT '使用时间',
`source` tinyint(1) DEFAULT NULL COMMENT '券来源 0:领券中心 1:平台发放 2:店铺领取',
`status` tinyint(1) DEFAULT NULL COMMENT '状态 0:未使用 1:锁定 2:已使用 3:已过期 4:已撤回',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '修改时间',
`del_flag` tinyint(1) DEFAULT NULL COMMENT '删除标识 0:未删除 1:已删除',
PRIMARY KEY (`id`),
UNIQUE KEY `idx_user_id_coupon_template_receive_count` (`user_id`,`coupon_template_id`,`receive_count`) USING BTREE,
KEY `idx_user_id` (`user_id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1815640588360376337 DEFAULT CHARSET=utf8mb4 COMMENT='用户优惠券表';
CREATE TABLE `t_user_coupon_11` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'ID',
`user_id` bigint(20) DEFAULT NULL COMMENT '用户ID',
`coupon_template_id` bigint(20) DEFAULT NULL COMMENT '优惠券模板ID',
`receive_time` datetime DEFAULT NULL COMMENT '领取时间',
`receive_count` int(3) DEFAULT NULL COMMENT '领取次数',
`valid_start_time` datetime DEFAULT NULL COMMENT '有效期开始时间',
`valid_end_time` datetime DEFAULT NULL COMMENT '有效期结束时间',
`use_time` datetime DEFAULT NULL COMMENT '使用时间',
`source` tinyint(1) DEFAULT NULL COMMENT '券来源 0:领券中心 1:平台发放 2:店铺领取',
`status` tinyint(1) DEFAULT NULL COMMENT '状态 0:未使用 1:锁定 2:已使用 3:已过期 4:已撤回',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '修改时间',
`del_flag` tinyint(1) DEFAULT NULL COMMENT '删除标识 0:未删除 1:已删除',
PRIMARY KEY (`id`),
UNIQUE KEY `idx_user_id_coupon_template_receive_count` (`user_id`,`coupon_template_id`,`receive_count`) USING BTREE,
KEY `idx_user_id` (`user_id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1815640588360376337 DEFAULT CHARSET=utf8mb4 COMMENT='用户优惠券表';
CREATE TABLE `t_user_coupon_12` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'ID',
`user_id` bigint(20) DEFAULT NULL COMMENT '用户ID',
`coupon_template_id` bigint(20) DEFAULT NULL COMMENT '优惠券模板ID',
`receive_time` datetime DEFAULT NULL COMMENT '领取时间',
`receive_count` int(3) DEFAULT NULL COMMENT '领取次数',
`valid_start_time` datetime DEFAULT NULL COMMENT '有效期开始时间',
`valid_end_time` datetime DEFAULT NULL COMMENT '有效期结束时间',
`use_time` datetime DEFAULT NULL COMMENT '使用时间',
`source` tinyint(1) DEFAULT NULL COMMENT '券来源 0:领券中心 1:平台发放 2:店铺领取',
`status` tinyint(1) DEFAULT NULL COMMENT '状态 0:未使用 1:锁定 2:已使用 3:已过期 4:已撤回',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '修改时间',
`del_flag` tinyint(1) DEFAULT NULL COMMENT '删除标识 0:未删除 1:已删除',
PRIMARY KEY (`id`),
UNIQUE KEY `idx_user_id_coupon_template_receive_count` (`user_id`,`coupon_template_id`,`receive_count`) USING BTREE,
KEY `idx_user_id` (`user_id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1815640588360376337 DEFAULT CHARSET=utf8mb4 COMMENT='用户优惠券表';
CREATE TABLE `t_user_coupon_13` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'ID',
`user_id` bigint(20) DEFAULT NULL COMMENT '用户ID',
`coupon_template_id` bigint(20) DEFAULT NULL COMMENT '优惠券模板ID',
`receive_time` datetime DEFAULT NULL COMMENT '领取时间',
`receive_count` int(3) DEFAULT NULL COMMENT '领取次数',
`valid_start_time` datetime DEFAULT NULL COMMENT '有效期开始时间',
`valid_end_time` datetime DEFAULT NULL COMMENT '有效期结束时间',
`use_time` datetime DEFAULT NULL COMMENT '使用时间',
`source` tinyint(1) DEFAULT NULL COMMENT '券来源 0:领券中心 1:平台发放 2:店铺领取',
`status` tinyint(1) DEFAULT NULL COMMENT '状态 0:未使用 1:锁定 2:已使用 3:已过期 4:已撤回',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '修改时间',
`del_flag` tinyint(1) DEFAULT NULL COMMENT '删除标识 0:未删除 1:已删除',
PRIMARY KEY (`id`),
UNIQUE KEY `idx_user_id_coupon_template_receive_count` (`user_id`,`coupon_template_id`,`receive_count`) USING BTREE,
KEY `idx_user_id` (`user_id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1815640588360376337 DEFAULT CHARSET=utf8mb4 COMMENT='用户优惠券表';
CREATE TABLE `t_user_coupon_14` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'ID',
`user_id` bigint(20) DEFAULT NULL COMMENT '用户ID',
`coupon_template_id` bigint(20) DEFAULT NULL COMMENT '优惠券模板ID',
`receive_time` datetime DEFAULT NULL COMMENT '领取时间',
`receive_count` int(3) DEFAULT NULL COMMENT '领取次数',
`valid_start_time` datetime DEFAULT NULL COMMENT '有效期开始时间',
`valid_end_time` datetime DEFAULT NULL COMMENT '有效期结束时间',
`use_time` datetime DEFAULT NULL COMMENT '使用时间',
`source` tinyint(1) DEFAULT NULL COMMENT '券来源 0:领券中心 1:平台发放 2:店铺领取',
`status` tinyint(1) DEFAULT NULL COMMENT '状态 0:未使用 1:锁定 2:已使用 3:已过期 4:已撤回',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '修改时间',
`del_flag` tinyint(1) DEFAULT NULL COMMENT '删除标识 0:未删除 1:已删除',
PRIMARY KEY (`id`),
UNIQUE KEY `idx_user_id_coupon_template_receive_count` (`user_id`,`coupon_template_id`,`receive_count`) USING BTREE,
KEY `idx_user_id` (`user_id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1815640588360376337 DEFAULT CHARSET=utf8mb4 COMMENT='用户优惠券表';
CREATE TABLE `t_user_coupon_15` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'ID',
`user_id` bigint(20) DEFAULT NULL COMMENT '用户ID',
`coupon_template_id` bigint(20) DEFAULT NULL COMMENT '优惠券模板ID',
`receive_time` datetime DEFAULT NULL COMMENT '领取时间',
`receive_count` int(3) DEFAULT NULL COMMENT '领取次数',
`valid_start_time` datetime DEFAULT NULL COMMENT '有效期开始时间',
`valid_end_time` datetime DEFAULT NULL COMMENT '有效期结束时间',
`use_time` datetime DEFAULT NULL COMMENT '使用时间',
`source` tinyint(1) DEFAULT NULL COMMENT '券来源 0:领券中心 1:平台发放 2:店铺领取',
`status` tinyint(1) DEFAULT NULL COMMENT '状态 0:未使用 1:锁定 2:已使用 3:已过期 4:已撤回',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '修改时间',
`del_flag` tinyint(1) DEFAULT NULL COMMENT '删除标识 0:未删除 1:已删除',
PRIMARY KEY (`id`),
UNIQUE KEY `idx_user_id_coupon_template_receive_count` (`user_id`,`coupon_template_id`,`receive_count`) USING BTREE,
KEY `idx_user_id` (`user_id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1815640588360376337 DEFAULT CHARSET=utf8mb4 COMMENT='用户优惠券表';进入 one_coupon_rebuild_1 数据库,执行下述 SQL。
CREATE TABLE `t_user_coupon_16` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'ID',
`user_id` bigint(20) DEFAULT NULL COMMENT '用户ID',
`coupon_template_id` bigint(20) DEFAULT NULL COMMENT '优惠券模板ID',
`receive_time` datetime DEFAULT NULL COMMENT '领取时间',
`receive_count` int(3) DEFAULT NULL COMMENT '领取次数',
`valid_start_time` datetime DEFAULT NULL COMMENT '有效期开始时间',
`valid_end_time` datetime DEFAULT NULL COMMENT '有效期结束时间',
`use_time` datetime DEFAULT NULL COMMENT '使用时间',
`source` tinyint(1) DEFAULT NULL COMMENT '券来源 0:领券中心 1:平台发放 2:店铺领取',
`status` tinyint(1) DEFAULT NULL COMMENT '状态 0:未使用 1:锁定 2:已使用 3:已过期 4:已撤回',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '修改时间',
`del_flag` tinyint(1) DEFAULT NULL COMMENT '删除标识 0:未删除 1:已删除',
PRIMARY KEY (`id`),
UNIQUE KEY `idx_user_id_coupon_template_receive_count` (`user_id`,`coupon_template_id`,`receive_count`) USING BTREE,
KEY `idx_user_id` (`user_id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1815640588360376337 DEFAULT CHARSET=utf8mb4 COMMENT='用户优惠券表';
CREATE TABLE `t_user_coupon_17` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'ID',
`user_id` bigint(20) DEFAULT NULL COMMENT '用户ID',
`coupon_template_id` bigint(20) DEFAULT NULL COMMENT '优惠券模板ID',
`receive_time` datetime DEFAULT NULL COMMENT '领取时间',
`receive_count` int(3) DEFAULT NULL COMMENT '领取次数',
`valid_start_time` datetime DEFAULT NULL COMMENT '有效期开始时间',
`valid_end_time` datetime DEFAULT NULL COMMENT '有效期结束时间',
`use_time` datetime DEFAULT NULL COMMENT '使用时间',
`source` tinyint(1) DEFAULT NULL COMMENT '券来源 0:领券中心 1:平台发放 2:店铺领取',
`status` tinyint(1) DEFAULT NULL COMMENT '状态 0:未使用 1:锁定 2:已使用 3:已过期 4:已撤回',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '修改时间',
`del_flag` tinyint(1) DEFAULT NULL COMMENT '删除标识 0:未删除 1:已删除',
PRIMARY KEY (`id`),
UNIQUE KEY `idx_user_id_coupon_template_receive_count` (`user_id`,`coupon_template_id`,`receive_count`) USING BTREE,
KEY `idx_user_id` (`user_id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1815640588360376337 DEFAULT CHARSET=utf8mb4 COMMENT='用户优惠券表';
CREATE TABLE `t_user_coupon_18` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'ID',
`user_id` bigint(20) DEFAULT NULL COMMENT '用户ID',
`coupon_template_id` bigint(20) DEFAULT NULL COMMENT '优惠券模板ID',
`receive_time` datetime DEFAULT NULL COMMENT '领取时间',
`receive_count` int(3) DEFAULT NULL COMMENT '领取次数',
`valid_start_time` datetime DEFAULT NULL COMMENT '有效期开始时间',
`valid_end_time` datetime DEFAULT NULL COMMENT '有效期结束时间',
`use_time` datetime DEFAULT NULL COMMENT '使用时间',
`source` tinyint(1) DEFAULT NULL COMMENT '券来源 0:领券中心 1:平台发放 2:店铺领取',
`status` tinyint(1) DEFAULT NULL COMMENT '状态 0:未使用 1:锁定 2:已使用 3:已过期 4:已撤回',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '修改时间',
`del_flag` tinyint(1) DEFAULT NULL COMMENT '删除标识 0:未删除 1:已删除',
PRIMARY KEY (`id`),
UNIQUE KEY `idx_user_id_coupon_template_receive_count` (`user_id`,`coupon_template_id`,`receive_count`) USING BTREE,
KEY `idx_user_id` (`user_id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1815640588360376337 DEFAULT CHARSET=utf8mb4 COMMENT='用户优惠券表';
CREATE TABLE `t_user_coupon_19` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'ID',
`user_id` bigint(20) DEFAULT NULL COMMENT '用户ID',
`coupon_template_id` bigint(20) DEFAULT NULL COMMENT '优惠券模板ID',
`receive_time` datetime DEFAULT NULL COMMENT '领取时间',
`receive_count` int(3) DEFAULT NULL COMMENT '领取次数',
`valid_start_time` datetime DEFAULT NULL COMMENT '有效期开始时间',
`valid_end_time` datetime DEFAULT NULL COMMENT '有效期结束时间',
`use_time` datetime DEFAULT NULL COMMENT '使用时间',
`source` tinyint(1) DEFAULT NULL COMMENT '券来源 0:领券中心 1:平台发放 2:店铺领取',
`status` tinyint(1) DEFAULT NULL COMMENT '状态 0:未使用 1:锁定 2:已使用 3:已过期 4:已撤回',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '修改时间',
`del_flag` tinyint(1) DEFAULT NULL COMMENT '删除标识 0:未删除 1:已删除',
PRIMARY KEY (`id`),
UNIQUE KEY `idx_user_id_coupon_template_receive_count` (`user_id`,`coupon_template_id`,`receive_count`) USING BTREE,
KEY `idx_user_id` (`user_id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1815640588360376337 DEFAULT CHARSET=utf8mb4 COMMENT='用户优惠券表';
CREATE TABLE `t_user_coupon_20` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'ID',
`user_id` bigint(20) DEFAULT NULL COMMENT '用户ID',
`coupon_template_id` bigint(20) DEFAULT NULL COMMENT '优惠券模板ID',
`receive_time` datetime DEFAULT NULL COMMENT '领取时间',
`receive_count` int(3) DEFAULT NULL COMMENT '领取次数',
`valid_start_time` datetime DEFAULT NULL COMMENT '有效期开始时间',
`valid_end_time` datetime DEFAULT NULL COMMENT '有效期结束时间',
`use_time` datetime DEFAULT NULL COMMENT '使用时间',
`source` tinyint(1) DEFAULT NULL COMMENT '券来源 0:领券中心 1:平台发放 2:店铺领取',
`status` tinyint(1) DEFAULT NULL COMMENT '状态 0:未使用 1:锁定 2:已使用 3:已过期 4:已撤回',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '修改时间',
`del_flag` tinyint(1) DEFAULT NULL COMMENT '删除标识 0:未删除 1:已删除',
PRIMARY KEY (`id`),
UNIQUE KEY `idx_user_id_coupon_template_receive_count` (`user_id`,`coupon_template_id`,`receive_count`) USING BTREE,
KEY `idx_user_id` (`user_id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1815640588360376337 DEFAULT CHARSET=utf8mb4 COMMENT='用户优惠券表';
CREATE TABLE `t_user_coupon_21` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'ID',
`user_id` bigint(20) DEFAULT NULL COMMENT '用户ID',
`coupon_template_id` bigint(20) DEFAULT NULL COMMENT '优惠券模板ID',
`receive_time` datetime DEFAULT NULL COMMENT '领取时间',
`receive_count` int(3) DEFAULT NULL COMMENT '领取次数',
`valid_start_time` datetime DEFAULT NULL COMMENT '有效期开始时间',
`valid_end_time` datetime DEFAULT NULL COMMENT '有效期结束时间',
`use_time` datetime DEFAULT NULL COMMENT '使用时间',
`source` tinyint(1) DEFAULT NULL COMMENT '券来源 0:领券中心 1:平台发放 2:店铺领取',
`status` tinyint(1) DEFAULT NULL COMMENT '状态 0:未使用 1:锁定 2:已使用 3:已过期 4:已撤回',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '修改时间',
`del_flag` tinyint(1) DEFAULT NULL COMMENT '删除标识 0:未删除 1:已删除',
PRIMARY KEY (`id`),
UNIQUE KEY `idx_user_id_coupon_template_receive_count` (`user_id`,`coupon_template_id`,`receive_count`) USING BTREE,
KEY `idx_user_id` (`user_id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1815640588360376337 DEFAULT CHARSET=utf8mb4 COMMENT='用户优惠券表';
CREATE TABLE `t_user_coupon_22` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'ID',
`user_id` bigint(20) DEFAULT NULL COMMENT '用户ID',
`coupon_template_id` bigint(20) DEFAULT NULL COMMENT '优惠券模板ID',
`receive_time` datetime DEFAULT NULL COMMENT '领取时间',
`receive_count` int(3) DEFAULT NULL COMMENT '领取次数',
`valid_start_time` datetime DEFAULT NULL COMMENT '有效期开始时间',
`valid_end_time` datetime DEFAULT NULL COMMENT '有效期结束时间',
`use_time` datetime DEFAULT NULL COMMENT '使用时间',
`source` tinyint(1) DEFAULT NULL COMMENT '券来源 0:领券中心 1:平台发放 2:店铺领取',
`status` tinyint(1) DEFAULT NULL COMMENT '状态 0:未使用 1:锁定 2:已使用 3:已过期 4:已撤回',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '修改时间',
`del_flag` tinyint(1) DEFAULT NULL COMMENT '删除标识 0:未删除 1:已删除',
PRIMARY KEY (`id`),
UNIQUE KEY `idx_user_id_coupon_template_receive_count` (`user_id`,`coupon_template_id`,`receive_count`) USING BTREE,
KEY `idx_user_id` (`user_id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1815640588360376337 DEFAULT CHARSET=utf8mb4 COMMENT='用户优惠券表';
CREATE TABLE `t_user_coupon_23` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'ID',
`user_id` bigint(20) DEFAULT NULL COMMENT '用户ID',
`coupon_template_id` bigint(20) DEFAULT NULL COMMENT '优惠券模板ID',
`receive_time` datetime DEFAULT NULL COMMENT '领取时间',
`receive_count` int(3) DEFAULT NULL COMMENT '领取次数',
`valid_start_time` datetime DEFAULT NULL COMMENT '有效期开始时间',
`valid_end_time` datetime DEFAULT NULL COMMENT '有效期结束时间',
`use_time` datetime DEFAULT NULL COMMENT '使用时间',
`source` tinyint(1) DEFAULT NULL COMMENT '券来源 0:领券中心 1:平台发放 2:店铺领取',
`status` tinyint(1) DEFAULT NULL COMMENT '状态 0:未使用 1:锁定 2:已使用 3:已过期 4:已撤回',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '修改时间',
`del_flag` tinyint(1) DEFAULT NULL COMMENT '删除标识 0:未删除 1:已删除',
PRIMARY KEY (`id`),
UNIQUE KEY `idx_user_id_coupon_template_receive_count` (`user_id`,`coupon_template_id`,`receive_count`) USING BTREE,
KEY `idx_user_id` (`user_id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1815640588360376337 DEFAULT CHARSET=utf8mb4 COMMENT='用户优惠券表';
CREATE TABLE `t_user_coupon_24` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'ID',
`user_id` bigint(20) DEFAULT NULL COMMENT '用户ID',
`coupon_template_id` bigint(20) DEFAULT NULL COMMENT '优惠券模板ID',
`receive_time` datetime DEFAULT NULL COMMENT '领取时间',
`receive_count` int(3) DEFAULT NULL COMMENT '领取次数',
`valid_start_time` datetime DEFAULT NULL COMMENT '有效期开始时间',
`valid_end_time` datetime DEFAULT NULL COMMENT '有效期结束时间',
`use_time` datetime DEFAULT NULL COMMENT '使用时间',
`source` tinyint(1) DEFAULT NULL COMMENT '券来源 0:领券中心 1:平台发放 2:店铺领取',
`status` tinyint(1) DEFAULT NULL COMMENT '状态 0:未使用 1:锁定 2:已使用 3:已过期 4:已撤回',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '修改时间',
`del_flag` tinyint(1) DEFAULT NULL COMMENT '删除标识 0:未删除 1:已删除',
PRIMARY KEY (`id`),
UNIQUE KEY `idx_user_id_coupon_template_receive_count` (`user_id`,`coupon_template_id`,`receive_count`) USING BTREE,
KEY `idx_user_id` (`user_id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1815640588360376337 DEFAULT CHARSET=utf8mb4 COMMENT='用户优惠券表';
CREATE TABLE `t_user_coupon_25` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'ID',
`user_id` bigint(20) DEFAULT NULL COMMENT '用户ID',
`coupon_template_id` bigint(20) DEFAULT NULL COMMENT '优惠券模板ID',
`receive_time` datetime DEFAULT NULL COMMENT '领取时间',
`receive_count` int(3) DEFAULT NULL COMMENT '领取次数',
`valid_start_time` datetime DEFAULT NULL COMMENT '有效期开始时间',
`valid_end_time` datetime DEFAULT NULL COMMENT '有效期结束时间',
`use_time` datetime DEFAULT NULL COMMENT '使用时间',
`source` tinyint(1) DEFAULT NULL COMMENT '券来源 0:领券中心 1:平台发放 2:店铺领取',
`status` tinyint(1) DEFAULT NULL COMMENT '状态 0:未使用 1:锁定 2:已使用 3:已过期 4:已撤回',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '修改时间',
`del_flag` tinyint(1) DEFAULT NULL COMMENT '删除标识 0:未删除 1:已删除',
PRIMARY KEY (`id`),
UNIQUE KEY `idx_user_id_coupon_template_receive_count` (`user_id`,`coupon_template_id`,`receive_count`) USING BTREE,
KEY `idx_user_id` (`user_id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1815640588360376337 DEFAULT CHARSET=utf8mb4 COMMENT='用户优惠券表';
CREATE TABLE `t_user_coupon_26` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'ID',
`user_id` bigint(20) DEFAULT NULL COMMENT '用户ID',
`coupon_template_id` bigint(20) DEFAULT NULL COMMENT '优惠券模板ID',
`receive_time` datetime DEFAULT NULL COMMENT '领取时间',
`receive_count` int(3) DEFAULT NULL COMMENT '领取次数',
`valid_start_time` datetime DEFAULT NULL COMMENT '有效期开始时间',
`valid_end_time` datetime DEFAULT NULL COMMENT '有效期结束时间',
`use_time` datetime DEFAULT NULL COMMENT '使用时间',
`source` tinyint(1) DEFAULT NULL COMMENT '券来源 0:领券中心 1:平台发放 2:店铺领取',
`status` tinyint(1) DEFAULT NULL COMMENT '状态 0:未使用 1:锁定 2:已使用 3:已过期 4:已撤回',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '修改时间',
`del_flag` tinyint(1) DEFAULT NULL COMMENT '删除标识 0:未删除 1:已删除',
PRIMARY KEY (`id`),
UNIQUE KEY `idx_user_id_coupon_template_receive_count` (`user_id`,`coupon_template_id`,`receive_count`) USING BTREE,
KEY `idx_user_id` (`user_id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1815640588360376337 DEFAULT CHARSET=utf8mb4 COMMENT='用户优惠券表';
CREATE TABLE `t_user_coupon_27` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'ID',
