


- 第01节:布隆过滤器比分布式锁性能高多少倍?
首先把Sentinel注释掉,因为要压榨性能,在ShortLinkController里面,还有SentinelRuleConfig;通过分布式锁创建短链接,本意是只做布隆过滤器的转换,因此没有其他的。
本意是只做布隆过滤器的替换,没有其他的,这里ShortLinkServiceImpl有一个generateSuffixByLock的方法,还有createShortLinkByLock新增(feature:添加短链接分布式锁和布隆过滤器性能比对)
那么,byLock方法干了什么呢?我又生成了一个方法,他是怎么做的对吧?
一般来说我们上面这里面有加一个分支锁,通过分支锁的形式,然后在这里去获取它怎么去获取。我们创建出来一个short URI之后对吧?我们去数据库里去查查看它是否存在,如果不存在的话,我们就让它跳出就证明可以用,对不对?
为此的话我们这边来测一下它的性能到底有多牛,好吧?我们先通过逻辑来判断一下,首先我们通过布隆过滤器它是并发的存在,对吧?假如说同时有很多的请求来访问,那么这些请求都是可以同时去看空,并且去做一些新增的操作的;
分布式锁大家可以看到我们这里面是没有任何参数的,相当于说是一个全局KEY,通过这种方式(SHORT_LINK_CREATE_LOCK_KEY)我们能够保证它的短链接是全局唯一的,对吧?所以说通过这种方式是能够避免重复生成,但是它的问题是很明显的,它会将布隆过滤器的并行改成串行化,对,所以说这也是为什么我说性能提高很多。
大家如果说学过guc的,就知道这种最基本的一些东西对吧?并行和串行孰高孰低还是能够清楚的对吧?那为此的话就是我们口说无凭对不对?
为此我们这边通过JMeter来压测一下,首先先把相关的数据清掉,然后我重新跑一下,因为刚才其实是有一些缓存存在的,ok我们以最新的记录去测试,然后我先apifox调一次创建短链接,然后我们把检测打开,然后开始测试。
首先我们先测布隆过滤器,然后我们现在线程组是40,40个线程数,然后循环100次,也就刚开始有点慢,我先跟大家讲现在其实性能是有瓶颈的对吧?至于为什么我等会跟大家说。
为了保障我们不会在这个视频里面调用这个方法耗费太长时间,所以我把它给改成10好吧?然后我们改一下,我们先测过滤器,这边有这个报告,看到没有?它的吞吐量上不去,才13,ok。
这样说的话我可以线程改成40感觉,因为就没必要执行完对不对?Ok我改成40之后,我看他有没有好转。没啥好转对吧?还是12、13,上不去也下不来,基本上就维持在12左右,ok我就没必要再跑了。
好,这样的话我们布隆过滤器这种形式看到没掉的对吧?我们是直接调到短链接的服务,短链接的中台服务,然后没有调用聚合,因为聚合里面它也有叫什么,对忘了刚才忘了跟大家说件事情,聚合里面它也有一点的,他不是会做后管的拦截,所以说我们这个里面也要把如果说,你要启动后管的话,你就要把对应的限流给关掉,其实我们这里面的话其实直接去压稍微立刻ok的话,就是不需要这一块我给他还原掉。
为了避免大家的一些干扰,所以我就还原掉了。我们这边继续。
然后我们再试一下分布式锁的形式,我们把它进行一下,然后再把它启用。行。看到没有?他连布隆过滤器器还不如对吧?他才7点多,也是上不去的一个情况;
为此的话我非常苦恼,我做了一件什么事情,就是我在那挨个去进行各种注释,比如我想把我当时想的是什么,我当时想的是会不会是因为我的数据库新增比较慢对吧?是不是这种情况?
然后我把本地的给关掉之后,我把我的代码部署到云服务器上,我自己有一台4C16G的云服务器其实基本还OK的然后我去试了一下,还是不行,然后我就在想那可能就不是资源问题,了,然后我就做了一些各种注释对吧?
然后首先这种各种注释,然后直到最后他依然是100多毫秒一个这种执行,所以说我就比较苦恼,然后我就开始全局这个代码对吧?当出现这种大家认为匪夷所思的事情,往往是隐藏在细节里面的,比如说我review这个时候发现了一个获取图标的话就比较慢。
然后我们来领略一下,我们把这里面也给它注释掉,注释掉之后会让大家知道什么叫飞一般的感觉。Ok老规矩我们先调一下bylock。因为这种要比较某个性能很牛,肯定是先要一个没那么牛的对吧?再往后慢慢的引出来对不对?
我们先调查他,然后他平均的话看到没有,响应时间就下了15毫秒,对。好,我们用JMeter压一下,都没有吞吐量马上就上来了,而且这种量在422,这样的话我们就可以断定对吧?刚才的有很大的系统问题,可能有人说马哥它是不是没新增的数据库,是不是你把这些对吧?没有新增成功,ok我们这边刷奖现在是48,382,正常应该是5万。
拆掉。52,000对吧?那就证明它是新增的数据库了的好吧?基本上我们去测试相关的代码的话,Log这一块基本上就到这里就结束了,然后我们可以去截个图,怎么截图,我感觉他这个挺操蛋的。所以说我得把我的评价对,我得把我的评价弄出来对不对?
我们给他截个图,然后待会找到医学库里面我要找到链接,然后再加一个,为什么说不用过滤器,性能远胜于怎么支付。开头的话,然后为了比较公平,我们这边多压几次,然后给出来一个就是三三三个的话去掉,同学中间好吧我们再来一下,基本上不会有特别大的差距的。Ok right.
然后到现在的话,我们就来带大家再看一下布隆过滤器是什么什么样的一个震撼?我们现在是6万对吧?60,901对,然后我们现在去试一下功能过滤器,大表已经执行完了。2400. 但是我觉得这2400应该更高。
我们首先结第一个,然后再加一波。Ok 2700. 忘了带大家看这个结论了,正好我们加两波那是6。这个点要跟大家说一下,因为在我们是这样的。因为我们这边使用的是同一个原始URL,然后当它在拼接的时候,那么它就有可能会冲突,冲突的点我相信大家应该都能理解对吧?
因为如果并发的情况下,我们去不能过滤器里面判断它是否存在,它可能不存在,然后AB两个线程生成了一模一样的就是短链接,然后新增数据库的时候就触发数据库的唯一索引的校验,能理解吧?不能理解的话大家想一下这个场景好吧?
所以说它的数据是对不上的是可以理解的对吧?因为正常情况下这种几率不会这么高对吧?因为大家的原始案例都不一样,那么它的西充的碰撞率就会变低,ok。
我们看一下这一波它的是2700,刚才我自己压的时候感觉都快上3000了,我们再看一下有点拉垮,不知道为什么。没关系,这个是有点太离谱,可能是当时计算机的系统执行有抖动,正常的话都在两千五六左右。
通过这个可以得出来一个结论,当我们的使用布隆过滤器之后,它的性能是在分布式锁的6倍及以上,为什么我说6倍及以上是因为我们在进行一个判断的时候,你像并发越高,布隆过滤器的性能对吧?它是恒定的,它是相对分布式锁来说它会更强,分布式锁在并发越高的时候它的性能就越低,不信的话我带大家当我把这个改到60的时候,变成数到60的时候,我们一起看一下,不如模拟器它的性能肯定是指标往上提的,但是分布式锁它不会提,我们试一下。
看到没有?2800。2700. 没问题,因为说实话本地的性能其实是有限的,如果说它是一个可被无限使用的。什么?没关系。当当如果说因为本地的性能有限的对吧?
当然如果说我们被调用的是一个所容忍请求比较多的远程服务器,那么它的性能会被无限的拉高好吧?然后我们可以试一下分支锁65.2. 10%多少?50%看他会不会有问题。应该问题应该没问题。你看它还是400多对吧?它其实是提不上去的。
看到没有?虽然它的样本数在增加,但是它的吞吐量就100就一直是400多一点对吧?你看400多一点对不对?甚至还不如我们40的时候。所以说你像分布式锁的话,因为它只能有一个请求再去请求数据库,然后查询数据库是否存在,你不能过去的话,当你的用户并发量越高,其实它是不影响性能的,不会随着你用户并发量提高而影响它看什么性能,当然对数据库新增的这种性能对吧?
可能你数据量越多,它新增的数据库的可能就越多大概是这种场景ok。
可能很多同学会问像像这个你现在对吧,你在压缩的时候你用了你把图标过滤给删了,如果说在真实场景下该怎么办呢?在回答这个问题之前我们先考虑一下,这是因为我们获取不好意思,是因为我们获取图标的代码有问题吗?当然不是因为他每个这种都很好使,为此的话我去打开了小马短链接,我去尝试一下,然后我创建了一个短链接也就是相同的,我创建了哪个offer这个网站对吧?默认的根路径。
然后我们可以看一下他在提交的时候也花了166毫秒,跟我们之前差不多,所以说它在并发的时候性能跟我们之前的是一样的,为此的话我们该怎么办?很多人能不能把它一幅画或什么之类的,对吧?
比如说我们我们在上面比如说我们在这里进到完了之后,我们发一个MQ,让MQ获取到之后给数据库修改掉,大家流量可以吗?可以肯定是可以的,但是问题在于用户的交互没那么好,比如说我这边新增了,然后这边显示空白,然后我一刷新它又有了对吧?
在用户体验度上面肯定不友好,你像小马短链接他们相当于没有考虑那种特别高并发的性能问题,你不能说人家做的不对?对吧?人家可能就没有那么大的这种查询或者新增的这种场景,因为能在他们这里面去买这种东西都是花钱的,谁也不会没事去测试对不对?或者去瞎测。
为此的话我这边想到一种解决方案,就是当我们在创建的时候,比如说我输入一个原始链接对吧?它默认不是现在只获取到这个标题,它只会获取到标题对吧?然后我们可以看一下提交的时候,它只会获取到一个标题,然后就没有了。
这个时候我们可以怎么做,他获取标题的同时让获取的图标然后存出来,然后新增的时候一起提交过来,就不用我们在做,有风险就是如果说别人提交的图标是一个不太友好的那种东西的话,你需要做额外的验证,好吧,大概就是这么个逻辑。
所以说你想要兼顾性能和产品力的话是不太可能的,但是大家去面试的时候是可以不讲是可以去说性能的时候不加这个东西的好吧?
吞吐量可以理解成 qps tps 吗?如果面试官仅说吞吐量,默认是创建短链接的接口,也就是 TPS。详情查看语雀库:《短链接接口的并发量有多少?如何测试?》
我用jmeter测试一秒60个 循环100次 布隆过滤器吞吐量400左右 分布式锁吞吐量80左右 怎么和视频里差这么多 是设备的原因吗
应该和设备有关系,我这边压测布隆过滤器是1000左右,分布式锁是180左右。不过二者大致是6:1的关系,我看视频里面也是这个比例。
- 第02节:注册用户异常信息返回错误
各位同学给我反馈了一个问题,就是在用户注册的时候,然后我们的如果说有一个用户相当于两个用户的名同时并发来请求,就是返回的信息,它不是我们预期的用户名已存在,而是一个未知异常错误,我们来看一下这个同学怎么描述的。首先它的浮现步骤是在APS里面执行了两次POS请求,然后在圈里面对吧,成功后加入一个睡眠30秒的行为模拟,第一个请求获取到锁的用户没释放锁的情况下,然后第二个请求获取不到锁就抛出异常对吧?但是它会执行 finally里面的安洛克,导致第二个请求的响应是系统执行错误,而不是我们期望的用户名存在的异常,可以看到这个描述是非常清晰的,提问题的逻辑非常清晰,导致我一看到这个我大概就知道是怎么回事了,我给大家模拟一下它是什么意思?首先在开log里面,它是因为我们代码执行很快对不对?可能它没办法模拟两个请求并发,所以说在这里的话它是进行了一个thread叫sleep,我们模拟一下怎么样?然后相当于我第一个提出来了,然后他还在这里执行对吧?他在执行我们所然后再让第二个一模一样的用户名去进行创建,正常的话我们是希望得到,我怎么办?我们把服务重启一下。我们这边风险高才能去执行两次,我觉得这哥们应该是做综合测试进行批发的,但是我们用那种形式比较麻烦,我觉得我们可以这样,我可以从这边的形式然后在这里我们先按这个去执行。对吧?然后这个时候不是在注册,然后我们模拟正常的第二个系统执行错误正常的话,我们肯定是希望他告诉我们一个用户名,你创建对吧?用户名不可用类似于这种提示,为此的话我们现在就要去重构一下这里面的一个逻辑。首先我们要先将这块内容给删掉。刚才测试的对吧?问题点就在于两层材料壳,我们可以先这样先把这个材料给它抽出去,然后他不如果说,他拿不到手的话,ok就先把异常收入出去,然后这样的话就很这个用户存在就没问题了对吧?然后我们再优化一下双层,双层这个东西。我们看一下正常来说的话,我们这个是什么意思?给大家解释一下如果说我们的对吧?新增的数据库,它一般的话我们新增一条数据库的话,它不是会给我们返回一个新增的条目数量对吧?如果我们在这一次如果说这里面它小于一的话,假如我们没有成功,这里面应该是返回一个0,然后抛个异常出去,但是因为大部分情况下,我们基本上这个异常是不会存在的,所以说我们可以在这里把它删掉当然你也可以留着对不对?然后我们这边就可以换一种思路,把给挪上去,在这一层里面加分类,我们就可以删掉就出来。不知道大家能不能理解,相当于首先它这里面可能会发生两个异常,第一个异常是如果说,我们新增数据他没有按照预期计划一场对吧记录新增进去,还有一场对吧?
