


达人探店
发布探店笔记

那第一张表block表它里边的结构呢是这个
首先呢第一个字段是i d,就是主键,第二个呢是shop id,就是商户你发的这个比例啊,它是跟哪个商户有关系的。第三个呢用户id就是谁发的这篇笔记,第四个呢标题,第五个呢是照片,照片呢最多不超过九张,多个呢以道号隔开,所以呢他这个是一个字段,里面包含了多张图片的
然后呢再往下呢content是探店的文字描述啊,然后再往下呢还有两个,一个叫点赞的数量啊,还有一个是评论的数量啊,点赞了不一定会评论是吧,所以这两个是分离去计数,再往下time update time,创建时间更新时间
实际生产中不会加外键,这会给每次操作进行验证,会大大降低性能,配了负载均衡的,记得启动两个服务,否则前端页面显示不全
uploadcontrol实现了功能,而因此呢啊在这个地方,我们会定义一个叫做image upload dr文件上传的地址,那么这个地址所以我们需要把它改成什么,我们当前的这个目录啊。你需要找到你自己的index的目录
package com.hmdp.utils;
public class SystemConstants {
public static final String IMAGE_UPLOAD_DIR = "D:\\lesson\\nginx-1.18.0\\html\\hmdp\\imgs\\";
public static final String USER_NICK_NAME_PREFIX = "user_";
public static final int DEFAULT_PAGE_SIZE = 5;
public static final int MAX_PAGE_SIZE = 10;
}
成功上传,也可以多 次上传图片啊
点击发布,那么会自动跳到主页里,在app首页,我们可以看到,同样的数据库的tb blog也可以看得到这条消息
实现查看发布探店笔记的接口
需求:点击首页的探店笔记,会进入详情页面,实现该页面的查询接口

好的,同学们,我们来继续分析这个接口。首先,接口相关的信息我已经提前分析了一下。请求的方式是GET,这一点我们通过查看就能知道,路径是/block,后面跟着的是id,这个也没有问题。然后请求参数自然就是这个id了,也就是当前这篇博客的ID。最后返回值是什么呢?返回值根据id查询这个博客(Blog),那返回值是不是应该就是Blog呀?理论上讲就是如此,但是大家别忘了,其实我们发布的任何一篇探店笔记,它里边都包含有这个用户的信息。然后才是这个图片,还有标题等等。
所以说我们在详情页面展示的时候,除了要展示这里的图片、标题、内容以外,那这个发布这篇笔记的用户是不是也应该展示出来,这样其他用户看到这篇博客以后,如果感兴趣,是不是可以直接关注当前的用户了。所以说呢,我们返回的结果中除了博客信息以外,还应该包含对应的用户信息。那我们怎么样才能在结果中包含两部分内容呢?
那我们回到IDEA看一下,在这里实现起来其实非常的简单,有两种选择。第一种选择就是在我们的这个Blog类里边加一个用户的成员变量就行了。那这样一来,我们只要把查询到的跟这个用户ID有关的这个用户(User)的对象存进去,是不是就OK了?但在这呢,我采用了一种简化的方法,怎么简化呢?就是在我们的Blog类里边加了两个字段,你看这个博客类里面的其他字段,店铺ID(shop id)、用户ID(user id)、还有我们的标题、图片、内容等等,这些都是数据库字段。而唯独这两个字段一个叫图标(icon)、一个叫姓名(name),这两个就是我们的用户字段了。
那我们的用户除了有ID以外,还有就是图标和姓名,剩下的敏感字段我们就不返回了,只返回这三个足够页面显示就可以了。而这两个字段呢我们加了@TableField注解,它代表的含义就是当前字段不属于博客所定义的表,你表不是博客表吗?而这两个字段不在表里面,所以说我加了这样一个注解,那将来呢我们手动的要维护这两个字段就可以了。这样大家应该就能理解了吧。
那下面呢我们就可以去实现一下了,我们找到博客控制器(BlogController),我们在这儿去写这个接口。实现的时候,我们首先要根据id查询到对应的博客(Blog)信息,然后根据博客信息中的用户ID(user id),再去查询用户(User)信息。查询到用户信息后,我们将用户信息添加到博客信息中,最后将包含用户信息的博客信息返回给前端。剩下的敏感字段我们就不返回,只返回这三个足够页面显示就可以了,而这两个字段呢我们加了table field,exit等于false这样一个注解,它代表的含义就是说当前字段不属于blog它所定义的表,而我这俩字段不在表里面,写control
package com.hmdp.controller;
import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
import com.hmdp.dto.Result;
import com.hmdp.dto.UserDTO;
import com.hmdp.entity.Blog;
import com.hmdp.entity.User;
import com.hmdp.service.IBlogService;
import com.hmdp.service.IUserService;
import com.hmdp.utils.SystemConstants;
import com.hmdp.utils.UserHolder;
import org.springframework.web.bind.annotation.*;
import javax.annotation.Resource;
import java.util.List;
/**
* <p>
* 前端控制器
* </p>
*
* @author 虎哥
* @since 2021-12-22
*/
@RestController
@RequestMapping("/blog")
public class BlogController {
@Resource
private IBlogService blogService;
@PostMapping
public Result saveBlog(@RequestBody Blog blog) {
// 获取登录用户
UserDTO user = UserHolder.getUser();
blog.setUserId(user.getId());
// 保存探店博文
blogService.save(blog);
// 返回id
return Result.ok(blog.getId());
}
@PutMapping("/like/{id}")
public Result likeBlog(@PathVariable("id") Long id) {
// 修改点赞数量
blogService.update()
.setSql("liked = liked + 1").eq("id", id).update();
return Result.ok();
}
@GetMapping("/of/me")
public Result queryMyBlog(@RequestParam(value = "current", defaultValue = "1") Integer current) {
// 获取登录用户
UserDTO user = UserHolder.getUser();
// 根据用户查询
Page<Blog> page = blogService.query()
.eq("user_id", user.getId()).page(new Page<>(current, SystemConstants.MAX_PAGE_SIZE));
// 获取当前页数据
List<Blog> records = page.getRecords();
return Result.ok(records);
}
@GetMapping("/hot")
public Result queryHotBlog(@RequestParam(value = "current", defaultValue = "1") Integer current) {
return blogService.queryHotBlog(current);
}
@GetMapping("/{id}")
public Result queryBlogById(@PathVariable("id") Long id) {
return blogService.queryBlogById(id);
}
}
service加一下就行,impl写一下如下
package com.hmdp.service.impl;
import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
import com.hmdp.dto.Result;
import com.hmdp.entity.Blog;
import com.hmdp.entity.User;
import com.hmdp.mapper.BlogMapper;
import com.hmdp.service.IBlogService;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.hmdp.service.IUserService;
import com.hmdp.utils.SystemConstants;
import org.springframework.stereotype.Service;
import javax.annotation.Resource;
import java.util.List;
/**
* <p>
* 服务实现类
* </p>
*
* @author 虎哥
* @since 2021-12-22
*/
@Service
public class BlogServiceImpl extends ServiceImpl<BlogMapper, Blog> implements IBlogService {
@Resource
private IUserService userService;
@Override
public Result queryBlogById(Long id) {
//1.查询blog
Blog blog = getById(id);
if (blog == null) {
return Result.fail("笔记不存在!");
}
//2.查询bLog有关的用户
queryBlogUser(blog);
return Result.ok(blog);
}
private void queryBlogUser(Blog blog) {
Long userId = blog.getUserId();
User user = userService.getById(userId);
blog.setName(user.getNickName());
blog.setIcon(user.getIcon());
}
@Override
public Result queryHotBlog(Integer current) {
// 根据用户查询
Page<Blog> page = query()
.orderByDesc("liked")
.page(new Page<>(current, SystemConstants.MAX_PAGE_SIZE));