`user_id` bigint(20) DEFAULT NULL COMMENT '用户ID',
`coupon_template_id` bigint(20) DEFAULT NULL COMMENT '优惠券模板ID',
`receive_time` datetime DEFAULT NULL COMMENT '领取时间',
`receive_count` int(3) DEFAULT NULL COMMENT '领取次数',
`valid_start_time` datetime DEFAULT NULL COMMENT '有效期开始时间',
`valid_end_time` datetime DEFAULT NULL COMMENT '有效期结束时间',
`use_time` datetime DEFAULT NULL COMMENT '使用时间',
`source` tinyint(1) DEFAULT NULL COMMENT '券来源 0:领券中心 1:平台发放 2:店铺领取',
`status` tinyint(1) DEFAULT NULL COMMENT '状态 0:未使用 1:锁定 2:已使用 3:已过期 4:已撤回',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '修改时间',
`del_flag` tinyint(1) DEFAULT NULL COMMENT '删除标识 0:未删除 1:已删除',
PRIMARY KEY (`id`),
UNIQUE KEY `idx_user_id_coupon_template_receive_count` (`user_id`,`coupon_template_id`,`receive_count`) USING BTREE,
KEY `idx_user_id` (`user_id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1815640588360376337 DEFAULT CHARSET=utf8mb4 COMMENT='用户优惠券表';
CREATE TABLE `t_user_coupon_28` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'ID',
`user_id` bigint(20) DEFAULT NULL COMMENT '用户ID',
`coupon_template_id` bigint(20) DEFAULT NULL COMMENT '优惠券模板ID',
`receive_time` datetime DEFAULT NULL COMMENT '领取时间',
`receive_count` int(3) DEFAULT NULL COMMENT '领取次数',
`valid_start_time` datetime DEFAULT NULL COMMENT '有效期开始时间',
`valid_end_time` datetime DEFAULT NULL COMMENT '有效期结束时间',
`use_time` datetime DEFAULT NULL COMMENT '使用时间',
`source` tinyint(1) DEFAULT NULL COMMENT '券来源 0:领券中心 1:平台发放 2:店铺领取',
`status` tinyint(1) DEFAULT NULL COMMENT '状态 0:未使用 1:锁定 2:已使用 3:已过期 4:已撤回',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '修改时间',
`del_flag` tinyint(1) DEFAULT NULL COMMENT '删除标识 0:未删除 1:已删除',
PRIMARY KEY (`id`),
UNIQUE KEY `idx_user_id_coupon_template_receive_count` (`user_id`,`coupon_template_id`,`receive_count`) USING BTREE,
KEY `idx_user_id` (`user_id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1815640588360376337 DEFAULT CHARSET=utf8mb4 COMMENT='用户优惠券表';
CREATE TABLE `t_user_coupon_29` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'ID',
`user_id` bigint(20) DEFAULT NULL COMMENT '用户ID',
`coupon_template_id` bigint(20) DEFAULT NULL COMMENT '优惠券模板ID',
`receive_time` datetime DEFAULT NULL COMMENT '领取时间',
`receive_count` int(3) DEFAULT NULL COMMENT '领取次数',
`valid_start_time` datetime DEFAULT NULL COMMENT '有效期开始时间',
`valid_end_time` datetime DEFAULT NULL COMMENT '有效期结束时间',
`use_time` datetime DEFAULT NULL COMMENT '使用时间',
`source` tinyint(1) DEFAULT NULL COMMENT '券来源 0:领券中心 1:平台发放 2:店铺领取',
`status` tinyint(1) DEFAULT NULL COMMENT '状态 0:未使用 1:锁定 2:已使用 3:已过期 4:已撤回',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '修改时间',
`del_flag` tinyint(1) DEFAULT NULL COMMENT '删除标识 0:未删除 1:已删除',
PRIMARY KEY (`id`),
UNIQUE KEY `idx_user_id_coupon_template_receive_count` (`user_id`,`coupon_template_id`,`receive_count`) USING BTREE,
KEY `idx_user_id` (`user_id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1815640588360376337 DEFAULT CHARSET=utf8mb4 COMMENT='用户优惠券表';
CREATE TABLE `t_user_coupon_30` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'ID',
`user_id` bigint(20) DEFAULT NULL COMMENT '用户ID',
`coupon_template_id` bigint(20) DEFAULT NULL COMMENT '优惠券模板ID',
`receive_time` datetime DEFAULT NULL COMMENT '领取时间',
`receive_count` int(3) DEFAULT NULL COMMENT '领取次数',
`valid_start_time` datetime DEFAULT NULL COMMENT '有效期开始时间',
`valid_end_time` datetime DEFAULT NULL COMMENT '有效期结束时间',
`use_time` datetime DEFAULT NULL COMMENT '使用时间',
`source` tinyint(1) DEFAULT NULL COMMENT '券来源 0:领券中心 1:平台发放 2:店铺领取',
`status` tinyint(1) DEFAULT NULL COMMENT '状态 0:未使用 1:锁定 2:已使用 3:已过期 4:已撤回',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '修改时间',
`del_flag` tinyint(1) DEFAULT NULL COMMENT '删除标识 0:未删除 1:已删除',
PRIMARY KEY (`id`),
UNIQUE KEY `idx_user_id_coupon_template_receive_count` (`user_id`,`coupon_template_id`,`receive_count`) USING BTREE,
KEY `idx_user_id` (`user_id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1815640588360376337 DEFAULT CHARSET=utf8mb4 COMMENT='用户优惠券表';
CREATE TABLE `t_user_coupon_31` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'ID',
`user_id` bigint(20) DEFAULT NULL COMMENT '用户ID',
`coupon_template_id` bigint(20) DEFAULT NULL COMMENT '优惠券模板ID',
`receive_time` datetime DEFAULT NULL COMMENT '领取时间',
`receive_count` int(3) DEFAULT NULL COMMENT '领取次数',
`valid_start_time` datetime DEFAULT NULL COMMENT '有效期开始时间',
`valid_end_time` datetime DEFAULT NULL COMMENT '有效期结束时间',
`use_time` datetime DEFAULT NULL COMMENT '使用时间',
`source` tinyint(1) DEFAULT NULL COMMENT '券来源 0:领券中心 1:平台发放 2:店铺领取',
`status` tinyint(1) DEFAULT NULL COMMENT '状态 0:未使用 1:锁定 2:已使用 3:已过期 4:已撤回',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '修改时间',
`del_flag` tinyint(1) DEFAULT NULL COMMENT '删除标识 0:未删除 1:已删除',
PRIMARY KEY (`id`),
UNIQUE KEY `idx_user_id_coupon_template_receive_count` (`user_id`,`coupon_template_id`,`receive_count`) USING BTREE,
KEY `idx_user_id` (`user_id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1815640588360376337 DEFAULT CHARSET=utf8mb4 COMMENT='用户优惠券表';优惠券分发逻辑
1. 验证前置逻辑
不管在 service 或者 controller,再或者说我们的消息监听器,一定要在前面去加上对应的日志。因为这个日志最重要的是什么?告诉你这个消息有没有执行,以及它的消息提示是什么。因为很多时候我们在排查的时候,如果你不打印这个的话,总有一些奇奇怪怪的 bug,你没办法很好地定位。
在之前的章节中,我们仅创建了优惠券分发任务的消息生产环节,尚未进行实际消费。在分发服务中,我们将编写具体的消息队列消费者,其代码逻辑如下:
@Component
@RequiredArgsConstructor
@RocketMQMessageListener(
topic = "one-coupon_distribution-service_coupon-task-execute_topic${unique-name:}",
consumerGroup = "one-coupon_distribution-service_coupon-task-execute_cg${unique-name:}"
)
@Slf4j(topic = "CouponTaskExecuteConsumer")
public class CouponTaskExecuteConsumer implements RocketMQListener<MessageWrapper<CouponTaskExecuteEvent>> {
private final CouponTaskMapper couponTaskMapper;
private final CouponTemplateMapper couponTemplateMapper;
private final StringRedisTemplate stringRedisTemplate;
private final UserCouponMapper userCouponMapper;
@Override
public void onMessage(MessageWrapper<CouponTaskExecuteEvent> messageWrapper) {
// 开头打印日志,平常可 Debug 看任务参数,线上可报平安(比如消息是否消费,重新投递时获取参数等)
log.info("[消费者] 优惠券推送任务正式执行 - 执行消费逻辑,消息体:{}", JSON.toJSONString(messageWrapper));
// 判断优惠券模板发送状态是否为执行中,如果不是有可能是被取消状态
var couponTaskId = messageWrapper.getMessage().getCouponTaskId();
var couponTaskDO = couponTaskMapper.selectById(couponTaskId);
if (ObjectUtil.notEqual(couponTaskDO.getStatus(), CouponTaskStatusEnum.IN_PROGRESS.getStatus())) {
log.warn("[消费者] 优惠券推送任务正式执行 - 推送任务记录状态异常:{},已终止推送", couponTaskDO.getStatus());
return;
}
// 判断优惠券状态是否正确
var queryWrapper = Wrappers.lambdaQuery(CouponTemplateDO.class)
.eq(CouponTemplateDO::getId, couponTaskDO.getCouponTemplateId())
.eq(CouponTemplateDO::getShopNumber, couponTaskDO.getShopNumber());
var couponTemplateDO = couponTemplateMapper.selectOne(queryWrapper);
var status = couponTemplateDO.getStatus();
if (ObjectUtil.notEqual(status, CouponTemplateStatusEnum.ACTIVE.getStatus())) {
log.error("[消费者] 优惠券推送任务正式执行 - 优惠券ID:{},优惠券模板状态:{}", couponTaskDO.getCouponTemplateId(), status);
return;
}
// 正式开始执行优惠券推送任务
var readExcelDistributionListener = new ReadExcelDistributionListener(
couponTaskId,
couponTemplateDO,
stringRedisTemplate,
couponTemplateMapper,
userCouponMapper,
couponTaskMapper
);
EasyExcel.read(couponTaskDO.getFileAddress(), CouponTaskExcelObject.class, readExcelDistributionListener).sheet().doRead();
}
}var 关键字是在 JDK10 中引入的。它用于在 Java 中进行局部变量类型推断,旨在简化代码的编写,同时保持类型安全性。
我个人不是很习惯用,有点短脖子的样式,对于我这种强迫症来说,样式非常不美观。这里仅代入让大家有这个关键字。
2. EasyExcel 读取分发用户列表
由于 EasyExcel 并非运行在 Spring 环境中,因此引入 Spring Bean 会稍显麻烦。在此,我们直接在创建消息消费者监听类时,通过构造函数注入所需的 Spring Bean。
为什么马哥你不把这些东西在这里面直接通过 @Autowired 或者说 Spring 的方式给它构造进来?因为大家可以看到,这是一个常规的类,不是被 Spring 进行管理的。大家这样能理解吗?相当于我们每一次的分发的一个消费,都会创建一个这样的类。这样的话,我们就没办法通过注入的方式就过去了。所以说,我们的消费者他在这里面有这些类的引用,我们直接给他传递就好了。
然后下面这个是比较常规的解法,就是通过它的读取的方式,把它的这些类给它放进来,它就会通过默认的方式进行一个读取,然后我们直接给它跳过来。
然后这里面的话,代码其实都还比较简单。首先第一步,就是我们构造出来对应该用户的 key,然后去给它进行一个自检。对吧?虽然这个叫“自增”,但是我们的值是 -1,也就是自己。然后如果说模板扣减失败的话,他就直接返回吗?我们这边没有报错的话,其实也没有很大的必要性。
然后的话,他会去这里面进行一个调用,对不对?检查优惠券模板库存。然后大家这一行可以忽略
<!--通过MySQL悲观行记录锁确保库存不会被多扣,并采用上层业务自旋重试直至成功将优惠券库存扣减至零 在 V2、V3 的时候才会用到的
@RequiredArgsConstructor
public class ReadExcelDistributionListener extends AnalysisEventListener<CouponTaskExcelObject> {
private final Long couponTaskId;
private final CouponTemplateDO couponTemplateDO;
private final StringRedisTemplate stringRedisTemplate;
private final CouponTemplateMapper couponTemplateMapper;
private final UserCouponMapper userCouponMapper;
private final CouponTaskMapper couponTaskMapper;
@Override
public void invoke(CouponTaskExcelObject data, AnalysisContext context) {
// 通过缓存判断优惠券模板记录库存是否充足
String couponTemplateKey = String.format(EngineRedisConstant.COUPON_TEMPLATE_KEY, couponTemplateDO.getId());
Long stock = stringRedisTemplate.opsForHash().increment(couponTemplateKey, "stock", -1);
if (stock < 0) {
// 优惠券模板缓存库存不足扣减失败
return;
}
// 扣减优惠券模板库存,如果扣减成功,这里会返回 1,代表修改记录成功;否则返回 0,代表没有修改成功
int decrementResult = couponTemplateMapper.decrementCouponTemplateStock(couponTemplateDO.getShopNumber(), couponTemplateDO.getId(), 1);
if (!SqlHelper.retBool(decrementResult)) {
// 优惠券模板数据库库存不足扣减失败
return;
}
// 添加用户领券记录到数据库
Date now = new Date();
DateTime validEndTime = DateUtil.offsetHour(now, JSON.parseObject(couponTemplateDO.getConsumeRule()).getInteger("validityPeriod"));
UserCouponDO userCouponDO = UserCouponDO.builder()
.couponTemplateId(couponTemplateDO.getId())
.userId(Long.parseLong(data.getUserId()))
.receiveTime(now)
.receiveCount(1) // 代表第一次领取该优惠券
.validStartTime(now)
.validEndTime(validEndTime)
.source(CouponSourceEnum.PLATFORM.getType())
.status(CouponStatusEnum.EFFECTIVE.getType())
.createTime(new Date())
.updateTime(new Date())
.delFlag(0)
.build();
try {
userCouponMapper.insert(userCouponDO);
} catch (BatchExecutorException bee) {
// 用户已领取优惠券,会被唯一索引校验住,直接返回即可
return;
}
// 添加优惠券到用户已领取的 Redis 优惠券列表中
String userCouponListCacheKey = String.format(EngineRedisConstant.USER_COUPON_TEMPLATE_LIST_KEY, data.getUserId());
String userCouponItemCacheKey = StrUtil.builder()
.append(couponTemplateDO.getId())
.append("_")
.append(userCouponDO.getId())
.toString();
stringRedisTemplate.opsForZSet().add(userCouponListCacheKey, userCouponItemCacheKey, now.getTime());
}
@Override
public void doAfterAllAnalysed(AnalysisContext analysisContext) {
// 确保所有用户都已经接到优惠券后,设置优惠券推送任务完成时间
CouponTaskDO couponTaskDO = CouponTaskDO.builder()
.id(couponTaskId)
.status(CouponTaskStatusEnum.SUCCESS.getStatus())
.completionTime(new Date())
.build();
couponTaskMapper.updateById(couponTaskDO);
}
}
Q:为什么添加用户已领取优惠券列表里,要追加用户领券记录的 ID 呢?为什么不是单独的优惠券模板 ID?
A:因为一个优惠券可能被用户领取多次,如果说只保存优惠券模板 ID,就没有办法满足这个需求,因为 ZSet 会过滤重复记录。
通过 MySQL 悲观行记录锁确保库存不会被多扣,SQL 如下所示:
<!-- 通过 MySQL 悲观行记录锁确保库存不会被多扣,并采用上层业务自旋重试直至成功将优惠券库存扣减至零 -->
<!-- 这里这行注释后半段有点问题,上层业务重试逻辑是 v2 分支逻辑 -->
<update id="decrementCouponTemplateStock">
UPDATE t_coupon_template
SET stock = stock - #{decrementStock}
WHERE shop_number = #{shopNumber}
AND id = #{couponTemplateId}
AND stock >= #{decrementStock}
</update>这里有些同学可能会有疑问,为什么要先访问优惠券模板缓存进行扣减,然后再扣减优惠券模板数据库?
这是因为在后续的优惠券秒杀流程中,我们也是先通过缓存扣减,再扣减数据库。如果这里先扣减数据库,可能会出现缓存扣减成功但数据库扣减失败的情况。为保持一致性,我们在此流程中同样先扣减缓存,然后再扣减数据库。
此外,如果用户已经领取过该优惠券,为了简化流程处理,我们通过捕获唯一索引异常来跳过当前流程。
最后,我们使用 Redis 的 ZSet 来缓存用户的领券记录,并将领券时间作为 Score 值,这样用户在查询时可以按时间倒序显示领取记录。
然后在这里面可以看到,我们是通过悲观行锁的方式来确保它的库存不会被多扣。之前大家如果看过我们的视频的话,应该是能够理解的。那就是我们通过 ID 的这种方式,然后去确保我们通过悲观锁的形式,然后去对它进行一个锁定,然后保障我们不会被多扣。
然后因为我们这里面加了一个条件:库存大于等于它对应要扣减的一个库存,所以说这里面还有一点乐观的一些机制。
所以说就有同学去纠结:“马哥,我到底是乐观还是悲观?”说实在话,之前大家在网上学秒杀,对吧?大家人云亦云这个“乐观”。但是在我看来的话,包括我之前也是这么认为的,后面其实我又仔细思考一下这件事情。在我目前看来,其实这个本质上是悲观的。因为乐观锁的一个寓意,就是在不使用锁的情况下,对这个记录进行并发安全的访问,对吧?但是我们这里面买的购的被加了行锁,它其实已经是一种排他锁,对不对?所以说我不觉得它是乐观锁。
当然,之前星球里面也有很多小伙伴挺纠结的。有些面试官说是乐观,那就是乐观,对吧?不要在面试的时候跟面试官去抬这种杠。
在这里面我们继续进行。然后等我们领完之后,我们直接去把这个记录给放到我们对应的一个数据库里面。大家可以看到,我还是蛮喜欢使用这种构建者模式去进行创建对象的——这种一个是美观,一个是对美观。
然后这里面我们通过了一个它的伪索引、它的一个异常去进行一个补货。因为我们刚才有加伪索引,如果他已经领取过了,OK,我们直接校验组返回即可。我们把这个记录加到我们对应的一个缓存里面,这样的话就能够解决问题了。
执行优惠券分发
然后这里面我们通过了一个它的伪索引、它的一个异常去进行一个补货。因为我们刚才有加伪索引,如果他已经领取过了,OK,我们直接校验组返回即可。我们把这个记录加到我们对应的一个缓存里面,这样的话就能够解决问题了。
再然后的话,我们在最后一行——这个是 Excel 它对应的一个 API。如果是最后一行的话,执行完之后,我们会把……用户他不对,不是用户,我们会把优惠券的推送的这条记录给他设置一个完成时间和一个状态。
我们这里面……不好意思,我们这里面直接把断点放开,然后我们去看它这里面在跑。
然后我们去看一下这条记录,看到没有?我们的优惠券模板库存一直在往下降。然后我们可以看到我们对应的分发任务,对吧?它的状态是 1。1 的话是什么?大家看一下,1 的话是“执行中”。
我们可以去等一下他。等到库存变成 1 的时候,我们的这条分发任务其实就已经结束了。可能要稍等一小会儿,因为我们 V1 最大的问题就是:它的所有的记录都是单次和数据库进行交互的。这样的话,其实它的性能全部都卡在网络 IO 上面了,对不对?
就是我们在计算机的世界里面,CPU——纯 CPU——已经是非常快的,但是问题卡在和磁盘 IO 和网络 IO 的一个消耗上面,对不对?
OK,我们可以看到这个已经结束了。包括我们 V2、V3 版本,其实更多的就是通过批量的这种思想去解决这个问题。
然后我们去看一下,可以看到我们的这个状态已经变成了……不对,我们的库存已经变成 1,然后我们的状态已经变成了 3,并且我们完成时间已经结束了。
1. 创建优惠券模板
创建新的优惠券模板,RocketMQ 5.x 默认任意延迟消息最大间隔 3 天,所以大家自己启动 RocketMQ 5.x 的话,记得设置结束时间在距离当前时间 3 天内。
{
"name": "用户下单满10减3特大优惠",
"source": 0,
"target": 1,
"goods": "",
"type": 0,
"validStartTime": "2024-07-08 12:00:00",
"validEndTime": "2024-08-30 23:59:59",
"stock": 20000,
"receiveRule": "{\"limitPerPerson\":10,\"usageInstructions\":\"3\"}",
"consumeRule": "{\"termsOfUse\":10,\"maximumDiscountAmount\":3,\"explanationOfUnmetConditions\":\"3\",\"validityPeriod\":\"48\"}"
}因为星球通用云服务器已经变更了这个最大延时时间配置为一年,所以这里时间长一点无所谓。修改 RocketMQ 5.x 延迟时间配置详情见下文。
2. 创建 Excel 分发记录
我们之前创建的 ExcelGenerateTests#testExcelGenerate 单元测试默认创建 100 万的分发记录,其实是有点大哈,咱们自己执行的话,只需要少量的数据即可,要不然执行起来太慢也不太行。
这里我建议 5001,为什么有零有整的?因为下一节会用到。
public final class ExcelGenerateTests {
/**
* 写入优惠券推送示例 Excel 的数据,自行控制即可
*/
private final int writeNum = 5001;
private final Faker faker = new Faker(Locale.CHINA);
private final String excelPath = Paths.get("").toAbsolutePath().getParent() + "/tmp";
// ......
}3. 创建优惠券分发任务
大家替换自己本地的 fileAddress 地址,并且复制刚才的优惠券模板 ID,sendType 为立即发送。
{
"taskName": "发送百万优惠券推送任务",
"fileAddress": "/Users/machen/workspace/opensource/onecoupon-rebuild/tmp/oneCoupon任务推送Excel.xlsx",
"notifyType": "0,3",
"couponTemplateId": 1829344152127647745,
"sendType": 0
}提交后就会看到我们的分发服务开始执行了,消费者日志打印如下:
2024-08-30T10:07:11.860+08:00INFO74088---[g-mading0924_17]CouponTaskExecuteConsumer:[消费者] 优惠券推送任务正式执行 - 执行消费逻辑,消息体:{"keys":"1829340057182523394","message":{"couponTaskId":1829340057182523394},"timestamp":1724983631789,"uuid":"b56eb4dd-6d9e-48a6-b42c-c31068559419"}大家可以记一下自己电脑跑这些记录需要多长时间,然后下一节我们做重构时,就会震惊对应的性能提升。
4. 查询执行结果
通过查询数据库得知,我们的数据均匀散落在了 2 个库的 32 张表里,刚好 5000 条(我测试的时候用了 5000 条记录)用户领券记录。
被标记的就是我们的数据库表里有多少数据行数。


我用本地跑的 RocketMQ 执行 5000 条用户优惠券分发记录,差不多用了 1分钟,云服务器 RocketMQ 测试了下会多个 10%-20% 的消耗。
然后我们查看优惠券模板表的库存扣减,刚好是和 Excel 中记录的数据保持一致。

常见问题答疑
1. RocketMQ 延时时间
默认 RocketMQ 最大延时时间 3 天,如果我们发送延时执行时间超过这个数值,则会报以下错误。
org.springframework.messaging.MessagingException: CODE: 13 DESC: timer message illegal, the delay time should not be bigger than the max delay 259200000ms; or if set del msg, the delay time should be bigger than the current time BROKER: xxx.xxx.xxx.xxx:10911
错误来源是从 Broker 抛出来的。
case WHEEL_TIMER_MSG_ILLEGAL:
response.setCode(ResponseCode.MESSAGE_ILLEGAL);
response.setRemark(String.format("timer message illegal, the delay time should not be bigger than the max delay %dms; or if set del msg, the delay time should be bigger than the current time",
this.brokerController.getMessageStoreConfig().getTimerMaxDelaySec() * 1000L));getTimerMaxDelaySec 方法返回的是默认值,如下所示:
private int timerMaxDelaySec = 3600 * 24 * 3;
public int getTimerMaxDelaySec() {
return timerMaxDelaySec;
}因为我们公共云服务器已经修改了这个配置,所以大家就算超过 3 天也无所谓的。那怎么变更这个延时时间呢?
其实很简单,只需要在 RocketMQ 的 Broker.conf 文件中加一行参数即可。
timerMaxDelaySec = 31622400timerMaxDelaySec 的数据单位默认为秒,所以我们采取闰年的一年秒数即可。
这样的话,我们在优惠券模板创建的时候,还需要在优惠券模板的数据校验中加入有效期不能超过当前时间一年的验证逻辑。
2. RocketMQ 超长延时时间是否会被清理?
之前我有点担心设置这么长时间的延时时间,和 RocketMQ 的消息清理策略是否会有冲突?
RocketMQ 消息清理策略即消息发送后,在指定时间后会被删除,腾出磁盘空间,默认是 48 小时后清理。
经过我实际测试,把清理时间改为 1 小时,然后延时时间改为 2 小时,延时消息可以正常执行。我个人猜测,延时消息的队列是个特殊队列,并不属于普通被清理的范畴。后面如果有机会看看 RocketMQ 的源码,这里再给大家补充详细内容。
完结,撒花 🎉
在优惠券分发任务里面,其实上面有讲到,就是说它是支持一些任意的延迟,比如说“我三天后执行”,比如说“我明天下午 5 点执行”。在之前我们 RocketMQ 5.0 版本之前是实现不了的,因为它之前的内容是通过叫做固定的一个延时机制。但是 5.0 之后,它其实优化了一个事情:通过时间轮的算法去解决这个问题。
但是总之,咱们就官方的角度上来考虑,它给的最大延迟时间是三天。如果说我们的发送时间超过了这个值,就会报错。这个是从博客那边弄过来的,当时我就看了一下它的源码,然后就在……其实大家去把 RocketMQ 拉下来一看就知道了。
因为我是用的我现在用的本地的消息队列,所以说我也是已经改过了。当然我们公共的云服务器其实也已经改过了。如果说大家想要去改的话,只需要在这个 RocketMQ 的配置文件里面加一个参数就可以了。然后它的默认单位是秒,然后我们直接取一年的时间,这样就可以了。
然后可能会有同学会纠结说:“马哥,我这么长时间的延迟时间,对于消息队列来说是否会有压力?”
我可以很直白地讲:就是不会有压力。为什么?首先你的数据量不会很多——你想,运营人员去创建这种分发的延时任务,它不会有多少。其次,就算有很多,一级别 10 亿级别——挺多了——但是你要知道,我们在消息队列里面,它的一条消息是以磁盘的形式存储的,10 亿条消息它的量才多大,对不对?所以说我觉得不会有问题。
然后,因为我们 RocketMQ 默认的话,它是有一个磁盘的清理策略的。不过它的磁盘清理策略是针对那些已经消费过的消息。所以说,我们这些没有消费过的消息也不会被处理。
zouhu:马哥,后台管理服务的发送分发任务和分发服务的发送优惠劵之间的关系有点弄不懂?发送分发任务为什么要插入到数据库,分发任务不是通过消息队列来读取的吗?
马丁 回复 zouhu:后台管理负责创建、查看、修改各种运营所需要的记录。分发服务负责将优惠券分给用户手里,两个职责不同。 插入数据库是因为创建记录要留痕,要查看进度等等。
希望~无尽:马哥,怎么理解,如果这里先扣减数据库,可能会出现缓存扣减成功但数据库扣减失败的情况。我有点不懂为什么数据库会扣减失败?
马丁 回复 希望~无尽:比如说数据库扣减超时,再比如说数据库里面的库存余额没有了,都有可能的
地信哥 回复 希望~无尽:man,要注意在《优惠券分发流程中》先扣减缓存库存,再扣减数据库库存,是为了和后续《优惠券秒杀流程》匹配,因为《优惠券秒杀流程》就是先扣减缓存库存,再扣减数据库库存。 我们先假设优惠券库存和数据库库存都只剩1个库存: 假设你在《优惠券分发流程中》先A:扣减数据库1个库存,再B:扣减缓存1个库存; 你在《优惠券秒杀流程中》先B:扣减缓存1个库存,再A:扣减数据库1个库存, 那么有可能出现以下流程: 1.分发流程A——》2.秒杀流程B——》3.秒杀流程A——》4.分发流程B 当你执行完1、2的时候,此时数据库库存和缓存库存都为0,那么你再执行3的时候,就会失败。 以上是我自己的理解,如有不对请指正
warrior 回复 地信哥:有点不理解
基洛夫 回复 地信哥:是不是类似于避免死锁的那种给资源排序的方案
基洛夫 回复 地信哥:大佬 还没学到优惠券秒杀部分 请问是不是他们可以共用一套优惠券模板? 所以这里要考虑两个业务的扣减库存的顺序问题?