这个开始发现没有,他拦截的是叫什么?主见冲突,对唯一作业冲突。然后如果说它会它触发了危机作用的话,抛的是用户名,已存在用户记录,存在如果说,他没有按照预期把数据记录插进去,他抛的是用户进入新的时代,这是两个不同的银行,我们不能说你现在失败,然后用户名已存在这种是不允许的。Okay为什么我们把这层开始就是把这三点往上移了,因为我们这块开始说白了如果说他这里跑异常了,或者说这里跑异常是执行不到这里的,所以说我们是可以把这块给合并起来了,大家看一下这个代码其实就能够理解了对不对?然后我们继续模拟个sleep。然后这边还是模拟100秒。Ok重启一下。要。然后我们这边用户名存在对不对?这样的话就比较符合我们为什么这里要为什么这里获取不到数据和用户名存在,我应该在上一个视频也跟大家去讲过如果说有个请求名称马丁对吧?还是先到的,然后再执行这里了对吧?那么他大概率是不会执行出错的,所以说你第二个如果别人正在获取锁,然后你没获取到对吧?就证明你比别人慢了,然后那个名字大概就被别人用了,为了避免你在这注册对吧?Ok还不如异常直接抛出去节省用户的时间。
好,那问题点就是这样,一个同学给我提了一个建议,然后也确实很合理,然后我们也把它进行一个改造,其次我们这里面有一个验证用户名是否登录过一个客户,我们这个删掉本质上是修改用户名的,但是我们的用户名是让用户传的,这里面不是很合理。正常的话我想想,正常的话我们这里面应该验证,比如筷子get your name对吧?有的有点有点不见了以后是吧?然后直接用一个由此而开始就盖茨优斯的内容。死肉因为我看了一下什么?当前用户信息异常。当前登录用户。Ok就这样。其实正常的话我们可以在这里面直接给他用 units带来的内网也是可以的给大家模拟一下不同的场景解决对不对Ok这个问题的话就解决了,我们提交一下代码,然后用户注册,说中国是对了,刚才刚才为什么会抛系统异常?是因为刚才我们的代码里面他揣了对吧?他没有获取到log,然后他不是要去解锁对不对?然后他解锁的话发现持有锁的线程不是他自己,然后就跑异常了,然后被我们全局长拦截器就拦截掉了,知道吧?就这个原因。有一点给大家再建议一下,我们每一个日志的提交的规范就是尽量要保证一个
那如果ab线程同时申请同一个用户名,都通过了布隆过滤器,然后a插入数据库释放锁之后,b开始trylock也拿到了锁,插入失败inserted<1抛出了保存异常错误,是不是在插入数据库之前在问一下布隆过滤器比较保险呢
yo 回复 年年:我认为,都通过了布隆过滤器,但是tryLock是快速失败,a释放锁之前,数据已经加入了布隆过滤器,b是通不过的。如果同时通过,b执行tryLock也会失败拿不到锁,就放弃后面的逻辑了。
TheTurtle 回复 yo:但是也可能出现ab同时通过后:在b执行tryLock前,a就已经释放了锁的情况。这种情况下,依然会执行后面的逻辑。
TheTurtle 回复 年年:我认为可以的,相当于【restoreUrl】那里的双重判定锁,但是也会带来误判的情况。
Lz 回复 年年:两个线程是同一个用户名的话,b线程只会抛唯一索引异常的报错(另外,布隆过滤器会误判的)
总结就是如果在并发的情况下多个用户在进行注册,并且在某种情况下小概率事件会发生用户名相同的情况,那么后来者比较慢的那个就会获取锁失败,然后就会进入try中,但是它本身就没有获得锁何谈解锁呢?这样就会在解锁的时候发生错误,这个错误又会被全局异常拦截器进行拦截
https://t.zsxq.com/19wgBhcoJ-知识星球
- 第03节:重构读写锁&延迟队列功能
说一下延迟对接,如果说短链接正在被修改,那么我们是需要通过队列去进行延迟之类的,大家之前都明白,然后也是我们放在知识星球上功能描述其中一个点,我们来复习一下功能对吧?这节课我会先和大家说一说,我们当时为什么要用延时队列,以及现在我们使用了消息队列的情况下,延时队列它的功效到底还有没有那么多?首先我们先看一下这张图,我们一个用户想要访问你项目的一个接口,是不是必须得通过一个线程去执行对吧?这个线程是哪里的?Ok我们现在开始说他们看到里面有一个线程池,然后他们开的作为是不是他的一个容器,所有的访问是不是不同的请求,都会通过他们的线程池里面的线程去访问一个执行单元。
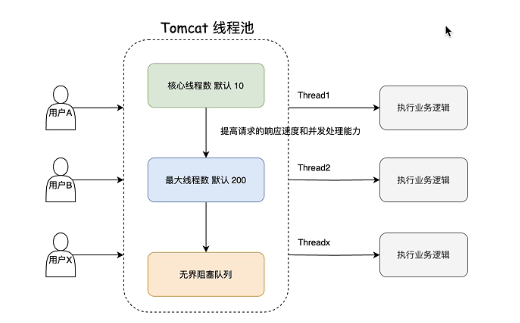
我给大家演示一下,比如说我们在先启动聚合,然后再启动一下网关。然后我们举个例子,我们直接在我的命里面打断你。Ok,然后我们现在执行一个命令,看到没有HTTP杠no-8003,其实就是我们刚开始里面线程池里面的线程,然后它会通过这个线程去执行我们具体方法里面的业务逻辑,最终反馈给前端或者说用户,这样就可以非常容易理解了对吧?然后也是把这个模型搞清楚之后,我才能跟大家去讲我们具体当时为什么要用研制队列的一个主要关系,只不过我们正常线程池是创建完核心线程去放阻塞队列,最后再去创建最大线程数线程,这个的线程池,它为了提高请求的响应速度和并发处理能力,它将这个阻塞队列和最大限度数调换一下位置,对吧?这一块如果大家有兴趣是可以去看一下他们看的底层的源码的,他进行一个复写O。我通过这个图可以得知,假如用户a去访问一下我的这个项目里面的一个请求,然后它会通过一个线程执行的业务,就像刚才那个一样,分页查询一样对吧?
其实本质上就是通过现实中的一个线程去执行的,这里面我们看得很清楚,线程池最大的数量是有限的,就是200个,假如说我的业务执行逻辑它的耗时是一秒,那么我们同一时间这个项目能够对外有多大的并发是不是就200对吧?因为最大限度数就是200,如果超过了200怎么办?是不是要放组织队列?我们假设200个用户。首先我们现在收到一个接口的处理能力。响应时间1000毫秒也就是一秒对吧?12123ok。然后我们200个用户同时去请求,那么我们项目的吞吐量是多少?就是200对不对?如果说这个时候我201个用户进行访问,那么他会有一个请求会等待这200个用户,全部就是200个线程把这些用户的数据处理完了之后,他才会去访问他最后一个加入到这个组织里面的任务也相当于第二百零一个它会响应时间是两秒,为什么?
是因为第一秒它这里面的所有的线程都在运行任务,没有时间处理它,等到200个线程里面有一个线程对吧?处理完了之前的任务才能轮到它,所以说它的响应时间是两秒,ok我们现在已经知道这个逻辑了,我们再来看一下当时为什么要用延迟。我们之前是知道的,如果说在修改短链接的时候,我们是需要申请一下读写锁的解锁,这个时候如果获取到协作的话,我所有的读锁也就是在去获取监控信息那块他是拿不到锁的,他会堵自主假设,我们这里面解锁已经被获取,执行了假如300毫秒ok,然后我们所有的访问短链接就会被阻塞300毫秒。假如说我们有一个链接是非常热的那种短链接,然后被别人访问对吧?这个时候正常我们的响应时间是5毫秒,然后因为你的鞋锁被占用了,获取读者是获取不到的,然后所有的去访问的请求都要阻塞300毫秒,你觉得这种有什么问题?
是不是我们本来5秒就能解决事情,来球直接来个极限卡,卡300毫秒,然后是不是可能我们很多的县城或者很多用户的请求都会堆积在肚子里面,对不对?如果说堆积的组织队列容量很大的情况下,注意它是无界的,是不是就触发了oom?大家设想一下不着急在这里面想一下好吧,因为很多同学都是对线上的一些项目接触的不是很多,尤其是像他们的这种底层的线程式机制了解的也不多,这种情况下你需要有一个思维去转变一下,想一想,就拿刚才我们举的这个例子去说,大家想一下,这里为了给那些不太容易接受的同学留点时间,我们留一个空白,如果说,他这种大量的请求被堵塞获取堵锁,这样的话我们会有很多的请求进入到注册的这里面,那么可能会造成om对不对?这样的话所以说我们当时才做了一个决定,说使用使延迟队列如果说发现协作已经获取了,ok我不等我直接把你这个请求扔到岩石堆里面去,让他后面再写不了数据库,这样的话我们就不会再有300毫秒的阻塞,也就是写锁去修改短链接的耗时了对不对?
但是我们当时是直接去写入到数据库的,就是同步逻辑。对吧?我们是直接一个请求过来之后,然后先获取对应的监控信息,然后直接进入到数据库,但是我们后面干什么,我们后面是不是改成消息队列了,对不对?这个时候大家想一下消息队列它的消费者的逻辑,是不是就不会再有这种海量并发存在的这种阻塞行为了,因为消息对于它的消费逻辑是匀速的,明白吗?我给大家举个场景,肯定放这里不是很合适,我在新店里ok。然后美国 ok这是他这么意义。搞什么二,搞什么三我们相当于是
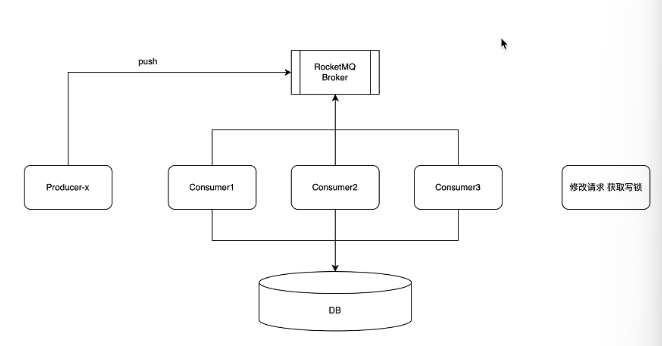
有人访问本链接,然后我们这边有一个什么有一个我就是不就是对吧叫X。然后他往消息的店里面去干什么?去铺什么?比方说然后我们有卡数码匀速的去里面去拉任务,说假设我一次性拉一个消息,然后拉完了就干什么?新增到DB对不对?然后我们表现到DB,首先他是自己去把控这个消息的速度的,比如说我从博客里面把消息拉到本地,我需要耗费一秒对吧?一秒才能形成到DB,ok我就在第二秒再去拉下一个,通过两个去做一个这种就是临时的存储,这样的话它是没有任何竞争压力的。
为此的话我们的读解锁其实意义就没那么大了。明白吗?大家想一想。我们这里之所以要家族解锁,是因为就算你知道他们看你什么的应用处理不了那么多的请求,但是用户是不关心他会一直访问你对不对?可能有N个用户去访问你处理不了,所以说我们要做消防,但是在这里你消费完以后他才会消费下一个,这样的话我们这个场所这里的延迟队列其实就没有意义了,或者说它的意义就没那么相当于我们之前是协作那边,假如说执行300毫秒,你这边相当于就是说你每次如果说恰巧遇到了短链接触发了修改逻辑,那么这里是不会有这300毫秒的阻塞的,明白吗?
如果说我们有了也是不会有300毫升注册的,但是整体来说300毫秒的提升就没那么大,因为它不带有那种om的风险了,明白吧?所以说我们这里面其实就不需要再使用了,直接就可以了,你有三秒毫秒ok我就等于300毫秒就可以了。大家想一想,然后我先把代码改一下,就按照然后我们这个就没有必要了,九色也可以删掉。对吧?这里删还是不删?先别删了,给大家留一个什么,我们标记一下删除标记好吧?然后我们就不删了,让大家这个代码让大家留着看一下就可以了,后面哪怕你们有别的场景,对吧?
想做这种延迟消费统计,我们也是可以借鉴这个代码,我代码都不然后大家明白了吧?在这里。然后到这里的话,我们延时队列就可以一改对吧?我们使用什么?Radiance分布式读写锁,功能,完成短链接在海量访问场景下的数据修改功能,修改一下,大家可以在自己的简历上也可以修改,当然我们不用延迟队列只能说是因为它的功效没那么大,其实用一下也是无伤大雅明白吧?