// 获取当前页数据
List<Blog> records = page.getRecords();
// 查询用户
//lam
records.forEach(this::queryBlogUser);
return Result.ok(records);
}
}
点赞
你发现一个人可以无限次的点赞,这是因为代码直接数据库中++,不做任何判断限定
需求:
- 同一个用户只能点赞一次,再次点击则取消点赞
- 如果当前用户已经点赞,则点赞按钮高亮显示(前端已实现,判断字段Blog类的isLike属性)
由于需要记录点赞人和被点赞人,还有点赞状态(点赞、取消点赞),还要固定时间间隔取出 Redis 中所有点赞数据,分析了下 Redis 数据格式中 Hash 最合适。blog.java里面添加有这个(实际用的set)
/** * 是否点赞过了 * boolean类型字段不能is打头,阿里明文规定 */ @TableField(exist = false) private Boolean isLike;
如果业务量比较多可以做个定时同步,隔一段时间同步一次点赞信息到数据库
@PutMapping("/like/{id}")
public Result likeBlog(@PathVariable("id") Long id) {
return blogService.likeBlog(id);
}修改或者添加这几个函数
@Override
public Result queryBlogById(Long id) {
//1.查询blog
Blog blog = getById(id);
if (blog == null) {
return Result.fail("笔记不存在!");
}
//2.查询bLog有关的用户
queryBlogUser(blog);
//3.查询blog是否被点赞
isBlogLiked(blog);
return Result.ok(blog);
}
private void isBlogLiked(Blog blog) {
// 1. 获取登录用户
Long userId = UserHolder.getUser().getId();
// 2. 判断当前登录用户是否已经点赞
String key = "blog:liked:" + blog.getId();
Boolean isMember = stringRedisTemplate.opsForSet().isMember(key, userId.toString());
blog.setIsLike(BooleanUtil.isTrue(isMember));
}
@Override
public Result queryHotBlog(Integer current) {
// 根据用户查询
Page<Blog> page = query()
.orderByDesc("liked")
.page(new Page<>(current, SystemConstants.MAX_PAGE_SIZE));
// 获取当前页数据
List<Blog> records = page.getRecords();
// 查询用户
records.forEach(blog ->
{
this.queryBlogUser(blog);
this.isBlogLiked(blog);
});
return Result.ok(records);
}
@Override
public Result likeBlog(Long id) {
// 1. 获取登录用户
Long userId = UserHolder.getUser().getId();
// 2. 判断当前登录用户是否已经点赞
String key = "blog:liked:" + id;
Boolean isMember = stringRedisTemplate.opsForSet().isMember(key, userId.toString());
if(BooleanUtil.isFalse(isMember)) {
// 3. 如果未点赞,可以点赞
// 3.1. 数据库点赞数 + 1
boolean isSuccess = update().setSql("liked = liked + 1").eq("id", id).update();
// 3.2. 保存用户到Redis的set集合
if(isSuccess) {
stringRedisTemplate.opsForSet().add(key, userId.toString());//此处应该拷贝if(isSuccess)判断数据更新成功才更新redis
}
}else {
// 4. 如果已点赞,取消点赞
// 4.1. 数据库点赞数 - 1
boolean isSuccess = update().setSql("liked = liked - 1").eq("id", id).update();
//这里有线程安全问题,判断和修改不是原子.也有事务的问题,update了两条数据
// 4.2. 把用户从Redis的set集合移除
stringRedisTemplate.opsForSet().remove(key, userId.toString());
}
return Result.ok();
}
/*如果A线程查到当前用户没点赞,没等进行redis更新操作,B线程进来查询redis当前用户也没进行点赞,就会赞两次
一般账号都会设置限制在1-5台设备左右登录,本来并发度就不高,并且这类数据也不要求强一致性,安全问题还是很低很低的。*/ 实现点赞和高亮
实现点赞和高亮
点赞排行榜
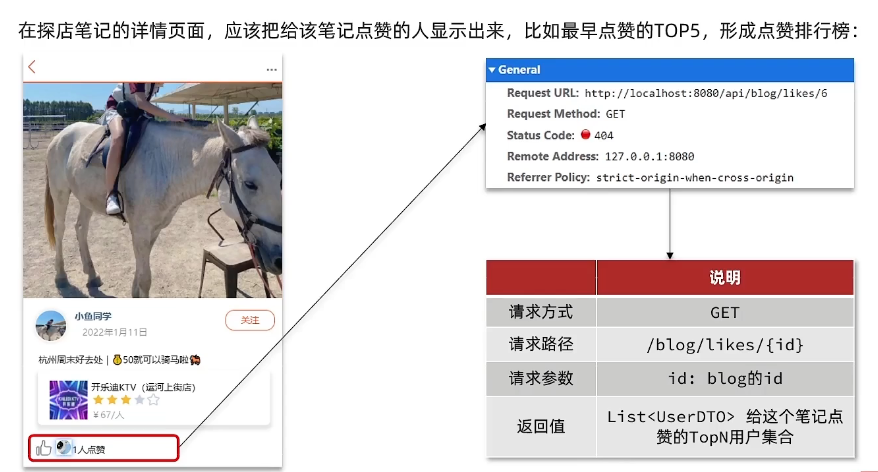
好的同学们,刚才我已经为大家总结了接口的信息,并且进行了梳理。可以看到,请求方式是GET请求,路径是`/blog/likes`或者`/blog/likes/d`,这里的`d`可能是指“点赞”的意思,后面跟着的是当前这篇笔记的ID。我们要查的是给这篇笔记点赞的人,所以参数就是`blogId`了。返回的自然是点赞的前五名了,所以是一个集合,集合里装的是用户信息。这里我们用了`UserDTO`,因为`UserDTO`里把敏感信息都已经给去掉了,所以不用担心数据泄漏的风险。在这个地方,我们要返回的这个集合就是所谓的前五名,也就是排行榜里面的前五名。但在这就有一个问题了,我上哪去查这前五名的用户去,而且是点赞的用户。
那同学们,我们点赞的信息都放在哪儿啊?而在上一节课当中,我们点赞是基于一个Redis的Set集合来实现的,也就是说我现在要想查询这些用户信息,我是不是得去Set集合来查?但是我要的是前五名,Set集合是所有的,那我就必须把Set集合的元素给它排个序啊。但是同学们,Set集合是有虚的吗?显然不是,我们当初为什么选Set集合呀,是因为当初我们的业务需求是:第一要存多个元素,也就是集合;第二点为一。那这两点他都满足呀。但现在我们又多了个需求,我们要做排行榜,所以我们的需求变成了三个需求了:要能够存多个元素,要能为一,完了还能排序。那Set集合就不行了,我们该选谁?
哎,在这儿呢我们去做一个对比啊,目前为止我们学习的Redis集合总共就三种,那这三种都是集合,所以第一条是不是就满足了,那么还剩两条吗,那一个就是排序,一个就是唯一。在这呢我给大家对比的就是这三点,哪个呢,第一排序,第二唯一性,第三个多了一个,我们要对比一下他们的查找元素时的方式。为什么呢?因为将来我们除了去做排序以外,我们还有一个需求就是点赞,点赞我们要判断它存不存在,对不对,而你要判断存不存在,不就是查找吗?所以说这个也要去做对比。那来一个看啊,首先Set集合,它首先是可以做排序的,为什么呢?他是个链表吗,那他按什么排,按照添加顺序,还有`lpush`和`rpush`两种,对不对?如果说我们所有的元素都是按`lpush`就插入的,那元素呢先插入进去的,是不是在最后,后插入的,在最前变成了一个按照插入顺序的倒序排序,这个跟我们点赞排行榜不太相符,但是如果我们全部采用`rpush`呢,先点赞在最前边,后点在最后边,这样是不是就刚好符合?所以说它是支持这种排序的啊,而Set集合就不好意思了,不支持啊,无法排序,而我们的Sorted Set,这个咱们之前是不是也学过呢?它可以排序的,按什么排按分数,也就是说我们存入`zset`的元素啊,除了元素本身以外,还要带一个score,那就分数啊,那么这个score分数呢,可以是用户自定义的任意的东西,那如果我把它按照时间戳啊作为score值存进去,那这样一来是不是也能实现按添加顺序排序了?那想添加越早,时间说是不是越小,那天下越晚,时间戳越大,这样天然是不是就带有一个顺序了?因此Sorted Set能不能实现按照时间排序没问题,这也就是说符合要求的是不是就有两个啊,从排序上来讲啊,那再从唯一性上来讲啊,直接把list排除了啊,list是链表,无法保证数据的唯一啊,他只管一共要往里面加,但是呢Set和Sorted Set都满足,因为他们底层都有一个哈希啊哈表,接下来它可以判断元素是否存在,从而把一些重复元素给剔除或者是覆盖,那从查找方式上来讲呢,我们的list查找,我们刚才讲过了,它底层是什么呢,是链表,所以说呢它只能按角标查找元素,或者是首尾查找啊,那意思我想知道一个元素存不存在,它的做法只能是便利一边啊,但是Set和Sorted Set就不一样了,那么这两个呢因为他们底层采用的是哈希表,所以说他们可以根据元素做这种哈希运算,快速定位到对应的那个数组位置,然后呢去判断是否存在,所以他们的查找更加高效,对不对,所以从这三点来看,哪个更适合啊,其实把前两点看完就已经找到答案了,是不是Sorted Set更符合我们的业务需求?同学们,只要你掌握了啊这种Redis数据结构的特点,然后你再结合你的业务需求,是不是一目了然,就能快速定位到合适的数据类型?那这里呢我们就需要用Sorted Set来代替我们的Set集合,改造我们之前的点赞业务了,但是在这就有一个问题了,Sorted Set虽然跟Set类似,但是还是存在差异的,很多的命令上是不一样的,那我们来看一下啊,在这呢我们之前使用这个Set的时候,我们去添加是`sadd`,对不对啊,`sadd`去添加一个元素,我们就判断是否存在叫`sismember`,它可以直接判断一个元素是否存在,但是现在我们用的是Sorted Set,Sorted Set里面就不存在啊,这个`sismember`这样一个命令了,那它添加元素是一样的,都是去`zadd`,但是呢他判断元素是否存在,它没有一个叫`sismember`的没有,那怎么办啊,那这里呢我们只能用一种别的方式啊,在这儿呢我们会使用一个叫做`zscore`的,意思是获取指定一个元素对应的分数,那为什么用它可以判断元素是否存在呢?我去获取元素的分数,元素如果存在,返回的自然就是分数,元素不存在,返回的是不是就是空了啊,你看我们可以试一下,现在我们通过这个`zadd`啊去添加这个元素啊,比如说k叫`z1`啊,然后呢我一啊,这是分数吗,`m1`,`m2`,`m3`,这样我是不是一下添加了三个元素,好全部添加进去了,那接下来呢我们就用`zscore`啊去查看一下,这个`z1`里边的`m1`这个元素,它的分数是不是查到了`m2`,查到了`m3`,查到了`m4`,不存在,看到没有,返回的是不是`null`,也就是空,所以说我们完全可以通过查分数的形式查到了就存在查不到是不是不存在,来判断元素是否存在,其他的就没什么太大差别了啊,那当然最后我们要去查排行榜,我们怎么查,这个之前咱们讲过,其实就用`zrange`,`range`是什么啊,`range`查询的是按范围查吗,就是你要查找哪个范围内的,它天然的会帮你做排序嘛,对不对,假如说我们按时间啊,时间戳插入,那么它会天然的按照时间戳从小到大排序,那显然啊最早插入的是不是就在最前,那这时我们要查前五名,其实就是查什么呢,它里边从0~4的这些啊,01234不刚好五个嘛,那就前五名啊,就这么来查的啊,所以呢这个将来我们要查前五名啊,也就知道该怎么做了。