鹅鹅鹅 回复 地信哥:其实我想问,同一张优惠券真的会有同时被分发和秒杀的时候吗,被秒杀的优惠券往往应该库存不多,分发的优惠券应该往往库存十分充足吧
地信哥 回复 鹅鹅鹅:一切皆有可能,实现业务要考虑任何情况
鹅鹅鹅 回复 地信哥:但实际上很多时候也不会考虑数据库宕机等概率很低的情况呀
地信哥 回复 鹅鹅鹅:别犟
鹅鹅鹅 回复 地信哥:照你这么说那我可不可以把一切脱离业务实际的问题都说成是犟呢😨
地信哥 回复 鹅鹅鹅:又犟
鹅鹅鹅 回复 地信哥:抽象了哈老哥,不是你能回答的就是“所有情况都要考虑”,不能回答的就是“犟”
地信哥 回复 鹅鹅鹅:我睡觉了,明天让我好好想想怎么回答你
鹅鹅鹅 回复 地信哥:个人理解是,不会对正常业务逻辑造成很大影响的问题,顺带也就解决了,成本很低。其他有些问题虽然也会发生,但可能让代码变复杂,就考虑解决成本
int main() 回复 鹅鹅鹅:我觉得这种库存不足的场景多少有点扯,这种批量发的都是廉价券,秒杀的券都会单独搞,甚至会接口隔离,如果是红包雨的话还会redis库存分片
鹅鹅鹅 回复 int main():确实很扯,百分之99.9999都不会发生这种问题
int main() 回复 鹅鹅鹅:一般都宁可库存超了也不会少,除非是意料之外的爆款
鹅鹅鹅 回复 int main():分发优惠券也不存在爆款不爆款了,都是由商家来决定想发多少就发多少,而且一般这种优惠券也不能由用户自己去领取
int main() 回复 鹅鹅鹅:优惠券的话,有一种是亏欠也会发的,纯纯就是为了引流,这种的话肯定是限量的,但是这个属于是秒杀业务层面了。而这种大批量发的券都是很廉价的那种小额券,理论上是平台方会发,平台方有用户的个人信息,整理出Excel然后对Excel加工处理,按照sheet,结合线程池和mq的并发消费进行海量的分发
int main() 回复 鹅鹅鹅:判断是否结束也是根据sheet读取的后处理里面的逻辑实现的。也没必要发消息,最后一批次了,直接在方法里面执行,还能计算任务完成个数,用来更新状态
int main() 回复 鹅鹅鹅:券的话,包括平台券和商家券,这种廉价券大多都是平台券
int main() 回复 鹅鹅鹅:根据刚才的逻辑,根本不可能超发,多设置库存都行
鹅鹅鹅 回复 int main():用线程池的话就不需要mq了吧
int main() 回复 鹅鹅鹅:需要的,性能差了很多,一个线程处理一个sheet,一个sheet批量发,每个批次并发消费,最后一个批次在后处理执行,如果存批量记录的list为空就直接更新进度,任务进度计数,任务状态。每个线程负责一个sheet,也就是说会在redis看到十个进度条。目前这里的问题是用什么作为进度条的key,如果是任务ID的话,只能通过MySQL唯一健判断是不是重复领取,如果是用模板ID的话可以判断,但是只能一次性使用这个模板,想再搞一个就得重新创建,由于幂等判断,只能在第一次创建模板开始执行开始之后两三秒之后再创建一个一模一样的新模板,我觉得这个策略就行了,因为这种磁盘空间很廉价,为了给每个人多发几个重复创建一两个功能有效期啥的都一样的券也没什么。幂等注解主要是防不想多创建却多创建的场景。
int main() 回复 鹅鹅鹅:你可以理解为如果一个sheet十万个,一批次五千,你用单独的服务器部署mq,mq可以十个线程并发消费这个sheet的分发任务,应用服务器如果是十个线程,那么用了mq之后就是远超仅仅十个线程的线程池能达到的性能。
int main() 回复 鹅鹅鹅:我自己测了,不用的话半小时,用了之后就六分半到七分钟
int main() 回复 鹅鹅鹅:这也仅仅是自己的笔记本能提升的,如果是生产的服务器呢?集群部署的mq,高性能的服务器,如果再用上虚拟线程,直接起飞,会非常快
int main() 回复 鹅鹅鹅:不过这里有个坑,就是一定要找插入记录再扣减MySQL库存,因为四个行为都在一个事务,如果先锁操作扣减库存的话,事务还没提交,后面插入还是长事务,就很容易造成锁超时,然后少发,漏发,一般是几万个甚至十多万个漏发,所以要么先用一个事务或者循环指数退避确保一定成功,然后再执行插入和redis的事务,要么就是我刚才说的先插入记录再直行锁操作,最后同步redis库存和记录。事务成功与否都会在后面记录进度
鹅鹅鹅 回复 int main():那其实只要把现在的版本改成一个线程处理一个sheet就行了,后面mq的具体分发逻辑都不用咋变
int main() 回复 鹅鹅鹅:后面也是要变的,他那个会发很多无用的消息,我这个版本每个线程的任务只需要发单个sheet里面的批次个消息或者批次减一个消息
int main() 回复 鹅鹅鹅:他原来的逻辑是每行都会发到下游判断,这样的话无用的消息太多了
int main() 回复 鹅鹅鹅:而且行号可以通过easyExcel的分析上下文直接获取,没必要计算++
鹅鹅鹅 回复 int main():直接在上游加一个取余判断就不会多发了
鹅鹅鹅 回复 int main():还有一个问题是,sheet拆分是应该在提交excel时就提交拆分好的,还是直接先进行一次解析完成拆分,再去提交任务到线程池呢
int main() 回复 鹅鹅鹅:先自己用程序拆,然后再请求接口,这个不麻烦,问gpt就行,自己测试的话直接用faker生成就行
地信哥:马哥你这两句话是不是自相矛盾呀,我有点看不懂了= =
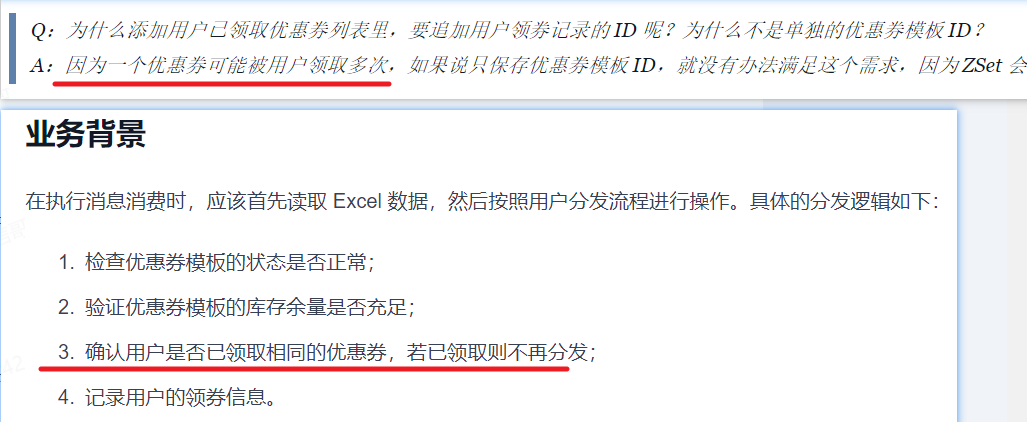
马丁 回复 地信哥:我们在分发的时候,逻辑和普通领取是有点儿不一样的。分发逻辑中,只判断用户领取过,直接让他跳过,不存在领取多次的行为
地信哥 回复 马丁:嗷嗷,我还以为分发和领取是一个意思。那我懂了
mni 回复 马丁:马哥,如果同一种优惠券 用户已经领取了多张(多于1张),再执行分发且excel表中存在该用户,此时receive_count不为1没法通过唯一索引跳过了吧。
Young 回复 mni:对,所以在分发前要查询用户的领取次数
Scofield. 回复 mni:确实存在这种问题
Scofield. 回复 马丁:马哥,这里是不是不应该用唯一索引来避免发送已经领取过的优惠券,这样可能会导致用户领取过一次券,这次发放跳过了,如果用户领取过大于一次,那么还会发放。应该先查询用户领取该优惠券次数是否为0,为0再发放,不为0则说明用户已经领取过了不用再发放了。
鹅鹅鹅 回复 mni:我理解的是每次领取都会添加一条领取记录,而不是在原纪录上修改,第一次receive_count为1,第二次receive_count为2,如果有receive_count > 1的记录,那么一定有receive_count = 1的记录
鹅鹅鹅 回复 Scofield.:我理解的是每次领取都会添加一条领取记录,而不是在原纪录上修改,第一次receive_count为1,第二次receive_count为2,如果有receive_count > 1的记录,那么一定有receive_count = 1的记录
不爱学习的懒猫 回复 鹅鹅鹅:我现在有点疑问,这里的receive_count具体在代码哪里进行修改了吗?我并没有看到,老哥可以说一下吗?
鹅鹅鹅 回复 不爱学习的懒猫:这个字段的意思是标识第几次领取,用户自己主动领取的业务应当是没做的,这里只是说假如用户领取过的话,每一次领取都会对应一条数据,所以领取过多次的话就一定领取了第一次,就一定有receive_count等于1的记录
花开富贵 回复 mni:我的理解是,领取和分发都是添加receive_count为1的记录(我们还没有写领取的代码,现在分发的逻辑是这样的),而我们刚好设置了唯一索引,这就可以保证每个优惠券不管是如何获取的都只能领取一次,也保证了如果领取之后,在后续的分发过程中也可以通过唯一索引保证不再发放给用户。
花开富贵 回复 鹅鹅鹅:我的理解是,领取和分发都是添加receive_count为1的记录(我们还没有写领取的代码,现在分发的逻辑是这样的),而我们刚好设置了唯一索引,这就可以保证每个优惠券不管是如何获取的都只能领取一次,也保证了如果领取之后,在后续的分发过程中也可以通过唯一索引保证不再发放给用户。咱俩意思一样吗
鹅鹅鹅 回复 花开富贵:如果平台券既可以分发也可以自行领取的话,那么在Redis应该也要有一个用户已领取次数的缓存,然后自行领取的时候receive_count就是这个缓存数 + 1。分发的话都是receive_count为1,因为本来就让领一次,不论是自己兑换过也好,已经被分发了也好,都是可以限制住的
没看懂”扣减库存逻辑的话同样是采用乐观锁机制保障“这句话,这个乐观锁机制是指 MySQL 底层使用了乐观锁机制?
乐观锁机制指的是 update ...... where stock >= "decement",在修改的时候才判断库存是否足够。如果是先select拿到库存,然后自己判断是否足够,足够的话再update,但是这两个操作不是原子性的,会出现 库存 < 0 的情况
分享一下自己捋的思路 首先看admin后管中的执行流程 1.CouponTemplateServiceImpl类 执行createCouponTemplate方法创建了优惠券,然后让该优惠券信息存入数据库 2.CouponTaskServiceImpl类 执行createCouponTask方法创建优惠券分发任务,然后让该优惠券分发任务存入数据库 这个任务是分发指定的优惠券给Excel中的用户,统计Excel中的行数是通过线程池异步执行的。 如果分发任务是立即发送,那状态就是执行中,如果不是立即发送,也就是定时发送,那状态就是待执行 如果是立即发送,就通过mq发送该分发任务id 再来看distribution分发的流程,注意我们分发的时候,是分发指定的优惠券给Excel中的用户 也就是优惠券id在这个流程中是确定的 1.CouponTaskExecuteConsumer类 执行onMessage消费mq中的消息,获取分发任务id 然后根据id从数据库中查询该任务 判断任务状态是否是执行中,如果不是执行中,那就说明还不该执行 如果任务是执行中,那就判断优惠券状态是否正确,也就是看优惠券是生效还是结束 如果优惠券生效,那就开始执行优惠券推送任务/分发任务 2.ReadExcelDistributionListener类 每获取一行Excel中的数据就会执行invoke一次 首先通过缓存判断优惠券模板记录库存是否充足,因为之前创建优惠券的时候已经将信息存入redis 如果缓存中的库存-1之后小于0,那就说明没库存了 过了缓存这一关就扣减数据库中的优惠券库存 优惠券库存扣减成功就说明可以分发给用户优惠券,所以开始构建用户领券记录 这里注意,validityPeriod是用户获取到优惠券之后优惠券的使用有效期,而不是优惠券的过期时间 所以要通过当前时间加上这个偏移量获取该条用户领券记录的过期时间 然后将用户领券记录插入数据库中,通过唯一索引校验用户是否领取过该优惠券 然后添加优惠券到用户已领取的优惠券缓存中 优惠券分发完成之后,执行doAfterAllAnalysed方法设置该分发任务的状态为执行成功以及完成时间
请教一下马哥,这里对缓存和数据库的操作为什么不加事务? 例如redis扣减库存成功了,但是数据库操作失败了。redis的缓存不得回滚嘛?
马哥,还有个问题,即在消费推送信息的时候,代码中是先检查模版状态已经被取消,没被取消才往下。如果检查的时候模版状态是正在执行的,检查逻辑完了之后模版刚好被取消了。此时又往下执行推送任务,这是不是不符合逻辑?
第20小节:开发用户优惠券分发功能(二)
业务背景
在上一节中,我们通过 EasyExcel 的方式读取用户分发券 Excel,并将结果保存到了数据和缓存中。如果你刚工作,写之前的代码没问题,如果工作几年或者有全局意识,大家就应该能想到,代码逻辑是有问题的。我梳理了几点内容,大家一起看看:
- 每次都单条方式操作 Redis 和 MySQL,网络成本消耗巨大,应该采用批量的形式执行,能节省大量时间。
- 如果中间应用重启或者宕机,我们还得重新执行,并不符合我们的预期,希望能够从上次执行点位开始。
- 不可能所有用户记录都是分发优惠券成功的,如果说有分发失败的用户记录,应该标记好保存数据库。
- 尽量不要在单个消息消费逻辑中执行太长的业务逻辑,我们应该尽可能的让这个消息执行时长变短。
那要么有两种方案:
- 要么就是我们把这个消息拆成 N 个小的消息去让它执行。比如说我一百万的 Excel,我可以每一次消息让它执行 5000,这是一个逻辑。选择了第一个
- 第二块的话,就是把它变成一个异步的、定时触发的逻辑。
其实这个很好实现,就是加一个缓存,里面加一个它对应的一个记录位就可以了。
然后第三条的话,是我们这里面的重头戏:那就是我们每次都以单条的形式去操作 Redis 和数据库,网络成本是很高的。因为像我们在执行这个逻辑的时候,最耗时的其实是 IO,对吧?其实 CPU 它是不瓶颈的。我们会采用一种批量(Batch)的形式去执行,能够节省我们大量的时间。
然后第四块的话,在上一个版本里面,我们如果说用户他的分发失败了的话,其实直接“跳过”了,对吧?在这个版本里面,我们是要给它记录下来,并且在常规里面的话,在应用界面里面它是能够去进行展示的,所以这个是很有必要的。
然后下面是我们第二个版本它的一个逻辑图。上面的话是我们之前讲过的,就是任务的执行阶段。其实重点是我们的读取分发逻辑,和我们对应的执行——就是去给用户去进行扣减库存,以及对应的一个给用户添加他已经要领取的优惠券。这一步逻辑,这两块是比较重要的。
v2 新版本业务逻辑如下:
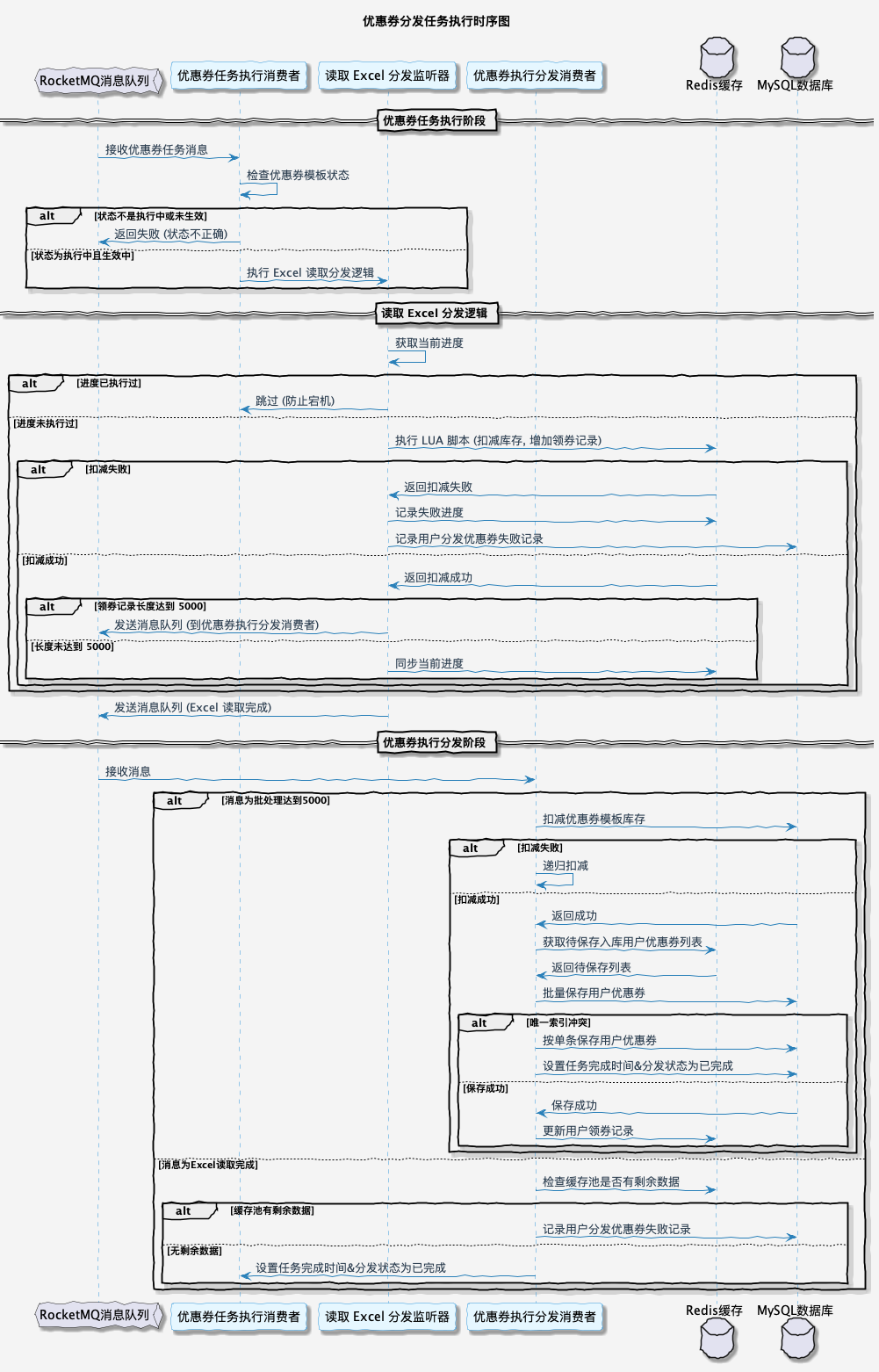
Git 分支
20240829_dev_coupon-distribute-v2_easyexcel-cache_ding.ma
origin/20240831_dev_coupon-distribute-v2_easyexcel-cache_ding.ma(rebuild)
v1那一块还只有两点分支
数据库表设计
新增的表用于记录分发过程中因优惠券库存不足或用户已领取等原因导致的失败记录。这些记录会生成错误 Excel 文件,交付给前端展示,方便业务人员查看失败用户及失败原因。
进入 one_coupon_rebuild_0 数据库,执行下述 SQL。
CREATE TABLE `t_coupon_task_fail` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'ID',
`batch_id` bigint(20) DEFAULT NULL COMMENT '批次ID',
`json_object` text COMMENT '失败内容',
PRIMARY KEY (`id`),
KEY `idx_batch_id` (`batch_id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='优惠券模板发送任务失败记录表';在 V2 里面的话,我们加了一张数据库表,它就是用来做分发失败的记录保存。里面其实很简单,就是一个主机 ID、我们的一个分发任务 ID,还有一个失败的内容。其实失败内容的话是一个 JSON 字符串,它有两个字段,当然后续也可以扩展:
- 第一块的话,就是它当前的一个行数,也就是在 Excel 里面的行数。
- 第二块的话,就是它失败原因。
我们失败原因的话目前定义了两种:
- 第一种的话,就是优惠券库存不足;
- 第二块的话,用户已经领取过优惠券。
重构优惠券分发逻辑
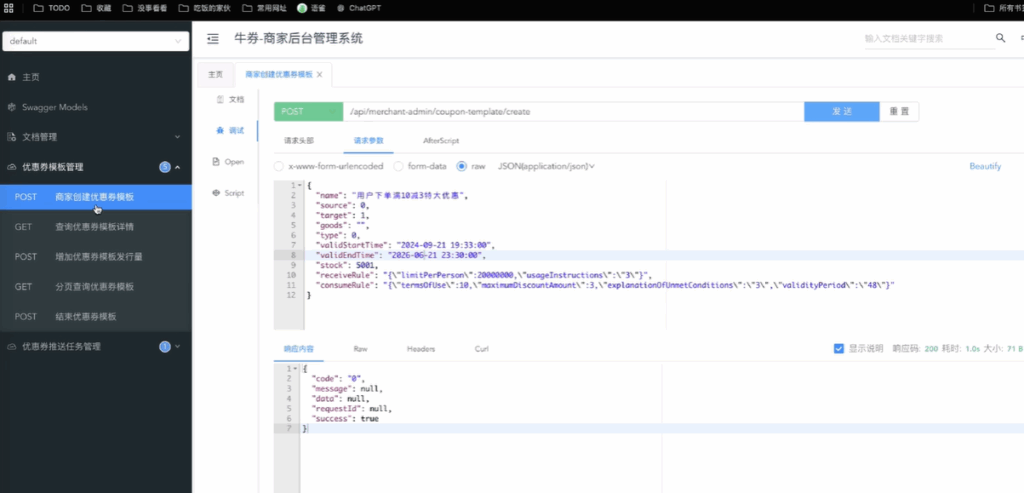
首先老样子,我们去加一个优惠券的模板,然后找到这张表,然后读出来。然后我们在这里去给它创建对应的任务。我们把对应的去打上一些断点——因为我们这个分支我还没有提交,还在进行一些本地的验证,看看是否万无一失,避免后续有些返工。然后因为我们的很多核心代码都在分发监听器里面,所以说我们直接把断点打到这里就好了。
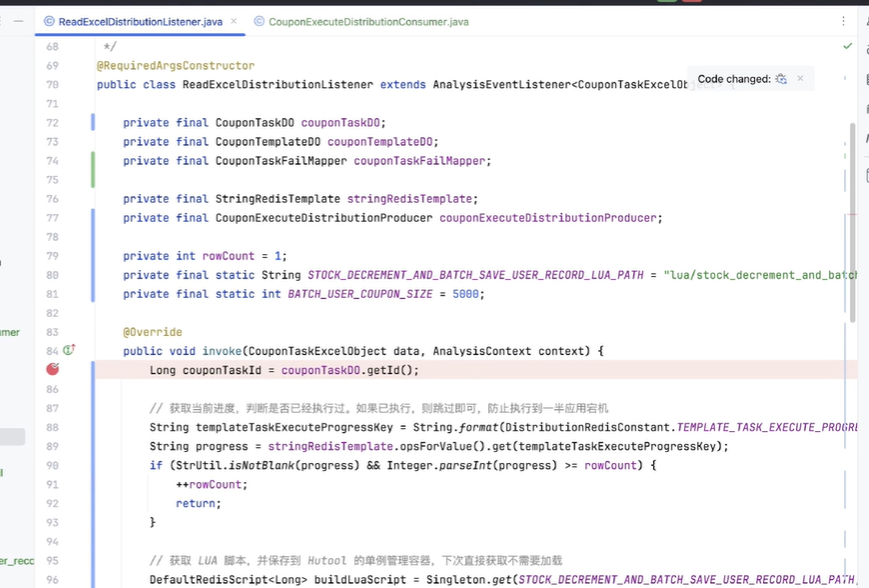
第二个断点:然后我们需要重启一下。重启的话其实不影响我们发送。逻辑已经打到这边了,然后到我们的监听器这里。
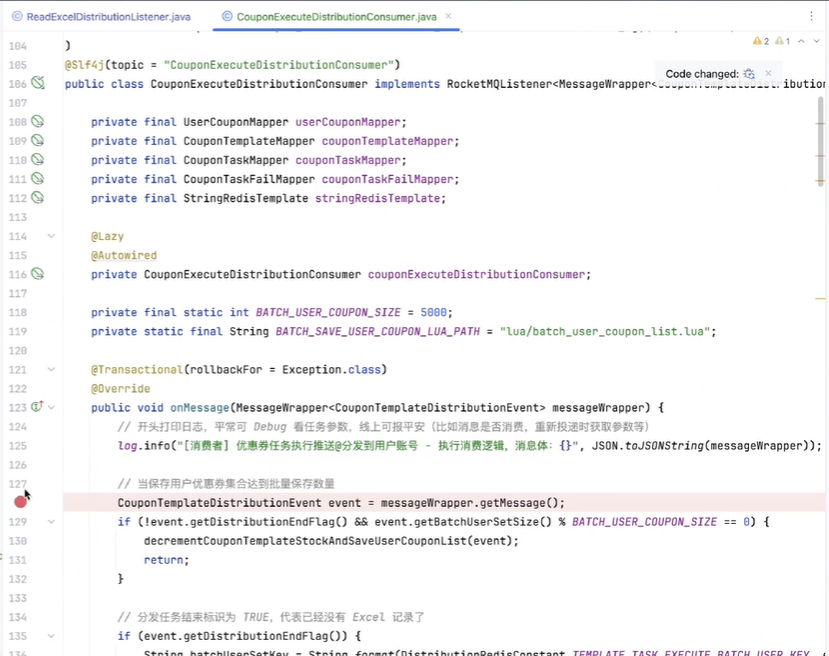
首先停在listener这里。刚才我们有说,如果说宕机的话,希望我们能够在它的宕机前的点位去继续执行。所以说这里我们会有一个判断:我们在缓存里面加了一个 Key,然后这个 Key 记住了就是我们本次任务所对应的一个消费点位是什么。如果说我当前的一个进度是小于这个值的话,就证明它宕机过,我们直接return跳过就好了。然后开始执行。代码如下
@Override
public void invoke(CouponTaskExcelObject data, AnalysisContext context) {
Long couponTaskId = couponTaskD0.getid();
// 获取当前进度,判断是否已经执行过。如果已执行,则跳过即可,防止执行到一半应用宕机
String templateTaskExecuteProgressKey = String.format(DistributionRedisConstant.TEMPLATE_TASK_EXECUTE_PROGRESS_KEY, couponTaskId);
String progress = stringRedisTemplate.opsForValue().get(templateTaskExecuteProgressKey);
if (StrUtil.isNotBlack(progress) && Integer.parseInt(progress)
++rowCount;
return;
}
第二步的话,就是我们要去 Redis 里面去进行扣减对应的优惠券模板的库存。之前是这样的,现在的话,因为我们上面有讲过,我们希望有一个批次的概念——比如说我们一个批次是 5000。如果说它的批次不足 5000 的话,我们要有一个缓冲队列给它缓存起来。
这里的话,我们采用了在 Redis 里面开辟了一个集合,让它去进行一个缓存。
// 获取 LUA 脚本,并保存到 Hutool 的单例管理器,下次直接获取不需要加载
DefaultRedisScript<Long> buildLuaScript = Singleton.get(STOCK_DECREMENT_AND_BATCH_SAVE_USER_RECORD_LUA_PATH, () -> {
DefaultRedisScript<Long> redisScript = new DefaultRedisScript<>();
redisScript.setScriptSource(new ResourceScriptSource(new ClassPathResource(STOCK_DECREMENT_AND_BATCH_SAVE_USER_RECORD_LUA_PATH)));
redisScript.setResultType(Long.class);
return redisScript;
});
// 执行 LUA 脚本进行扣减库存以及增加 Redis 用户领券记录
String couponTemplateKey = String.format(EngineRedisConstant.COUPON_TEMPLATE_KEY, couponTemplateD0.getId());
String batchUserSetKey = String.format(EngineRedisConstant.TEMPLATE_TASK_EXECUTE_BATCH_USER_KEY, couponTaskId);
Map<Object, Object> userRowNumMap = MapUtil.builder()
.put("userId", data.getUserId())
.put("rowNum", v -> rowNumCount + 1)
.build();
Long combinedFiled = stringRedisTemplate.execute(buildLuaScript, ListUtil.of(couponTemplateKey, batchUserSetKey), JSON.toJSONString(userRowNumMap));
// firstField 为 false 说明优惠券已经没有库存了
boolean firstField = StockDecrementReturnUtil.extractFirstField(combinedFiled);我们可以看一下:这里一般我建议,如果说涉及到多次它对应的 Redis 操作,我们尽量能用 Redis 脚本就去做。这个建议是:大家再去一些比较核心、或者说一些 ToC(面向用户)、变化频率比较高的系统里面,我建议大家这么做。因为这样的话会节省一次网络的 IO。
对,可能不止一次——看你 Redis 脚本里面会执行多少逻辑。
然后我们可以看一下这一块是我们 build 的一个 Redis 脚本。我们的 Keys 第一个的话,就是我们优惠券模板的 Key;第二个的话,就是我们构建的缓冲队列的一个 Key。然后我们对应的参数这一块,我们去把它当前的用户 ID 以及它所在的行数传进去。
大家可能会纠结:我第一个消息为什么 rowNumber 会是 2?因为我们在 Excel 里面的第一行是标题行,但是我们的用户的第一行记录其实在 Excel 里面它的行数是 2。所以说我们给它在执行的时候先加了一个 1。
因为代码逻辑整体比较耦合,所以我们将整体代码奉上,并在接下来的小节中逐个解析其中的核心业务逻辑和优化。其中优化逻辑主要涉及两个完整类:ReadExcelDistributionListener 和 CouponExecuteDistributionConsumer。
其中一些细节处使用了较多小技巧,看下文细细道来。
1. ReadExcelDistributionListener
@RequiredArgsConstructor
public class ReadExcelDistributionListener extends AnalysisEventListener<CouponTaskExcelObject> {
private final CouponTaskDO couponTaskDO;
private final CouponTemplateDO couponTemplateDO;
private final CouponTaskFailMapper couponTaskFailMapper;
private final StringRedisTemplate stringRedisTemplate;
private final CouponExecuteDistributionProducer couponExecuteDistributionProducer;
private int rowCount = 1;
private final static String STOCK_DECREMENT_AND_BATCH_SAVE_USER_RECORD_LUA_PATH = "lua/stock_decrement_and_batch_save_user_record.lua";
private final static int BATCH_USER_COUPON_SIZE = 5000;
@Override
public void invoke(CouponTaskExcelObject data, AnalysisContext context) {
Long couponTaskId = couponTaskDO.getId();
// 获取当前进度,判断是否已经执行过。如果已执行,则跳过即可,防止执行到一半应用宕机
String templateTaskExecuteProgressKey = String.format(DistributionRedisConstant.TEMPLATE_TASK_EXECUTE_PROGRESS_KEY, couponTaskId);
String progress = stringRedisTemplate.opsForValue().get(templateTaskExecuteProgressKey);
if (StrUtil.isNotBlank(progress) && Integer.parseInt(progress) >= rowCount) {
++rowCount;
return;
}
// 获取 LUA 脚本,并保存到 Hutool 的单例管理容器,下次直接获取不需要加载
DefaultRedisScript<Long> buildLuaScript = Singleton.get(STOCK_DECREMENT_AND_BATCH_SAVE_USER_RECORD_LUA_PATH, () -> {
DefaultRedisScript<Long> redisScript = new DefaultRedisScript<>();
redisScript.setScriptSource(new ResourceScriptSource(new ClassPathResource(STOCK_DECREMENT_AND_BATCH_SAVE_USER_RECORD_LUA_PATH)));
redisScript.setResultType(Long.class);
return redisScript;
});
// 执行 LUA 脚本进行扣减库存以及增加 Redis 用户领券记录
String couponTemplateKey = String.format(EngineRedisConstant.COUPON_TEMPLATE_KEY, couponTemplateDO.getId());
String batchUserSetKey = String.format(DistributionRedisConstant.TEMPLATE_TASK_EXECUTE_BATCH_USER_KEY, couponTaskId);
Map<Object, Object> userRowNumMap = MapUtil.builder()
.put("userId", data.getUserId())
.put("rowNum", rowCount + 1)
.build();
Long combinedFiled = stringRedisTemplate.execute(buildLuaScript, ListUtil.of(couponTemplateKey, batchUserSetKey), JSON.toJSONString(userRowNumMap));
// firstField 为 false 说明优惠券已经没有库存了
boolean firstField = StockDecrementReturnCombinedUtil.extractFirstField(combinedFiled);
if (!firstField) {
// 同步当前执行进度到缓存
stringRedisTemplate.opsForValue().set(templateTaskExecuteProgressKey, String.valueOf(rowCount));
++rowCount;
// 添加到 t_coupon_task_fail 并标记错误原因,方便后续查看未成功发送的原因和记录
Map<Object, Object> objectMap = MapUtil.builder()
.put("rowNum", rowCount + 1)
.put("cause", "优惠券模板无库存")
.build();
CouponTaskFailDO couponTaskFailDO = CouponTaskFailDO.builder()
.batchId(couponTaskDO.getBatchId())
.jsonObject(JSON.toJSONString(objectMap, SerializerFeature.WriteMapNullValue))
.build();
couponTaskFailMapper.insert(couponTaskFailDO);
return;
}
// 获取用户领券集合长度
int batchUserSetSize = StockDecrementReturnCombinedUtil.extractSecondField(combinedFiled.intValue());
// batchUserSetSize = BATCH_USER_COUPON_SIZE 时发送消息消费,不满足条件仅记录执行进度即可
if (batchUserSetSize < BATCH_USER_COUPON_SIZE) {
// 同步当前 Excel 执行进度到缓存
stringRedisTemplate.opsForValue().set(templateTaskExecuteProgressKey, String.valueOf(rowCount));
++rowCount;
return;
}
CouponTemplateDistributionEvent couponTemplateDistributionEvent = CouponTemplateDistributionEvent.builder()
.couponTaskId(couponTaskId)
.shopNumber(couponTaskDO.getShopNumber())
.couponTemplateId(couponTemplateDO.getId())
.couponTaskBatchId(couponTaskDO.getBatchId())
.couponTemplateConsumeRule(couponTemplateDO.getConsumeRule())
.batchUserSetSize(batchUserSetSize)
.distributionEndFlag(Boolean.FALSE)
.build();
couponExecuteDistributionProducer.sendMessage(couponTemplateDistributionEvent);
// 同步当前执行进度到缓存
stringRedisTemplate.opsForValue().set(templateTaskExecuteProgressKey, String.valueOf(rowCount));
++rowCount;
}
@Override
public void doAfterAllAnalysed(AnalysisContext context) {
// 发送 Excel 解析完成标识,即使不满足批量保存的数量也得保存到数据库
CouponTemplateDistributionEvent couponTemplateExecuteEvent = CouponTemplateDistributionEvent.builder()
.distributionEndFlag(Boolean.TRUE) // 设置解析完成标识
.shopNumber(couponTaskDO.getShopNumber())
.couponTemplateId(couponTemplateDO.getId())
.couponTemplateConsumeRule(couponTemplateDO.getConsumeRule())
.couponTaskBatchId(couponTaskDO.getBatchId())