然后这是第一步,首先然后这个视频的第二步我们就会再揭露一下另外一个事情,然后再什么意思?在修改的链接结构。Ok这里有同学之前跟我讲说马哥我如果说短链接一直在被用户访问对吧?这里的解锁是不是可能就修改不成功?大家思考一下,是不是有这种可能性对不对?接下来的话这里面也可以改了,为什么这么改大家能理解吗?还是一个道理,按照按照之前的这种逻辑的话,如果说我这里面不加创客,有没有可能一个短链接一直在被人访问,然后我这里是一直获取不到锁,的,或者说需要一个长时间去获取锁的逻辑,这样的话吞吐量就会下降,或者说用户点一个修改逻辑,然后发现一直转圈圈这种行为,明白吗?为什么现在又不需要?是因为我们去点绕的时候,他会去访获取这个分布式的读写锁。假如说这个时候有这么几个线程在拿到读所去进行新增数据库,ok假如前面有123对吧?这个时候假如说我有一个修改,获取协作,它的获取时机是什么?是不是等他们三个获取完的时候就到他了,对不对?大家想一想是不是如果说像之前的那种的话有大量的请求在那写入,写 DB的话,他可能他获取到锁的时机就会非常的慢,但是因为我们现在用这个软件进行了一个萧峰之后,他每次都是固定几个消费者线程去获取堵锁的,所以说他现在我们在用这种获取同步去获取协作的形式,就不会再像之前那样所耗费的时间那么长。
然后我们看一下它这里面读锁解锁ok没有问题,大家这一块可以梳理一下,因为相对于这种大量场景下的这种访问对吧?为了避免这种延迟性,所以说我们做了一些妥协,通过创造尝试过这种形式来避免用户请求,有一个很长时间的响应问题。
通过我们用 Q进行交锋之后,那么这种响应问题可能就不存在了,对不对?大家理解一下如果说讲的再讲细,其实也就这样,可能有些人会觉得啰嗦,所以说这个问题的话我们就到这里结束,我把这个代码提交一下,稍等我再检查一下。然后这里面的话是获取堵锁或者获取解锁解锁去一直去绕口,然后在这里面是通过读数的形式去死党,然后把颜色都给删掉,ok没有问题。然后我们这边去变更下。对。怎么修改?如果大家梳理了之后还是不太明白,可以把这个疑问发到评论区好吧
简单总结一下 1. 加入消息队列的原因: 因为tomcat最多支持200个线程并发,所以当海量请求到来时,需要进行削峰,否则会有OOM的风险,具体做法就是将保存短链接访问记录的操作异步化,当前线程只负责帮用户跳转链接并发送短链接访问记录到消息队列中。 2. 加入延迟队列以及删除延迟队列的原因: 当用户修改短链接的gid时,为了保证数据的一致性,需要加读写锁,即在短链接gid修改期间加写锁,短链接访问记录保存的时候加读锁。 现在假设一种情况,当一个线程a从消息队列中拉取短链接访问记录准备保存到数据库中时,如果此时该短链接的gid正在被修改,因为修改短链接的线程拿到了写锁,所以此时线程a可能会因为拿不到读锁被阻塞,使用延迟队列是正是为了防止线程a被阻塞。 但是这里并没有必要使用延迟队列,为什么?因为这里不存在占用过多线程从而导致OOM的问题,消费者组只会安排固定的几个线程去拉取消息,如果碰到上面那种拿不到锁的情况,阻塞等待就好。 3. 为什么修改短链接也不用tryLock和延迟队列了? 原因和上面一样,抢读锁的就是消费者组中的那几个固定线程,在Redisson中,RReadWriteLock的实现默认是公平的,这也就意味着修改短链接的线程总会有机会拿到写锁,只需要阻塞等待其他读锁释放即可。
Yan. 回复 yuemo:使用延迟队列就是为了给gid的修改提供时间,可以这么理解吗。如果延迟时间内还是没修改完,还是会存到旧的gid记录上吧。
地信哥 回复 yuemo:大佬,本来我还想自己总结笔记,我现在直接用你这条评论当笔记了,哈哈,真的总结的太好了,我这种笨蛋都能看明白
地信哥 回复 Yan.:使用延迟队列是为了防止oom,但现在有了消息队列了,oom就不会存在了,所以可以不用延迟队列
地信哥 回复 Yan.:至于为啥有了消息队列oom就不会存在了,是因为消息队列他的消费者逻辑是不会有这种海量并发存在的阻塞行为,因为消息队列他的消费逻辑是匀速的,也就不会出现OOM
地信哥 回复 Yan.:我想说的是,觉得挺这节课有些困难的同学,可以先听一下之前《功能扩展》板块的第5节和第12节,再来听这节课会比较好。 还有就是吐槽一下马哥这种排课方式,我觉得同学们来听课,一般都是菜鸟(至少我是这样的),接受不了这种知识点来回跳转的排课方式。。。
之前的延迟队列感觉是为了防止数据库压力太大了,5秒存进去一波,然后5秒内数据库疯狂操作。但是现在有RocketMQ了,数据库的速度有多快,RocketMQ的拿的速度就有多快,至于OOM是消息队列解决的,以前没消息队列的时候,每个请求都要对数据库进行操作,数据库压力大并且操作慢。这样就容易出现等待的情况,那就把单独拿一个守护线程出来让其修改数据库的数据。其他的主线程就负责把信息传给消息队列了。创建短链接那人不会因为监控数据的信息不是实时的而烦恼,但是访客会因为不能跳转网页而烦恼。
ReentrantReadWriteLock的默认模式应该是非公平模式的把;经过官方文档查询,RReadWrite是非公平锁,你说的这里有误
马哥,我想问下,为什么在消费消息,进行访问监控数据入库的时候,采用的是读锁,这个入库操作不是插入数据库的操作吗。还有就是针对这个读写锁,该怎么向面试官解释这样设置读写锁的原因。稍后写个语雀文章,主要就是为了避免修改gid后,消息队列消费时还在使用旧的gid
Yan.:虽然是固定的几个线程消费,可是他们是一直持有读锁的啊。如果我的消息队列中有1000个消息,三个线程并发的消费,修改短链接的写锁是不是会一直获取不到?因为这个读锁就一直没释放过,需要等消息队列中的1000个消息消费完就可以获取了吧?这里不太懂
还有一楼说的RReadWriteLock的实现默认是公平的,这个有考究吗?
RQTN 回复 Yan.:我懂你的意思,虽然使用延时队列或者消息队列后,只存在少量消费者,但是对于热点短链接的情况,还是很容易出现消费者交替获取读锁的情况,导致写线程依然可能长时间饥饿。 如果一楼说的 Redisson 读写锁是公平的,那么这个问题就不存在,但我上网查以及问ChatGPT好像都说是非公平的...,要解决的话可能得自己实现一个类似公平读写锁的东西了。
RQTN 回复 Yan.:我对 RReadWriteLock 做了一个测试,就是虽然 RReadWriteLock 不支持公平锁,但是每次读线程 readLock.lock() 获取读锁的时候,其实会检查锁同步队列的队头是否是一个写线程在等待,如果是的话,那么读线程会直接进入锁同步队列等待,因此这里写线程其实是可以避免被读线程不断插队的。 但前提是你获取读锁的时候用的是 readLock.lock(),如果你用的是 readLock.tryLock(),那么读线程将不会检查锁同步队列的队头,而是直接加读锁,导致写线程被不断插队。 这个和 JDK 的 ReentranReadWriteLock 是同一个道理,区别在于 RReadWriteLock 只实现了非公平锁,但是在这个锁并发度不高的场景下已经足够避免写线程长时间饥饿了。
我就想问问,为啥goto那张表要加gid字段,为什么不直接加原始链接,这样修改短链接的时候也不需要修改goto表,跳转的时候也只需要查一张表,这里就更没有必要搞什么读写锁,为了读写锁而读写锁?还是说goto这张表加gid有什么深意?希望来人解答一下
Deler 回复 aman:如果加原始链接的话,当我修改原始链接的时候,就要同时修改goto表和短链接表,这会增加业务复杂性并引入事务问题。另外,假如我想通过短链接查询其他信息呢?比如短链接的describe,那我是不是还要在goto里再额外增加describe?这说明了增加额外字段会引入业务拓展性的问题。所以这种方案也不是万能的。
马哥,修改短链接的其他信息时也是需要加写锁的。 假设有一个线程正在读短链接,然后发现缓存里的短链接失效了,于是去读取数据库,在这个线程写回缓存之前,另一个线程进行写操作,完成之后执行删除缓存的操作。这之后之前的读操作的线程才完成写回缓存的操作。于是缓存里是旧数据。
GP 回复 Deler:也可以采用异步双删解决问题
先搞清楚消息队列和延迟队列的作用: 消息队列:跳转与记录访问监控分离 延迟队列:拿不到锁,不要阻塞,放入延迟队列,稍后重试 考虑一个场景:某热点短链接正在修改分组,拿到了写锁后,大量访问请求同时过来,假设修改分组占用写锁较长时间 再依次看以下几种方案: (1)无消息队列,无延迟队列,跳转与监控不解耦 拿不到读锁,则该线程阻塞(需要等到写锁释放),tomcat中10个核心线程很快用完,紧接着200个最大线程也都阻塞,剩下的都在无界队列中,容易oom (2)有消息队列,无延迟队列,跳转监控解耦 监控数据封装为消息,投入消息队列。固定10个消费者,拿不到读锁,阻塞,但最多只阻塞这10个消费者线程。其它消息就堆积在消息队列中,等着慢慢消费。 (3)有消息队列,有延迟队列,跳转监控解耦 监控数据封装为消息,投入消息队列。固定10个消费者,拿不到读锁,再投入延迟队列,不阻塞,直接返回 为什么用(2)不用(3)?即本章视频的改动点 消息队列中,我们可以固定消费者数量,实现匀速消费。例如,就10个消费者,全阻塞了也可以接受。我们不能接受的是(1)中有大量线程阻塞,乃至oom 为什么落库、修改上读锁、写锁不再tryLock,而是直接lock,即阻塞等待拿锁? 在(2)的情况下,最多是1个修改线程拿写锁和10个消费线程拿读锁,互相竞争。拿写锁阻塞会儿没关系,等10个消费完;拿读锁阻塞也没关系,最多就10个消费线程阻塞,都可以接受。redisson的读写锁是公平的。10个消费者释放后,就会轮到修改线程,不会被插队。所以不用担心永远拿不到写锁的情况。
但其实在使用延迟队列的时候,也可以不用在没拿到锁的时候才放入延迟队列,即无mq,有延迟队列的情况。个人感觉还需要对比mq和相比延迟队列的优势。比如mq可以使用消费者组;延迟队列会导致内存紧张等等。
我觉得还有一个原因为什么选(2)是因为如果我修改gid分组的同时,有大量用户并发去获取短链接接口,这时用(3)的话,大量请求获取不到读锁,直接进入延时队列,而延时队列进行后续的逻辑还需要通过goto表去查最新的gid,进行数据统计的回补操作,而直接用(2)是因为楼主上面所说的原因和这时我能获取到读锁,证明没有写锁在操作,我的gid就是最新的且没被修改过的gid,直接扔到消息队列进行消费即可。
补充:无消息队列,有延迟队列 延迟队列的一个主要目的就是防止统计短链接访问数据的线程被阻塞,那么延迟队列是怎么做到这一点的呢。首先,尝试获取读锁,如果失败的话,那么把任务放进延迟队列,在延迟队列中设定好时间,比如500ms,那么也就是说每隔500ms,任务被消费者消费也就是被统计,可以理解为统计数据每隔500ms刷新一次
正常来说,Tomcat最多只有200个线程,刚好有着200个人都在进行业务。而201个人的请求会放在阻塞队列里面,等前面的某个人干完了,201号的业务才能进行。但是实际业务不止201个人,可能几十万人呢,虽然请求速度很快,但是同一时间请求的时候,后面的请求都要放在无界阻塞队列里面。无界就是没有界限,放太多了自然就溢出了(oom)。所以正常来说就把访客的请求(监控数据功能)放到一个队列里面,这样就不会有oom了,因为只管把数据放过去就行了,因为监控数据要对数据库进行操作的,所以就慢。这里放在队列里面,然后用一个异步线程,慢慢的把数据存进队列即可。然后就是后面要重构为RocketMQ,RocketMQ就是数据库更改速度有多快,那么从队列中获取的速度就有多快,以前使用阻塞队列感觉就是为了减少数据库压力而已5秒放一波,但是现RocketMQ已经是加多少水,喝多少水的感觉。这里用lock而不用tryLock的原因是:个人理解就是使用就消息队列后早就可以lock了。因为如果没使用队列的话,当修改短链接时就写锁上锁了,读锁就获取不了就会出现一堆请求,请求多了和上面那样造成阻塞,阻塞多了就oom。但是有了消息队列后只管把信息存进去,后面操作数据库的时候再一点点来。写锁那边也要lock,因为读锁那边把信息存进队列里面是很快的,读锁lock就一直等着就行了。
全糖很多冰 回复 皮蛋瘦肉粥。:求问:为什么用户注册里还是 tryLock()?不能也类似这种等一等吗
1. 增加掉延迟队列的原因: 首先,如果使用无界阻塞队列,修改短链接的时候获取写锁,此时如果大量并发请求会获取读锁,会导致大量请求都到无阻塞队列里面,导致OOM。因此当时要用延迟队列,发现写锁已经获取了,他就不等了,直接把请求扔到延迟队列里面,让他后面在写入到MySQL,这样的话,就不会再有300ms的阻塞(也就是这个写锁去修改短链接的耗时),后面因为用到MQ异步统计短链接的访问情况,MQ异步消费是不会再有海量并发导致的阻塞行为,因为MQ的消费者是匀速消费的,不是上文提到的大量并发请求无脑冲过来导致全阻塞了。因为前面提到的使用延迟队列的原因是防止OOM,因为现在用了MQ匀速消费了,不会再有这种OOM的情况(我感觉这里应该是跟MQ的可靠性和持久性,流量控制有关),后面他说延迟队列提升的300ms提升不大,他就等300ms就完事儿了,因此他改了trylock(非阻塞)->lock(阻塞)给我也干蒙皮了,有点无语,也不是很理解。 2. 多个用户正在浏览短链接,但恰逢修改短链接,原来trylock->lock的原因。 这里我觉得马哥的意思应该是非公平锁的意思,因为RReadWriteLock本身默认是非公平锁,然后多个用户浏览完之后,多个统计短链接请求和修改锁的线程是互相插队争抢锁的,所以后面lock比trylock更合适!