127.0.0.1:6379> ZADD z1 1 m1 2 m2 3 m3
(integer) 3
127.0.0.1:6379> ZSCORE z1 m1
"1"
127.0.0.1:6379> ZSCORE z1 m3
"3"
127.0.0.1:6379> ZSCORE z1 m9
(nil)
127.0.0.1:6379> ZRANGE z1 0 4
1) "m1"
2) "m2"
3) "m3"
@Override
public Result likeBlog(Long id) {
// 1. 获取登录用户
Long userId = UserHolder.getUser().getId();
// 2. 判断当前登录用户是否已经点赞
String key = "blog:liked:" + id;
//Boolean isMember = stringRedisTemplate.opsForSet().isMember(key, userId.toString());
Double score = stringRedisTemplate.opsForZSet().score(key, userId.toString());
if(score == null) {
// 3. 如果未点赞,可以点赞
// 3.1. 数据库点赞数 + 1
boolean isSuccess = update().setSql("liked = liked + 1").eq("id", id).update();
// 3.2. 保存用户到Redis的set集合 zadd key value score
if(isSuccess) {
stringRedisTemplate.opsForZSet().add(key, userId.toString(),System.currentTimeMillis());//此处应该拷贝if(isSuccess)判断数据更新成功才更新redis
}
}else {
// 4. 如果已点赞,取消点赞
// 4.1. 数据库点赞数 - 1
boolean isSuccess = update().setSql("liked = liked - 1").eq("id", id).update();
//这里有线程安全问题,判断和修改不是原子.也有事务的问题,update了两条数据
// 4.2. 把用户从Redis的set集合移除
stringRedisTemplate.opsForZSet().remove(key, userId.toString());
}
return Result.ok();
}
private void isBlogLiked(Blog blog) {
// 1. 获取登录用户
Long userId = UserHolder.getUser().getId();
// 2. 判断当前登录用户是否已经点赞
String key = "blog:liked:" + blog.getId();
Double score = stringRedisTemplate.opsForZSet().score(key, userId.toString());
blog.setIsLike(score!=null);
}这里记得改完调试的时候把之前Redis的缓存删除了
神了,有的帖子可以取消赞,有的就不能,哦牛批
@GetMapping("/likes/{id}")
public Result queryBlogLikes(@PathVariable("id") Long id) {
return blogService.queryBlogLikes(id);
} //使用map方法将每个元素转换为对应的Long类型,并使用collect方法将结果收集到一个List中
@Override
public Result queryBlogLikes(Long id) {
String key = BLOG_LIKED_KEY + id;
// 1. 查询top5的点赞用户 zrange key 0 4
Set<String> top5 = stringRedisTemplate.opsForZSet().range(key,0,4);
if (top5 == null || top5.isEmpty()) {
return Result.ok(Collections.emptyList());
}
// 2. 解析出其中的用户id
List<Long> ids = top5.stream().map(Long::valueOf).collect(Collectors.toList());
// 3. 根据用户id查询用户
List<UserDTO> userDTOS = userService.listByIds(ids).stream()
.map(user -> BeanUtil.copyProperties(user, UserDTO.class))
.collect(Collectors.toList());
// 4. 返回
return Result.ok(userDTOS);
}
private void isBlogLiked(Blog blog) {
// 1. 获取登录用户
//return前可以把isLike设为null或者false,不然账号退出登录再打开首页会残留上一个账号的点赞状态。
UserDTO user = UserHolder.getUser();
if (user == null) {
return;
}
Long userId = UserHolder.getUser().getId();
// 2. 判断当前登录用户是否已经点赞
String key = "blog:liked:" + blog.getId();
Double score = stringRedisTemplate.opsForZSet().score(key, userId.toString());
blog.setIsLike(score!=null);
}
return前可以把isLike设为null或者false,不然账号退出登录再打开首页会残留上一个账号的点赞状态。
//使用map方法将每个元素转换为对应的Long类型,并使用collect方法将结果收集到一个List中
@Override
public Result queryBlogLikes(Long id) {
String key = BLOG_LIKED_KEY + id;
// 1. 查询top5的点赞用户 zrange key 0 4
Set<String> top5 = stringRedisTemplate.opsForZSet().range(key,0,4);
if (top5 == null || top5.isEmpty()) {
return Result.ok(Collections.emptyList());
}
// 2. 解析出其中的用户id
List<Long> ids = top5.stream().map(Long::valueOf).collect(Collectors.toList());
// 3. 根据用户id查询用户
String idStr = StrUtil.join(",",ids);
List<UserDTO> userDTOS = userService.query().in("id",ids)
.last("ORDER BY FIELD(id,"+idStr+")").list()
.stream()
.map(user -> BeanUtil.copyProperties(user, UserDTO.class))
.collect(Collectors.toList());
// 4. 返回
return Result.ok(userDTOS);
}
好的同学们,接下来我们需要对原来的业务做一些改造。首先,在之前的点赞业务中,我们使用的是Redis的Set集合存储数据,现在需要改为Sorted Set(即ZSet)。因此,原本使用StringTemplate的Set操作需要调整为ZSet操作。添加数据时,需要指定三个参数:key、value和分数。这里我们使用时间戳作为分数,可以通过System.currentTimeMillis()获取当前毫秒数。因此,添加数据的命令相当于ZADD key score value。
删除操作则使用ZSet的remove方法,这部分保持不变。判断用户是否已点赞时,之前可能使用的是Set的isMember方法,现在需要改为通过ZSet的score方法获取用户的分数。如果返回的score为null,表示用户未点赞;反之则已点赞。
接下来,除了点赞逻辑,还需要修改查询逻辑。在根据ID查询和分页查询时,都会调用isBlogLiked方法判断当前用户是否点赞过该博客。这里同样需要将判断方式改为使用ZSet的score方法,检查返回的分数是否为null,从而确定点赞状态。
测试时,首先清空Redis中的旧数据,重启服务后进行测试。点赞操作成功后,检查Redis中的数据结构是否变为ZSet,且分数为时间戳。重复点赞或取消操作时,确保逻辑正确。
接下来实现点赞列表查询功能。在BlogController中添加新的查询接口,调用BlogService的queryBlogLikes方法。该方法首先使用ZSet的range命令获取前5个点赞用户的ID(0到4的索引),然后将这些ID解析为Long类型列表。接着,根据这些ID查询用户信息,并转换为UserDTO列表返回。需要注意的是,如果查询结果为空,应返回空列表避免空指针异常。
在查询用户信息时,直接使用MyBatis-Plus的listByIds方法可能无法保证返回顺序与传入ID顺序一致。此时需要手动拼接SQL语句,使用ORDER BY FIELD(id, id1, id2,...)确保结果顺序。具体实现时,将ID列表拼接为逗号分隔的字符串,并通过MyBatis-Plus的last方法添加自定义排序语句。
测试过程中可能出现未登录用户访问导致的空指针异常,需在isBlogLiked方法中增加用户登录状态判断,未登录用户直接返回,避免执行后续查询逻辑。
最后,验证点赞列表功能是否正常,确保返回的用户顺序与点赞时间顺序一致,并处理可能因数据库查询顺序不一致导致的显示问题。