.couponTaskId(couponTaskDO.getId())
.build();
couponExecuteDistributionProducer.sendMessage(couponTemplateExecuteEvent);
}
}2. CouponExecuteDistributionConsumer
@Component
@RequiredArgsConstructor
@RocketMQMessageListener(
topic = "one-coupon_distribution-service_coupon-execute-distribution_topic${unique-name:}",
consumerGroup = "one-coupon_distribution-service_coupon-execute-distribution_cg${unique-name:}"
)
@Slf4j(topic = "CouponExecuteDistributionConsumer")
public class CouponExecuteDistributionConsumer implements RocketMQListener<MessageWrapper<CouponTemplateDistributionEvent>> {
private final UserCouponMapper userCouponMapper;
private final CouponTemplateMapper couponTemplateMapper;
private final CouponTaskMapper couponTaskMapper;
private final CouponTaskFailMapper couponTaskFailMapper;
private final StringRedisTemplate stringRedisTemplate;
@Lazy
@Autowired
private CouponExecuteDistributionConsumer couponExecuteDistributionConsumer;
private final static int BATCH_USER_COUPON_SIZE = 5000;
private static final String BATCH_SAVE_USER_COUPON_LUA_PATH = "lua/batch_user_coupon_list.lua";
@Transactional(rollbackFor = Exception.class)
@Override
public void onMessage(MessageWrapper<CouponTemplateDistributionEvent> messageWrapper) {
// 开头打印日志,平常可 Debug 看任务参数,线上可报平安(比如消息是否消费,重新投递时获取参数等)
log.info("[消费者] 优惠券任务执行推送@分发到用户账号 - 执行消费逻辑,消息体:{}", JSON.toJSONString(messageWrapper));
// 当保存用户优惠券集合达到批量保存数量
CouponTemplateDistributionEvent event = messageWrapper.getMessage();
if (!event.getDistributionEndFlag() && event.getBatchUserSetSize() % BATCH_USER_COUPON_SIZE == 0) {
decrementCouponTemplateStockAndSaveUserCouponList(event);
return;
}
// 分发任务结束标识为 TRUE,代表已经没有 Excel 记录了
if (event.getDistributionEndFlag()) {
String batchUserSetKey = String.format(DistributionRedisConstant.TEMPLATE_TASK_EXECUTE_BATCH_USER_KEY, event.getCouponTaskId());
Long batchUserIdsSize = stringRedisTemplate.opsForSet().size(batchUserSetKey);
event.setBatchUserSetSize(batchUserIdsSize.intValue());
decrementCouponTemplateStockAndSaveUserCouponList(event);
List<String> batchUserMaps = stringRedisTemplate.opsForSet().pop(batchUserSetKey, Integer.MAX_VALUE);
// 此时待保存入库用户优惠券列表如果还有值,就意味着可能库存不足引起的
if (CollUtil.isNotEmpty(batchUserMaps)) {
// 添加到 t_coupon_task_fail 并标记错误原因,方便后续查看未成功发送的原因和记录
List<CouponTaskFailDO> couponTaskFailDOList = new ArrayList<>(batchUserMaps.size());
for (String batchUserMapStr : batchUserMaps) {
Map<Object, Object> objectMap = MapUtil.builder()
.put("rowNum", JSON.parseObject(batchUserMapStr).get("rowNum"))
.put("cause", "优惠券模板库存不足")
.build();
CouponTaskFailDO couponTaskFailDO = CouponTaskFailDO.builder()
.batchId(event.getCouponTaskBatchId())
.jsonObject(com.alibaba.fastjson.JSON.toJSONString(objectMap))
.build();
couponTaskFailDOList.add(couponTaskFailDO);
}
// 添加到 t_coupon_task_fail 并标记错误原因
couponTaskFailMapper.insert(couponTaskFailDOList);
}
// 确保所有用户都已经接到优惠券后,设置优惠券推送任务完成时间
CouponTaskDO couponTaskDO = CouponTaskDO.builder()
.id(event.getCouponTaskId())
.status(CouponTaskStatusEnum.SUCCESS.getStatus())
.completionTime(new Date())
.build();
couponTaskMapper.updateById(couponTaskDO);
}
}
@SneakyThrows
private void decrementCouponTemplateStockAndSaveUserCouponList(CouponTemplateDistributionEvent event) {
// 如果等于 0 意味着已经没有了库存,直接返回即可
Integer couponTemplateStock = decrementCouponTemplateStock(event, event.getBatchUserSetSize());
if (couponTemplateStock <= 0) {
return;
}
// 获取 Redis 中待保存入库用户优惠券列表
String batchUserSetKey = String.format(DistributionRedisConstant.TEMPLATE_TASK_EXECUTE_BATCH_USER_KEY, event.getCouponTaskId());
List<String> batchUserMaps = stringRedisTemplate.opsForSet().pop(batchUserSetKey, couponTemplateStock);
// 因为 batchUserIds 数据较多,ArrayList 会进行数次扩容,为了避免额外性能消耗,直接初始化 batchUserIds 大小的数组
List<UserCouponDO> userCouponDOList = new ArrayList<>(batchUserMaps.size());
Date now = new Date();
// 构建 userCouponDOList 用户优惠券批量数组
for (String each : batchUserMaps) {
JSONObject userIdAndRowNumJsonObject = JSON.parseObject(each);
DateTime validEndTime = DateUtil.offsetHour(now, JSON.parseObject(event.getCouponTemplateConsumeRule()).getInteger("validityPeriod"));
UserCouponDO userCouponDO = UserCouponDO.builder()
.id(IdUtil.getSnowflakeNextId())
.couponTemplateId(event.getCouponTemplateId())
.rowNum(userIdAndRowNumJsonObject.getInteger("rowNum"))
.userId(userIdAndRowNumJsonObject.getLong("userId"))
.receiveTime(now)
.receiveCount(1) // 代表第一次领取该优惠券
.validStartTime(now)
.validEndTime(validEndTime)
.source(CouponSourceEnum.PLATFORM.getType())
.status(CouponStatusEnum.EFFECTIVE.getType())
.createTime(new Date())
.updateTime(new Date())
.delFlag(0)
.build();
userCouponDOList.add(userCouponDO);
}
// 平台优惠券每个用户限领一次。批量新增用户优惠券记录,底层通过递归方式直到全部新增成功
batchSaveUserCouponList(event.getCouponTemplateId(), event.getCouponTaskBatchId(), userCouponDOList);
// 将这些优惠券添加到用户的领券记录中
List<String> userIdList = userCouponDOList.stream()
.map(UserCouponDO::getUserId)
.map(String::valueOf)
.toList();
String userIdsJson = new ObjectMapper().writeValueAsString(userIdList);
List<String> couponIdList = userCouponDOList.stream()
.map(each -> StrUtil.builder()
.append(event.getCouponTemplateId())
.append("_")
.append(each.getId())
.toString())
.map(String::valueOf)
.toList();
String couponIdsJson = new ObjectMapper().writeValueAsString(couponIdList);
// 调用 Lua 脚本时,传递参数
List<String> keys = Arrays.asList(
// 为什么要进行替换 %s 为空白字符串?因为后续代码需要使用 %s 进行动态值替换,但是当前 LUA 脚本中不需要,所以为了兼容后续不改动特此替换
StrUtil.replace(EngineRedisConstant.USER_COUPON_TEMPLATE_LIST_KEY, "%s", ""),
USER_COUPON_TEMPLATE_LIMIT_KEY,
String.valueOf(event.getCouponTemplateId())
);
List<String> args = Arrays.asList(
userIdsJson,
couponIdsJson,
String.valueOf(new Date().getTime()),
String.valueOf(event.getValidEndTime().getTime())
);
// 获取 LUA 脚本,并保存到 Hutool 的单例管理容器,下次直接获取不需要加载
DefaultRedisScript<Void> buildLuaScript = Singleton.get(BATCH_SAVE_USER_COUPON_LUA_PATH, () -> {
DefaultRedisScript<Void> redisScript = new DefaultRedisScript<>();
redisScript.setScriptSource(new ResourceScriptSource(new ClassPathResource(BATCH_SAVE_USER_COUPON_LUA_PATH)));
redisScript.setResultType(Void.class);
return redisScript;
});
stringRedisTemplate.execute(buildLuaScript, keys, args.toArray());
// 增加库存回滚方案,如果用户已经领取优惠券被校验,需要将 Redis 预扣减库存回滚
int originalUserCouponSize = batchUserMaps.size();
// 如果用户已领取被校验会从集合中删除
int availableUserCouponSize = userCouponDOList.size();
int rollbackStock = originalUserCouponSize - availableUserCouponSize;
if (rollbackStock > 0) {
// 回滚优惠券模板缓存库存数量
stringRedisTemplate.opsForHash().increment(
String.format(EngineRedisConstant.COUPON_TEMPLATE_KEY, event.getCouponTemplateId()),
"stock",
rollbackStock
);
// 回滚优惠券模板数据库库存数量
couponTemplateMapper.incrementCouponTemplateStock(event.getShopNumber(), event.getCouponTemplateId(), rollbackStock);
}
}
private Integer decrementCouponTemplateStock(CouponTemplateDistributionEvent event, Integer decrementStockSize) {
Long couponTemplateId = event.getCouponTemplateId();
int decremented = couponTemplateMapper.decrementCouponTemplateStock(event.getShopNumber(), couponTemplateId, decrementStockSize);
// 如果修改记录失败,意味着优惠券库存已不足,需要重试获取到可自减的库存数值
if (!SqlHelper.retBool(decremented)) {
LambdaQueryWrapper<CouponTemplateDO> queryWrapper = Wrappers.lambdaQuery(CouponTemplateDO.class)
.eq(CouponTemplateDO::getShopNumber, event.getShopNumber())
.eq(CouponTemplateDO::getId, couponTemplateId);
CouponTemplateDO couponTemplateDO = couponTemplateMapper.selectOne(queryWrapper);
return decrementCouponTemplateStock(event, couponTemplateDO.getStock());
}
return decrementStockSize;
}
private void batchSaveUserCouponList(Long couponTemplateId, Long couponTaskBatchId, List<UserCouponDO> userCouponDOList) {
// MyBatis-Plus 批量执行用户优惠券记录
try {
userCouponMapper.insert(userCouponDOList, userCouponDOList.size());
} catch (Exception ex) {
Throwable cause = ex.getCause();
if (cause instanceof BatchExecutorException) {
// 添加到 t_coupon_task_fail 并标记错误原因,方便后续查看未成功发送的原因和记录
List<CouponTaskFailDO> couponTaskFailDOList = new ArrayList<>();
List<UserCouponDO> toRemove = new ArrayList<>();
// 调用批量新增失败后,为了避免大量重复失败,我们通过新增单条记录方式执行
userCouponDOList.forEach(each -> {
try {
userCouponMapper.insert(each);
} catch (Exception ignored) {
Boolean hasReceived = couponExecuteDistributionConsumer.hasUserReceivedCoupon(couponTemplateId, each.getUserId());
if (hasReceived) {
// 添加到 t_coupon_task_fail 并标记错误原因,方便后续查看未成功发送的原因和记录
Map<Object, Object> objectMap = MapUtil.builder()
.put("rowNum", each.getRowNum())
.put("cause", "用户已领取该优惠券")
.build();
CouponTaskFailDO couponTaskFailDO = CouponTaskFailDO.builder()
.batchId(couponTaskBatchId)
.jsonObject(com.alibaba.fastjson.JSON.toJSONString(objectMap))
.build();
couponTaskFailDOList.add(couponTaskFailDO);
// 从 userCouponDOList 中删除已经存在的记录
toRemove.add(each);
}
}
});
// 批量新增 t_coupon_task_fail 表
couponTaskFailMapper.insert(couponTaskFailDOList, couponTaskFailDOList.size());
// 删除已经重复的内容
userCouponDOList.removeAll(toRemove);
return;
}
throw ex;
}
}
/**
* 查询用户是否已经领取过优惠券
*
* @param couponTemplateId 优惠券模板 ID
* @param userId 用户 ID
* @return 用户优惠券模板领取信息是否已存在
*/
@Transactional(propagation = Propagation.NOT_SUPPORTED)
public Boolean hasUserReceivedCoupon(Long couponTemplateId, Long userId) {
LambdaQueryWrapper<UserCouponDO> queryWrapper = Wrappers.lambdaQuery(UserCouponDO.class)
.eq(UserCouponDO::getUserId, userId)
.eq(UserCouponDO::getCouponTemplateId, couponTemplateId);
return userCouponMapper.selectOne(queryWrapper) != null;
}
}
记录分发点位
在消费者读取 Excel 执行到最后一条记录时,如果发生宕机,消息队列在重试时需要重新执行整个任务,这显然会造成时间和资源的浪费。为了优化这一点,我们在每次成功分发记录后,会将进度保存到缓存中。
// 获取当前进度,判断是否已经执行过。如果已执行,则跳过即可,防止执行到一半应用宕机
String templateTaskExecuteProgressKey = String.format(DistributionRedisConstant.TEMPLATE_TASK_EXECUTE_PROGRESS_KEY, couponTaskId);
String progress = stringRedisTemplate.opsForValue().get(templateTaskExecuteProgressKey);
if (StrUtil.isNotBlank(progress) && Integer.parseInt(progress) >= rowCount) {
++rowCount;
return;
}
// .....
// 记录执行后,同步当前执行进度到缓存
stringRedisTemplate.opsForValue().set(templateTaskExecuteProgressKey, String.valueOf(rowCount));
++rowCount;这样,即使应用宕机或重启,我们的任务进度依然可以判断是否已经执行过,执行过仅执行自增内存中的读取进度即可。
重构消息队列执行
如上所述,如果消息消费时间过长,可能会导致意外问题,例如 Broker 可能会认为消息消费超时并重新投递。为了解决这一问题,我们将消费者拆分为两个部分:一个负责解析优惠券分发任务的 Excel 模板,另一个负责实际的优惠券任务分发。
- CouponTaskExecuteConsumer:在执行优惠券分发时,我们同时进行 Excel 模板解析和前置校验,包括数据格式的正确性检查以及当前优惠券模板的库存情况。
- CouponExecuteDistributionConsumer:将优惠券分发到用户账户,包括数据库和缓存等多个存储介质。
通过这种拆分机制,我们可以最大程度地缩短单个消息队列消费者的执行时间。
批量保存用户优惠券
之前处理大约 5000 条 Excel 分发记录需要约 1 分钟。如果需要处理 100 万条记录,预计耗时将达到 200 分钟,这显然是不可接受的。我们分析发现,大量的 Redis 和 MySQL 操作需要频繁的网络 I/O,而网络操作相比于 CPU 内部处理要慢得多。因此,我们需要将所有涉及网络 I/O 的操作改为批量处理。
批量处理分为两个步骤:批量保存到数据库和批量保存到缓存。
1. 批量保存用户分发记录
在执行分发之前,我们需要首先验证优惠券模板的库存是否充足。如果库存不足,则无法执行分发。正如之前提到的,我们需要将涉及网络 I/O 的请求进行批量处理。同时,我们将消息发送任务拆分给了两个消费者,其中实际的发送操作在 CouponExecuteDistributionConsumer 中完成。这就带来了一个问题:如果不满足批量发送条件,数据应该暂存在哪里?对此,我们选择将数据暂存到 Redis 的 Set 缓存中,待满足批量条件时再从 Redis Set 中提取并执行批量保存。
ReadExcelDistributionListener#invoke 核心逻辑如下:
// 执行 LUA 脚本进行扣减库存以及增加 Redis 用户领券记录
String couponTemplateKey = String.format(EngineRedisConstant.COUPON_TEMPLATE_KEY, couponTemplateDO.getId());
String batchUserSetKey = String.format(DistributionRedisConstant.TEMPLATE_TASK_EXECUTE_BATCH_USER_KEY, couponTaskId);
Map<Object, Object> userRowNumMap = MapUtil.builder()
.put("userId", data.getUserId())
.put("rowNum", rowCount + 1)
.build();
Long combinedFiled = stringRedisTemplate.execute(buildLuaScript, ListUtil.of(couponTemplateKey, batchUserSetKey), JSON.toJSONString(userRowNumMap));
// firstField 为 false 说明优惠券已经没有库存了
boolean firstField = StockDecrementReturnCombinedUtil.extractFirstField(combinedFiled);
if (!firstField) {
// 同步当前执行进度到缓存
stringRedisTemplate.opsForValue().set(templateTaskExecuteProgressKey, String.valueOf(rowCount));
++rowCount;
// 添加到 t_coupon_task_fail 并标记错误原因,方便后续查看未成功发送的原因和记录
Map<Object, Object> objectMap = MapUtil.builder()
.put("rowNum", rowCount)
.put("cause", "优惠券模板无库存")
.build();
CouponTaskFailDO couponTaskFailDO = CouponTaskFailDO.builder()
.batchId(couponTaskDO.getBatchId())
.jsonObject(JSON.toJSONString(objectMap, SerializerFeature.WriteMapNullValue))
.build();
couponTaskFailMapper.insert(couponTaskFailDO);
return;
}
// 获取用户领券集合长度
int batchUserSetSize = StockDecrementReturnCombinedUtil.extractSecondField(combinedFiled.intValue());可能很多同学不清楚,为什么要把 Lua 返回脚本中的字段通过工具类拆分为两个值,先看看下文的解释。
首先编写一个 Lua 脚本,用于验证优惠券模板库存是否充足。如果库存充足,则将数据保存到 Redis 的 Set 结构中。
-- 定义最大值和位数
local SECOND_FIELD_BITS = 13
-- 将两个字段组合成一个int
local function combineFields(firstField, secondField)
local firstFieldValue = firstField and 1 or 0
return (firstFieldValue * 2 ^ SECOND_FIELD_BITS) + secondField
end
-- Lua脚本开始
local key = KEYS[1] -- Redis Key
local userSetKey = KEYS[2] -- 用户领券 Set 的 Key
local userIdAndRowNum = ARGV[1] -- 用户 ID 和 Excel 所在行数
-- 获取库存
local stock = tonumber(redis.call('HGET', key, 'stock'))
-- 检查库存是否大于0
if stock == nil or stock <= 0 then
return combineFields(false, redis.call('SCARD', userSetKey))
end
-- 自减库存
redis.call('HINCRBY', key, 'stock', -1)
-- 添加用户到领券集合
redis.call('SADD', userSetKey, userIdAndRowNum)
-- 获取用户领券集合的长度
local userSetLength = redis.call('SCARD', userSetKey)
-- 返回结果
return combineFields(true, userSetLength)大家看到这个可能有点蒙圈,简单解释下。这个 LUA 脚本主要做两件事情:
- 1. 判断库存是否大于 0,如果大于的话,自减库存。如果库存为空或小于等于 0 则返回失败;
- 2. 扣减库存成功后,我们需要将用户领券记录保存到 Redis Set 结构中,方便后面批量进行分发保存数据库。
这个 Lua 脚本的命令虽然简单,但通过位移操作巧妙提升了返回数据的性能 。通常情况下,我们需要返回两个数据:库存是否充足,以及用户领券 Set 的长度(当达到指定长度时开始执行批量分发)。如果按照常规方式返回,比如返回 false,0-5000,就需要在 Java 服务中进行字符串分割。相比之下,使用二进制位移操作可以大幅提升性能。
首先,库存如果说小于等于0的话,那就证明我们的库存不够了,我们要返回一个失败,以及我们当前缓冲队列里面它已经有了多少行数——接下来的业务当中会用到这个数据。这里先忽略掉。
然后如果说它的库存是充足的,那么我们会自减它的库存,然后将它的用户信息给它添到我们对应的领券集合里面去。其实我们就是用了一个 Set 的数据结构去保存了记录。同时,我们也要返回用户领券集合的一个长度。
这个长度是用来做什么的?这个就是用来刚才我们讲的“批次”的概念。如果说它达到了一个我们批次的要求,就要给它进行一次处理,对吧?