第一就是先明确一下 延迟队列的作用: 因为是读写锁,一者获取的时候,另一者是不能进行获取的,为了保证数据的唯一性准确性。 场景: 短链接项目中进行修改短链接分组的时候,如果刚好有用户进行了短链接跳转我们就要对他进行记录统计,但是由于是我们抢先一步获得了写锁,所以在进行统计的时候这一步就进行不下去了,因为读锁它获取不了,这样就照成了线程阻塞。假如说我们tomcat有200个线程,我们在进行获得写锁的时候,进来了300个甚至更多的请求,这样的话就会造成oom(Out Of Memory)。OK这样的话我们的延迟队列就派上了用场,因为这里我也不熟悉所以我就按我的个人理解来进行解释,如有错误恳求斧正! 还是上面这种情况,我们率先获得了写锁,然后来了一堆请求获取读锁,我们的延迟队列就会把这些个获取读锁的请求进行延迟(比如说延迟5秒,5秒后如果写锁还没释放,就在延迟5秒),这样就等到了写锁释放,然后这些请求再去请求读锁(但是如果那么多请求一窝蜂的同时请求,应该也会造成oom这种情况,这一点我也不太懂,应该跟消息队列一样固定几个线程进行释放?但是思路应该就是这么个思路) 以及 消息队列的作用: 用于解耦,快速返回结果,异步 场景: 用于短连接进行跳转的情景,这里除了跳转外,还会进行短链接统计,因为后者涉及到大量的表MySQL修改,并且前者也会进行MySQL操作但相比于后者就少很多了,这样的话虽然不会造成阻塞场景的发生,但是会响应时间过长,反应慢,用户体验差等情况产生,并且跳转是主要功能并发场景大,操作频繁,对于MySQL的压力会更大。 因此我们使用MQ进行操作,直接将这个监控统计访问记录这一部分扔给MQ异步操作!我们主线程只需要负责重定向即可!这样响应快反应也快,并且MQ也不会丢失同时也保证了数据的准确性! 第二 问题: 为什么可以删掉延迟队列? 答案: 因为我们把这个统计相关的代码扔给了MQ。 这样的话就拿我们延迟队列上面说的情况: 当我们获得写锁的时候,来了一堆请求获取读锁(用于记录短连接的访问记录),但是他们获取不到就会照成阻塞,一旦这种请求过多就会oom。这是原先没有延迟队列的情况,但是我们现在将统计抛给了MQ,这种获取读锁的请求会一窝蜂的涌进MQ中,值得注意的是MQ处理请求是固定的几条线程进行处理并且是匀速处理,这样就不会发生一下子把所有线程都占据挤爆造成oom发生了,当然有人说这样不还是会造成阻塞情况吗? 就像马哥说的那样我们举个例子,加入MQ有3个线程进行处理涌进来的一窝蜂请求,同时MQ外面我们还占据着写锁,当我们修改时,MQ着3个线程进行阻塞等待。释放写锁后,MQ中的3个线程都获得读锁等到他们释放后会有一段空隙,外面的写锁以及MQ中陷入阻塞队列的请求也会进行抢夺读锁,虽然读写锁不是公平锁,但是也不是绝对的,两者抢夺;
两者抢夺到的几率都是有的,并且进行阻塞等待的时候也不会等待太久---写锁就一个线程进行处理,-----读锁就MQ中固定的几个线程进行处理-----所以等待时间也很短!!! 以上只是我的个人理解,如有不对恳请斧正,不胜荣幸!
https://t.zsxq.com/19WFNH9c1-知识星球
- 第04节:修复幂等&Redis-Stream消息队列线上消费停止问题
这节课我们还是来讲这个消息队列,然后第一个点讲密的,第二个点讲线上,环境运行的过程当中,然后消息就不消费了。首先第一个点是密等的过程当中,大家给我提了一些问题,就是比较多的疑问,这里统一说一下,大家比较多的问题是什么?为什么这里面抛了异常,但是还是要给它设置成已完成的状态,正常来说抛异常之后不应该是要等消息队列进行重试对不对?如果说我给他设置已完成,那不就相当于后面这个消息就算是正常消费了,对不对?实际上这里面是小写的一个词是吧?我们在这里面是要把触发到的就是捕捉到异常就把它收入出去,因为我们要让消息队列他的底层的线程要知道,然后不要把ack返回给包括了知道吧?所以说这里面是我一个失误,少写一行throw,因为刚才我已经提交了,所以我刚提交了,所以说这个地方大家知道就好加一个思路ex就可以了。
然后第二个问题,问题就是大家部署上线之后,我们在进行跳转短信的时候,我们不是有一个在这里面。然后大家就很疑惑,为什么刚开始上线我们跳一个链接,它这里面就能增加一次访问次数,但是过了一段时间之后它就不能再增加了。明白我意思吗?就相当于我们的消息队列的消费者仿佛就失效了。为此的话我也比较苦恼,因为确实我不知道线上就是这样,但是现在我的问题已经解决了,是昨天晚上找到的问题的一个结论,核心问题我给大家说一下,我在我的服务器上发了一张截图比较有意思,然后给大家瞄一眼。 stream Top task.
我应该有个什么stream?Top task. Ok,对。他怎么讲?我找一个有没有不是卡手机。他有点奇怪,他这里如果是卡手机他不应该给我写了一个登录的,首先是什么意思?我给大家解释。首先 Student就相当于是从瑞丽斯的斯蒂姆队列里面去拉消息,看到没有?本质上它是什么?它是一个现场其实本身就是一个现场运行任务,对吧?里面去做一个一直去食品里面去拿消费者,其实在这里。然后在这里面的话,它相当于去瑞德日靠依靠的,然后这里面这个函数就是底层自己实现了一个内容是什么?算了,这个比较复杂,我就跟大家讲了,我去看一下它的底层代码太复杂了,我也没看的特别明白,但是我大概已经知道问题在哪,然后通过这个去进行变现,然后我们看一下么,records对吧?It's not,所以说他没有办法执行给他记的。
为什么对吧?我们这里面这个做循环为什么报这个错?是因为它后循环的底层其实掉的就是例子的迭代器的方法,所以说如果这个是空的话,那么它返回的就会抛这个异常出来,然后就会触发下面一系列的连接不到。等抛这个ready不到立场,为此的话我可能就昨天开始分析了这个问题是由什么引起的,首先我们看一下我们这个包是从哪里来的?他这是不认得,他刚来意思我就在想会不会是不是的问题,然后我就把这个包扔到了最新的就是85的升到了3.2.4,我就去搜了一下跟大家讲什么,讲一个如何去做这个版本。
我跟大家讲我的一些实际的一个排查问题的方方方法。这里面给大家看一个平台,在这里去搜一下。底盘的意思是它的一个依赖,看到没有?最新版本是4天前发布了一个3.2.4,然后为此的话我就把这个版块替换了3.2.4,我当时可能会以为这里面它会加这种类似于非判断之类的,但是没有我哪怕升到3.24,这也没有为此的话,我就在想是不是可能是别的问题引起的。
Ok我就在想他肯定得去干什么?去看一下外套的记录对吧?有没有让别的包去实现。然后王朝阳看一下这个值是怎么来的。Ok这个值是通过工作计划出来的,ok工作器看一下它是从哪来的,read的方式,看到没有?这里面有个get的方式,然后在这里面我们去干什么,就获取到对应的一个函数,ok我们去看一下它是怎么来的,这个是个关注,ok看到这里,我们就可以看到这里面有什么由此烹饪自己去实现的,然后还有什么发表?还有一个去实现的,然后就实现了,这就有点意思,因为我们本质上用的是什么用,也用了相关的包对不对?能把自己的时间内替换进去,这也就是一个多态的理念,为此的话我就又换了个思路,换了个思路是什么?没意思。我们去搜一下us里面的版本是多少,很多问题,如果出现这种要不的问题,大部分情况下是因为你用的版本比较低,高版本会有一个修复,大概3.27.2。3.2.
27.2,而且你像spring的版本对吧?对于我们正式的项目来说,它是基本上不敢生太多的,3钟 3.2,这是一个很大的跨越,很多人在生产项目不敢生的,但是reason还好,因为它只影响是自己的东西,而且类似于这种他们一般不敢在一些比较成熟的功能上做一些比较,和之前版本有差异化的迭代,所以说有些我们是可以正常升级的,为此的话我升级了一个3.27.2的一个版本发布到线上,从昨天到现在为止是没有问题的,所以说基本上这个问题就解决了,就是因为listen自己底层的一些机制导致本来不应该为空,它变成了空,然后我给大家讲的这是第一个思路我是一个万金油的方式,用版本的形式去解决,但是大部分情况下我还是推荐大家通过先去什么先去Top上去搜对应的一个问题,你像我们这个问题其实不太好找的对吧?因为什么?他的报错不是不够个性化,个性化的话只认或者说surprise自己的那种异常,但是他这种控制帧就不太好去做一个不搜索,我们可以复制一下,一般的话我昨天我是怎么做的?以前我是首先就是瑞森他的衣袖里面去进行一个搜索,也可以来麻辣烫的天亮一点。好的
我复制出来的这些单词有可能是有些是错误,但是昨天我复制出来的肯定是对的,然后我又想他可能和spring的对他的意思有关,然后我就又去搜了一下 springboard,我们用他最高的去搜一下,应该就是spring book。好吧,我们还得往下。对, Spring。Spring它应该版本挺高的。不是,他应该差挺高的。这么奇怪。它有个杠。你们告诉一下,然后我就在19里面去搜了一下,结果还是没有找到和spring相关的立场,为此的话我只能寄希望于他的版本升级能够解决,如果版本升级解决不了,那没办法,只能蒙着他的源码,看看哪里可能会出问题,这是解决问题的三板斧,首先第一我们要去衣袖里面去搜一下有没有相同的,或者说我们打开谷歌去访问一下,对应的报错的一个标识对吧?然后第四第第三个在第一个问题衍生出来的第三点对吧?那就是谷歌搜不到那就去百度好吧?然后第二块的话就是尝试去升级它的版本,对吧?你可以去类似于它的版本发布的一个历史里面,你看他其实都有版本发布历史的,就看一下我们现在的版本和这个版本之间它的你看X它其实都有对吧?我们去搜一下有没有类似的,如果没有有可能人家没列出来,我们就也可以正常的进行升级,对吧?然后我们如果搜不到或者说能搜到就把版本先升上去,我们先运行一段时间,看看能不能把问题修复,如果说能修复皆大欢喜,就像我们现在这种方式如果修复不了,不好意思,你只能通过看源码的形式去解决了,对吧?因为没有办法网上有现成的我们就吃,没有现成的我们只能自己去做对不对?索性去看它的源码,它的源码确实太复杂了。我们fix修复消息队列,运行中读取数据为空,停止异常,就是问号。好的,如果大家之前已经部署过了,就把瑞森升级一下,就能够解决运行时的监控数据不再采集的问题
https://t.zsxq.com/19wP11zuR-知识星球
- 第05节:Redis-Stream消息队列重构为RocketMQ
以下是您原始讲解内容的文本修正版(保留原始表达方式,仅修正明显语音转文字错误):
第05节:Redis-Stream消息队列重构为RocketMQ
我看一下如何从Redis的Stream然后改变成RocketMQ,然后给咱们就为了避免浪费大家的时间,所以说我把这些步骤已经提前模拟了一次,然后写到了一个文档里面,这节课我就会通过这个文档来将消息队列从零到一的引入。
首先我们要先将高文件移到代码里,还是我们老规矩放到resources文件里面。然后然后将这个放到我们的依赖管理中去,注意这里再给大家提一下,依赖管理他只是去管理依赖,而不是去下载依赖,只有在我们的子module里面去具体的引入了依赖他才会下载。
好的,我们刷新一下,没有依赖他正常就应该能够下载下来,看到没有已经?然后第二个就把我们的消息队列的配置去复制到对应的配置文件当中,因为我们这边其实是有project和聚合两个都需要用,那为此的话我们要复制两个地方,解释一下它这个参数。
首先然后他们就那么多就是去连接,然后给他绕开,咱们包括搜索这里面的话,我们使用功能就可以。在这里肯定要逐步的改善,避免大家本地的一个安装对不对?如果说大家可能够启动失败的话,就可以告诉我说我去恢复。
然后group里面有讲究的,首先前面是我们的一个项目名称,或者说我们的一个分组名称,比如说你在哪个组里面,假如说我是做基础架构的对吧?我应该是只有安排靠我们告诉你下面的哪个项目的哪个业务,然后PT什么,不就是客户对不对?通过这样的一种标识名的形式来告诉大家,通过这个名称就能够知道他是做什么的,因为我们只有一个短链接,所以说我们的最前面的组名就直接刷到link了,然后后面才是它的一个项目。
然后topic的话大家可以看到汇报一个波浪线,是因为它本身这里面提供的配置是没有topic的,但是我又不想把它放到别的地方,就在这里面。这个是它消息全局的一个超时时间,然后下面是它捋出来的一个次数,然后这个是我们的topic以及group。group这个也比较好理解,看到没有?上面叫PG这个叫CT对吧?一个是producer,一个是consumer。
然后为了避免大家共用一个云中间件的时候,会出现你发的消息到他的队列下面去,这种情况也就是说你在这里面发了个消息,然后他项目启动了,消息就跑到他本地上去了,避免这种情况,我推荐大家这里面再加一个什么?