好的同学们,接下来我们需要对原来的业务做一些改造。什么改造呢?首先,在之前我们的点赞业务是往Redis的Set集合存储,现在不行了,我们要把它往Sorted Set,也就是zset里存。所以这块String template,这不是set了,我们要采用Sorted Set,在这里面它叫zset去做这个操作。添加的时候啊,需要指定三个,一个是key,一个是value,一个是分数。所以呢,最后还差一个分数,这个分数我们说了,用时间戳对不对,我们可以用system.time看看每毫秒就行了,所以这块这个命令呢,其实就相当于是zadd key,然后后面跟value再跟score这个词好,这是去存储。那如果说我们将来要把它删除呢,删除啊,我们用zset里边的remove,这个是不变的,然后呢就是判断嗯是否存在了,那判断是否存在呢,我们刚才说了,用score,对吧,用score好,在这个地方改一改,在这里用zset啊,这个地方用score。你看call是不是就是个key,还有这个元素啊,也就是说我要查当前这个用户,他在这里边的这个分数,那用户分数其实就是时间戳吧,对不对,我们去查一下好,得到这个score,那个score如果等于null,就证明不存在,是不是啊,那就是未点赞,那如果说不等于null,那就是存在,那就是已点赞。所以你看这个点赞逻辑是不是就改造好了。
那别忘了,除了点赞以外,我们再去做这个查询的时候啊,哪个查询呢?有两个,一个是根据id查,一个是这个分页查,他们都会去判断一下当前用户有没有点赞过当前这个博客啊,is like,那这里边是不是也有判断呀,在这我们是不是还要去用它,还用它,那这里用open for the score地方好,那么is member,而不是了,这次是用那个score,对不对,score查分数啊,查分数,好,那么查完以后返回的自然就是分数啊,得到这个结果好,那怎么才算是呃点赞了呢,就是score不等于null,只要不等于呢,那就是点赞了,对不对啊。所以这个逻辑改掉了好了,到这儿我们首先是把以前的点赞这个逻辑改掉了是吧,那现在点赞他就会走什么,走这个zset的逻辑了。
我们先试一下,首先我们把Redis里面的数据清空啊,以前的那个点赞的给他清空,这个对吧,他干掉,好那再刷新一下,没了啊,没了以后呢,我们去重启一下我们这个服务啊,然后呢我们去做测试,我们打开浏览器好,我们其实在这也能测,我们首先刷新一下,刷新一下以后,你会发现现在是不是显示灰色,说明我没点过赞,对不对,好,然后我们就来点个赞哦,来走好,是不是点赞成功,对不对啊,可以点赞的啊,那这个地方这些措施还是我们刚才讲查那个点赞列表的错啊,这个不管,所以说我们点赞一些是不是成功了,我们去Redis看一下,放心,那在Redis里边这个里面存的东西就变了,大家看它就变成了一个zset啊,那么这个key还是跟以前一样,是用户id,这个value说错了,那这边的值其实已经变成了一个什么了,这个分数其实是时间戳,所以说他将来就会按时间戳排序了啊,好那这个时候呢重复点赞肯定也不会多次点赞,我们看一下走是不是又取消了,对不对,来这边来看刷新是不是没了,我们再回来再点啊,又点上了啊,大概就这么个玩法啊,好这是我们现在把点赞逻辑先改掉了,然后我们再来实现这个点赞列表的查询,blog likes后面跟好来做一下,打开我们的idea the blog control,所以呢我们现在需要加一个新的查询逻辑了啊,嗯可以把之前复制一下,叫什么叫likes,是不是啊,然后呢这块我们叫query blog likes,就说我这个博客点赞的所有人嘛,是不是啊,然后呢根据id查询啊,然后core blog likes现在这个方法根本不存在啊,我实现一下走,那找到实现类,然后再实现对应的方法在这实现啊,这个查询啊,top 5 top 5这个这个用户怎么查啊,那我刚才说了吧,啊命令我们都已经给大家演示过了,对不对啊,那么查询top 5的用户用的是什么,the range,查范围,对不对,指定一个key,然后指定这个范围嘛,0~4嘛就行了,就这么简单,但是你别忘了我们查到的是什么,同学们,我们查到的是这个Sorted set里边的什么呀,用户id和分数吧,而我们最重要的是什么,是不是用户,所以说查完了以后别着急,你首先要解析出其中的用户id,完了以后呢,你还要根据用户id去查询用户,对不对,然后再返回,所以说这里是有一系列逻辑的啊,不是上来就ok了,对吧好,那我们首先去查那茶具,用the range吧,我们用string template.for this set,调这个range方法就行了,认方法就接触这几个参数啊,那么这个k呢跟之前的k一样,我们可以去复制一下,就这个k好,那这个可以重复使用,像这里的前缀文是不是,最好把它提取到rise constance的常量里面去,是不是,然后我们找到rise constance,那在这里就可以去复制一份啊,像这种你老是写的不好的,还是定义常量啊,blog likes啊,就这样就行了啊,然后呢回来粘贴啊,你这样代码看起来就更加优雅了啊,那上面也是,这都是替换定好的,那现在k都有了吗,我们就用这个key啊,那我查几查0~4,我们查这个前五条嘛,就0~4好,得到结果,那这个结果是一个set啊,那其实就是什么,就是top 5的这个id的集合,对不对,好top 5 d top 5吧,就这样写,拿到top 5了以后,我要把它解析出来,变成用户id,它里面现在是字符串,因为我们用的是string template,取出来的是字符串,我需要转成long好,那简单,我们用一个stream流,然后呢做个map映射啊,用这个long点啊,long value of去做这个处理,处理完以后收集一下,这不就得到了ids了吗,对不对,这top 5的id有了用了id,我是不是查用户好,uid查用户怎么查,查用户太简单了,usual service啊,list by爱迪丝是吧,这样是不是查到用户列表,这叫有点思好了,插用户列表了以后,是不是直接返回好,别着急直接返回,为什么呢,因为你在这个地方直接返回的是user,我们刚才说了返回的是什么,是不是user d t,所以说你在这个地方要对user是不做处理啊,那怎么处理,有点撕,所以这个地方其实先别着急去直接return啊,在这里啊,点stream啊,也用stream demap做映射,对不对,我们用我们接受的是user嘛,我们用user做处理啊,利用byt做个拷贝就行了,这个拷贝我们以前是不是做过,把user call成user的d t o是吧,这不就行了吗,然后收集一下,这不得到dt的集合了吗,最后返回返回dt集合,是吧,行了啊,那这个地方为什么涉黄了,他说了有可能有控制帧,你想呀,你去s的查一定能查到吗,万一没有人给他点赞呢,所以这个地方是不是也要做一个非空的判断呀,if a5 等等于n或者top is empty,那这个空外空你就别玩了呀,是不是return ok啊,然后里边什么都没有,或者给个空集合就行了,collections 4点empty list,这样可以避免什么的控制针嘛,那我走到这就确保什么,确保里面有id就肯定不会空,id不为空,查到右边肯定也不会空,对不对,到这儿这个逻辑是不是就写完了,好我们重启测试一下,好,那我们打开浏览器,然后呢这里直接刷新吧,最起码我自己是点过赞的,查到了没有,看我自己的这个头像是不是出来了,没问题啊,可以啊,同学们,那我再来个人点个赞呗,啊我换个号啊,我开个新窗口logo host啊,然后呢一个浏览器重新打开,它就是一个全新的一个什么全新的列表了啊,我发现我们这个首页无法访问了,是不是这报错了,我们去后台看一下啊,我们到后台一看,发现这里报了个空指针,同学们报了个空指针啊,这咋回事儿呢,啊点过来啊,说是这个地方为空啊,user holder这块为空啊,那就知道了,说明什么,说明当前的用户是不是没登录,那用户没登录,你去取这里是不是就有问题,看到吗,哎那为什么说用户为登录,他要来获取用户,因为我们要知道当前用户有没有点过赞,对不对,但是同学们首页,咱们的首页是用户一定会登录吗,不一定是不是啊,里边的才会有要求登录啊,这个页面是不要求登录的,所以说也就是说如果用户未登录的情况下,我们需不需要查询有没有点过赞,不需要对吧,所以说我们在这个地方啊,查出来一个bug,这个is block这块这个id不一定有啊,不一定有,所以你直接get a d就有可能出问题啊,怎么办,这么做,我们在这取出这个user对象,if user啊,等等于no,那我们就什么都不做,直接return对吧,用户未登录,无需查询是否点赞啊,这样就可以避免未登录的用户来查的时候,结果报空指针吗,是不是啊,我们重启一下啊,大家碰到bug的时候不要着急啊,看到异常分析一下,为什么啊,像这种控制针一下就能知道是怎么回事,对不对啊,而且呢我们刚才第一次的时候没有出现问题,这边出问题了,那不就是因为我们一个是登录的,然后这边是不是未登录的呀,我们再刷新看这次是不是没问题了,好那现在我们去做登录啊,那我们去换一个号吧,我们从数据库我们找一个user,小于同学吧啊这是他的id还是c啊,手机号啊,在这里我们用手机号登录,然后呢打开我们的release,在这里找到登录的这块的内容,找他的code登录code好,然后开始c在这粘贴一下好,登录成功,登录成功以后,我们也来给这个美女点个赞好吧,我们呢就在这个地方点进去好,然后我们给他点个赞在走,哦不对,这边下边好点了吧,哎大家看我一点赞,这个列表是不是出现两个人了,哎咱们点赞列表功能是不是实现了呀,啊同学们啊,看起来确实实现了,但是同学们注意看顺序,谁先点的赞,谁先点的赞啊,是不是我们这个美女自己点赞,自己发自己点赞,然后才是小于同学点赞吧,但是小于同学怎么跑前面去了,啥情况呀,你这个排序是不是有问题啊,啊唉有点意思吧,好我们来看一下啊点赞列表当中小于同学在前,我们在后,这不对,应该反过来才对,是不是我们代码写错了,我们回到d在这个地方,我们找到这个查询博客,刚才那个代码应该是在这里或者布罗格莱克斯,对不对,解析出id,然后查询一路往下,那我们来看一下啊,看一下我们service里我们传的这个id的顺序对不对,传达id顺序对不对,我们得到那个查询的逻辑查询,select az,这不是查用户的吗,传递时先传到五再传到一,对不对,是对的吧,先传到五再乘一,同学们,55号是谁啊,看一下数据库5号是不是呃,这个用户就是咱们刚才那个妹子嘛,对不对,1号是不是小于同学,先乘五再乘以一对的吧,我们去raise看一下rise的顺序,我们刚才的那个like是不是5号在前,1号在后没问题,那为什么我查传的没问题,结果查出来不对,同学们知道为什么吗,好我告诉大家是因为数据库的问题,因为我们用的是in,同学们来我们打开数据库,在这个地方我们打开一个查询,然后在这呢粘贴这条sql语句,注意看了我这传五这传一,这是我们给的i e的顺序,对不对,然后我们看查询结果,先一再五看到了吗,也就是说当你用in的时候,你查询的结果会不会按照你给的id的顺序,不会,这怎么办,这事闹大了,是不是啊,我明明给的顺序是对的,结果查出来是错的,这怎么办,有没有同学知道怎么保证用in的时候啊,然后我们的查询结果按照我们给的id出去,好在这告诉大家一个小的技巧啊,这里用order by哦,那拜什么呢啊不是by id哦,如果你直接拜d的话,那不就还是一在前五在后吗,所以他默认其实就是这样,所以一代前五代后,而而是by什么而是by field啊,field是什么意思,字段哪个字段id,然后id的什么顺序呢,d的顺序,这个时候你要手动指定啊,五一你要手动指定,就是你要告诉他我要按照什么顺序对啊,我先五再一,你告诉他好,这个时候我们再来看一下是不是行了,对不对,也就是说你要用order by field,然后后边呢这个顺序一定要给你传递,顺序一致就ok了,那也就是说我们这个查询啊,我们回到我们的idea是不是要做改造了,我们哪个查询这个我们现在用的类似by d4,结果发现不行啊,人家不玩这一套,你必须加油,德败这个in不行怎么办,还好我们的my base plus啊,它提供自定义查询的功能,这里用query,然后用什么呢,query用in对吧,id嘛后边跟的是d4,这样这一块啊,就等于这块i d in的,那后面order by怎么办,这个地方后面不能直接写order by啊,因为他这个order by也是不支持那个feel的功能,那怎么办,这里只能是手写,用一个last last就是最后一条sql语句的意思,也就是说它会自动的在原有的sql语句,后面拼接啊,拼接什么呢,你手写呗order by就是这个那是写,但是手写这里有个问题啊,同学们,你在这儿手写这个啊,你这块手写的是这个,但是你这个order by field,你这个五跟一不能写死呀,你这里的五和一是不是这里的id,拼成的字符串啊,怎么办,好这里我们要把id拼字符串,我们用一个s t r youtube.join joy,就是拼接的意思,用什么拼音,用逗号啊把谁拼了,把这个i d4 拼了,那么它就会自动的帮你拼接成一个i d的,s t r字符串,那么这个时候你把它拼到这个地方,而不是写死,是不是就ok了,看看这样不就完了吗,对不对,然后点list啊就行了,那也就是说我们利用这个query啊,先印在last,其实就是实现了这样一条sql语句,当然了,我们可以把合一条,这样你就知道这一行就是一条sql语句,实现了这个der by,然后呢再去做后面的逻辑就行了。