然后这里返回结果的时候,大家可以看到它会去调这个函数。这个函数其实就是一个作用:那就是它会把两个字段组合成一个 int 去进行返回。然后我们在业务里面通过位运算的形式,把这个 int 再解析成两个字段。
大家一听这个逻辑操作可能会有点懵:为什么会这么去写?
因为如果说我们不对它进行这种位运算的组合,那么我们是不是需要类似于这种结构?第一个是“是否库存扣减成功”的字段。如果说我们不进行位运算拼接,我们一定是返回两个值,对不对?这样的话,你是不是到了业务代码里面,需要去进行一个分割?
在这里跟大家讲一下:分割的性能是远不如位运算的。好吧?所以说这里面是一个“花活”。大家能够在代码里面看到一些核心代码这么写,不建议大家在普通业务里去用,避免有“秀”的嫌疑。但你要知道:这样的操作在一些核心代码里面可以这样写,帮助大家去扩展一下思维。
另外,如果细心的小伙伴,包括看过一些线程池源码的小伙伴,可能就有想法了——对吧?线程池的状态其实也是这么去做的,也是通过一个字段表示了它的多个属性。
返回的时候,可以看到它会返回一个数值。然后通过数值,我们封装了一个工具类,帮助这个数值去进行一个解析。可以看到它返回了一个 8193,这个数据对咱来说没有任何意义,或者说没有任何可读性。所以我们需要通过工具类的形式去解析。就是下面
数据返回后,我们通过自定义的一个工具类,解析返回数据。
public class StockDecrementReturnCombinedUtil {
/**
* 2^13 > 5000, 所以用 13 位来表示第二个字段
*/
private static final int SECOND_FIELD_BITS = 13;
/**
* 将两个字段组合成一个int
*/
public static int combineFields(boolean decrementFlag, int userRecord) {
return (decrementFlag ? 1 : 0) << SECOND_FIELD_BITS | userRecord;
}
/**
* 从组合的int中提取第一个字段(0或1)
*/
public static boolean extractFirstField(long combined) {
return (combined >> SECOND_FIELD_BITS) != 0;
}
/**
* 从组合的int中提取第二个字段(1到5000之间的数字)
*/
public static int extractSecondField(int combined) {
return combined & ((1 << SECOND_FIELD_BITS) - 1);
}
}经过这个工具类,就可以实现我们上面的一个字段完成两个值的存储。另外,我们通过一个单元测试能够很直观的看到两种方式的性能差距,如下:
@Slf4j
public final class StockDecrementReturnCombinedUtilTests {
@Test
public void stockDecrementReturnCombinedUtilTest() {
boolean firstField = true;
int secondField = 5000;
int combined = StockDecrementReturnCombinedUtil.combineFields(firstField, secondField);
long startTime = System.currentTimeMillis();
for (int i = 0; i < 100000; i++) {
StockDecrementReturnCombinedUtil.extractFirstField(combined);
StockDecrementReturnCombinedUtil.extractSecondField(combined);
}
long endTime = System.currentTimeMillis();
long startTime2 = System.currentTimeMillis();
String str = "1,1234";
for (int i = 0; i < 100000; i++) {
StrUtil.split(str, ",");
}
long endTime2 = System.currentTimeMillis();
log.info("位移程序执行时间:{}", endTime - startTime);
log.info("split程序执行时间:{}", endTime2 - startTime2);
/**
* 位移程序执行时间:2
* split程序执行时间:40
*/
}
}运行 10 万次时,性能差距通常会非常明显,可能达到 20 倍左右。然而,这种优化在我们的应用系统中实际意义不大,只是让大家了解这种方法的存在。毕竟在执行时间上,1 毫秒与 2 毫秒的差距很难察觉。这种优化思路来源于线程池的 ctl 字段,其核心思想与我们这里的一致,即通过位移操作让一个字段表示多种用途。
public class ThreadPoolExecutor extends AbstractExecutorService {
// ......
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
// ......
}在这里的话,我们是需要第一个字段:我们的优惠券是否还有库存。
我们第一个字段怎么解析?首先通过位运算,我们可以看到这个方法,它的作用其实就是从我们的 int 里面去提取出来第一个字段(0 或 1),是通过位移运算的形式提出来的。提出来之后,我们就可以知道它是一个 true 或 false。
如果说它等于 false,就证明我们优惠券里面已经没有库存了。这个时候我们会执行两个逻辑:
- 第一步,把我们当前的一个进度放到缓存里面去;
- 然后,我们去把它对应的一个行数以及对应的一个失败原因,新增到我们刚才讲到的任务失败的记录表里面。
到这里就结束了。然后我们可以看到,其实现在肯定是有记录的,对不对?
第二个字段的话,就是我们的优惠券缓冲队列的一个长度——是 1~5000 之间的一个数字。
可能有同学会纠结:“马哥,我第二个长度的话是多大比较合适?”
我们在这里用的是 2 的 13 次幂(8192),对吧?代表的是 8192,肯定是大于 5000 的。我们留这个长度让它来解析,然后我们给它解析出来之后,就能够获取到它第二个数据。
第二个数据我们可以看一下,在这里的话是 1,对不对?因为我们刚执行第一次。如果它是一的话,可以看到它是不满足我们的批次的(一个批次是 5000)。如果不满足的话,和刚才的逻辑一样,我们给他统计一下它对应的进度就 OK 了,然后我们把对应的逻辑加到这里。
2. 达到条件执行消息队列分发消费者
我们设定每读取 5000 条记录后执行一次批量操作,如果不足 5000 条,则只同步当前的 Excel 读取进度。当读取进度达到 5000 条时,将发送消息队列通知具体的优惠券分发消费者进行处理。
private final static int BATCH_USER_COUPON_SIZE = 5000;
// 获取用户领券集合长度
int batchUserSetSize = StockDecrementReturnCombinedUtil.extractSecondField(combinedFiled.intValue());
// batchUserSetSize = BATCH_USER_COUPON_SIZE 时发送消息消费,不满足条件仅记录执行进度即可
if (batchUserSetSize < BATCH_USER_COUPON_SIZE) {
// 同步当前 Excel 执行进度到缓存
stringRedisTemplate.opsForValue().set(templateTaskExecuteProgressKey, String.valueOf(rowCount));
++rowCount;
return;
}
CouponTemplateDistributionEvent couponTemplateDistributionEvent = CouponTemplateDistributionEvent.builder()
.couponTaskId(couponTaskId)
.shopNumber(couponTaskDO.getShopNumber())
.couponTemplateId(couponTemplateDO.getId())
.couponTaskBatchId(couponTaskDO.getBatchId())
.couponTemplateConsumeRule(couponTemplateDO.getConsumeRule())
.batchUserSetSize(batchUserSetSize)
.distributionEndFlag(Boolean.FALSE)
.build();
couponExecuteDistributionProducer.sendMessage(couponTemplateDistributionEvent);3. 新增用户领券数据库
执行分发逻辑消息队列消费者时,会有两个业务类型,分别是满足批量处理数量 5000 的消息,以及 Excel 读取到最后可能没满足 5000 批量也需要发送消息队列。
批量达到 5000 条执行的消息队列如上所述,然后给大家看下 EasyExcel 读取完 Excel 后执行的后置逻辑:
@RequiredArgsConstructor
public class ReadExcelDistributionListener extends AnalysisEventListener<CouponTaskExcelObject> {
// ......
@Override
public void doAfterAllAnalysed(AnalysisContext context) {
// 发送 Excel 解析完成标识,即使不满足批量保存的数量也得保存到数据库
CouponTemplateDistributionEvent couponTemplateExecuteEvent = CouponTemplateDistributionEvent.builder()
.distributionEndFlag(Boolean.TRUE) // 设置解析完成标识
.shopNumber(couponTaskDO.getShopNumber())
.couponTemplateId(couponTemplateDO.getId())
.validEndTime(couponTemplateDO.getValidEndTime())
.couponTemplateConsumeRule(couponTemplateDO.getConsumeRule())
.couponTaskBatchId(couponTaskDO.getBatchId())
.couponTaskId(couponTaskDO.getId())
.build();
couponExecuteDistributionProducer.sendMessage(couponTemplateExecuteEvent);
}
}我们先说其中的执行批处理消息,代码如下:
@Component
@RequiredArgsConstructor
@RocketMQMessageListener(
topic = "one-coupon_distribution-service_coupon-execute-distribution_topic${unique-name:}",
consumerGroup = "one-coupon_distribution-service_coupon-execute-distribution_cg${unique-name:}"
)
@Slf4j(topic = "CouponExecuteDistributionConsumer")
public class CouponExecuteDistributionConsumer implements RocketMQListener<MessageWrapper<CouponTemplateDistributionEvent>> {
private final UserCouponMapper userCouponMapper;
private final CouponTemplateMapper couponTemplateMapper;
private final CouponTaskMapper couponTaskMapper;
private final CouponTaskFailMapper couponTaskFailMapper;
private final StringRedisTemplate stringRedisTemplate;
@Lazy
@Autowired
private CouponExecuteDistributionConsumer couponExecuteDistributionConsumer;
private final static int BATCH_USER_COUPON_SIZE = 5000;
private static final String BATCH_SAVE_USER_COUPON_LUA_PATH = "lua/batch_user_coupon_list.lua";
@Transactional(rollbackFor = Exception.class)
@Override
public void onMessage(MessageWrapper<CouponTemplateDistributionEvent> messageWrapper) {
// 开头打印日志,平常可 Debug 看任务参数,线上可报平安(比如消息是否消费,重新投递时获取参数等)
log.info("[消费者] 优惠券任务执行推送@分发到用户账号 - 执行消费逻辑,消息体:{}", JSON.toJSONString(messageWrapper));
// 当保存用户优惠券集合达到批量保存数量
CouponTemplateDistributionEvent event = messageWrapper.getMessage();
if (!event.getDistributionEndFlag() && event.getBatchUserSetSize() % BATCH_USER_COUPON_SIZE == 0) {
decrementCouponTemplateStockAndSaveUserCouponList(event);
return;
}
// ......
}
@SneakyThrows
private void decrementCouponTemplateStockAndSaveUserCouponList(CouponTemplateDistributionEvent event) {
// 如果等于 0 意味着已经没有了库存,直接返回即可
Integer couponTemplateStock = decrementCouponTemplateStock(event, event.getBatchUserSetSize());
if (couponTemplateStock <= 0) {
return;
}
// 获取 Redis 中待保存入库用户优惠券列表
String batchUserSetKey = String.format(DistributionRedisConstant.TEMPLATE_TASK_EXECUTE_BATCH_USER_KEY, event.getCouponTaskId());
List<String> batchUserMaps = stringRedisTemplate.opsForSet().pop(batchUserSetKey, couponTemplateStock);
// 因为 batchUserIds 数据较多,ArrayList 会进行数次扩容,为了避免额外性能消耗,直接初始化 batchUserIds 大小的数组
List<UserCouponDO> userCouponDOList = new ArrayList<>(batchUserMaps.size());
Date now = new Date();
// 构建 userCouponDOList 用户优惠券批量数组
for (String each : batchUserMaps) {
JSONObject userIdAndRowNumJsonObject = JSON.parseObject(each);
DateTime validEndTime = DateUtil.offsetHour(now, JSON.parseObject(event.getCouponTemplateConsumeRule()).getInteger("validityPeriod"));
UserCouponDO userCouponDO = UserCouponDO.builder()
.id(IdUtil.getSnowflakeNextId())
.couponTemplateId(event.getCouponTemplateId())
.rowNum(userIdAndRowNumJsonObject.getInteger("rowNum"))
.userId(userIdAndRowNumJsonObject.getLong("userId"))
.receiveTime(now)
.receiveCount(1) // 代表第一次领取该优惠券
.validStartTime(now)
.validEndTime(validEndTime)
.source(CouponSourceEnum.PLATFORM.getType())
.status(CouponStatusEnum.EFFECTIVE.getType())
.createTime(new Date())
.updateTime(new Date())
.delFlag(0)
.build();
userCouponDOList.add(userCouponDO);
}
// 平台优惠券每个用户限领一次。批量新增用户优惠券记录,底层通过递归方式直到全部新增成功
batchSaveUserCouponList(event.getCouponTemplateId(), event.getCouponTaskBatchId(), userCouponDOList);
// 将这些优惠券添加到用户的领券记录中
List<String> userIdList = userCouponDOList.stream()
.map(UserCouponDO::getUserId)
.map(String::valueOf)
.toList();
String userIdsJson = new ObjectMapper().writeValueAsString(userIdList);
List<String> couponIdList = userCouponDOList.stream()
.map(each -> StrUtil.builder()
.append(event.getCouponTemplateId())
.append("_")
.append(each.getId())
.toString())
.map(String::valueOf)
.toList();
String couponIdsJson = new ObjectMapper().writeValueAsString(couponIdList);
// 调用 Lua 脚本时,传递参数
List<String> keys = Arrays.asList(
// 为什么要进行替换 %s 为空白字符串?因为后续代码需要使用 %s 进行动态值替换,但是当前 LUA 脚本中不需要,所以为了兼容后续不改动特此替换
StrUtil.replace(EngineRedisConstant.USER_COUPON_TEMPLATE_LIST_KEY, "%s", ""),
USER_COUPON_TEMPLATE_LIMIT_KEY,
String.valueOf(event.getCouponTemplateId())
);
List<String> args = Arrays.asList(
userIdsJson,
couponIdsJson,
String.valueOf(new Date().getTime()),
String.valueOf(event.getValidEndTime().getTime())
);
// 获取 LUA 脚本,并保存到 Hutool 的单例管理容器,下次直接获取不需要加载
DefaultRedisScript<Void> buildLuaScript = Singleton.get(BATCH_SAVE_USER_COUPON_LUA_PATH, () -> {
DefaultRedisScript<Void> redisScript = new DefaultRedisScript<>();
redisScript.setScriptSource(new ResourceScriptSource(new ClassPathResource(BATCH_SAVE_USER_COUPON_LUA_PATH)));
redisScript.setResultType(Void.class);
return redisScript;
});
stringRedisTemplate.execute(buildLuaScript, keys, args.toArray());
// 增加库存回滚方案,如果用户已经领取优惠券被校验,需要将 Redis 预扣减库存回滚
int originalUserCouponSize = batchUserMaps.size();
// 如果用户已领取被校验会从集合中删除
int availableUserCouponSize = userCouponDOList.size();
int rollbackStock = originalUserCouponSize - availableUserCouponSize;
if (rollbackStock > 0) {
// 回滚优惠券模板缓存库存数量
stringRedisTemplate.opsForHash().increment(
String.format(EngineRedisConstant.COUPON_TEMPLATE_KEY, event.getCouponTemplateId()),
"stock",
rollbackStock
);
// 回滚优惠券模板数据库库存数量
couponTemplateMapper.incrementCouponTemplateStock(event.getShopNumber(), event.getCouponTemplateId(), rollbackStock);
}
}
private Integer decrementCouponTemplateStock(CouponTemplateDistributionEvent event, Integer decrementStockSize) {
Long couponTemplateId = event.getCouponTemplateId();
int decremented = couponTemplateMapper.decrementCouponTemplateStock(event.getShopNumber(), couponTemplateId, decrementStockSize);
// 如果修改记录失败,意味着优惠券库存已不足,需要重试获取到可自减的库存数值
if (!SqlHelper.retBool(decremented)) {
LambdaQueryWrapper<CouponTemplateDO> queryWrapper = Wrappers.lambdaQuery(CouponTemplateDO.class)
.eq(CouponTemplateDO::getShopNumber, event.getShopNumber())
.eq(CouponTemplateDO::getId, couponTemplateId);
CouponTemplateDO couponTemplateDO = couponTemplateMapper.selectOne(queryWrapper);
return decrementCouponTemplateStock(event, couponTemplateDO.getStock());
}
return decrementStockSize;
}
private void batchSaveUserCouponList(Long couponTemplateId, Long couponTaskBatchId, List<UserCouponDO> userCouponDOList) {
// MyBatis-Plus 批量执行用户优惠券记录
try {
userCouponMapper.insert(userCouponDOList, userCouponDOList.size());
} catch (Exception ex) {
Throwable cause = ex.getCause();
if (cause instanceof BatchExecutorException) {
// 添加到 t_coupon_task_fail 并标记错误原因,方便后续查看未成功发送的原因和记录
List<CouponTaskFailDO> couponTaskFailDOList = new ArrayList<>();
List<UserCouponDO> toRemove = new ArrayList<>();
// 调用批量新增失败后,为了避免大量重复失败,我们通过新增单条记录方式执行
userCouponDOList.forEach(each -> {
try {
userCouponMapper.insert(each);
} catch (Exception ignored) {
// ...... 新增到 t_coupon_task_fail 表
});
// 删除已经重复的内容
userCouponDOList.removeAll(toRemove);
return;
}
throw ex;
}
}
}梳理这段代码业务逻辑如下:
- 1. 首先调用
decrementCouponTemplateStock进行扣减 MySQL 优惠券模板库存,如果一次性扣减成功,那么进行下述逻辑;如果扣减失败,会有一个递归扣减,直到扣减指定的库存为止; - 2. 获取 Redis 中待保存入库用户优惠券 Set 列表,转换成 userCouponDOList 待保存到数据库集合;
- 3. 调用
batchSaveUserCouponList批量保存方法,如果没有唯一索引冲突,则方法结束,否则按照单条执行新增语句; - 4. 批量保存到数据库后,我们将保存成功的用户优惠券记录新增到用户 Redis 领券记录中;
- 5. 如果说用户已经领过券,需要将已经预扣减过的库存再调用
incrementCouponTemplateStock方法进行回滚。
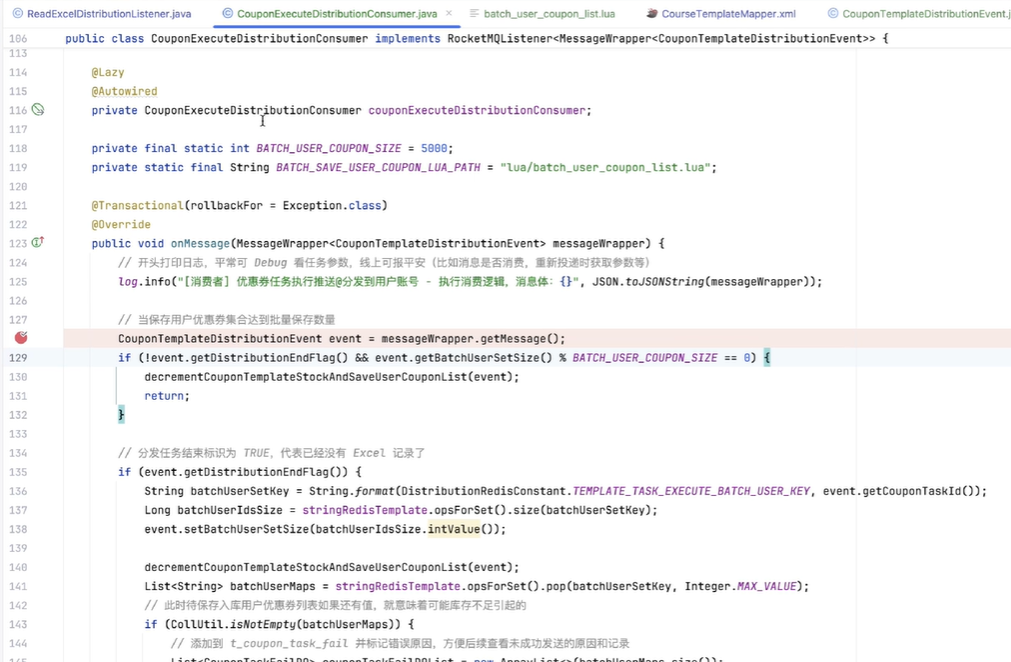
所以的话,我们就不先打断点了。因为刚才我打断点的时候,其实发现了一些问题。
首先,我们刚才的优惠券 Excel 里面其实是 5000 条。第 5000 次的话,它会通过上面这个逻辑去往这里发个消息。然后发消息的时候,它其实已经发出去了,对吧?然后在这个 Excel 里面,它就会开始执行这一步逻辑。
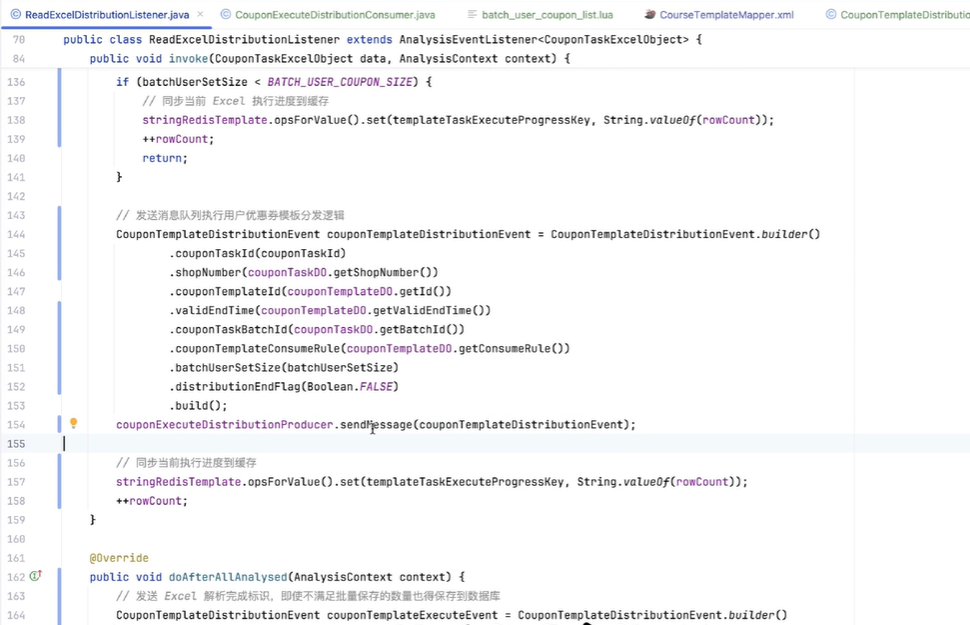
然后这个是在它 Excel 执行解析完了,对吧?它还会再发一个“结束”的标识,意味着“我 Excel 已经解析成功了”,然后再去告诉我我的消费者:“你有一些消息,可能没有满 5000,其实他已经在对应的缓存里面了。发这个消息就是要把那些给清空掉。”
这就会导致一个问题:我在这边第一个消息来了之后,我打个断点,其实第二个消息他会把我的逻辑给执行掉。
我举个简单的例子:那就是我们在这里,它有一个判断
// 当保存用户优惠券集合达到批量保存数量
CouponTemplateDistributionEvent event = messageWrapper.getMessage();
if (!event.getDistributionEndFlag() && event.getBatchUserSetSize() % BATCH_USER_COUPON_SIZE == 0) {
decrementCouponTemplateStockAndSaveUserCouponList(event);
return;
}在CouponTemplateDistributionEvent event = messageWrapper.getMessage();打断点 ,如果说它不是解析完成,并且它的批量批次已经达到了 5000,我们会执行这个逻辑。OK,我在这里打断点。然后第二个消息他发过来的时候,其实大家可以看到,完成标识已经到了这里。
@Override
public void doAfterAllAnalysed(AnalysisContext context) {
// 发送 Excel 解析完成标识,即使不满足批量保存的数量也得保存到数据库
CouponTemplateDistributionEvent couponTemplateExecuteEvent = CouponTemplateDistributionEvent.builder()
.distributionEndFlag(Boolean.TRUE) // 设置解析完成标识
.shopNumber(couponTemplateD00.getShopNumber())
.couponTemplateId(couponTemplateD00.getId())
.validEndTime(couponTemplateD00.getValidEndTime())
.couponTemplateConsumeRule(couponTemplateD00.getConsumeRule())
.couponTaskBatchId(couponTaskD00.getBatchId())
.couponTaskId(couponTaskD00.getId())
.build();
couponExecuteDistributionProducer.sendMessage(couponTemplateExecuteEvent);
}他发现已经没有 Excel 记录的时候,他会去把我所有的缓存里面的记录给他弹出来——看到没有?他会去把 set 弹出来,弹的数据量是最大的。
// 分发任务结束标识为 TRUE,代表已经没有 Excel 记录了
if (event.getDistributionEndFlag()) {
String batchUserSetKey = String.format(DistributionRedisConstant.TEMPLATE_TASK_EXECUTE_BATCH_USER_KEY, event.getCouponTaskId());
Long batchUserIdsSize = stringRedisTemplate.opsForSet().size(batchUserSetKey);
event.setBatchUserSetSize(batchUserIdsSize.intValue());
decrementCouponTemplateStockAndSaveUserCouponList(event);
List<String>
// 此时待保存入库用户优惠券列表如果还有值,就意味着可能库存不足引起
if (CollUtil.isNotEmpty(batchUserMaps)) {大家能理解我说的吗?比如说,我正常在这个节点,我第一个消息来了,我要扣减 5000,对吧?我数据库里面是 5001,对不对?我在这边打着断点,然后他给我执行完了,相当于我数据库里面只有一个库存了——这就有问题了,对不对?