比如说我的名字马丁对吧?这样的话大家就完全区分开了,对不对?这里面都是要复制,但是我就不复制了,因为我给大家提的是一个这种示范作用。不对,如果说要大家这种去做的话感觉避免我想想为了避免大家使用这样相同的配置,然后有一个互相引用的问题,我想想通过能通过一个什么去给他做。想象,那算了就靠大家自觉,如果大家启动的时候,如果用我们group键就这样加一行,在后面贴上自己的独特的名字或者独特的标识好吧?
这里我就不讲了,大家自己写的时候要注意,然后我们继续去看一下消息发送者在哪我就不复制了。在producer给大家解释一下。
首先我们把引进来对吧?因为我们发送,然后其次我们这里给他产生一个key,这个key是用来做什么?是用来帮助我们在消息队列的平台里面去看看这个消息轨迹,以及它对应的一个消息详情的查看,然后这个是去给他设置给他把这个里面去设置,这个key我们消费者去明白吧?
因为我们已经没有必要我们在这里需要注意的,就可以了,我们是这个key,然后这个是我们设置一个message里面用的,我们通过同步去发送,就是topic我们出来的一个消息体,然后注意不管你在生产当中还是在自己本地开发当中,一定要打日志的过程要包含以下几点,比如说你什么场景,然后消息,所以这个消息是给我们返回的,明白所对应的独一无二的消息key,这个消息key是我们自己业务里面去设置的,相当于假如说你这个消息有问题了,你能够在咱们的控制台里面能通过两种方式能查到什么呢?未来表扬,把这个产品了,我们在这里看到没有,它能够根据topic去发消息,能够给你message以及message ID。
我们给一个message是这样,等我们改造好了之后,我们在这里搜索。然后然后发送如果说异常了,那么我们就在这里把日志给打出来,并且一定要把异常给打出来,有很多同学喜欢怎么着呢,就是喜欢只打一个日志,没有把异常打出来,或者说甚至说不打这个人肯定是不行的知道吧?
然后这里面有个自定义行为,就看大家日常在公司当中是怎么去规范这种发送MQ的一个异常行为,对吧?你可以发送报警,你可以去发送同事都是的,我们比较开放,所以说我们就仅打日志,然后大家可能会比较疑问,看到没有?为什么报错说找不到这个类的bean,明明我已经把他的依赖引进来了对吧?
@Start就是帮助我们快速去启动某个组件,他为什么找不到他的bean?这个问题是因为在这个Spring Boot 3里面,谁知道是因为我们是不能不疼(不能自动扫描)。Spring Boot 3它的这种启动的顺序是不一样的,或者方式不一样。
我给大家看一下,老框架他们Spring Boot 2.4分布的starter。稍等。看到没有,它是通过2.4版本去生效它的,但是Spring Boot 3已经就是它的生成方式已经变了应该是什么方式变成了要创建meta-inf噢我这已经创造然后再去创建一个这样的文件。不是文件夹是文件。然后把这个内容给粘贴进去,Spring Boot 3的这种其他的生效方式已经变了,所以说我们只能自动给他去生效。
当然可能是RocketMQ还有这个版本比较新的话,他就适配了Spring Boot 3.0的,但是我没有去研究,可能就是版本升高了,这个问题就不用我们自己去手动去触发了对吧?
Ok现在就找到了对不对?然后我们确定一下消费者的一个行为,然后消费者首先我们要加一个@RocketMQMessageListener注解,两个必须的消费者组,一个是定义的topic,一个是定义的消费者组。
我们的topic它是可以支持这种通过工厂里面去取值的,不需要我们去把厂商写进去好吧?大家都明白通过配置的形式就过去就像这种application一样明白。
然后我们通过咱们就在哪去获取它的一个接口实现。首先我们传的是什么?我们这里面传的是不是在哪里?我们这里面它的消息体是不是它的map形式对吧?我们这里面它进行序列化的时候要进行反序列化不明白吧?然后它会实现一个I,然后我们这里面要把key取出来,要当做我们的一定的一个标识,对不对?
然后代码我稍微改了一下,把那些什么某某的行为我都给删掉了。然后我看一下还有哪里要跟大家说其他的好像就没了。然后要删除rights,数据不准备删。那一块肉有一张对接上,然后这样的话应该就没问题了。
来我们重启一下。现在不是这样。加油。所以说不知道,因为发现一下现在今日两次刷新一下应该变成数字,可以看到我们的消息已经过来了,然后也都比较顺利,然后我们看一点。还有什么?刚才一路给大家一个消息key。
为什么我们要在这里面打印可以,因为我们的key是可以查询的看到这里面有非常详细的一个trace,对吧?这么的已经消费了,然后它的消息体是什么?以及他的消费者组是哪个对不对?如果你不打这个key,人家告诉你说我的这个消息发送失败或者怎么样,你怎么知道是哪个。
然后消息的话也可以查询你看到没有在这里也能够查得到对吧?Okay,消息就是和有什么区别,为什么要因为是我们生产的消息ID是我们成就这么简单好吧?
然后我们把代码不能提交到main分支里面去,差一点给大家忘了,sorry。我们把这个分成复制一下。这是我那天想做没做的,然后做到今天,所以我之前这个框架我然后我们去弄一个分支,然后分支命名的话,我是推荐大家怎么做如果说,你是个开发形式的分支对吧?比如果是优化的就叫optimization对应单词,然后develop是开发时间这是我昨天做的,然后今天做的对吧?然后可能给我扩展-,你的姓名你说是什么,ok我们可以走。
干什么?不动重构消息队列,重构。Ladies使用消息对接,变更为老朋友。能够这个能不能提到?他得把我们公用的有可能配置给提上去。这个还是要提交之前看一下代码,然后大家如果想看这个对应平台的话,记得我们的域名加上8088,好吧,这个是我们公司还有一个端口。
Ok现在提交东西了。然后大家如果想看这个代码怎么看呢?点击它的仓库,然后加上分支,然后看我们本次提交就可以了,明白吧?有问题欢迎评论区回复。
然后我们在删除的时候多删了一步,就是这个删如果抛出了异常,我们要去把消息的标识给删掉,这里给删错了,ok我们给它加进来,然后因为这里面已经抛异常了,然后我们不能确定它是一个首保,为什么要跑首保?之前应该跟大家讲过的就是像这种网络的这种调用,它一般触发的异常是我们不可知道它不一定是Exception,有可能是Throwable还要更高对吧?或者说它的层级可以在不是平级的,为此如果说你只有catch是捕捉不到的,那么你只能用最顶层的Throwable去捕获。
然后我们这样做。只是把它的异常给记录出来,这边就不要做其他行为了,抛的话还是要抛这个Throwable包好,把代码提交一下。
最新的代码是改回去了吗;RocketMQ 有个单独的分支,main 分支一直是 Redis Stream;示例环境中用的 Stream 哈哈,因为 RocketMQ 只是告诉大家怎么写,后面的代码没有继续迭代的;加一个mq,俺滴轻量服务器也遭不住hh
想请教马哥一下,RocketMQ在消费者消费的时候,为什么判断幂等时候,幂等标识使用keys呢,keys对应的值不是UUID生成的么?这样能保证唯一标识么,是不是还是应该使用RocketMQ自带的唯一标识进行幂等判断呢?
普通情况下都是可以的,只要是一个唯一的标识就可以。 不过可能会有极端场景,举一个场景:生产者发送消息到 Broker 超时了,但是 Broker 其实并没有执行失败。然后消息发送者以为失败了,默认执行重试,然后第一次执行成功,重试也成功了。 对于 Broker 来说,其实是两个消息,消息 ID 是不同的,所以就没有办法了。
https://t.zsxq.com/19uAxXHYG-知识星球
- 第06节:重构短链接分组监控以及其他优化
重构短链接分组监控以及其他优化 - 监控表删除分组标识 - 当天监控查询取消分表 - 监控历史数据分页失效 - 修复原始链接变更缓存未更新场景 - 前端登录小优化
这节课和大家聊一聊短链接分组变更的时候会带来监控表大量的数据变动问题。
首先背景是这样的,因为我们在监控表里面除了gid用来做分组监控查询的,我们的初衷是想让它更好的支持分组查询,也就是监控的功能,但是它有个问题就是当我们短链接的访问量比较大的时候,它会有一些监控信息,它都是一条一条的记录。
如果说,我们变更分组的话,我们相关的监控表里面也要去做这种记录的变更,这个量级就非常大了。
首先我们是有一个短链接,单单个链接的监控,其次我们还可以监控你整个分组下面的信息,这种情况下如果说我把这个短链接换一个分组对吧?它的一个监控信息要跟着大量的变更,大家理解一下这个背景。
也就是说如果说你传的链接就是解码后的和我们的原始的接地不同,那么就要开始进行大量的变更的一个逻辑。这种的话假如说我有几百万人访问了记录,可能修改几百万条记录,这种情况下是绝对不能够被允许的。
为此的话我们换一种实现思路,那就是我们的gid就不再存储到监控表里了,而是通过短链接表和监控表走一种内联的形式去解决分组查询。
什么意思呢?我们看一下,之前的话,我们假如说去查询监控数据,我们只需要查一张监控信息表就可以了,然后通过他的G ID去查询指定的分组,ok,现在我们已经没有分组标识了怎么办?
我们就需要引入短链接表,立刻走一个银行交易的形式,通过短链接表里面的gid去进行筛查,然后其他的从监控信息表里面去筛查,所以说两者做一个互补,能理解吧?
相关的这种监控表的这种SQL改的还是蛮多的,大概改了43个文件,当然不只是这一个短期监控的重构,还有一些其他的小的变更,我会在下面一点点跟大家说。
第一个问题我们已经知道了,那就是监控表我们删除了分组标识,然后通过短链接表和监控表走一个内连接的形式去解决了这种大量变更的一种场景,ok。
然后第二种的话当天查询就是当天的监控我们取消分表,提高link_to_day这张表,之前我们是用的gid进行分表的,对吧?然后SQL语句。太阳,对这个SQL语句是通过gid两个进行了一个校验,但是这会有个问题什么意思?
就是我们的短链接表里面这个分类里面已经没有gid了,为此的话就两个如果分秒钟就会产生二级之前,我在视频里面跟大家是有讲过的,为此我们只能换一种思路,什么意思?取消分表!
Two_day也就是当天的监控的一个分表,然后它会有一个问题,就是我们提到那个图表里面,它的记录会越来越大,这种情况怎么办?
我们可以采用这种方式是什么?就是冷热存储就是冷热分离的意思,就是我们把需要用到的记录全部存到提到那个表里面,相当于之前的记录我们其实是已经用不到的,能理解吗?
因为我们这里面是只需要查询当天的今日数据对不对?如果说非今日的其实我们基本上已经用不到了,我们是不是可以就把它给它迁移到另外一张表上去,比如说today_backup这个标准去,如果说将来别人要因为某些事情要查一下之前的某天的监控记录,我们再给他查询出来对吧?