好友关注
他还会发送一个请求去查询是否已经关注过当前用户。这个查询的接口叫做follow_or_not,从名字上就能看出,是用来检查是否关注了某个用户。在接口中,后面跟着的是用户的ID,也就是你想要查询是否关注过的那个用户的ID。接口会返回一个布尔值,true表示已经关注,false表示还没有关注。这样页面上就可以根据这个结果来渲染出不同的效果。
所以这节课我们要实现这两个接口,一个是关注和取关,另一个是查看有没有关注,这两个接口。用户关注实际上描述的是用户与用户之间的关系,对吧?一个用户可以关注很多其他的用户,当然他自己也可以被很多用户关注,对吧?那也就是说用户与用户之间的这种关注的关系是一种多对多的关系。因此我们要想在数据库里记录这种关系,肯定是要有一张中间表来实现。
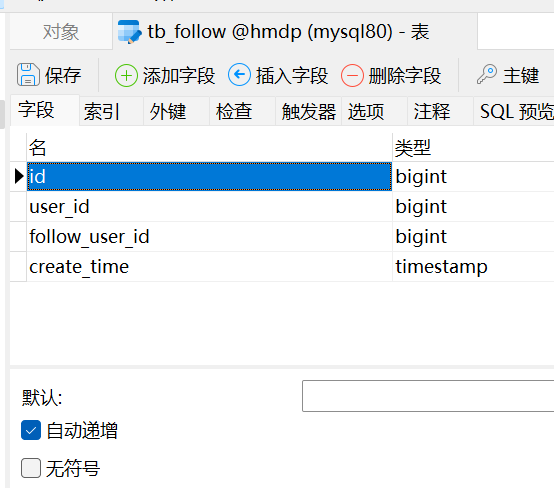
在这里我们有一张表叫做tp_follow,既然是中间表,就记录用户之间的关系,所以他的字段也非常简单,除了主键和时间以外,就两个字段:一个叫做user_id,就是当前用户的ID;另一个叫做followed_id,就是被关注的那个用户的ID。所以这样两个关系是不是就记录下来了。不过细心的同学可能发现了,就是我们这张表的主键并没有设置自增长,那这样我们将来如果去实现功能的时候,是不是得手动去指定ID啊,太麻烦了。所以在这里我们就把这个组件改成自增长。
这样,每次插入新记录时,数据库会自动为我们生成一个新的ID,我们就不需要手动指定了,简化了我们的操作。接下来,我们就可以根据这个设计来实现关注和取关的功能了。在实现这两个功能时,我们需要做的是,当用户发送关注请求时,我们在tp_follow表中插入一条新的记录,记录当前用户ID和被关注用户ID。当用户发送取关请求时,我们则需要从tp_follow表中删除对应的记录。
同时,我们还需要实现一个查询功能,根据当前用户ID和被查询用户ID来确定是否关注。这个查询可以通过一个简单的SQL语句来实现,比如SELECT * FROM tp_follow WHERE user_id = ? AND followed_id = ?。这里的问号?是参数占位符,我们将在代码中用具体的用户ID来替换它们。
实现关注和取关功能
需求:基于该表数据结构,实现两个接口:
①关注和取关接口
②判断是否关注的接口
关注是User之间的关系,是博主与粉丝的关系,数据库中有一张tb_follow表来标示:
右键选择”设计表“,将id设置为自增长
为control,service,impl依次完善
@RestController
@RequestMapping("/follow")
public class FollowController {
@Resource
private IFollowService followService;
@PutMapping("/{id}/{isFollow}")
public Result follow(@PathVariable("id") Long followUserId, @PathVariable("isFollow") Boolean isFollow) {
return followService.follow(followUserId, isFollow);
}
@GetMapping("/or/not/{id}")
public Result isFollow(@PathVariable("id") Long followUserId) {
return followService.isFollow(followUserId);
}
}public interface IFollowService extends IService<Follow> {
Result follow (Long followUserId, Boolean isFollow);
Result isFollow(Long followUserId);
}
@Override
public Result follow(Long followUserId, Boolean isFollow) {
//1.获取登录用户
Long userId = UserHolder.getUser().getId();
//1.判断到底是关注还是取关
if(isFollow) {
//2.关注,新增数据
Follow follow = new Follow();
follow.setUserId(userId);
follow.setFollowUserId(followUserId);
save(follow);
}else {
//3.取关,删除deletefromtb_followwhereuser_id=?and follow_user_id=?
remove(new QueryWrapper<Follow>()
.eq("user_id", userId).eq("follow_user_id", followUserId));
//这里用lamdaquerymapper好一些,用LambdaQueryWrapper的记得把xml里的苞米豆版本改成3.4.3.4以上 不然有bug
//new LambdaQueryWrapper<Follow>().eq(Follow::getUserId, userId).eq(Follow::getFollowUserId,followUserId).remove()
}
return Result.ok();
}
@Override
public Result isFollow(Long followUserId) {
//1.获取登录用户
Long userId = UserHolder.getUser().getId();
//2.查询是否关注select count(*)from tb_follow where user_id=?and follow_user_id=?
Integer count = query().eq("user_id",userId).eq("follow_user_id",followUserId).count();
//3.判断
return Result.ok(count > 0);
} 成功关注
成功关注
共同关注
点击用户头像查询用户和指定用户所有笔记,资料提供的一个叫代码片段.java的文件
// UserController 根据id查询用户
@GetMapping("/{id}")
public Result queryUserById(@PathVariable("id") Long userId){
// 查询详情
User user = userService.getById(userId);
if (user == null) {
return Result.ok();
}
UserDTO userDTO = BeanUtil.copyProperties(user, UserDTO.class);
// 返回
return Result.ok(userDTO);
}
// BlogController
@GetMapping("/of/user")
public Result queryBlogByUserId(
@RequestParam(value = "current", defaultValue = "1") Integer current,
@RequestParam("id") Long id) {
// 根据用户查询
Page<Blog> page = blogService.query()
.eq("user_id", id).page(new Page<>(current, SystemConstants.MAX_PAGE_SIZE));
// 获取当前页数据
List<Blog> records = page.getRecords();
return Result.ok(records);
}分别为UserController和BlogController添加上面的代码
那这个请求它的路径上叫followcommon,也就是共同关注的意思,那后面跟着这个id就是啊指定的这个用户的id,就是比如说我要查的是比如2号用户关注谁,然后还有当前登录用户关注了谁。
需求:利用Redis中恰当的数据结构,实现共同关注功能。在博主个人页面展示出当前用户与博主的共同好友。redis的set可以实现交集功能。我首先是不是应该把一个用户,他的关注的列表保存的redis,比如说我们当前登录用户的关注了谁,保存到ridis的 集合,目标用户同理。那这样来我们发起这个请求查的时候,就可以直接求两个set集合的交集
说实在的,这个量又不大,直接上数据库了,没必要redis,虽然能持久化,但是专业的还得专业来干啊
改造followserviceimpl
@Resource
private StringRedisTemplate stringRedisTemplate;
@Override
public Result follow(Long followUserId, Boolean isFollow) {
//1.获取登录用户
Long userId = UserHolder.getUser().getId();
//String key ="follow:"+followUserId+":"+isFollow;
String key = "follow:" + userId;
//1.判断到底是关注还是取关
if (isFollow) {
//2.关注,新增数据
Follow follow = new Follow();
follow.setUserId(userId);
follow.setFollowUserId(followUserId);
boolean isSuccess = save(follow);
if (isSuccess) {
//把关注用户的id,放入redis的set集合sadd userId followerUserId
stringRedisTemplate.opsForSet().add(key, followUserId.toString());
}
} else {
//3.取关,删除delete from tb_follow where user_id=?and follow_user_id=?