然后接下来的话,我通过断点的形式就是一改。我跟大家先梳理一遍逻辑,大家自己可以在本地电脑上去打断点去进行一个调试。第一块,首先我们要去扣减我们的优惠券模板的库存;
其次,我们要去保存我们的用户领券记录。
OK,第一点的话,就是我们去数据库里面去进行一个自减。大家之前也都看过,那就是一个通过悲观锁的形式去给他一个并发保障的扣减。<!-- 通过 MySQL 悲观行记录锁确保库存不会被多扣,并采用上层业务自旋重试直至成功将优惠券库存扣减至零 --> <update id="decrementCouponTemplateStock"> UPDATE t_coupon_template SET stock = stock - #{decrementStock} WHERE shop_number = #{shopNumber} AND id = #{couponTemplateId} AND stock >= #{decrementStock} </update> <!-- 回滚 MySQL 数据库优惠券库存余量,通过 MySQL 悲观行记录锁保障并发安全 --> <update id="incrementCouponTemplateStock"> UPDATE t_coupon_template SET stock = stock + #{incrementStock} WHERE shop_number = #{shopNumber} AND id = #{couponTemplateId} </update>
然后在这里,如果说——因为我们去操作 MySQL 的时候,如果你加个返回值的话,它是个 int 类型。如果说对这条记录有变更,它就会返回 1;如果说没有变更,它就会返回 0。
这里如果返回 0 的话,就一定是意味着我们的库存不足了。因为我们在这里面有一个判断:我们要扣减库存,一定要大于等于它要扣减的数量。所以说,这里判断不足的话,我们就要开始获取到最新的一个库存,然后再给他执行一次我们的递归,对不对?直到能扣减出来它对应的一个能够被扣减的库存数量。
然后返回正常的话,我们这里面肯定是decrementStockSize和返回值一定是相等的,对不对?异常的情况下才会不等。
OK,假设我们是相等的,然后到了上面之后,它应该是 5000,对吧?在这里,batchUserSetKey是我们在 Redis 底层里面保存的缓冲队列。然后我们去拿到已经扣减成功的库存——相当于我们已经有了一个入场券了。
接下来的话,我们已经把从缓冲队列里面把数据给弹出来了,然后我们要去把这些数据给它新增到我们的数据库里面。
在这里,我们是给他进行了一些组装,逻辑比较简单一点,我们就先跳过。就那陀for里面的内容
然后去在这里面有一个特殊说明
batchSaveUserouponList(event.getCouponTemplateId(),event.getCouponTaskBatchId(),userCouponDoList);
:我们去限制了每个用户只能限领一次。然后在这里,这是一个批量新增的方法——就是 MyBatis-Plus 它的一个扩展方法。
第一个userCouponMapper.insert(userCouponDoList,userLouponDoList.size();是我们的一个需要批量新增的数据集合,第二块是它的一个 size——相当于我们单次的批量的数值。我们相当于我们是 5000,就直接让他批量新增就好了。他默认的话,我如果记得没错,应该是单次 1000。
我们可以看一下。对,默认的话 1000。如果说我们不设置的话,相当于我们一次 5000 的记录,他会分 5 次执行,性能不就慢了 5 倍,对不对?
Q:event.getBatchUserSetSize() % BATCH_USER_COUPON_SIZE == 0 这段代码的意义是什么?
A:之前其实没有这行代码的,得益于星球同学的提醒,我们将这个逻辑进行了添加。如果 BatchSize 等于 50001,那么取模后值不等于 0,就会跳过该流程。直到下次 BatchSize 等于 5000 时执行。
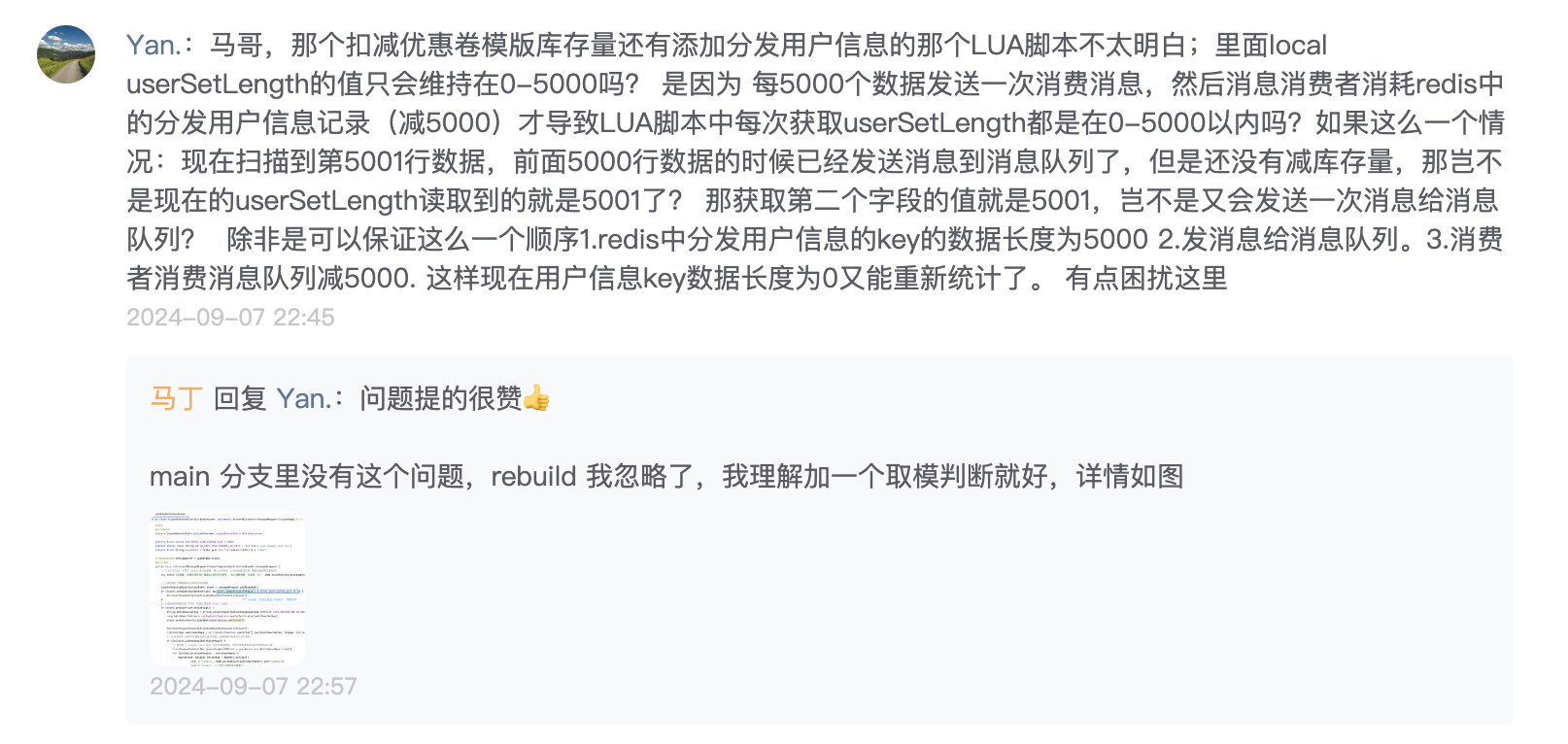
另外,我觉得大家可能对批量保存这里会有点疑问,之前我们是用递归的形式写的,为什么改成批量新增失败后退化成单条新增?
如果我们使用递归的话,会有一个很尴尬很尴尬的问题,不知道是事务引起的,还是批量新增引起的。这个是之前的代码:
private void batchSaveUserCouponList(Long couponTemplateId, List<UserCouponDO> userCouponDOList) {
// MyBatis-Plus 批量执行用户优惠券记录
try {
userCouponMapper.insert(userCouponDOList, userCouponDOList.size());
} catch (Exception ex) {
Throwable cause = ex.getCause();
if (cause instanceof BatchExecutorException) {
// 查询已经存在的用户优惠券记录
List<Long> userIds = userCouponDOList.stream().map(UserCouponDO::getUserId).toList();
List<UserCouponDO> existingUserCoupons = getExistingUserCoupons(couponTemplateId, userIds);
// 遍历已经存在的集合,获取 userId,并从需要新增的集合中移除匹配的元素
for (UserCouponDO each : existingUserCoupons) {
Long userId = each.getUserId();
// 使用迭代器遍历需要新增的集合,安全移除元素
Iterator<UserCouponDO> iterator = userCouponDOList.iterator();
while (iterator.hasNext()) {
UserCouponDO item = iterator.next();
if (item.getUserId().equals(userId)) {
iterator.remove();
}
}
}
// 采用递归方式重试,直到不存在重复的记录为止
if (CollUtil.isNotEmpty(userCouponDOList)) {
batchSaveUserCouponList(couponTemplateId, userCouponDOList);
}
}
}
}问题复现步骤:数据库中的用户优惠券表已有一条记录,ID 为 1。在一个事务中使用 MyBatisPlus 的批量新增方法插入三条记录,ID 分别为 1、2、3。调用批量新增方法时,出现 ID 1 主键重复的错误。将 ID 1 从集合中删除后,在同一个方法中通过递归再次调用批量新增方法,这次却报错 ID 2 主键冲突,但实际上数据库中并不存在 ID 2。由于 ID 2 无法查询到,也无法从集合中删除,导致递归调用持续报错。
确实没找到原因是什么,最终只能改成批量保存失败后转为单条记录保存。如果报错则忽略,最终没有报错的记录会跟着事务一起提交。
这里说下唯一索引的功能,即使事务没有提交,唯一索引也是生效的。举例:事务执行中,没提交数据;然后在数据库可视化工具里,新增同样的唯一索引记录,会报错。
catch (Exception ex) {
Throwable cause = ex.getCause();
if (cause instanceof BatchExecutorException) {..............
重点在这里:如果说我们批量执行的时候,假设用户已经领了一次优惠券了,这里就会被我们的唯一索引给校验住。校验住之后,我们就会抛一个异常出来。我们去识别,然后那就是:我把这个记录从之前的批量新增改成单次新增。如果单次新增还有问题,OK,我去查一下它是否已经存在了这条记录。如果已经存在,好,我把它给添加到我的用户的领券失败记录里面去,并且我把它从我的主机集合里面给它抹掉。
因为我之前是测试过的效果是好的,然后我给大家看一下:“用户已领取该优惠券”。其实复现的逻辑很简单,那就是我们在数据库里面随便找一个用户。如果说你之前执行过分发,OK,像我这种,找到用户的 ID 之后,我们拿最新的一次它的模板 ID 给它——就是假设我在里面新增一个模板 ID,然后拿到之后给它放到这里,其实它已经存在了,对不对?
然后我们这里面就会抛异常,这条记录里面就会有值了。大家可以去试一下,然后这里面我们就不再过多赘述。然后把用户的优惠券已经加到数据库之后了,我们需要把这个数据给它预热到缓存里面
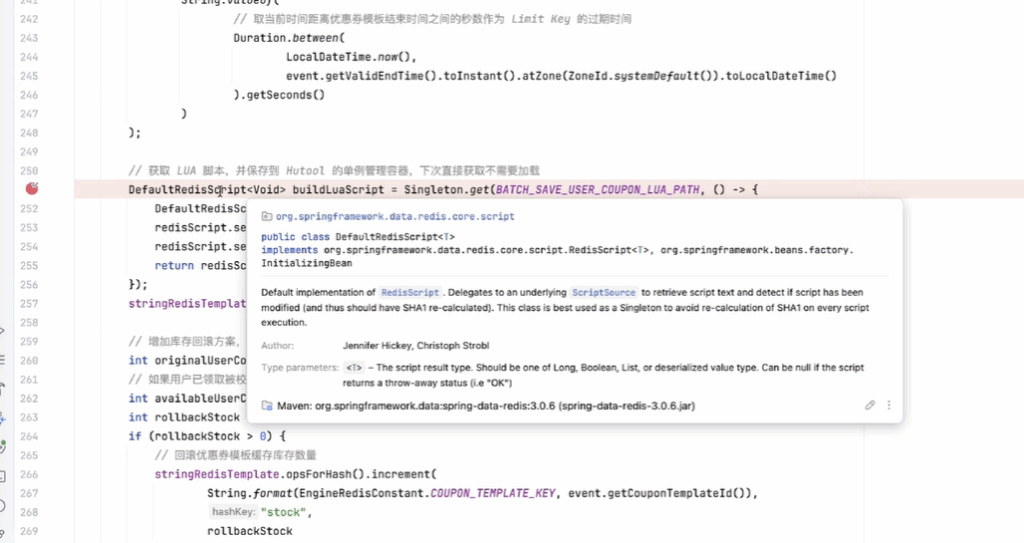
之前可以看到,我们是通过 Lua 脚本去做的。因为一般来讲,面对一些 To C 或者说一些高并发的逻辑,尽量还是用 Redis 脚本去做,或者说管道的形式,这样的话性能会高一点。
然后我们可以看一下我们的 Keys 和参数,它里面都放了什么:
- 这个的话,就是我们的用户的一个领券的 Key 前缀;
- 这个的话,就是我们单个优惠券模板要去限制的数量;
- 然后再往下的话,就是一个我们的模板 ID。
我们 Keys 的话就比较多了:
- 首先第一点,就是我们本次需要参与的用户 ID。
这个就比较有意思了。大家可以看到,我们可以看一下它是怎么拼的:首先前面是我们的模板 ID,然后这里是我们用户的领券 ID(刚才我们新增的数据库的主键 ID)。
好像发现一下,似乎代码有点多余——这里我就先不改,因为我发现配置里面已经有优惠券模板 ID 了,其实没有必要拼。既然拼了,就先这么去用,对吧?其实这样写的话会增加一些网络的消耗。我们就不在这个课堂上去给大家改了,大家知道有这个事情就好。
然后我们为什么要把用户的领券 ID 和我们的优惠券模板拼一起?
正常来讲,我一个用户的领券里面,对吧?我有一个 Key 对应的是我所有的优惠券,这样的话它应该是一个单个的值,对不对?
但是我这里把它考虑把优惠券的模板给它加进去,是因为我们在后面是有一些要用到的。
众所周知,我们的领券记录它是通过什么去进行分片的?它是通过用户 ID
假设我要去查用户的可用优惠券列表的时候,如果我没有优惠券模板 ID,我怎么能知道用户的这张券能不能被用于商品或者订单? 不知道
这样的话,你是不是还得去数据库查一遍——根据 ID 去查一下说我的优惠券模板是什么,再去查一下模板对应的规则。这样的话,你是一定要查一次数据库。
在这里,因为我们查询用户可用的优惠券列表,或者说我们去核销优惠券的时候,一定要用到优惠券模板的。所以说,我们是一定要避免他去查数据库的。
所以在这里面,我们就把它的模板给它拼一起。这样的话,等到后面我们是直接用的,OK。
第三个参数的话,是当前的一个时间——后面会用到。因为我们是用 ZSet 去存的,所以说我们通过当前的时间来给用户的领券记录排个序。再往后的话,就是因为我们要限制优惠券模板它的一个领券的次数,所以说我们要给它一个过期时间。因为优惠券模板是有过期时间的,对不对?所以说我们要取它的过期时间——从现在到它的过期时间一共有多少秒,然后把这个值设置给 Redis 的参数。List args = Arrays.asList(args, size = 4);
userIdsJson, userIdsJson: "[\"184837815886552667\",\"184837815877719251\",\"1848378158684917782\",\"187
couponIdsJson, couponIdsJson: "[\"1936786368782878978_1936786403177820160\",\"1936786368782878978_193
String.valueOf(new Date().getTime()),
// 取当前时间距离优惠券模板结束时间之间的秒数为 Limit Key 的过期时间
Duration.between(
LocalDateTime.now(),
event.getValidEndTime().toInstant().atZone(ZoneId.systemDefault()).toLocalDateTime()
).getSeconds()
);
// 获取传递的参数
local userIds = cjson.decode(ARGV[1]) -- 用户 ID 集合,JSON 格式的字符串
local couponIds = cjson.decode(ARGV[2]) -- 优惠券 ID 集合,JSON 格式的字符串
local userIdPrefix = KEYS[1] -- 用户 ID 前缀(从 KEYS 获取)
local limitKeyPrefix = KEYS[2] -- 用户优惠券模板限制 ID
local currentTemplateId = tonumber(KEYS[3]) -- 优惠券模板 ID
local currentTime = tonumber(ARGV[3]) -- 获取当前 Unix 时间戳(毫秒)
local couponTemplateValidEndTime = tonumber(ARGV[4]) -- 优惠券模板到期时间
-- 遍历用户 ID 集合
for i, userId in ipairs(userIds) do
local key = userIdPrefix .. userId -- 拼接用户 ID 前缀和用户 ID
local couponId = couponIds[i] -- 获取对应的优惠券 ID
if couponId then
redis.call('ZADD', key, currentTime, couponId) -- 添加优惠券 ID 到 ZSet 中
local limitKey = limitKeyPrefix .. userId .. '_' .. couponTemplateId
redis.call('INCR', limitKey) -- 添加用户和优惠券的领取次数,方便后续对用户进行领取次数前置限制
redis.call('EXPIRE', limitKey, couponTemplateValidEndTime) -- 添加用户优惠券模板限制领取 Key 过期时间
end
end- 第一块操作的话,通过 ZAdd 的形式,将当前的“优惠券模板 ID + 用户领券 ID”拼接好的 Key 加进去,它的值就是排序字段(当前的时间);
- 然后,我要给对应的限制用户领优惠券的字段,给大家自增一下;
- 然后给它设置一个过期时间。
// 增加库存回滚方案,如果用户已经领取被校验,需要将 Redis 预扣减库存回滚
int originalUserCouponSize = batchUserMaps.size();
int availableUserCouponSize = userCouponDOLList.size();
int rollbackStock = originalUserCouponSize - availableUserCouponSize;
if (rollbackStock > 0) {
// 回滚优惠券模板库存数量
String redisTemplateOpsForHash = String.format(EngineRedisConst.COUON_TEMPLATE_KEY, event.getCouponTemplateId()),
hashKey = "stock",
rollbackStock
);
// 回滚优惠券模板数据库库存数量
couponTemplateMapper.incrementCouponTemplateStock(event.getShopNumber(), event.getCouponTemplateId(), rollbackStock);
}然后我们这边执行成功之后,然后我们就要去增加一个判断了:如果说你用户已经领过优惠券,然后在刚才那里被唯一索引校验住了,相当于我们已经把在缓存和数据库里面的优惠券的库存给扣减了,对不对?这个时候但是没有用上,我们是不是要把它给回滚回去?对不对?
其实本来像这种能够进行分发的邮件——其实没有,其实不需要回滚。就是从我的角度上来看,不需要回滚,因为它不属于那种很重要的优惠券。但是为了保障我们业务逻辑的合理性,我们还是给他进行了一次回滚。
然后回滚的话很简单:就是我正常的逻辑——我要去扣减的一个数据,以及你最终返回给我的一个用户的领券集合的一个记录长度进行比较。如果说小于我们预期的批量大小,就证明有被唯一索引校验的记录。
大家可以看到这个数据:这个数据的话,就是如果说被唯一索引占住的话,我们会从这里面把它移除掉,对不对?在这里删除已经重复的记录,所以说是通过这个数据给他进行一个扣减的。
然后回滚的话很简单:
- 第一个,就是回滚它的数据库(把失败的记录从待插入集合中移除);
- 第二个的话,回滚它的库存(把多扣的库存加回去)。
4. 修改优惠券分发记录状态
上面讲了到达批量执行条件的消息,然后我们接着说 Excel 读取完执行的消息。
@Component
@RequiredArgsConstructor
@RocketMQMessageListener(
topic = "one-coupon_distribution-service_coupon-execute-distribution_topic${unique-name:}",
consumerGroup = "one-coupon_distribution-service_coupon-execute-distribution_cg${unique-name:}"
)
@Slf4j(topic = "CouponExecuteDistributionConsumer")
public class CouponExecuteDistributionConsumer implements RocketMQListener<MessageWrapper<CouponTemplateDistributionEvent>> {
private final UserCouponMapper userCouponMapper;
private final CouponTemplateMapper couponTemplateMapper;
private final CouponTaskMapper couponTaskMapper;
private final CouponTaskFailMapper couponTaskFailMapper;
private final StringRedisTemplate stringRedisTemplate;
@Lazy
@Autowired
private CouponExecuteDistributionConsumer couponExecuteDistributionConsumer;
private static final String BATCH_SAVE_USER_COUPON_LUA_PATH = "lua/batch_user_coupon_list.lua";
@Transactional(rollbackFor = Exception.class)
@Override
public void onMessage(MessageWrapper<CouponTemplateDistributionEvent> messageWrapper) {
// ......
// 分发任务结束标识为 TRUE,代表已经没有 Excel 记录了
if (event.getDistributionEndFlag()) {
String batchUserSetKey = String.format(DistributionRedisConstant.TEMPLATE_TASK_EXECUTE_BATCH_USER_KEY, event.getCouponTaskId());
Long batchUserIdsSize = stringRedisTemplate.opsForSet().size(batchUserSetKey);
event.setBatchUserSetSize(batchUserIdsSize.intValue());
decrementCouponTemplateStockAndSaveUserCouponList(event);
List<String> batchUserMaps = stringRedisTemplate.opsForSet().pop(batchUserSetKey, Integer.MAX_VALUE);
// 此时待保存入库用户优惠券列表如果还有值,就意味着可能库存不足引起的
if (CollUtil.isNotEmpty(batchUserMaps)) {
// ...... 添加到 t_coupon_task_fail 并标记错误原因
}
// 确保所有用户都已经接到优惠券后,设置优惠券推送任务完成时间
CouponTaskDO couponTaskDO = CouponTaskDO.builder()
.id(event.getCouponTaskId())
.status(CouponTaskStatusEnum.SUCCESS.getStatus())
.completionTime(new Date())
.build();
couponTaskMapper.updateById(couponTaskDO);
}
}
}和上面流程一致,首先扣减 MySQL 优惠券模板库存,然后保存用户 Redis 领券记录等操作。最终所有逻辑执行完后,我们设置优惠券推送任务的状态和完成时间即可。
如果说我的分发任务已经结束了,那这个时候我要做哪些事情?
第一步的话,我获取到刚才我最后的一个数据量,也就是我们对应的缓冲队列它里面还有多少元素,然后我们去给他设置到我们的批量的一个大小里面,然后再给它进行一次刚才上面的逻辑。
可以看到这个逻辑:他弹了、操作完之后,如果说里面还有对应的记录,基本上可以断定我们的优惠券库存里面已经没有值了。到这里的话,我们就要把这些记录给它新增到我们对应的优惠券任务失败的记录里面去。
couponTaskFailMapper.insert(couponTaskFailDoList);
最后的话,然后我们把之前上一节课里面——在 Excel 解析完的去修改我们分发任务的逻辑——给加到了这里,然后给它变更一下它的一个状态以及它的一个完成时间。
//确保所有用户都已经接到优惠券后,设置优惠券推送任务完成时间
CouponTaskDO couponTaskDO = CouponTaskDO.builder()
.id(event.getCouponTaskId())
.status(CouponTaskStatusEnum.SUcCESS.getStatus())
.completionTime(new Date())
.build();
couponTaskMapper.updateById(couponTaskDO);
保存用户领券失败记录
如果用户已经领取过该优惠券或者库存不足,会被唯一索引校验住,那我们就需要将对应的报错记录添加到 t_coupon_task_fail 表中。
@Transactional(rollbackFor = Exception.class)
@Override
public void onMessage(MessageWrapper<CouponTemplateDistributionEvent> messageWrapper) {
// ......