去这个表里面然后去查询就可以了,对吧?我们写一个定时任务让他去进行迁移,比如说我们可以不仅是保存一下,我可以保存一个月对吧?如果超过一个月,我们就从主表里面迁移到我们的备份表里面,那这样能够保证我们这个表里面都是热数据而且数据量不会特别多。
然后第三点的话,就是我们监控历史数据分析失效的问题,就是在这里。这个没怎样。我们要好在这里。
大家现在的代码应该是分页是不生效的,为什么?是因为我们这里面在后管里面它是没有传当前页以及size的,所以说整体的一个分析的情况是没有的,我们在最新的代码里面是已经修复了,大家看一下将来的提交就可以了。
第四点就是前端登录的一个小优化,首先你之前登录过期的话,假如说我们现在这种场景你登录过期了,假如刷新页面或者掉接口,它是只会反馈给你401,他不会直接调到登录页面,但是这种交互肯定不好,然后通过我和前端同学的一个沟通也确定是一个bug,然后这次把它优化了。
相当于如果说你假如现在已经是一个登录过期的状态,假如点个查看图表,他只要返回给401,马上它会跳转到登录页面,好吧,大家可以尝试一下。
然后因为本次的变更的点比较多,大概有43个文件,所以说我是直接把代码写好了,给大家去讲解一下就可以了。
我先把前端的提交了,前端的东西其实对我们来说作用不是很大,先把它提交了。
refactor:前端功能优化&登录失效问题修复
然后我们的link_access_hourly表里面因为删了挺多的字段,就是监控表里面gid,所以说大家可以重新执行一下自己的SQL,把整个库里面的之前的表信息给删掉,然后重新执行一下,我们这里面也给他提交一下。
这样的话大家可以看到,你像我们这些SQL里面都已经把gid给删除了,然后你像我们这些Mapper里面都通过之前的单表查询,然后变成了我们现在的图表查询,也是通过进行一个链接,相当于我们后续再变更的话,所有的分组的相关的技术变更只会变更,我们地方认可,就没有相关的任何变更了,我们可以瞄一眼。
对修改接口修改结果之前很长的修改结果对吧?还有看到这个东西锁非常标注,之前非常好,现在只有这些。然后在这里面。
还有一个好像我记得之前有位同学提了一个点,就是修改了原始链接之后,它是不生效的,我给大家测试一下。比如说我们给他改成一个原始链接之后,看他能不能找到证据,可以看到我们修改链接之后,它是没有调整对记录的,为此的话我们这里面还要做一个小这里是一个小bug。
是就bug不是小bug。我们重启一下。重启之后一下就好了。那我们再讲一个可以了,就可以做这种正常的计划。
然后我这边也提交一下。修复。
fix:修复短链接修改原始链接缓存不生效问题
然后我们这个代码先不要提交。为什么?我们这个里面是要保证纯正一些短链接分组变更的,然后我们要单独去提交,然后这个里面去把一些短链接内核对以及之前的1个绑定表的关系都给删除了这4个文件都变更好吧,大家都要改一下,其他的应该都还好,就没有其他的大的变化,我们改一下,然后我们再把给它加进去。
然后卡了。不好意思我们稍等一下。那么你怎么忙?我试一下强制退出,如果不行的话这个视频就先到这了。
刚更新到2024.1,昨天刚更新的今天。就尴尬了,不好意思。修复。
Ok大家就可以根据这4个提交来变更一下自己代码里面的一些变更点好吧?另外有什么问题欢迎跟我沟通。
- 第07节:监控保存Gid错误&短链唯一
今天这节课给大家带来两个问题,首先第一个就是队列在消费的时候,也就是我们消息队列的消费者是需要读取最新的GID的。然后第二个不同分组下,我们去创建短链接的时候能保证唯一吗?
我们先说第一个问题。
首先之前的话我们在短链接监控的时候,也就是在发送这里面,我们是有传递GID的情况,什么情况下传递的?就是我们的短链接刚好在缓存里面失效了,那么他会去读出来他完整的记录,然后我们再去发送者发送MQ消息的时候会把GID给他带上。
当时我们想的是这样不就省去了一次数据查询对吧?但是有一些小伙伴给我留言说这种可能在一些场景下是会有问题的,我们一起来看一下。
假设我们现在有短链接对吧?-123,然后分组的话是GID它是ABC,这个时候我们执行一下逻辑,进行短链接在变更分组的流程对吧?
我们将ABC的分组变更到BCD,那么我们在获取到写锁执行流程的过程当中,这个时候有某个用户去访问短链接,恰巧它的缓存失效,然后我们去数据库读取出来,记录查询出来它的短链接GID是ABC,然后我们去给它投递到消息队列。
给大家描述一下代码,我本地稍微改一下,不过不要紧,能够看一下。加记录。
大家看一下。点错了,不好意思。
首先这个是我们的跳转URL的接口,然后如果说它的缓存不存在,那么我们会一步一步的执行分布式锁,然后最终去读取出来这个记录,然后把它的监控信息发到MQ里面对吧?
在这里大家可以看到,我们是已经读取出来这条记录了对吧?从数据库里面然后会把GID给他带过去,也就刚才说的能够对得上。
这个时候假如说我们的消息队列获取到了这个消息去给他进行写入数据库,这个时候因为我们的写锁正在被占用,那么我们的log就是获取log会被阻塞对吧?
再然后我们到县城就是修改短链接分组完毕,正常的话就释放解锁,然后GID从ABC变更到了BCD。
然后消息队列他消费的时候对吧,就能拿到读锁,将我们的短链接-123和GID为ABC的记录进行操作,那么就会产生一种数据错位问题。
大家理解一下就是这个场景,因为它是读写并发的,不是某个单线程的场景,所以说可能会有一点绕,大家想一想应该怎么想得通。
针对于这种场景我们做了一种解决方案,那就是我们在客户端所有传递的地方全部去掉,我们的GID就不让生产者去传了,而是说我们消费者也就是消息队列的消费者去数据库里面重新去查询。
这样的话能够保证我们的短链接的分组ID是实时最新的,对吧?
我给大家看一下代码,之前的话这里面有一个判断,首先判断是否为空,如果为空的话我们再去查询,现在就不需要判断了,我们直接就去查。
那可能会有小伙伴有疑问对吧?每次都查询数据库对我们的性能有影响吗?也就是对数据库的性能有影响吗?
其实没有,为什么?是在消息队列的消费逻辑里面,众所周知消费消息队列它是执行完一条再执行下一条对不对?所以说它同一时间不会有大量的并发,为此的话我们查一次数据库是没有任何问题的,能理解吧?
所以说基于这种场景,我们这样去改造,就能够保障我们的流程,在其他场景下不会有问题。
我先提交一下。应该叫fix,这算是一个bug。
修复:短链接监控保存GID错误问题
Ok,这是第一个问题。
第二个问题就是:不同分组下去创建短链接的时候能保障唯一吗?
假设我们有两个分组,分别是ABC和BCD两个分组的GID,那么它们分别就是两个分组在创建的时候去创建出来的短链接是-12356,那这个时候我们能保障12356两个分组下只能创建一条吗?我们能保证吗?大家想一想,对吧?
可能很多同学能说会保证一致,因为我们在数据库做了一层唯一索引的兜底对吧?但是对也不对?
首先如果说他们两个分组分到了一个表下,这样的话是能够保障唯一的,因为唯一索引肯定能保障唯一对吧?
但是因为我们link表是按照GID分组的,如果说他们两个取模之后不在一个表下,自然没办法让短链接保证唯一对吧?
这种场景下我们该怎么去做?
我们有一张link表,不知道大家还有没有印象,在短链接跳转的时候,因为只有一个短链接没有不知道它的分组的分配件,我们通过完整的短链接去找出来它的分组标识这种形式去做一个跳转。
这种场景下我们是不是可以考虑在link表里面加一个字段,或者加一个唯一索引,这样的话不就能够保证它的短链是唯一的吗?
因为我们这张表是按照完整的短链接进行分片的,所以说一模一样的短链接,他们一定能在一个分片上,这样讲大家能理解吧?
然后如果说他们两个有问题了,一模一样的记录插入进来的话,它就会触发唯一索引异常,在我们的业务逻辑里面可以捕获处理。
所以说我们在第一层唯一索引如果他能过去,那么在第二层他也是会判断出来的好吧?
为此的话我们的问题也已经解决了,通过我们提供了一个link表,然后我们要修改一下link表的表结构,因为之前我们是没有加索引的,所以我们现在要加一个唯一索引。
当然如果大家已经知道这个东西了,你是可以不用加的,因为只有在极端情况下会产生这种问题,或者数量大的情况下会产生,如果大家自己的项目应该是不会有太大问题的,当然我这里是要改。
这个叫别的fix。
修复:短链接跨分组唯一性问题
然后这里还要跟大家再提一嘴是什么呢?大家可以看到我们用了很多hutool下面的一些包,然后给我们报了一些其他的问题,对吧?
本质上就是IDE在提醒你说,之前的版本可能会存在一些漏洞,我们针对这种应该怎么办?
一般的话你用了你就去GitHub某个包的他或者她最新发版,比如说你用hutool的话,我们可以看到他两周前发布了一个5.8.27的版本,我们就可以把这个5.8.27给它替换一下。
我们是用20我们替换一个27来刷一下,因为我本地已经之前装过了,把1236的项目给改过来,行,所以说他下得很快,我们可以再看一下还有没有问题。
不知道为什么它这里还是有问题,我们一起倒一下,试一试看看它是不是实时做的时候今天生效。
可以看到没了,通过分析的话,它有可能是基于那些什么,他给他那边的class去做分析的,只是有可能或者可能是IDE的一个响应延迟对吧?
布隆过滤器不是就可以保证短链唯一吗?不行的,在并发情况下,A去查布隆过滤器说短链接不存在可以插入,那么插入开始(这个时候插入未完成,布隆过滤器还没有更新)。 在这个没更新的间隔,B也过来了,B也能够通过布隆过滤器开始插入,而刚好又不是同一个gid分到了不同的表,那么兜底的唯一索引失效,也就会生成两条一样的短链接。
这里不是有问题吗?如果写锁已经被获取,那么缓存失效后要读取数据库也得拿到读锁啊,此时读锁已经拿不到了怎么会把原始gid投递到消息队列
学不会的小王 回复 A:我也有这个疑问,这里想不明白
阿宝 回复 学不会的小王:去数据库获取短链接原始地址用的不是读写锁吧,统计状态信息的时候才加的读锁与修改分组的写锁互斥
- 第08节:优化大量空缓存查询数据库&修复后管限流逻辑
今天还是老样子,我们对短链接系统做出来两个问题的 fix。
首先第一个问题,如何防止大量空缓存查询数据库?
然后它的问题背景的话是一位同学对查询空缓存那里也提出来一点疑问,我们一起看一下原题。内容比较长,大家我就不读了,大家看一下我来总结汇总一下。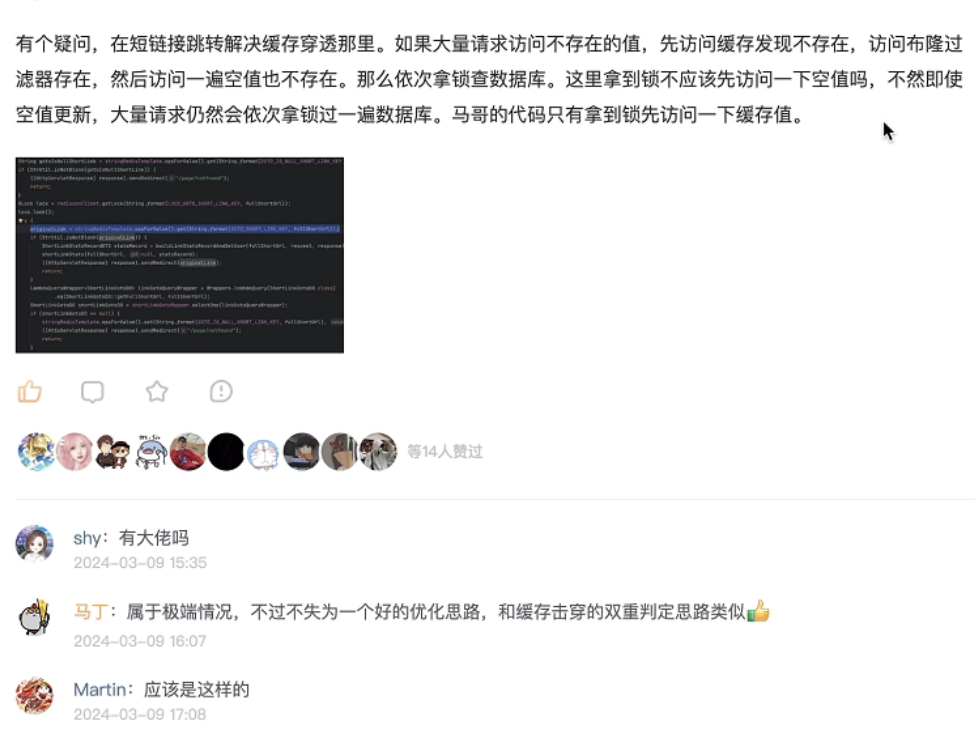
首先这位同学的意思是什么?就是如果说有大量的请求来访问那些空置的缓存,如果说按照我们现在的逻辑,他会大量的去拿到锁,去过一遍数据库,然后它的意思就是什么意思?
我们可以在拿到锁之后去查一下空缓存是否有,如果有的话就没必要让他再查数据库了,和我们双重判定锁的逻辑是一样的。
当时我也给他做了一个回复,只不过这个事情到今天才会把这个代码提交上去,然后我们一起看一下。
其实解决问题的思路很简单,拿到锁之后之前我们不是双重判定对吧?他会去查询一下短链接对应的缓存是否存在,如果存在的话,那么它就会进行一个跳转。
但是如果说它是空缓存,它还是会走一下接下来的流程。
我们看一下,如果说我是一个空缓存,那么在这里肯定是fast对吧?因为我是肯定不存在的,这一行是我新加的,我先入目的,然后他就会去查询数据库,最终会给他去加入到一个控制缓存里面去。
如果说大量用户去访问一个类似于这样的空缓存的话,我们是否可以在这里面加一行代码,和上面的双重判定是一样的逻辑对吧?
他就没必要再去查数据库了,可以进一步提高我们的接口吞吐量。
毕竟访问一下缓存和访问数据库还是有一定的性能差距的,虽然说可能会很小,但是在高并发的情况下,它可能就会是一些比较可观的性能提升,对吧?
这是解决方案,然后可能会有一些较真的同学,他可能会有一些疑问,就是为什么我们获取到锁之后先查缓存是否存在,而不是先查空缓存是否存在呢?