boolean isSuccess = remove(new QueryWrapper<Follow>()
.eq("user_id", userId).eq("follow_user_id", followUserId));
//这里用lamdaquerymapper好一些,用LambdaQueryWrapper的记得把xml里的苞米豆版本改成3.4.3.4以上 不然有bug
//new LambdaQueryWrapper<Follow>().eq(Follow::getUserId, userId).eq(Follow::getFollowUserId,followUserId).remove()
if (isSuccess) {
//把关注用户的id从Redis集合中移除
stringRedisTemplate.opsForSet().remove(key, followUserId.toString());
}
}
return Result.ok();
}我觉得应该在用户登录时下才把用户信息和关注的人一起查出来放到redis,而点开别人主页的时候再去查这个人的信息和关注放在redis中,点共同关注就直接redis判断。设过期时间用户活跃就刷新
另找一个号关注小鱼同学和可可今天不吃肉,
这个接口呢它的请求方式是get
Result followCommons(Long id); @GetMapping("/common/{id}")
public Result followCommons(@PathVariable("id") Long id){
return followService.followCommons(id);
} @Override
public Result followCommons(Long id) {
//1.获取当前用户
Long userId = UserHolder.getUser().getId();
String key = "follows:" + userId;
//2.求交集
String key2 = "follows:" + id;
Set<String> intersect = stringRedisTemplate.opsForSet().intersect(key, key2);
if (intersect == null || intersect.isEmpty()) {
//无交集
return Result.ok(Collections.emptyList());
}
//3.解析id集合
List<Long> ids = intersect.stream().map(Long::valueOf).collect(Collectors.toList());
//4.查询用户
List<UserDTO> users = userService.listByIds(ids)
.stream()
.map(user -> BeanUtil.copyProperties(user, UserDTO.class))
.collect(Collectors.toList());
return Result.ok(users);
}关注推送
关注推送也叫做Feed流,直译为投喂。为用户持续的提供“沉浸式”的体验,通过无限下拉刷新获取新的信息。
Feed流产品有两种常见模式:
Timeline:不做内容筛选,简单的按照内容发布时间排序,常用于好友或关注。例如朋友圈
》优点:信息全面,不会有缺失。并且实现也相对简单
》缺点:信息噪音较多,用户不一定感兴趣,内容获取效率低
智能排序:利用智能算法屏蔽掉违规的、用户不感兴趣的内容。推送用户感兴趣信息来吸引用户
》优点:投喂用户感兴趣信息,用户粘度很高,容易沉迷
》缺点:如果算法不精准,可能起到反作用
本例中的个人页面,是基于关注的好友来做Feed流,因此采用Timeline的模式。该模式的实现方案有三种:
①拉模式
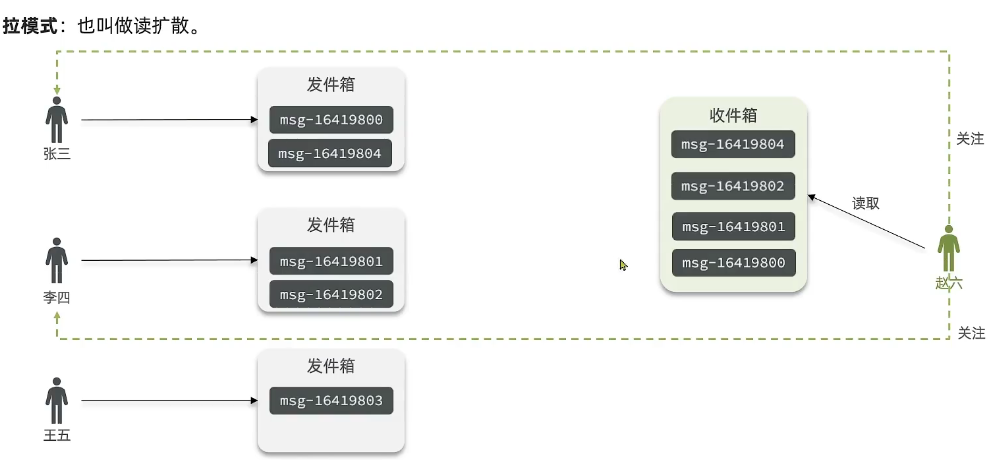
比如说现在有三个UP主,分别叫张三、李四和王五,这三个人他们将来会发布自己的一些笔记或者是发视频。那不管他们发什么吧,我们统一叫做消息。这个时候我们会给他们三个人每个人准备一个发件箱,将来他们发消息的时候,就会发到这个发件箱里去。
比如说张三他发了一条,然后就发到这里。那这里的消息除了消息本身以外,还要带上一个时间戳,因为我们timeline核心就是要按时间排序嘛,所以一定要带上时间戳。那这个时候他发完了,这个时候再有别的人来发,那这个时间戳是不会依次增大的呀,张三、李四都可以去发,比如说李四又发了一条,又增大了,王五又发一条,越来越大,这是张三再发一条,所以每个人发的时间戳都会递增。
这个时候呢有一个粉丝赵六,那赵六他会有一个收件箱,他的收件箱平常是空的,只有在他要去读消息的时候,我们才会去给他拉去发件箱里的消息,一个一个的拉到他的收件箱里去。所以叫拉模式嘛,拉过来了以后去做一个按照时间排序,这样他就可以去读取了。这种模式叫拉模式,为什么它要叫拉模式呢,因为一开始我们并没有做扩散,每个消息是不是只有一份,只有你在读的时候,是不是才会去拉一个副本回来,所以它叫读扩散。
那这种模式有什么优点呢?优点其实就是节省内存空间嘛,因为我们这个收件箱读完了以后就不用了,就可以清理掉了,下次再重新拉嘛,其实这个收件箱里一般是不存的。那我们的新游戏呢其实只保存了一份,就是发件人的这个发件箱里,所以比较节省内存空间。但是它的缺点是什么呢?我每次来读消息的时候,都要重新去拉去发件箱的这些消息,然后再做排序,那这一系列的动作啊耗时就会比较久,所以呢读取的延迟往往比较高,特别是如果有一些变态,他一个人关注了成百上千的人,甚至上万的人,每个人如果有几十条消息的话,将来你一拉是不是几万条,那这个耗时就更高了。所以说拉模式它的缺点主要缺点就是延迟。
②推模式
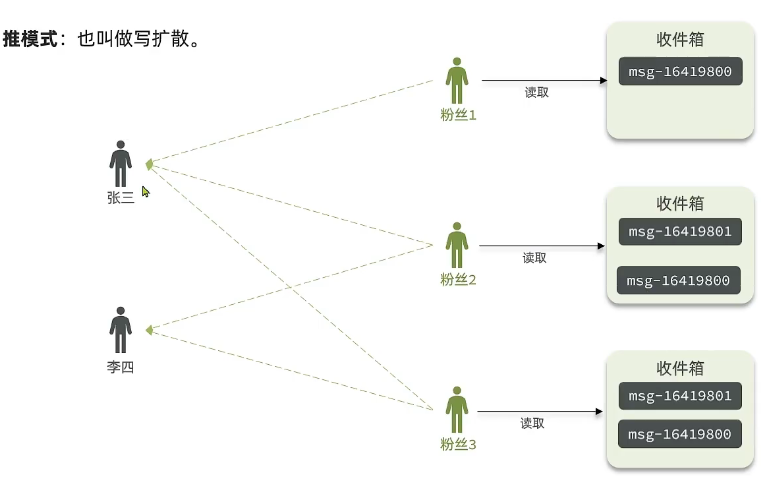
那下面呢第二种模式叫推模式,也叫血扩散。那这种模式就可以去弥补刚才那种模式的缺点啊。比如说现在有两个UP主,张三和李四,然后这次他们可就没有发件箱了,假如说有三个粉丝,粉丝一、粉丝二、粉丝三也关注了张三和李四。假设说现在张三要发消息,他没有发件箱,那我消息往哪发呀,这些消息会直接推送到他的所有粉丝的收件箱里去,所以叫推模式,直接推过去了,也就没有扩散性了。
那么这个消息是不是就写了好几份啊,他有几个粉丝就写几份。那同样李四要发消息呢,也是一样,推送给他的粉丝推测他的收件箱去,然后对收件箱里的消息做一个排序好了。那这个时候我们的粉丝啊想要来读的时候,那直接拿到的是不是就是完整的消息了,并且是排序好的,就不需要临时去拉取和排序了,就不用了。那因此它的延时就非常的低,是不是弥补了拉模式的那个缺点。但是呢他也有自己的缺点,什么缺点,你看吧,你发消息的时候没有发现枪了吗,你不得不把这消息发给每一个粉丝啊,写给每一个人,那是不是写了好几份啊。
所以这种消息的扩散方式,不是通过读的时候扩散,而是在发的时候直接写给他们了,所以他就写扩散。那正因为此呢,它的内存占用会比较高,一个消息要写n份。我们假设说这个张三是个大V,他有成千上万的粉丝啊,你像那个什么微博里面有些大V啊,什么何炅啊什么的,上亿粉丝,那不得了,你这一个消息发出去要保存上亿份,就炸了吗。所以这是它的缺点。但是它延迟真的很低。
③推拉结合
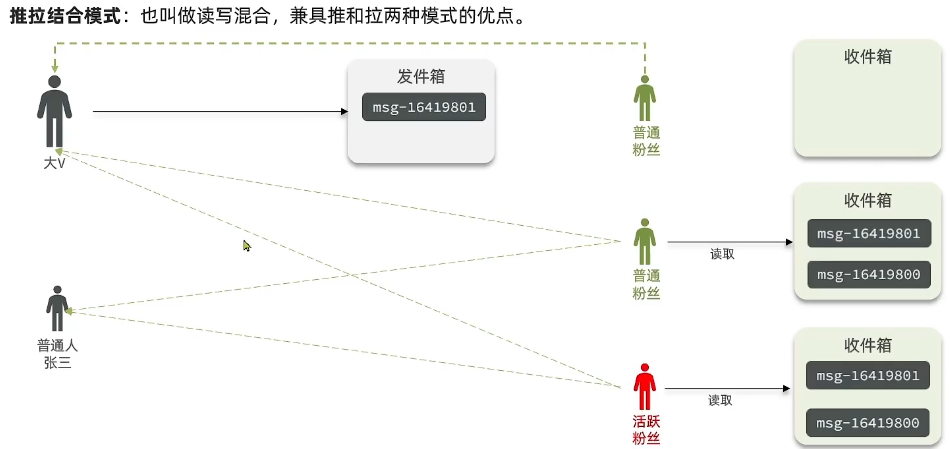
那有没有更加完美的方式,唉就有了第三种推拉结合,而这种模式也叫读写混合模式,它兼具了两种模式的一些优点。比如说现在有一个大V和一个普通人,张三是吧,那接下来呢还有几个用户啊,那用户肯定还会有自己的收件箱吗,现在呢假如说第一个用户啊,他关注了大V,第二个用户呢同时关注了这俩人,第三个也是同时关注这俩人,然后呢如果现在这个普通人张三,他要去发消息,因为他是个普通人,他的粉丝非常少,所以我们可以用什么模式哎,是不是讲了第二种推模式呀,因为他粉丝少,所以说呢你写几份也没什么问题嘛。