// 分发任务结束标识为 TRUE,代表已经没有 Excel 记录了
if (event.getDistributionEndFlag()) {
String batchUserSetKey = String.format(DistributionRedisConstant.TEMPLATE_TASK_EXECUTE_BATCH_USER_KEY, event.getCouponTaskId());
Long batchUserIdsSize = stringRedisTemplate.opsForSet().size(batchUserSetKey);
event.setBatchUserSetSize(batchUserIdsSize.intValue());
decrementCouponTemplateStockAndSaveUserCouponList(event);
List<String> batchUserMaps = stringRedisTemplate.opsForSet().pop(batchUserSetKey, Integer.MAX_VALUE);
// 此时待保存入库用户优惠券列表如果还有值,就意味着可能库存不足引起的
if (CollUtil.isNotEmpty(batchUserMaps)) {
// 添加到 t_coupon_task_fail 并标记错误原因,方便后续查看未成功发送的原因和记录
List<CouponTaskFailDO> couponTaskFailDOList = new ArrayList<>(batchUserMaps.size());
for (String batchUserMapStr : batchUserMaps) {
Map<Object, Object> objectMap = MapUtil.builder()
.put("rowNum", JSON.parseObject(batchUserMapStr).get("rowNum"))
.put("cause", "优惠券模板库存不足")
.build();
CouponTaskFailDO couponTaskFailDO = CouponTaskFailDO.builder()
.batchId(event.getCouponTaskBatchId())
.jsonObject(com.alibaba.fastjson.JSON.toJSONString(objectMap))
.build();
couponTaskFailDOList.add(couponTaskFailDO);
}
// 添加到 t_coupon_task_fail 并标记错误原因
couponTaskFailMapper.insert(couponTaskFailDOList);
}
// 确保所有用户都已经接到优惠券后,设置优惠券推送任务完成时间
CouponTaskDO couponTaskDO = CouponTaskDO.builder()
.id(event.getCouponTaskId())
.status(CouponTaskStatusEnum.SUCCESS.getStatus())
.completionTime(new Date())
.build();
couponTaskMapper.updateById(couponTaskDO);
}
}
private void batchSaveUserCouponList(Long couponTemplateId, Long couponTaskBatchId, List<UserCouponDO> userCouponDOList) {
// MyBatis-Plus 批量执行用户优惠券记录
try {
userCouponMapper.insert(userCouponDOList, userCouponDOList.size());
} catch (Exception ex) {
Throwable cause = ex.getCause();
if (cause instanceof BatchExecutorException) {
// 添加到 t_coupon_task_fail 并标记错误原因,方便后续查看未成功发送的原因和记录
List<CouponTaskFailDO> couponTaskFailDOList = new ArrayList<>();
List<UserCouponDO> toRemove = new ArrayList<>();
// 调用批量新增失败后,为了避免大量重复失败,我们通过新增单条记录方式执行
userCouponDOList.forEach(each -> {
try {
userCouponMapper.insert(each);
} catch (Exception ignored) {
Boolean hasReceived = couponExecuteDistributionConsumer.hasUserReceivedCoupon(couponTemplateId, each.getUserId());
if (hasReceived) {
// 添加到 t_coupon_task_fail 并标记错误原因,方便后续查看未成功发送的原因和记录
Map<Object, Object> objectMap = MapUtil.builder()
.put("rowNum", each.getRowNum())
.put("cause", "用户已领取该优惠券")
.build();
CouponTaskFailDO couponTaskFailDO = CouponTaskFailDO.builder()
.batchId(couponTaskBatchId)
.jsonObject(com.alibaba.fastjson.JSON.toJSONString(objectMap))
.build();
couponTaskFailDOList.add(couponTaskFailDO);
// 从 userCouponDOList 中删除已经存在的记录
toRemove.add(each);
}
}
});
// 批量新增 t_coupon_task_fail 表
couponTaskFailMapper.insert(couponTaskFailDOList, couponTaskFailDOList.size());
// 删除已经重复的内容
userCouponDOList.removeAll(toRemove);
return;
}
throw ex;
}
}
/**
* 查询用户是否已经领取过优惠券
*
* @param couponTemplateId 优惠券模板 ID
* @param userId 用户 ID
* @return 用户优惠券模板领取信息是否已存在
*/
@Transactional(propagation = Propagation.NOT_SUPPORTED, readOnly = true)
public Boolean hasUserReceivedCoupon(Long couponTemplateId, Long userId) {
LambdaQueryWrapper<UserCouponDO> queryWrapper = Wrappers.lambdaQuery(UserCouponDO.class)
.eq(UserCouponDO::getUserId, userId)
.eq(UserCouponDO::getCouponTemplateId, couponTemplateId);
return userCouponMapper.selectOne(queryWrapper) != null;
}Q:为什么要是用非事务的查询方式查询已存在的用户优惠券记录?
A:如果第一次批量保存数据库失败后,批量保存的一些记录会在事务缓冲区中,如果在同一个事务下,会查到数据库中本不存在的记录。我们保存用户已领取优惠券的失败记录,需要是数据库中真实存在的,所以不使用事务的方式查询。
常见问题答疑
1. 为什么 CouponExecuteDistributionConsumer 消费时会比批量结果多几条?
给大家支个招,5000 批次是生产中的参数,我们测试时候 10 条一个批次就好了,方便 Debug。
然后有同学提问:为什么 CouponExecuteDistributionConsumer 消费时获取 Redis Set 用户领券记录会比批量结果多几条?有时候是 10 条,有时候是 11 条这样。
因为触发批次条数后,开始往 CouponExecuteDistributionConsumer 发送消息,但是有可能在执行消费前,Excel 监听器又往 Redis Set 结构添加了一条用户领券记录,所以就会出现比预期的结果多出几条的可能。这个并不会影响系统运行,忽略就好。
就是你再去这里面进行消费的时候,对不对?你肯定会打 debug,对不对?你打断点的时候,这里面它是源源不断地往你的缓冲队列里面会去设置它的一个新增值的。明白吧?所以说你打断点是一定会出现这种情况的。我们设置了缓冲的一次批次是 10,但是你去看它对应的 Set 里面的话,它会多于 10——这个是正常的一个现象。
2. 消息队列是否需要顺序消息?
需要的。我们在执行正式分发用户优惠券的消费者时,需要使用顺序消息执行。因为有可能我们 Excel 已经读取完了,开始执行 distributionEndFlag 等于 True 的逻辑时,上一个 5000 批次的消息还没有执行完的可能。假设 5000 批次消息里有出现异常,但是因为 distributionEndFlag 等于 True 的逻辑先执行,就会存在记录不上的场景。
为此,我们需要发送顺序消息,有两种方式:
- Topic 下单队列:这样能保证顺序,但是缺点是并发太慢。
- Topic 下多队列,根据分发任务 ID 进行 Hash 投递到固定队列:并发较高,推荐使用该策略。
参考文章:RocketMQ 顺序消息
首先是需要的。因为我们去进行一个分发消费的时候,有一种可能:我在执行的时候,假如说我的一个批次到了,我去发送了个消息。但是恰巧我的下一条——我的 Excel 已经没记录了,那么我会把这个也去发送到对应的消息队列里面。然后相当于这两条消息是同时执行的。
然后因为这里面的逻辑会执行得稍微复杂一点——第一个消息会稍微复杂一点,第二个消息的话它可能会更快一点。也就意味着我们这里面设置了它已经执行完成了,但是它的消息其实还在执行的过程当中。
所以说,我是推荐大家用顺序消息的。
那顺序消息的话有两种:
- 第一种的话,我们在一个 Topic 下面使用单个队列,这样的话能够保证我们这个消息的顺序性,但是缺点就是并发会慢一点,对吧?
- 第二个就是我们一个 Topic 下面多队列,我们可以根据我们分发任务 ID,通过 Hash 的形式放到固定的队列里面,这样的话并发还是比较高的。
大家可以去看一下我们的参考文章里面,这里面是有对这种消息进行一个演示示例的。
3. 为什么要拆分消息队列消息?
有位同学提出疑问,为什么要对消息队列进行拆分消息消费?以下是原话:
在优惠券分发的时候,我们使用了消息队列消费拆分方案,目的是使得 rocketmq 的 broker 不要认为消息消费超时而重新投递。 但是我可以把 rocketmq 的消息消费超时时间设置的长一点不就可以了吗。网上说可以通过 transactionTimeout 参数来配置。 而且我也不觉得不拆分会使得消费时间变得太长,因为百万优惠券发放其实只需要 200s,我们已经通过批处理来大大缩短时间了,那这个拆分是不是显得没什么必要呢。
从我们的场景来看,我没有发现明显的问题。但为什么仍然要做拆分呢?其实核心目的是树立规约意识——消息队列的消息处理应该尽量轻量,不适合嵌入过长的业务逻辑。
在本地测试时,即使单次消费时间较长可能也不会出现问题,但生产环境更复杂,这种做法可能会带来潜在风险。
总结来看,拆分消息一定不会出错,并且没有明显缺陷,而长消息虽然实现更简单,但潜在风险不确定。如果是我,一定会选择拆分。
参考原回答:https://t.zsxq.com/IdYVS
文末总结
本章节较为复杂,代码逻辑一环套一环,不过,虽然逻辑相较于 v1 版本变的晦涩难懂,但是性能提升非常明显。相同的 5000 条记录,v1 版本需要执行 1 分钟左右,v2 也就是当前版本仅需要 1 秒,接近 60 倍的性能提升。
虽然逻辑已经相对完善了,但是还有两个可能存在瑕疵的地方,如下所示:
- 如果
batchSaveUserCouponList执行时数据库宕机,那么就会面临事务回滚问题,意味着我们需要将从 Redis 中获取的领券用户记录再保存到 Redis。 - 批量新增时有部分用户优惠券已存在,那么新增数量和预期就会不一致,也就意味着我们需要将这些失败的库存返回给数据库和缓存。
为什么没有在代码逻辑中体现呢?是因为难不好写,或者马哥偷懒了么?其实都不是,这个逻辑写起来很简单,无外乎业务套业务。为什么不写,我梳理两个原因:
- 数据库宕机可能性非常非常低,我工作这么些年,是没有遇到过。所以,为了这种非常极端的概念去把业务代码变得更复杂,我认为是得不偿失的,会让大家的理解难度再次加深。
- 为什么不做库存回滚?因为能进行大批量分发的优惠券模板,基本上库存可以理解为无限。如果需要回滚,将新增的 userCouponDOList 减去执行了
batchSaveUserCouponList后的 userCouponDOList 就好了。不写这个逻辑的原因同上,增加代码复杂度,所以没有必要进行回滚。
完结,撒花 🎉
=_=:马哥,递归扣减这里,什么情况下会一次性扣减失败走递归扣减呢
马丁 回复 =_=:比如你扣减 5000 库存,但是数据库只有 4996 了,那么通过递归的形式有多少扣减多少
=_= 回复 马丁:但是5000这个值不是在excel监听那里执行lua脚本得到的set大小吗?为什么缓存库存够,数据库不够呢
马丁 回复 =_=:缓存的数值并不能完全可信,参考 AOF 丢指令和集群主从同步丢数据场景
马哥,那个扣减优惠卷模版库存量还有添加分发用户信息的那个LUA脚本不太明白;里面local userSetLength的值只会维持在0-5000吗? 是因为 每5000个数据发送一次消费消息,然后消息消费者消耗redis中的分发用户信息记录(减5000)才导致LUA脚本中每次获取userSetLength都是在0-5000以内吗?如果这么一个情况:现在扫描到第5001行数据,前面5000行数据的时候已经发送消息到消息队列了,但是还没有减库存量,那岂不是现在的userSetLength读取到的就是5001了? 那获取第二个字段的值就是5001,岂不是又会发送一次消息给消息队列? 除非是可以保证这么一个顺序1.redis中分发用户信息的key的数据长度为5000 2.发消息给消息队列。3.消费者消费消息队列减5000. 这样现在用户信息key数据长度为0又能重新统计了。 有点困扰这里
2024-09-07 22:45
马丁 回复 Yan.:问题提的很赞👍 main 分支里没有这个问题,rebuild 我忽略了,我理解加一个取模判断就好,详情如图
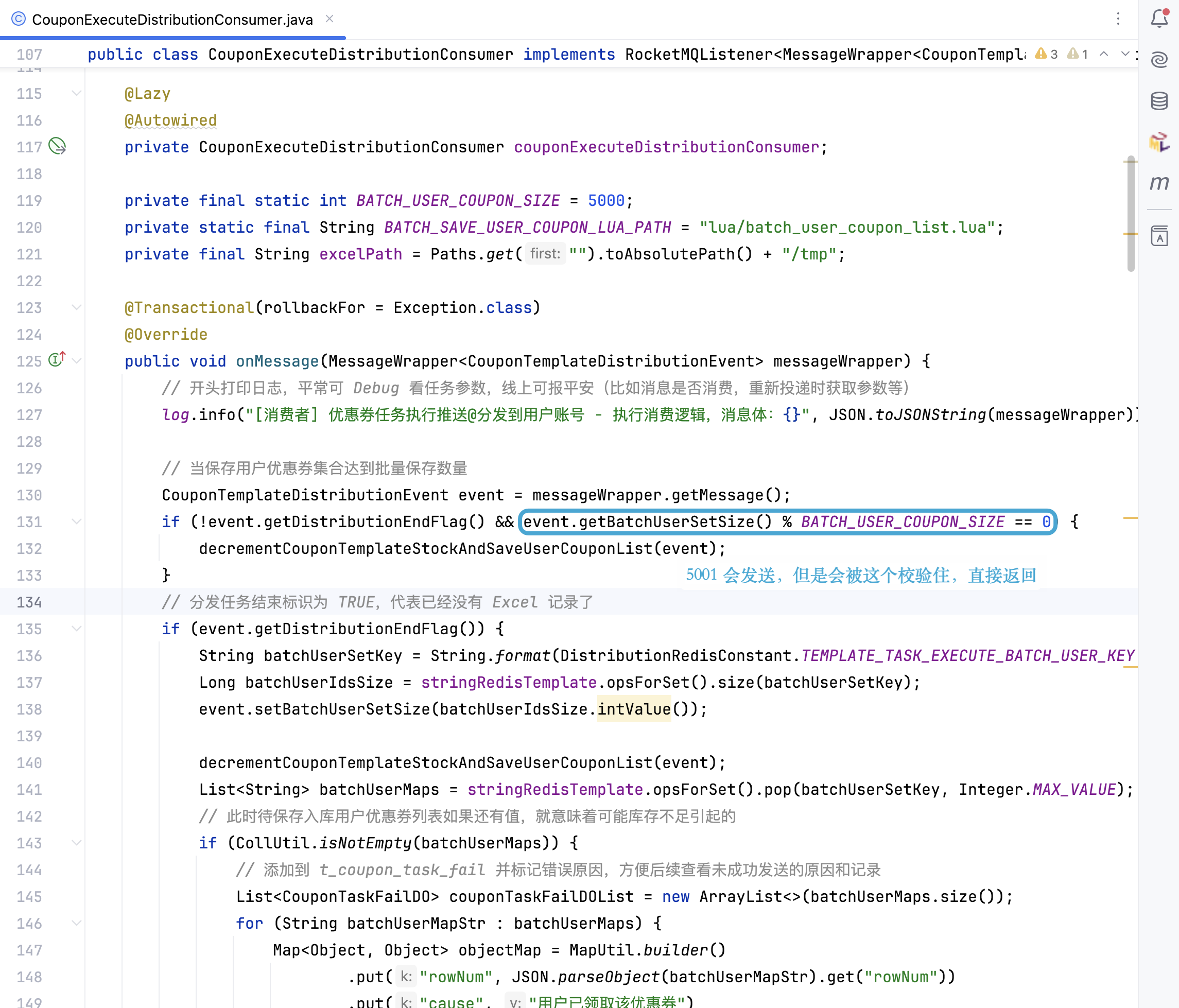
aalwayss_ 回复 Yan.:加入有5001条数据 前5000条信息已经被投到消息队列了 此时有三种情况: 1.前5000条数据已经被rocketMq开始处理,但是此时库存总量不足以分配全部(缓存不准的情况) 假设只分配一个用户 此时excel扫描到5001行数据并且set中用户数量再次达到5000会再次发送rocketmq但仍然会遇到数据库优惠券库存不足情况发生 如果分配了4900个用户此时扫描到5001行也不会触发发送rocketmq的条件, 只能等待结束扫描再次发送信息到消息队列但是因为优惠券库存不足不会进行分发优惠券而返回 //2.前5000条数据已经被rocketMQ开始处理,而且数据充足已经被set中移除,此时扫描到5001行数据时,因为set的总数量不足5000而不会发送消息到消息队列,等到excel结束扫描再发送信息到消息队列,完成剩余优惠券分发 //3.前5000条数据没有被rocketMQ开始处理,此时扫描到5001行时,因为set中的数据量超过5000,会再次发送消息到消息队列,但是因为发送的是顺序消息队列,因此当第一条消息开始消费时,如果优惠券库存充足则分发,而第二个到来的消息的数据量是5001(只有对5000取模为0或者扫描excel结束才会处理)不会被消息队列处理,等到excel完成扫描,再发送消息到消息队列,最后一次消息对会带数据量是多少,直接取出set中的所有数据,也就是5001条数据,最后一条消息得到处理 end
鹅鹅鹅 回复 aalwayss_:那为什么最后一条消息要直接把set里所有数据取出来?在解析的时候算好最后还剩多少然后发到消息队列,不就不会有这个多扣的问题了吗?
分享一下自己梳理的逻辑 首先看admin后管中的执行流程 1.CouponTemplateServiceImpl类 执行createCouponTemplate方法创建了优惠券,然后让该优惠券信息存入数据库 2.CouponTaskServiceImpl类 执行createCouponTask方法创建优惠券分发任务,然后让该优惠券分发任务存入数据库 这个任务是分发指定的优惠券给Excel中的用户,统计Excel中的行数是通过线程池异步执行的。 如果分发任务是立即发送,那状态就是执行中,如果不是立即发送,也就是定时发送,那状态就是待执行 如果是立即发送,就通过mq发送该分发任务id 再来看distribution分发的流程,注意我们分发的时候,是分发指定的优惠券给Excel中的用户 也就是优惠券id在这个流程中是确定的 1.CouponTaskExecuteConsumer类 执行onMessage消费mq中的消息,获取分发任务id 然后根据id从数据库中查询该任务 判断任务状态是否是执行中,如果不是执行中,那就说明还不该执行 如果任务是执行中,那就判断优惠券状态是否正确,也就是看优惠券是生效还是结束 如果优惠券生效,那就开始执行优惠券推送任务/分发任务
花开富贵 回复 浮语虚辞:2.ReadExcelDistributionListener类 每获取一行Excel中的数据就会执行invoke一次 先来说消费点位 invoke中先获取消费点位,也就是从缓存中获取TEMPLATE_TASK_EXECUTE_PROGRESS_KEY+couponTaskId的值 如果消费点位不为空并且大于当前分发任务处理的行数rowCount的话,那就说明之前宕机过,也就是点位之前的都执行过了 所以如果满足这种情况就直接return并且让rowCount++,直到rowCount大于消费点位,此时rowCount就表示要处理的行数 再来说缓冲的概念(分批的概念) v1版本中我们执行invoke一次只会处理一行数据,因此会造成磁盘IO网络延迟等问题,这里我们一批一批的进行处理 首先执行stock_decrement_and_batch_save_user.lua脚本,每次执行invoke方法都会让该lua脚本执行一次 给lua脚本传入的参数中,key包含优惠券模板key也就是couponTemplateKey还有缓冲队列的key也就是batchUserSetKey,value是一个存储userId以及在excel中对应行数rowNum的转为json的map lua脚本首先获取优惠券缓存中的库存 如果库存为空或者小于0,那就直接返回(false, 缓冲队列中存储的数量) 如果库存大于0,那就让库存减1,然后让value也就是userId以及rowNum存入到缓冲队列中(其实就是一个set中) 然后返回(true, 缓冲队列的长度) 如果没有库存的话,那之后的数据在执行invoke的时候也是没有库存的,所以我们需要让后面分发失败的数据给记录到数据库中,此时也要让处理到的行数rowCount++,因为记录失败也算处理,然后一行一行的return 如果还有库存的话,那就看缓冲队列的长度是否达到我们设置的批次大小BATCH_USER_COUPON_SIZE 如果没有达到我们设置的批次大小,那就只更新一下缓存的消费点位,然后让rowCount++即可,简而言之,放到缓冲队列也算处理 如果达到我们设置的批次大小,那就要开始对这个批次进行优惠券的分发了,此时就要给MQ发送一条消息(包括分发任务id、优惠券模板id、批次id、批次大小、分发任务结束标识false) excel处理到最后才会执行doAfterAllAnalysed方法,该方法也是给MQ发送一条消息(包括分发任务id、优惠券模板id、批次id、分发任务结束标识true),此时没有发送批次大小,而是后面统计了一下(这里不太明白)
花开富贵 回复 浮语虚辞:3.CouponExecuteDistributionConsumer类 该消费者就是用来消费ReadExcelDistributionListener类发送的消息的,直接看onMessage方法即可 首先获取消息,然后看消息中分发任务标识是否为false 先来看分发任务标识为false的情况 如果为false并且消息中批次大小%BATCH_USER_COUPON_SIZE==0,那就表示后续还有数据没处理,并且当前缓存了一个批次的用户数据了,所以直接先处理这个批次的数据 然后直接执行decrementCouponTemplateStockAndSaveUserCouponList方法进行分发,这个方法才是真正干活的方法,传入的参数是CouponTemplateDistributionEvent event 该方法首先执行decrementCouponTemplateStock进行库存的扣减,传入的参数是CouponTemplateDistributionEvent event以及event中的批次大小 decrementCouponTemplateStock方法通过乐观锁机制来进行库存的扣减,扣减失败就从数据库中查询最新的库存,然后递归调用自身用当前库存数量重新扣减,递归的目的是为了缩小扣减数量,直到库存扣减或库存为0 decrementCouponTemplateStock方法最终返回的是实际扣减的数量,然后赋值给couponTemplateStock 如果couponTemplateStock小于等于0,表示库存不够了,那就decrementCouponTemplateStockAndSaveUserCouponList方法直接return退出不干活 如果couponTemplateStock大于0,表示扣减成功了couponTemplateStock个(可能并不是都扣减成功了) 那就从缓冲队列里面pop出couponTemplateStock个数据,赋值给List<String> batchUserMaps,因为couponTemplateStock个肯定都是扣减成功的,所以可以放心处理 处理的方式就是,遍历这个集合,然后转回map(因为存入的时候就是存储userId以及在excel中对应行数rowNum的转为json的map) 然后让对应的行号、用户id、优惠券id、领取数量也就是1等信息构建为UserCouponDO类然后存入List<UserCouponDO> userCouponDOList集合中,最后批量插入用户优惠券表中(也就是执行batchSaveUserCouponList方法),这就表示领取成功了
花开富贵 回复 浮语虚辞:batchSaveUserCouponList方法也很有考究,直接执行userCouponMapper.insert(userCouponDOList, userCouponDOList.size())方法进行批量插入 如果批量插入有错,那就通过一条一条插入执行,所以遍历userCouponDOList来进行插入。如果单挑插入也失败的话,那就执行hasUserReceivedCoupon看用户是否领取过优惠券 如果已经领取过了,那就让该条记录的行号以及对应错误原因也就是用户已领取该优惠券加入到List<CouponTaskFailDO> couponTaskFailDOList中,最后批量插入数据库 因为用户已经领取过了,那就添加到List<UserCouponDO> toRemove表示已经处理过了,之后要在List<UserCouponDO> userCouponDOList集合中移除 所以执行完batchSaveUserCouponList方法之后,此时userCouponDOList已经剔除了重复的或者已经添加的记录,然后将这些优惠券领取记录添加到缓存中, 因为数据库层面加入用户优惠券记录已经在上面做了,这里就是执行batch_user_coupon_list.lua脚本 再来看分发任务标识为true的情况 分发任务结束标识为true标识没有Excel记录了,说明Excel数据读取结束,整个分发流程走到了最后阶段,需要处理剩下的缓冲队列中没有发出去的用户数据 首先获取这个批次的数据数量,然后赋值给event 然后执行decrementCouponTemplateStockAndSaveUserCouponList方法进行分发,过程不在赘述,和上面一样,最后就是让分发优惠券成功的数据给存入用户优惠券表中 然后再从缓冲队列里面pop出Integer.MAX_VALUE个数据,也就是全部pop出去,这些就是不能够正确处理的,也就是库存不足或者用户已经领取优惠券的原因, 而执行batchSaveUserCouponList的时候已经让用户领取优惠券的情况给考虑进去了,所以这里的原因就是库存不足,然后让领取失败的记录给批量存入数据库中 执行到最后,让该分发任务状态改为已完成,并且更新相应字段即可
。 回复 花开富贵:‘如果couponTemplateStock小于等于0,表示库存不够了,那就decrementCouponTemplateStockAndSaveUserCouponList方法直接return退出不干活’那这些不应该也插入到用户分发失败表中吗?这里好像什么也没处理
疑问:文中说了使用顺序消息,但是代码中没有看到哈希选择队列的代码。顺序消息是怎么用的?
o3o 回复 int main():发送消息的时候,重写MessageSelector类即可 就可以发到指定队列
int main() 回复 o3o:挺麻烦,我直接用springboot的api,这个里面的选择队列算法默认就是取模
o3o 回复 int main():很简单呀 就几行搞定
O泡果奶 回复 o3o:请问代码里顺序消息咋做的,没看啥处理呀,是单队列吗
int main() 回复 o3o:其实,springboot集成的mq,里面队列选择的方法默认就是哈希取模,直接用就行了
鹅鹅鹅 回复 O泡果奶:直接用带orderly的那个方法,指定个分片键,然后消费者配顺序消费模式
我有一个疑问,看代码逻辑应该是每读取一行excel就执行一次lua,实时扣减库存,但是只有领券记录长度达到5000才一次性批量写入数据库,这样看mysql的更新相当于延迟的,那如果中途宕机了,redis已经扣减了库存但mysql并未执行,这样是不是会导致库存数据和数据库中数据不同步呀
孤远 回复 Fortitude:中途宕机的话,会导致消费者未能正常消费消息,但后面还会再次消费这条信息的
int main() 回复 Fortitude:哥们儿,你不觉得这个处理逻辑有问题吗?读文件是单线程的,后面批处理的意义不是特别大啊,而且easyexcel的重写方法的第二个参数就是分析容器,可以获取当前进度条的行号和sheet号
int main() 回复 Fortitude:压根就没必要各种++计算
Fortitude 回复 孤远:那这里是不会有不一致风险吗
Fortitude 回复 int main():你的意思是redis扣减库存的时候也不一个一个减吗?
int main() 回复 Fortitude:有必要吗?
int main() 回复 Fortitude:直接把list长度扣减就好了
int main() 回复 Fortitude:而且读easyExcel也应该用线程池批处理,哪有单线程读文件,然后一顺撇都是顺序消费的?单线程处理百万数据?