这个问题其实很简单,它会涉及到一次无用的网络IO。
我们举个例子,如果说这个用户是访问的缓存是我们中间存在的,假如说我们去先访问空缓存,那不就相当于是一次无用的网络IO吗?因为空缓存肯定没有的对不对?
反过来如果说我们的用户访问的都是一些空缓存,那么先去访问一下 Redis 对应的缓存对应的原始链接,它肯定也是不存在的。
那么总的来说,如果我们希望说系统里面的用户都是正常的访问,那么我们就把这个查询对应的原始链接缓存就放在首位,反之则把对应的空缓存放在上面。
这个很好理解,大家想一想就应该能够明白的。
然后我把这个代码提交一下,这里应该是叫做一个优化,这个不是问题。
然后第二个问题就是修复后管限流逻辑无限刷新的问题。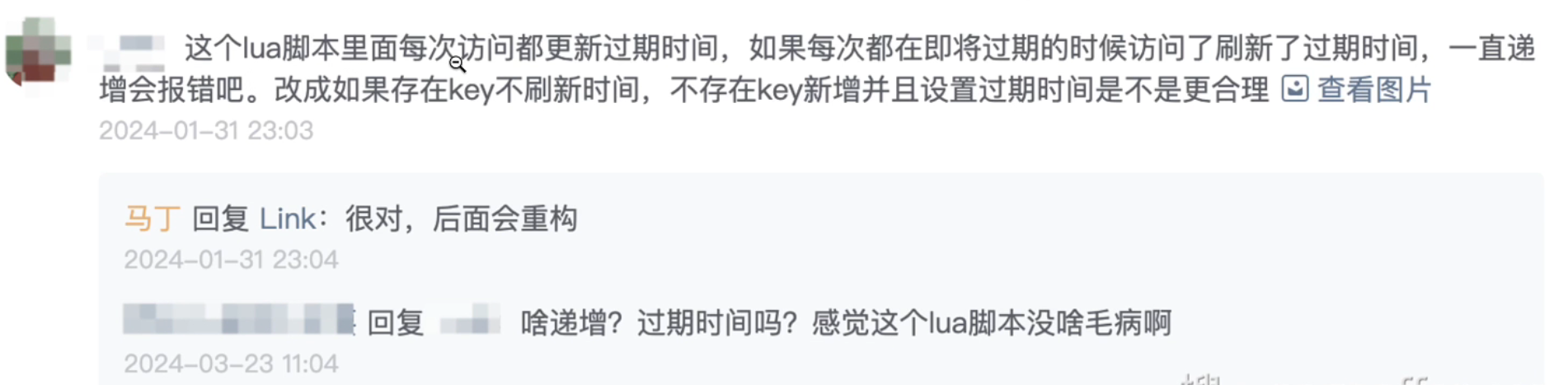
这个同学提了一个点,就是如果 Lua 脚本里面每次访问都更新过期时间,那么如果每次都在即将过期的时候刷新了,过期时间一直递增对吧?
那和我们之前的一个逻辑是不相符的,为此的话我们做了一些改善。
简单的提要一下之前的一个逻辑,那就是我们后管里面不是说一秒钟之内对吧?你能访问多少次,比如说1秒钟之内能访问5次接口,那么如果说用户访问了1秒6次,那么它就会报错对吧?
这是我们之前的逻辑,我们每次都会对用户对应的限流KEY给它进行自增,并且给它设置一个过期时间。
其实这里是有问题的,就像刚才那个同学讲的一样,如果说我设置的是一秒去访问10次,假设我在一秒的最后一个毫秒我又访问了一次,对吧?
那么它会无限的去刷新过期时间,只要别人逮着你这个漏洞,它就相当于会无限的刷新,对不对?
为此的话我们做了一个优化,就是只有在限流KEY它不存在的时候,我们才对它进行一个设置过期时间。
能理解为什么我这里面设置原子递增等于一的时候再设置过期时间,是因为第一次自增完成之后的数据,就是一。
假设我里面有一个count的字段,它是没有值的,相当于是个空值,那么我给它进行 incr 之后它会返回一,那如果返回一的话就证明它是个空值。
和上面这位同学提出来的逻辑是一模一样的,就是不存在KEY。新增并且设置过期时间对吧?如果说存在KEY则不刷新过期时间是一个道理好吧?
大家也捋一捋,是个比较常见的一个场景题,然后我也提交一下。
Fix:修复后管限流无限刷新问题
然后大家如果说在看代码的过程当中,如果发现问题,非常欢迎和我沟通。
一般来说,如果是问题的话,我会先跟你说清楚,说清楚之后,因为我们的视频我们的代码是跟着视频一起写的,所以说这个录视频才能够去写这个代码,大家能理解吧?
所以说可能这个视频录的有一些延迟,但是最终一定会发上去好吧?非常欢迎大家跟我沟通。
我们这节课要讲的事情大概就是这两个点。
总结一下这一节: bug背景:短链接跳转过程中,如果大量并发请求尝试访问一个不存在的短链接,且刚好被布隆过滤器误判为数据库存在,并且此时如果还没有设置空缓存的值,这些线程都会尝试获取锁进行数据库查询。 解决方案:在获取到锁之后,先查询redis中是否存在短链-长链的映射,如果没有,再查询空缓存是否有值(本节视频新增)。这样做之后,除了第一个线程会进行数据库查询失败并缓存空值之外,其他的线程在拿到锁之后就会因查询空缓存有值而直接返回,避免对数据库的访问。 获取到锁之后,为什么先缓存查询而不是先查询是否存在空值?——个人理解是,上述这种访问不存在的短链接并被布隆过滤器误判为存在的概率是极低极低的,大部分情况下都是正常访问。而在正常访问情况下,大量请求访问同一个存在的短链接,先查询缓存比先查询是否存在空值会减少一次网络IO。如果考虑的主要问题是系统是否会被大量恶意请求攻击的话,先查询是否存在空值就会好一点。
- 第09节:修复用户访问短链接监控数据横向越权问题
有同学给我反馈过一个问题,那就是我们的短链接监控数据的查看存在一个横向越权问题。
什么是横向越权?就指的是假设我们系统当中有两个用户A和B,A可以访问他自己创建的短链接下的监控数据,B也是同理。
横向越权指的就是我们用户A是可以访问用户B他创建的短链接下的监控数据的,为此的话叫做横向越权。
**针对这个问题怎么解决?**
就是在我们访问短链接监控数据的时候,需要确认短链接是属于当前登录用户所有的。
但是现在有问题,我们的分组标识(GID)在用户下是唯一的,咱们把那些表里面是仅存储了GID这个标识码,相当于我们两个用户上面现在是可能会有一样的GID的,这样的话我们就不能够通过link表来判断出这个短链接它所归属的用户。
为此的话,我整理了两种解决方案:
**第一种方案**:我们可以在短链接里面加一个字段,比如说用户ID。我们可以通过这两个字段一起去判断归属。
但是这种方案有一点不好的是什么?因为我们之前的数据是没有任何关联的,相当于你在link表里面加上一个字段,你很难去和他的GID去进行一个对应对吧?
而且在生产环境当中这种肯定是行不通的,就像刚才讲的,你没有对应关系就没办法去给他清洗数据,因为他有可能有两个一模一样的GID,你不知道他是哪个用户的。
为此的话,我们可以换一种解决方案:**把分组标识改成全局唯一**,也可以避免修改之前的一些字段。
**修改GID唯一的话我们大概需要去改两处地方:**
第一步的话就是修改它的唯一索引,就是我们之前的group表,它之前是使用的用户名 + GID内容当做一个联合索引就是唯一的。
但是我们如果说要使用GID全局唯一的话,就不太能够解决这个问题,为什么?
因为用户名去进行分片,分片之后有可能他的单个用户或者说多个用户创建的GID,它不在一张表里面,这和我们的link表的原理是一样的。所以说我们的唯一索引就失效了。
所以我们直接把它的建立变成一个字段就可以了,我可以删掉。
为此的话我们是需要去创建一个全局唯一的GID的一张单独表去对接,进行一个唯一索引的兜底。
然后我们看一下这里的话,如果说直接地这个是创建或者插入没有关系,为什么?是因为我们给他设置这种唯一的时候已经通过提高group这张表,就是唯一表去给他去做了一个校验,然后所以说加到这里面的话一定是GID是唯一的。
所以我们这里将设置,然后这张表里面只有一张字段,我们的分组标识就这一个字段。
**我们在进行设置分组标识的时候:**
之前是通过用户名和分组标识一起去加的,判断现在我们改成建立单独控制,然后这里面加了一个布隆过滤器建立的来对数据库减少一些压力。
然后它的配置的话相当于我们之前用户名的配置的两倍,为什么?是因为用户下面可能会能创建多个分组标识,但是我们也不要太大,因为它有可能是用户创建完,它只是用默认分组,所以说我们要尽可能的去让它的逻辑给控制在一个可控范围内。
为此的话我们这边在生成的时候去做一些判断,因为它不能布隆可能会满,所以说我们这里在判断GID之后是否可用,我们加了一个最大值的字符数限制。
所以如果说他这边没有问题了,然后才会添加到叫做我想想叫做分组标识里面。
在之前他怎么去判断这个GID就是分组ID可用?
首先你要经过一次布隆过滤器的一次过滤对吧?然后其次我们还要再加到这个唯一表里面,我们相当于是一个路由表,也可以说是一个唯一索引的一张表。
如果说它已经插入失败了,我们可能就会代表说它已经被使用过了。
另外还有一个小插曲:
我们之前用户注册的方法上面,之前我们的布隆过滤器在上面,但是现在我们给它调到了上面,为什么?
因为我们如果说现在布隆过滤器成功,假设我们插入group失败了,它是没有办法去新增去唯一功能的。
为此的话我们像这种不可能会唯一数据要尽量把它放下来,只有这样的话它上面假如失败了就不执行它直接回滚。
如果执行它成功了,大概率它也不会失败的,如果说它失败了OK直接回滚也不会对工程布隆有什么影响,大家可以去想一想,逻辑蛮简单的,算是一个小优化。
当我们把上面的GID设置成全局唯一之后,我们就要去做一个用户的权限校验检查了。
关于检查的话其实是有两个逻辑的:
首先它是通过 my(后管) 去调 project(业务) 对吧?这样的话我们需不需要在两个端都进行校验,或者说在哪个端校验?
这里我给出来了两个方法:
第一个方法:两个端都校验。如果用户访问越权直接在 my 层就直接进行拦截,就避免了这个无端的一个调用对吧?
那缺点就是如果用户没有越权会多一次 my 层的检查性能,因为我们去检查用户是否越权了,说白了我们是去查数据库的,能理解吧?
查了数据库,他看他的这个关系是否存在,用户去检查他的分组ID,如果不存在就证明越权了,不存在这里面没有维权。
第二种方法:只在 project 里面单独校验。如果用户访问越权,会多一层无效调用。
它的无效调用指的是我们本来可以在 my 层去给它进行拦截校验,但是你经过一次网络 IO,my 掉了 project,然后再去判断。
优点就是用户如果没有越权的情况下,它少一层 my 的检查,它的性能会更好一些。
综合这两个点的话,我最终选择了使用在 project 里面校验。
因为我们做系统的话,就是面临正常用户访问还是要多一些的,对不对?
如果说面临用户正常访问和不正常访问两种情况和系统挂钩的时候,我们要尽可能的去选择相信用户对吧?
所以说我最终选择了第二种,但是在某些场景下,比如说访问的是敏感数据 ready 接口,那我就倾向于 my 和 project 都校验,这取决于你的性能成本的一个问题好吧?
然后我们监控方法里面大概有4个,
所以说只要在每个方法的开头去加一个 checkUserAccess 方法,判断该短链接是否属于当前用户就可以了。
但是这里也有一个小的问题不知道大家能不能思考出来,就是我们的用户上下文的一个变量。
众所周知,用户上下文是我们在后管里面有的,我们之前的 project 里面是没有用户上下文的,大家可以去翻一下代码。
因为之前我们的用户的一个访问的话,是直接通过网关去把用户信息传递过来,但是我没有用过,为什么我们是获取不到信息的?
怎么办?有两种形式:
第一种:我们可以通过参数的形式,但反过来比如说我们在监控方法里面加一个 userId 参数,这样行不行?完成功能肯定是可以的,但是如果说我直接去调用你的 project,这个时候我们是可以伪造 userId 的,明白吧?
因为我们之前讲过这个是可以单独的可以进行调用的,然后 my 是面向这种浏览器或者说手机端的这种页面去做的,所以说这是不行的,明白吧?
第二种:我们是在 my 里面去把它的用户上下文信息给它透传过来。
怎么透传?我们是通过 openfeign 进行网络调用的,对不对?
我们在这个 openfeign 里面给它加一个类似于拦截器的一个东西,然后把它的用户上下文,通过 header 传递过来,跟你说这个很简单,就相当于加个 header 加一个 token 的品类,然后我们在 openfeign 的 remote call 结构上给它加上这个就可以了。
这没有把 remote 加上,这里面的话还是和大家简单说一下。可以了。
我们通过这种方式配置上之后就可以去做这种透传了。
然后我之前有同学跟我讲,我们之前都是用过来的过滤器去做的,然后大家说可以尝试一下拦截器,为此的话我们的拦截对吧?通过这个普通的一个拦截器去做。
然后我看一下。没问题。不过名字可能要改一下。Filter. 过滤器的意思我们直接给它改成 checkAuthInterceptor。
然后我再多讲一下我们的为什么后面加一个是因为我们给大家去创建聚合项目的这种方式,它两边的 bean 会有一个冲突,所以说我们去创建了通过这个名称给他制定了一下 bean 的一个内容,如果正常大家只有说把这个和 my 是没有这个问题的,好吧?