那意思当他发现的时候,他就没有发件箱了,而是直接推送给每一个啊粉丝,然后写到他的数据效率就完了,采用了推模式。而大V则不一样,大V的粉丝可能会比较多呀,不过呢粉丝虽然多啊,确实有差异的,大家会注意到我这个粉丝啊,有一个粉丝标红了啊,叫活跃粉丝。你应该知道啊,虽然何炅在微博上有几亿粉丝是吧,但是你该知道大部分应该都是僵尸粉,其实任何一个人都是这样,还有很多粉丝呢,平常都不怎么上线了,偶尔来看一看,但是有一些人粉丝头是吧,那饭圈里面那些啊非常变态的,他就会有一个活跃粉丝,天天都在线上啊,今天看一下,明天看一下啊,或者一天看好几次。
所以呢我们在后台就可以把粉丝啊,分成两类去做处理,既然活跃粉丝数量不多,我们就可以利用推模式,而普通粉丝呢数量超级多,我们呢就采用拉模式。那这样呢就推拉结合,既节省了内存啊,又照顾了一些活跃用户的感受啊,因此呢大V需要有一个发件箱,当大V一发消息的时候,那些活跃粉丝因为经常看我们将采用推模式,直接推到他的视频下,而至于普通人了,平常都不怎么上线,我发给你不也浪费吗,所以说呢发到发件箱里,那因此大V的消息就会发件箱里一份,然后呢所有的活跃粉丝一份放到数据箱里,这个时候活跃粉丝他受教权的消息肯定要做个排序,当他来读取的时候,是不是直接读到了啊,不需要临时拉去,也不需要临时排序。
所以呢活跃粉丝它读取的时候,这个延时就非常的低,诶他看的频繁了,我肯定要延迟低一点,而对于普通粉丝来讲呢,那当他要来读取的那一刻,我在临时的去拉取大V发件箱里的消息,给他做个排序,这样就ok了。那因此呢普通粉丝他平常也不怎么来,偶尔来一次,那稍微延迟低一点,是不是也无所谓啊。那这样呢我们就照顾了什么呢,这些活跃用户的感受啊,那普通粉丝呢他只是某些大V的消息,需要临时拉取,其实呢拉取的也不多,所以说呢效率也还可以,而对于那些啊永远不上线的僵尸粉,那根本就不需要去拉啊,因为我拉它干嘛呢,是不是就节省了内存空间了。综合来讲,推拉结合这种模式啊,就兼具了推模式和拉模式的优点了。
| 拉模式 | 推模式 | 推拉结合 | |
| 写比例 | 低 | 高 | 中 |
| 读比例 | 高 | 低 | 中 |
| 用户读取延迟 | 高 | 低 | 低 |
| 实现难度 | 复杂 | 简单 | 很复杂 |
| 使用场景 | 很少使用 | 用户量少、没有大V | 过千万的用户量,有大V |
基于推模式实现关注推送功能
需求:
①修改新增探店笔记的业务,在保存blog到数据库的同时,推送到粉丝的收件箱
②收件箱满足可以根据时间戳排序,必须用Redis的数据结构实现
③查询收件箱数据时,可以实现分页查询
@PostMapping
public Result saveBlog(@RequestBody Blog blog){
//获取登录用户
UserDTo user = UserHolder.getUser();
blog.setUserId(user.getId());
//保存探店笔记
return Result.ok();blogservice.save(blog);
}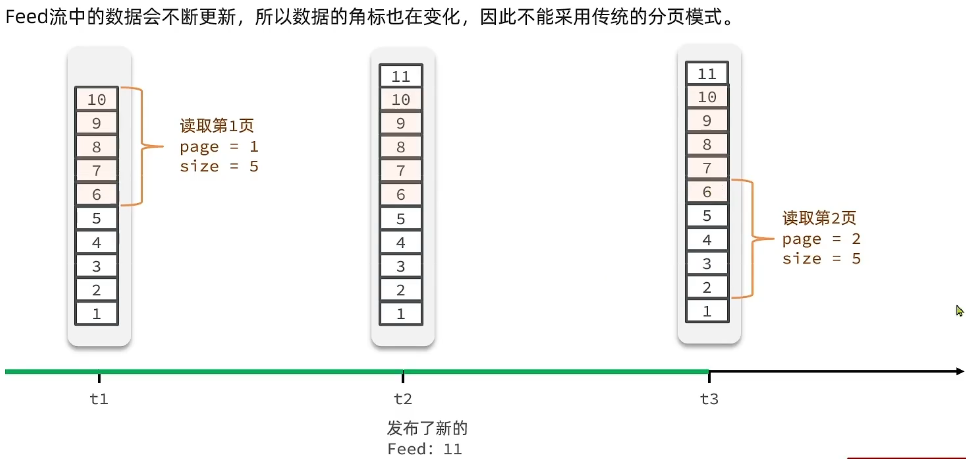
在Feed流中,数据会不断变化,因为不断有人发布新的消息,这些消息会持续进入我们的队列中,导致排名不断变化,因此游标(cursor)也在变化。此时,如果你仍然采用传统的分页模式,就会遇到问题。传统分页模式是按照游标进行查询的。为什么这样呢?我们来看一下。
假设时间轴到达了t1时刻,此时收件箱里有十条消息,这些消息按ID或时间戳从大到小排列。如果我们按游标查询,比如要查第一页,每页查五条,我们传的参数可能是0, 3(配置,配置-1,乘以一个size,算出来是0,从0开始查五条,正好是这一部分)。当第一页查完后,时间到了第二个时刻,有人插入了一条新数据,这条新数据因为是最新的,所以排名靠前,它的游标变成了0,原来第六条的游标是4,现在变成了5。
到了第三个时刻,我们来读取第二页,给的参数自然就是配置等于2, 3=5(配置等于2, 2-1, 乘以一个size,等于五,游标从五开始)。从5开始查,012345,又从6开始,这就会出现重复读取的情况。因此,这就是Feed流不能采用传统分页的原因,因为数据的变化导致游标变化,分析出现混乱。
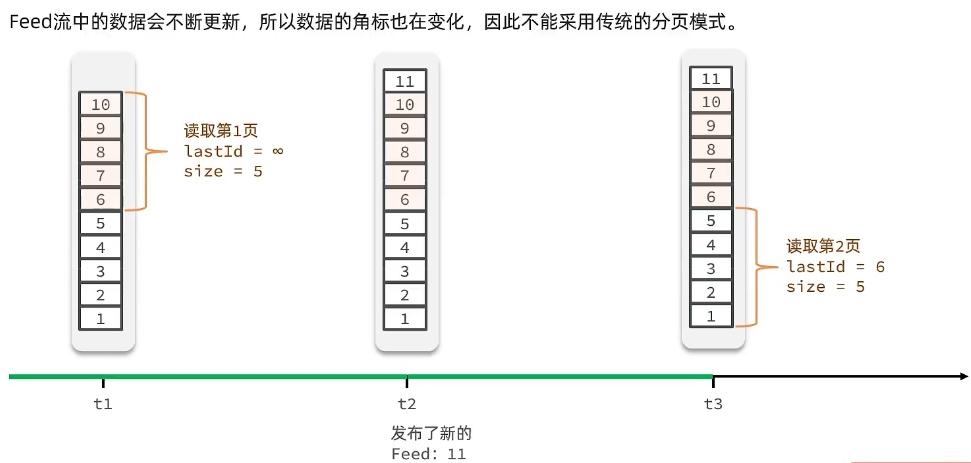
那怎么办呢?所以这里我们只能采用滚动分页模式。什么叫滚动分页?其实就是记录每一次查询的最后一条,下一次从这个位置开始查,这就叫滚动分页。因为我们这里的顺序是有序的,所以完全可以按照顺序,每次记住最后一条,下一次从它往后查就好了。
有人说,你这个每次记住上一次查询的最后一条,那我第一次查询怎么办?既然我们是倒序从大到小,那第一次的时候,完全可以把起始的ID指定成无穷大(或者时间戳也行,反正直接成无穷大),然后查五条,这样就从最大的开始,查五个12345,刚好678 90,对不对,就这几个。
然后到了第二时刻,有人插入一条新数据11,按照刚才说的,11会跑到队列最上面。好,这上面以后游标发生改变了,没关系,因为我们不是按游标查,我们是按照ID,那这一次我查询的last id是谁,我上一个查的最小的那个是不是六啊,所以下一次我是不是就拉出来,就等于六,从六开始往后查五条,那么刚好是54321,所以会不会出现重复了,不会吧。所以这就是滚动分页的实现原理,这是因为他的查询不依赖于游标,所以就不会受到Feed流中数据变化、游标变化带来的影响。
那么问题来了,我们的类似结构支持这种滚动分页吗?显然不行,因为在list里我们查询数据啊,只能按照游标查询,或者是首尾,首尾更不行了。所以list不支持滚动分页,而sorted set我们之前说了,set它会按照score排序,然后有一个排名,如果你按照排名查询呀,那跟游标查询没什么区别,但是我们的set呀,还支持按照score范围进行查询,我们的思考值就是我们时间戳嘛,我们把时间戳按从大到小的顺序做个排列,每一次查询的时候啊,我都记住最小的那个时间戳,然后下次查询时我再找比这个时间戳更小的,这样是不是就实现了滚动分页了,那数据也就不会重复了。
因此最终胜出的是谁啊,sorted set。所以大家记住了,如果你的数据会有变化的情况下,那尽量不要使用list这种队列去做分析,而是使用sorted set。那同样你以后做排行榜的话,你也要注意这一点。那接下来不废话,我们就去实现一下,我们先来实现什么了,每当有人发布笔记时,把这个笔记保存到我们的sorted set。
我们修改blogcontroller,删掉,全部改为在impl中操作
@PostMapping
public Result saveBlog(@RequestBody Blog blog) {
return blogService.saveBlog(blog);
}
数据库中tb_follow的有user_id和follow_user_id。分别是关注人和被关注人
//前面补个
@Resource
private IFollowService followService;
@Override
public Result saveBlog(Blog blog) {
//1.获取登录用户
UserDTO user = UserHolder.getUser();
blog.setUserId(user.getId());
//2.保存探店笔记
boolean isSuccess = save(blog);
if (!isSuccess) {
return Result.fail("新增笔记失败!");
}
//3.查询笔记作者的所有粉丝select*from tb_folLow where follow_user_id=?