Fortitude 回复 int main():对。。。这个疑问我也有。。。
Fortitude 回复 int main():感觉单线程一行一行读有点怪
int main() 回复 Fortitude:你放心,普通win系统的13900及以下的CPU压根跑不出马哥的性能,我跟师兄优化了好久才把速度提升几十倍
Fortitude 回复 int main():所以你们测出来的速度是多少哇
int main() 回复 Fortitude:六七分钟吧,就能分发完百万数据
看了两三遍算是看懂了,整个执行流程大概是这样 : (1)->(上一章的内容)后管服务创建分发任务表插入到数据库 -> 统计excel行数 -> 将行数插入优惠券分发任务表 ->发送定时消息或延时消息执行给分发引擎服务执行分发任务。 (2) -> 校验消费者拿到消息并进行校验 -> 使用easyexal读取 -> Easyexcel监听类 记录执行点位 、执行缓存扣减,记录批量数据到缓存 -> 批量达到5000,发送消息给分发消费者 -> 分发消费者拿到消息(顺序执行) -> 批量保存到数据库 ->要是库存不足,批量记录到发放失败表 -> 更新分发任务表的完成时间
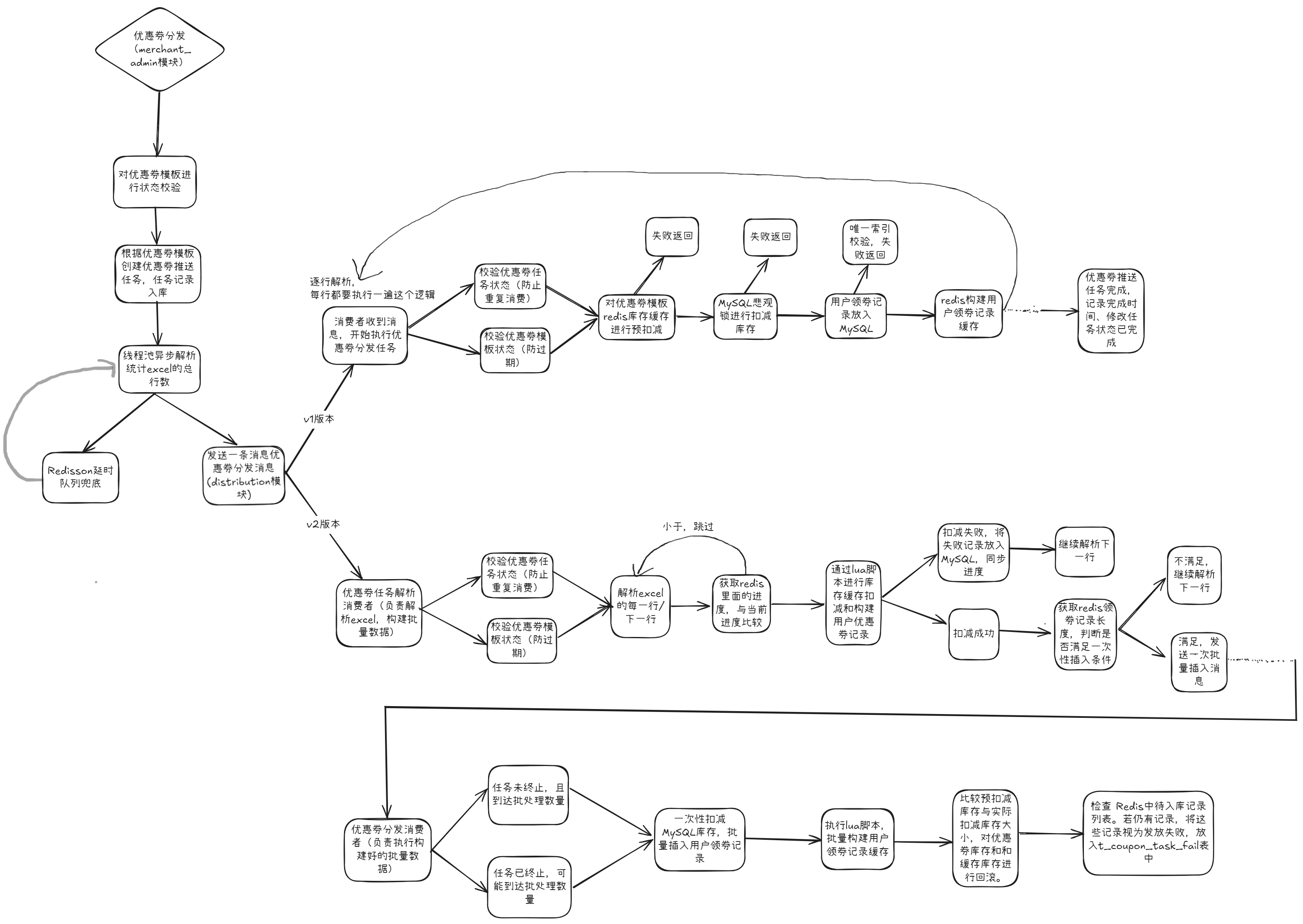
大体的思路就是将用户是否已领过券的判断提前,不要在批量插入异常时再做处理,由于我的代码跟马哥的不太一样,改了一些东西,大家可以对照着看一下。
先上测试结果,分发给1000个用户,其中有20个用户已领过该券,预期结果分发成功980张,coupon_distribution_task_fail表中新增20条发放失败的记录,缓存和数据库中优惠券库存剩余20张。
首先创建一张优惠券,缓存和db中的库存都为20;
从1000个用户中抽20个用户先执行一下推送任务,分发成功后会向缓存user-gained-coupon写入用户领券记录;
为这张券新增1000张库存,再次执行推送任务,缓存和db中的库存都变成了20,coupon_distribution_task_fail表中多了20条记录,正是之前领过券的用户;

执行时间37ms(可能是因为之前请求过一次的原因,第一次执行是在700ms);
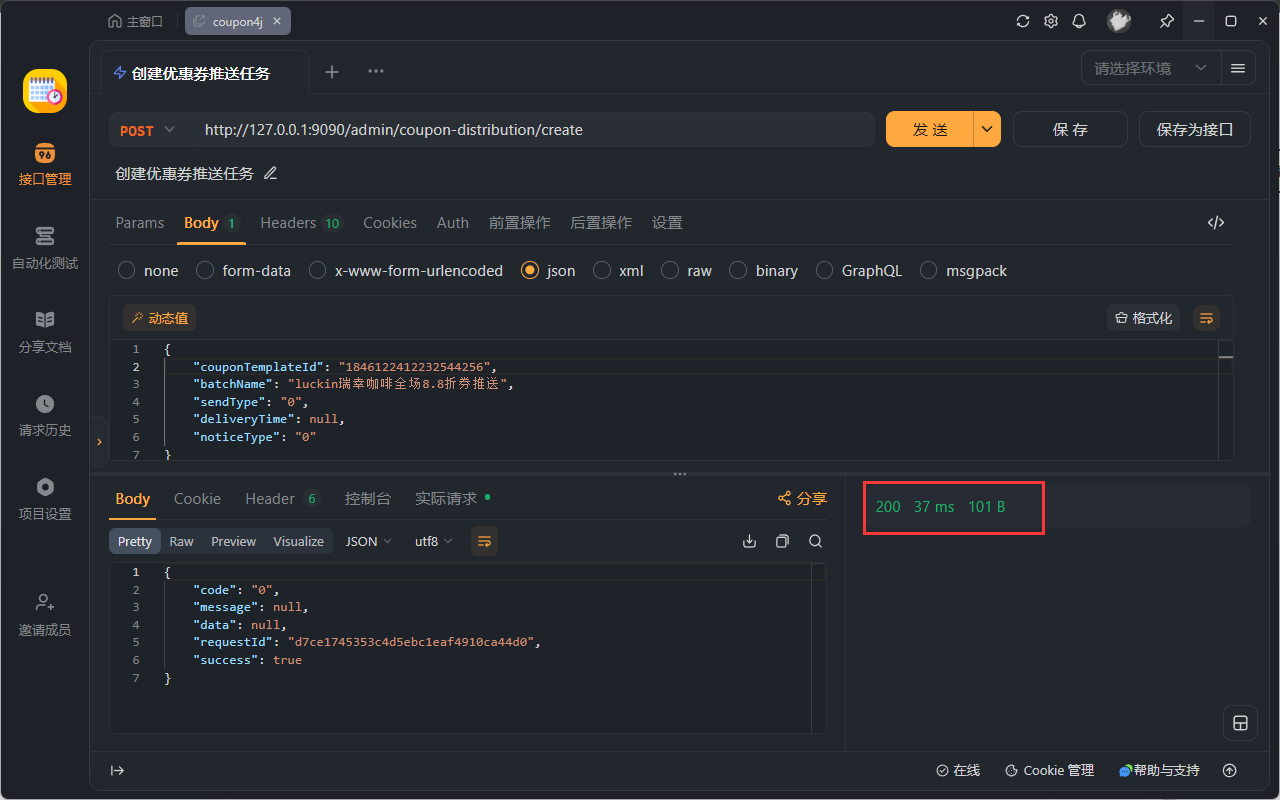
代码主要分为ExcelDistributionListener(读取excel每一行数据,做一些前置工作)和CouponDispenseConsumer(真正执行分发)
@RequiredArgsConstructor public class ExcelDistributionListener extends AnalysisEventListener<CouponDistributionUserExcelBO> { private final CouponTemplateDO couponTemplateDO; private final RedisProxy redisProxy; private final CouponDistributionFailMapper couponDistributionFailMapper; private final CouponDistributionTaskDO taskDO; private final CouponDispenseProducer couponDispenseProducer; /** * 跳过标题,从第2行开始读excel */ private long rowRecord = 2; /** * 分批次执行的大小 */ private static final int BATCH_SIZE = 200; /** * 分发失败记录的暂存区 */ private final List<CouponDistributionTaskFailDO> failRecordCacheList = new ArrayList<>(BATCH_SIZE); @Override public void invoke(CouponDistributionUserExcelBO excelData, AnalysisContext context) { String couponTemplateKey = StrUtil.join(":", "coupon-template", couponTemplateDO.getId()); String processKey = StrUtil.join(":", "coupon-distribution-process", taskDO.getId()); if (redisProxy.exist(couponTemplateKey)) { // 获取当前执行进度,优化因系统重启或宕机而重复执行分发 String point = redisProxy.get(processKey, String.class); if (point != null && Integer.parseInt(point) >= rowRecord) { rowRecord++; return; } // 获取lua脚本对象并保存到单例容器,优化每次都需要重新创建脚本对象 DefaultRedisScript<Long> luaScript = Singleton.get(AdminConstantPool.COUPON_DISTRIBUTION_TASK_LUA_SCRIPT, () -> { DefaultRedisScript<Long> script = new DefaultRedisScript<>(); script.setScriptSource(new ResourceScriptSource(new ClassPathResource(AdminConstantPool.COUPON_DISTRIBUTION_TASK_LUA_SCRIPT))); script.setResultType(Long.class); return script; }); String batchUserReceiveCouponKey = StrUtil.join(":", "user-coupon-collection", taskDO.getId()); String userId = excelData.getUserId(); Map<Object, Object> userRowNumMap = Collections.emptyMap(); // 计算用户领券集合缓存分片键并判断当前用户是否已经领过该优惠券 int mod = (Long.valueOf(userId).hashCode() & Integer.MAX_VALUE) % 5; String key = StrUtil.join(":", "user-gained-coupon", mod); String hashKey = StrUtil.join("-", userId, couponTemplateDO.getId()); // 如果已领取过则将其保存为发券失败的记录 if (redisProxy.getTemplateInstance().opsForHash().hasKey(key, hashKey)) { Map<Object, Object> contentMap = MapUtil.builder() .put("userId", userId) .put("cause", "用户已领取过该优惠券") .build(); CouponDistributionTaskFailDO taskFailDO = CouponDistributionTaskFailDO.builder() .batchId(taskDO.getBatchId()) .content(JSONUtil.toJsonStr(contentMap)) .build(); failRecordCacheList.add(taskFailDO); } else { userRowNumMap = Collections.singletonMap("userId", userId); } if (userRowNumMap.isEmpty()) { // 检查一下失败记录暂存区的大小,及时进行批处理,防止在极端情况下堆积大量失败记录导致ArrayList扩容 if (failRecordCacheList.size() % BATCH_SIZE == 0) { couponDistributionFailMapper.insert(failRecordCacheList); failRecordCacheList.clear(); } return; } // 扣减缓存中的优惠券库存以及新增记录到用户领券集合 Long combineInt = redisProxy.getTemplateInstance().execute(luaScript, Arrays.asList(couponTemplateKey, batchUserReceiveCouponKey), JSONUtil.toJsonStr(userRowNumMap)); assert combineInt != null; boolean hasInventory = BinarySplitUtil.extractFirstField(combineInt); if (!hasInventory) { failRecord(processKey, userId, "缓存中优惠券库存不足"); return; } int setSize = BinarySplitUtil.extractSecondField(combineInt); if (setSize < BATCH_SIZE) { syncProcess(processKey); return; } // 通知另一个消费者执行分发,避免单条消息消费时间过长,这里取模可以保证每5000为一个批次的发消息,最后不足5000的交给后置逻辑来处理 if (setSize % BATCH_SIZE == 0) { CouponDispenseMessage messageEvent = CouponDispenseMessage.builder() .taskId(taskDO.getId()) .shopId(couponTemplateDO.getShopId()) .couponTemplateId(couponTemplateDO.getId()) .taskBatchId(taskDO.getBatchId()) .batchSetSize(BATCH_SIZE) .endFlag(false) .build(); couponDispenseProducer.sendOrderlyMessage(messageEvent); } syncProcess(processKey); } else { failRecord(processKey, null,"优惠券缓存失效"); } } @Override public void doAfterAllAnalysed(AnalysisContext context) { CouponDispenseMessage messageEvent = CouponDispenseMessage.builder() .taskId(taskDO.getId()) .shopId(couponTemplateDO.getShopId()) .couponTemplateId(couponTemplateDO.getId()) .taskBatchId(taskDO.getBatchId()) .endFlag(true) .build(); couponDispenseProducer.sendOrderlyMessage(messageEvent); if (!failRecordCacheList.isEmpty()) { couponDistributionFailMapper.insert(failRecordCacheList); failRecordCacheList.clear(); } } /** * 保存分发失败的记录 * @describe 批量执行最保险的方法应该是发mq,但正常执行几乎不可能会分发失败 */ private void failRecord(String processKey, String userId, String cause) { Map<Object, Object> contentMap = MapUtil.builder() .put("userId", userId) .put("cause", cause) .build(); CouponDistributionTaskFailDO couponDistributionTaskFailDO = CouponDistributionTaskFailDO.builder() .batchId(taskDO.getBatchId()) .content(JSONUtil.toJsonStr(contentMap)) .build(); failRecordCacheList.add(couponDistributionTaskFailDO); if (failRecordCacheList.size() % 100 == 0) { couponDistributionFailMapper.insert(failRecordCacheList); failRecordCacheList.clear(); } syncProcess(processKey); } /** * 同步执行进度到缓存 */ private void syncProcess(String processKey) { redisProxy.set(processKey, String.valueOf(rowRecord)); rowRecord++; }
@Component @RequiredArgsConstructor @Slf4j @RocketMQMessageListener( consumerGroup = AdminConstantPool.COUPON_DISPENSE_CG, topic = AdminConstantPool.COUPON_DISPENSE_TOPIC, consumeMode = ConsumeMode.ORDERLY ) public class CouponDispenseConsumer implements RocketMQListener<CouponDispenseMessage> { private final RedisProxy redisProxy; private final CouponTemplateMapper couponTemplateMapper; private final UserCouponMapper userCouponMapper; private final CouponDistributionMapper couponDistributionMapper; @Override @Transactional(rollbackFor = Exception.class) public void onMessage(CouponDispenseMessage messageEvent) { log.info("[消费者] 优惠券分发到用户,消息体:{}", JSONUtil.toJsonStr(messageEvent)); // 非结束标识的batchSetSize已经存在,可以直接进行后续逻辑的处理 if (!messageEvent.isEndFlag()) { handler(messageEvent); return; } // 获取当前用户领券集合的大小 String batchUserReceiveCouponKey = StrUtil.join(":", "user-coupon-collection", messageEvent.getTaskId()); Long userReceiveCouponSetSize = redisProxy.getTemplateInstance().opsForSet().size(batchUserReceiveCouponKey); // 用户领券集合缓存为空的情况:1.缓存失效 2.缓存中优惠券库存不足 3.最后这批用户都已领过该优惠券 if (userReceiveCouponSetSize == null || userReceiveCouponSetSize == 0) { updateTaskStatus(messageEvent); return; } messageEvent.setBatchSetSize(userReceiveCouponSetSize.intValue()); handler(messageEvent); } /** * 分发券的处理 */ @SneakyThrows private void handler(CouponDispenseMessage messageEvent) { Integer couponTemplateInventory = decrementInventory(messageEvent); if (couponTemplateInventory == 0) { RocketMQLogUtil.consumeFailure("优惠券分发到用户", messageEvent, "优惠券库存为空"); return; } String batchUserReceiveCouponKey = StrUtil.join(":", "user-coupon-collection", messageEvent.getTaskId()); // 扣减了多少张库存就从用户领券集合中pop出多少个待领券的用户信息 List<String> userAndRowMap = redisProxy.getTemplateInstance().opsForSet().pop(batchUserReceiveCouponKey, couponTemplateInventory); if (userAndRowMap == null) { RocketMQLogUtil.consumeFailure("优惠券分发到用户", messageEvent, "缓存中用户领券集合为空"); return; } // 初始化用户领券实体集合并指定大小,避免ArrayList扩容开销 List<UserCouponDO> userCouponDOList = new ArrayList<>(couponTemplateInventory); userAndRowMap.forEach(item -> { JSONObject recordObject = JSONUtil.parseObj(item); UserCouponDO userCouponDO = UserCouponDO.builder() .userId(recordObject.getLong("userId")) .couponTemplateId(messageEvent.getCouponTemplateId()) .source(UserCouponSourceEnum.PLATFORM) // 只有平台才有权限获取用户隐私数据以及向用户派发券 .status(UserCouponStatusEnum.UNUSED) .receiveCount(1) // 平台券限领1张 .build(); userCouponDOList.add(userCouponDO); }); // 批量新增用户领券记录 batchSaveUserCouponList(messageEvent, userCouponDOList); StringBuilder stringBuilder = new StringBuilder(); // 将用户领券记录保存到缓存中 Map<Object, Object> valMap = MapUtil.builder() .put("count", 1) // 领券次数 .put("date", DateUtil.date()) // 领券时间 .build(); userAndRowMap.forEach(each -> { Long userId = JSONUtil.parseObj(each).getLong("userId"); // 取hashCode后按位与保证其值为正 int mod = (userId.hashCode() & Integer.MAX_VALUE) % 5; String key = stringBuilder.append("user-gained-coupon").append(":").append(mod).toString(); stringBuilder.setLength(0); String hashKey = stringBuilder.append(userId).append("-").append(messageEvent.getCouponTemplateId()).toString(); redisProxy.hashSet(key, hashKey, JSONUtil.toJsonStr(valMap)); stringBuilder.setLength(0); }); // 确保全部分发完毕后更新推送任务的状态 if (messageEvent.isEndFlag()) { updateTaskStatus(messageEvent); } } /** * 扣减优惠券库存 * @return 扣减的库存数量 */ private Integer decrementInventory(CouponDispenseMessage messageEvent) { int res = couponTemplateMapper.decrementCouponTemplateInventory(messageEvent.getCouponTemplateId(), messageEvent.getShopId(), messageEvent.getBatchSetSize()); // 库存不足导致扣减失败,需要重新获取可扣减的库存量,尽量让能发的券分发到用户 if (res == 0) { LambdaQueryWrapper<CouponTemplateDO> queryWrapper = Wrappers.lambdaQuery(CouponTemplateDO.class) .select(CouponTemplateDO::getInventory) .eq(CouponTemplateDO::getShopId, messageEvent.getShopId()) .eq(CouponTemplateDO::getId, messageEvent.getCouponTemplateId()); CouponTemplateDO couponTemplateDO = couponTemplateMapper.selectOne(queryWrapper); // 若库存已经为0则直接返回 Integer inventory = couponTemplateDO.getInventory(); if (inventory == 0) return 0; // 进行递归扣减 messageEvent.setBatchSetSize(inventory); return decrementInventory(messageEvent); } return messageEvent.getBatchSetSize(); } /** * 批量新增用户领券记录 */ private void batchSaveUserCouponList(CouponDispenseMessage messageEvent, List<UserCouponDO> userCouponDOList) { try { userCouponMapper.insert(userCouponDOList); } catch (Exception ex) { Throwable cause = ex.getCause(); if (cause instanceof BatchExecutorException) { // 捕获唯一索引异常并记录日志 RocketMQLogUtil.consumeFailure("优惠券分发到用户", messageEvent, ex); } throw new ServiceException(MerchantErrorCodeEnum.SERVICE_UPDATE_ERROR); } } /** * 更新推送任务状态 */ private void updateTaskStatus(CouponDispenseMessage messageEvent) { LambdaUpdateWrapper<CouponDistributionTaskDO> updateWrapper = Wrappers.lambdaUpdate(CouponDistributionTaskDO.class) .eq(CouponDistributionTaskDO::getId, messageEvent.getTaskId()) .set(CouponDistributionTaskDO::getStatus, CouponDistributionStatusEnum.SUCCESS); if (couponDistributionMapper.update(updateWrapper) == 1) { // 清理excel读取进度缓存 String processKey = StrUtil.join(":", "coupon-distribution-process", messageEvent.getTaskId()); redisProxy.remove(processKey); RocketMQLogUtil.consumeSuccess("优惠券分发到用户", messageEvent); return; } RocketMQLogUtil.consumeFailure("优惠券分发到用户", messageEvent, "更新推送任务状态失败"); }
假如excel一共有6000条数据,扫描到5000的时候发送消息到消息队列,然后一直执行到6000,这中间的假如消费者还没开始进行消费,中间会连续产生1000条消息到消费者 他们的event要消耗的库存分别是5000,5001,5002,。。。6000以及doAfter产生的6000[这里的distributionEndFlag是true]。 然后开始消费, 第一条消息(5000)正常扣库存5000,5001...5999,6000都会因为if (event.getDistributionEndFlag()) 和event.getBatchUserSetSize() % BATCH_USER_COUPON_SIZE == 0被剔除,但是由于doAfter产生的6000的endFlag是True,所以他会通过第二图的代码,由于Integer couponTemplateStock = decrementCouponTemplateStock(event, event.getBatchUserSetSize());因为这个返回的couponTemplateStock=Min(event中要消耗的数量=6000,数据库余额) ,在这一步 会消耗大量的数据库库存吗?
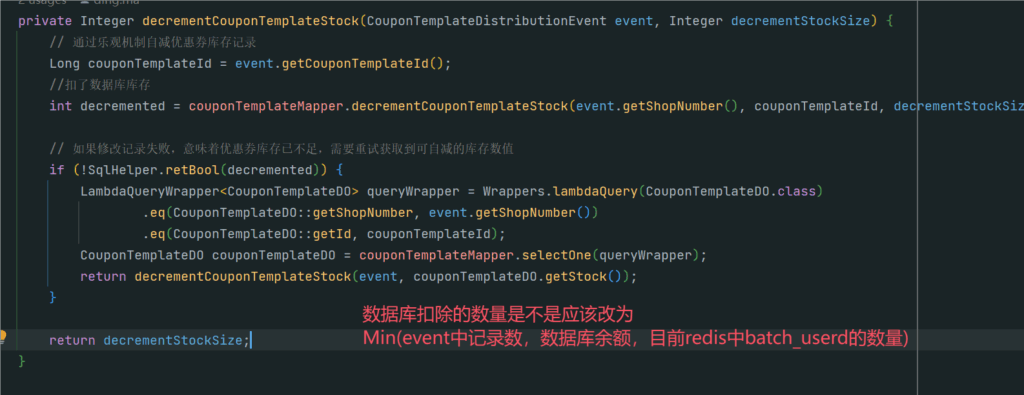
doAfter是根据目前redis中剩余未分发的人数来扣库存的 所以不会大批量多扣了

一开始没看到最后,后面其实说了要顺序消息,所以根本原因应该是因为消息是顺序消费的吧,如果不是顺序消费的,上一个批次的5000条还没有从redis剩余未分发的人数中pop出来,假设第5001条就分发完了,那么扣减的库存数量还是5001,就还是会多扣
那 5001 到 5999 这些是不是都作为消息发送了,但是都由于if (event.getDistributionEndFlag()) 和event.getBatchUserSetSize() % BATCH_USER_COUPON_SIZE == 0)被过滤了,也不就是说这些都是无用的消息吗,这不浪费吗,每 5 千条才有 1 条有用的消息;我觉得这里应该改成取模判断,而不是小于,这样就可以避免了




Comments NOTHING