总结一下:
- 修复了短链接监控数据的横向越权问题
- 优化了 GID 的生成逻辑,改为全局唯一
- 增加了布隆过滤器减少数据库压力
- 优化了用户权限校验流程
- 增加了 my 与 project 之间的用户上下文透传机制
视频里提交 t_group_unique 表索引命名错误,已在项目 SQL 中修复。大家添加表时请执行下述语句: CREATE TABLE `t_group_unique` ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'ID', `gid` varchar(32) DEFAULT NULL COMMENT '分组标识', PRIMARY KEY (`id`), UNIQUE KEY `idx_unique_gid` (`gid`) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
总结: 缓存穿透解决方案 解决方案:使用布隆过滤器,但是做了改进:布隆过滤器 + 缓存无效数据 注意:这里的缓存无效数据和传统的缓存空值不一样,因为它的key的前缀和正常数据的key的前缀是区分开的。相当于单独对那些不存在的数据做了缓存 思路: 首先查缓存,如果缓存存在,直接返回 如果缓存不存在,查询布隆过滤器: 如果布隆过滤器里不存在,说明一定不存在,把这个key放入无效数据缓存里(设置较短的过期时间),然后返回 如果布隆过滤器里存在,说明可能存在,于是查询无效数据缓存 如果无效数据缓存里有这个key,说明这个值一定不存在,对这个无效数据缓存进行续期,然后返回 如果无效数据缓存里没有这个key,说明这个key可能存在,于是去查询数据库 查询数据库: 首先获取分布式锁 获取到分布式锁之后,重新判定一下缓存是否存在,如果存在则使用缓存,直接返回。如果不存在还需要再次查询一次空值缓存,如果空值缓存存在则直接返回,否则进行下一步。 否则查询数据库,并更新缓存和无效数据缓存 暂时无法在飞书文档外展示此内容 问题 为什么不对无效数据缓存也使用布隆过滤器?这样不是可以节省内存空间吗? 因为布隆过滤器不能删除元素。如果现在这个key不存在,以后又存在了,无法从布隆过滤器里删除 为什么要对无效数据缓存设置过期时间? 首先,无效数据缓存只在布隆过滤器误判的情况下才会插入数据,所以无效数据缓存的数据量不会很大。 为了防止攻击者故意伪造会导致误判的且不存在的数据而导致服务器宕机,给它设置了过期时间 为什么获取到分布式锁之后,再次检查缓存发现不存在,还需要查询无效数据缓存?为什么不用查询布隆过滤器了? 第一个拿到锁的线程查询数据库之后必定会更新缓存和无效数据缓存中的一个。后续线程只要判断这两个缓存就行了 在这里,布隆过滤器不会更新,不能提供有效信息
缓存空值的前缀不就是GOTO_IS_NULL_SHORT_LINK_KEY = "short-link:is-null:goto_%s"吗?那缓存无效数据的前缀是啥?
Deler 回复 全糖很多冰:空值缓存就是无效数据缓存。一共有两个缓存和一个布隆过滤器。分别是:短链接缓存、空值缓存、短链接是否存在的布隆过滤器
鉴权能不能使用 aop 或者一个中间件来做呢?感觉对 project 的代码侵入太强了,而且耦合性和扩展性都不好,如果后续又增加了许多统计方法呢?
不会游泳的我却还没上*:为什么不能使分组id全局唯一,比如使用username+6位随机数的形式。这样是不是能够解决这个问题,可能会产生的问题是这个gid会比原来长很多。这里t_group_unique感觉是会存16张分表的数据,但是相对于其他表来说这个表存的字段比较少。所以可以在同等查询性能上是可以存储更多的数据,但是感觉这个倍数跟不上分表数,不知道这样理解正确不
云海牧猪人 回复 不会游泳的我却还没上*:分组id最好是单调递增的话比较好,这样用索引查询时性能高
- 第10节:优化监控跨时间异常以及消息幂等方法命名
这节课有两个小的优化点,首先第一个就是短链接监控场景可能会存在跨时间异常,王同学说的比较明确了,我们最好不要用很多的data,而是提前new,一个就是由全局的new,而不是说到一个场景上就去new一个data,因为这样的话有极小的概率,刚好跨零点创建会有错误。 我们去看一下我们之前的代码里面,这个是短链接的监控的统计,它是在每个需要用到data的地方就去扭了一下,但是这种就像刚才讲的,假如说我们刚好跨了零点,刚好跨了一个整点,这种的话对我们的监控以及存储就会有问题,为此的话我们应该在上面用一个全局的然后直接去使用就好了。
但是我在王同学的基础上,然后又捎带脚的优化了一下,怎么去做的?我们之前的 new data都是在抗松也就是消费者里面去做的,但是如果说消用户在今天晚上23:59:58点的。但是由于网络波动或者说消息积压,然后我们消费的时候可能已经到第二天了,为此的话可能有一点不准确,当然无伤大雅,但是我们可以给他去尝试做一下优化,为此的话我们在这里传了一个更看人的对他的一个字段,这样的话就能够比较好的解决我们刚才聊的问题。先提交一下。算了。因为这次有两个优化点,他们两个是耦合在一起的,所以说我们就分一次提交就行了,然后这是这位同学提的问题非常好。
第二个问题的话是关于方法命名的问题,我们在进行消息队列密等处理的时候,那个方法名取的不是很好,然后这位同学提了一些建议,为此的话我这边去给他做了一个内部的逻辑处理,以及方法名的优化,相当于之前的话是通过处去比对,然后外面去做取返,现在的话我们把取返的逻辑删掉了,然后通过files去进行比对。因为昨天我提交的代码里面那一版的优化做的不是很好,所以说这里就是单独的再做一次提交
- 第11节:Redis-Stream消息队列问题答疑
然后今天也是在研究 Redis 消息队列的一些问题,然后有了一些进展,给大家录视频去讲解一下。
之前有一位同学给我提了一个建议,或者说提了一个问题,他说为什么我们在 Redis 的配置文件里面设置了消费者的形式,就是用线程池的方式去消费,但是为什么我们在消费的时候线程池永远只有一个线程在运行?
为了方便我给大家在这里面打印了一下当前执行线程,我们可以看一下都是 -1 对不对?都是 -1 对,大家可以看得到。为什么?
我给大家解释一下:
首先按照我们的常理上来讲,大家认为用消费者的形式去消费,应该是它底层的客户端拿到了 Redis 里面的消息,交给线程池去运行,大家肯定是这样理解的,对不对?
但不是这个样子,它真实的流程是:
把我们的这样一个监听器包装成了一个任务,然后通过这个任务本身去死循环去拉取对应的一个 Redis 里面的消息,然后再交由我们的方法去运行。
实际是这样子的,我给大家先看一下。
通过我们的线程只是去运行任务,运行任务是已经被包装好的一个叫做 `StreamPollTask` 的类,然后他其实继承了 `Runnable`,也就相当于我们一个监听器等于一个 `StreamPollTask`,然后在 `StreamPollTask` 里面去运行,while(true) 去把我们的相关的一些消息拉过来,然后交由我们的 `onMessage` 的方法去执行。
大家这个是比较容易理解了吧?
然后我给大家打了一些断点,相当于我们在注册的时候,它是单独的一个监听器对应一个线程,如果说有多个监听器的话会启用线程池里面的多个线程。
刚才跟大家说了对吧?任务它这个里面会有一个死循环的类,会源源不断地去拿消息,然后交由我们的 `onMessage` 的方法去执行。
所以说一个监听器它只会启用一个线程,大家应该能够明白吧?
为此的话我们这边也做了一些调整。
上面之前因为我不太懂 Redis Stream 它的一些东西,因为毕竟这东西生产上用还是要非常谨慎的,我们是没有用过的,为此的话上次的配置还是有一点欠缺,这次读了读源码修改了一下。
我们第一个改动的话,把它的这个线程池的大小改成一了,因为我们这里面只有一个消费者,所以说它最多只有一个线程在运行,那就没必要去写的太多对吧?
然后第二的话我们修改了一下,因为刚才上一次我们是用了 `LinkedBlockingQueue`,它是个**无界队列**,那严格意义上来讲是不建议这样去用的,因为它可能在消息堆积的情况下会出现一些不太好的场景,比如说 OOM。
然后还有我加了一个**拒绝策略**,那拒绝策略的话,尤其如果说触发了这样的一个叫做拒绝的一个行为,那么就让提交它的主线程去运行。
然后我们的拒绝队列也改成了同步队列。
为此的话第一个问题就跟大家解释明白了,其实是没有问题的,这是人家那边的机制所导致的。
然后第二个问题的话就是为什么消费流程执行异常后就不再消费了?
我给大家模拟一下,这个就可以删掉了。这个是我新写的代码,我给大家去回顾一下。
看到没有?他如果有一个报错之后,他后面再有的话他就不再执行了,发现了吗?
其实它是因为有一个配置,这一块的代码也比较绕,我简单跟大家讲一下。
然后它这里面有一个取消的异常,如果是异常的话,如果是 `true` 的话,那么它会把这个流程直接终止掉,如果是 `false` 它是不影响正常执行的。
那为此的话其实我们从上面改造下面这些东西就主要是改这一个配置参数,大家知道就好。
我们改完以后给大家去演示一下,两个闹了对不对?
然后这里面其实也可以控制,如果我们改成 `true` 的话,它其实也会变成如果遇到异常就会取消整个流程,大概是这个样子。
然后还有一个小的改动点需要跟大家讲一下:
然后之前我们这里面其实是有一个 try-catch 块的,但是这个 try-catch 我给删了,我给大家看一下。
对,这个 try 我删了,为什么?
因为如果说这里面有这个 try-catch 的话,那么我们这里将捕获不到这个异常,也就没办法去执行消息队列它所对应的一些幂等的一些删除 key 的逻辑。
如果是正常的消息队列的话,它的异常就不能够被 try-catch 所感知,进而就不能够再进行重试或者处理。
所以说大家在写的时候一定要把异常的捕获给删掉。
1. 解释了 Redis-Stream 消费者线程池只有一个线程的原因;
2. 分析了消费者异常后不再继续消费的问题;
3. 修改了线程池大小和任务队列类型;
4. 删除了不必要的 try-catch 避免异常被捕获导致流程中断;
5. 强调了在生产环境下使用 Redis Stream 需要谨慎配置,避免 OOM 和任务堆积。
之前写这一块想用redis stream的pel结合xpending和xclaim来实现消息可重复投递的时候,就把这里的源码看了一遍,有一说一坑是真的多,而且这一块源码只有接口是public级别的,想扩展都没法扩展。
吃个月饼 回复 RQTN:hxd你最后有解决方案吗,我现在也想做这个,要不中间消费过程中给挂掉,未消费的消息就会一直得不到消费了。但是没想好也没找到怎么在项目里比较好地处理PEL中的消息
RQTN 回复 吃个月饼:我的解决方案大概是: 1. 读取消息不做 autoack 2. 定了两个消费者,一个是正常消费者,正常消费者只会以消费者组的形式读取 stream 中最新的未读过的消息,一个是 PEL 消费者,PEL 消费者专门读取 PEL 队列中属于自己的消息。 3. 最后就是起了个死循环线程,该线程通过 xpending 不断地将 PEL 队列中空闲时间超过 3s 的消息查出来,然后重新 xcliam 给 PEL 消费者(这一步是重复投递的关键) 消息的整体处理流程是: 1. 大部分消息会在正常消费者那里就被处理掉,消息正确处理后,就会执行 ack 将消息从 PEL 中删除(是的,只有 ack 才会让消息从 PEL 中删除,delete 操作好像只是删除 stream 中的消息,消息是有两份的) 2. 如果正常消费者出现了异常,没有执行 ack,那么该消息在 PEL 中会存在,且该消息属于正常消费者,因为 PEL 消费者是只读 PEL 队列中属于自己的消息,所以此时该消息还不会被 PEL 读到 3. 死循环 xcliam 线程不断从 PEL 队头开始检查超过 3s 的消息,将这些消息重新 xcliam 给 PEL 消消费者,从而能被 PEL 消费者监听到并处理。 4. 消息被 xcliam 给 PEL 消费者后,PEL 消费者就能进行处理,如果处理成功,就执行 ack,从而消息彻底从 PEL 中删除。如果处理失败,那么 PEL 消费者会将消息重新 xcliam 给正常消费者(其实 xcliam 给任何人都行,这里主要是将消息的所属权转移出去,避免 PEL 消费者反复从队头读取该消息) 5. PEL 消费者将消息 xcliam 给正常消费者以后,其实正常消费者并不会去读 PEL,正常消费者只会以消费者组形式读 stream,从而这条消息在 PEL 中会空闲,超过 3s 后,就会被前面提到的死循环线程重新 xcliam 给 PEL,这样消息就是 3s 后重新可以被 PEL 消费者处理,在 PEL 消费者这里通过 xcliam 和 xpending 机制实现了一种重复投递的效果。



Comments NOTHING