List<Follow> follows = followService.query().eq("follow_user_id", user.getId()).list();
//4.推送笔记id给所有粉丝
for (Follow follow : follows) {
//4.1.获取粉丝id
Long userId = follow.getUserId();
//4.2.推送
String key = "feed:" + userId;
stringRedisTemplate.opsForZSet().add(key, blog.getId().toString(), System.currentTimeMillis());
}
//4.返回id
return Result.ok(blog.getId());
}我们用可爱多的号发一套消息,可以在数据库中查到
可以看到redis里面都有id是24号的blog
在这儿呢我已经提前准备好了一个集合,sortset set集合这里边有六个元素
然后他们对应的扣值啊分别是1~6,而它们的名称呢恰好也是1~6,这样方便我们将来去看这个规律,然后这个score值呢你就把它当成是时间戳,时间戳肯定也是有大有小,我们将来要对时间戳做一个排序,而且是降序,这样来时间越大的代表越新数据,那它排名了自然也就越靠前,然后呢我们再去做分页啊,比方说我们每页查三条啊,那我查第一页的时候,那其实就是查654啊,第二页是321啊,这是我们期望目标
127.0.0.1:6379> ZREVRANGE z1 0 2 WITHSCORES
1) "m6"
2) "6"
3) "m5"
4) "5"
5) "m4"
6) "4"
127.0.0.1:6379>
#此时插入一个新的数据,模拟数据混乱的情况
127.0.0.1:6379> ZADD z1 7 m7
(integer) 1
127.0.0.1:6379> ZREVRANGE z1 3 5 WITHSCORES
1) "m4"
2) "4"
3) "m3"
4) "3"
5) "m2"
6) "2"
在Feed流中,数据会不断变化,因为不断有人发布新的消息,这些消息会持续进入我们的队列中,导致排名不断变化,因此游标(cursor)也在变化。此时,如果仍然采用传统的分页模式,就会遇到问题。分页实际上有两种:按游标分页和滚动分页,不同的分页方式效果也不同。
按游标分页在我们使用的Sorted Set中就是按排名分页,使用的命令叫做`ZRANGE`。`ZRANGE`命令需要指定key,然后指定`min`和`max`,这是分页的依据,也就是排名的最小值和最大值。例如,如果Redis中已经有六条数据,排名是倒序排列的,那么名次分别是0、1、2、3、4、5。如果我们指定0~2,那是不是刚好查前三条。利用这种方式就是按游标分页。
如果我们回到命令行,最小值最大值就是它的排名,也就是游标,然后后边你可以指定是否要带上分数。我们来试一下,当然这是按照升序排列的,但我们刚才说要按降序排列,按降序的话,需要把`ZRANGE`前面加上一个`REV`(反转的意思),命令就变成了`ZREVRANGE`。参数基本一样,我们来试一下`ZREVRANGE`,直接key,然后直接开始0,然后到2结束,这不就是我们刚才讨论过的差`D`,`0~2`,然后`WITHSCORES`,这个是指结果中带上分数。
此时如果插入一条新的数据,我们模拟一下这种数据混乱的情况。`ZADD`插入一条新的数据,`Z1`,然后它的值是7,因为现在插入的是一个分数为7的元素,它的值是最大的,也就是代表最新的数据,是不是会跑到我们排名的最前边。那此时的游标就混乱了,本来我们的4号元素游标是2,插入了一个新的元素以后,它游标是不是非常变化了。所以这个时候再来查第二页,那理论上第二页查的时候应该从哪儿开始查,第一页查到2了,那第二页是不是从3开始查,3、4、5查到5,应该是这样查吧。我们期望查到是不是3、2、1,但你实际查到是4、3、2,刚才说过了,游标发生变化了,所以这就是按游标查询所存在的问题。
要解决这个问题,就不能按游标查,那按什么查呢,按分数score查询。我们回到桌面客户端,也就是说我不看游标了,我看分数65432,对吧,我查的时候第一次我就从最大的分数开始查,查三条,我就数三条,我不管你游标是什么,从最大开始654,第一查完了,当我要查下一页的时候怎么办,诶,我记住上一次查到哪了哦,上次查到4了是吧,好,既然是有序的,而且是倒序,那我下次再查出,我只要查比4小的那些数据就OK了。注意听了,找比4小的那些数据就行了,所以说按照分数大小来排列,第四小吧,从这开始刚好三条是不是3、2、1,所以它就能避免因为游标变化导致的混乱了。我们来试一下,我们打开控制台,这里首先要去看一下命令,这个命令会不一样,它不再是`ZREVRANGE`了,而是`ZRANGEBYSCORE`,也就是根据分数差,而这个地方指定的也不是游标的开始结束了,而是分数的最大值和最小值。现在我们来试一下,来`ZRANGEBYSCORE`对吧,`k`还是`z1`,最大值是谁呢,我们给你找好了,最大值是不是上一次查询的最小的那个分数啊,那我现在是第一次来啊,那我这个给什么啊,那肯定是给当前时间戳的最大值了,因为将来我们这个思考值可不是456,我们是什么,我们是时间戳,所以作为时间戳来讲,最大值就是什么,是不是就是当前时间戳啊,那我们现在既然是用456这种数字来模拟的,那咱们就随便给个值,1000够大了吧,那接下来你记住啊,这个最小值就是当前时间戳好,那最小值其实最小我们关心吗,不关心对不对,你看我们刚才讲了,我们滚动查询的思路是记住上一次的查到哪了,从哪开始数三条就行了,所以我只关心两个事,第一从哪儿开始的,第二总共差几条,所以你这个最小值我是不关心,那不关心,我就给个最小值呗,时间的最小值是0,因为时间没有负数,是不是好了好,然后呢问你要不要带分数啊,那我带上呗,`WITHSCORES`好,到这没有结束,因为你还要告诉他一件事啊,就是从这开始我要查几条呢,哎所以后面还有`LIMIT`,那么这个`LIMIT`里面有俩参数,`offset`和`count`,这里的`offset`代表的含义是指偏移量什么,偏移量就是从最大值开始的第几个元素查询,而这里的最大值最小值啊都是包含关系啊,大于等于小于等于,所以说呢如果偏移量你给了零,就是从啊小于等于最大值的第一个元素开始查,那如果给了一呢,就是小于等于最大值的第二个元素开始,那在这儿呢我们是第一次来,那我们肯定是从第一个元素开始嘛,所以在这儿呢我们给零,但是如果你是第二次或第三次来,那这个地方可就不一定了,ok后边跟上`count`,这个`count`是指总共查几条,比方说我们就查三条,那就给三角形好,写完了走查了是765啊,因为刚才有一条七嘛,对不对,好765,那我现在再查下一页,我期望查到的是什么,是不是432,但是就在此时,有人插入一条新的数据是八,那一旦他出了一个新的八,那线是最大的,它是不是跑到了我们最前面去了,少了一个`z1`啊,是不是跑到最前面去了,那它一旦跑到最前边,那理论上讲,如果按照游标查,是不是混杂了,但现在我们按照范围查,好注意看了,我们讲了要指定最大值,最小值对不对,最大值是上一次查询的什么最小值,因为它是按这个分数倒序,我只要找比他小就行了,比谁小b5,因为上次查询最小值是不是五比五小的啊,最小值不管,然后呢,`WITHSCORES LIMIT`,这个地方不能给零啊,刚才说了,零代表的是小于等于最大值的第一个元素,那这里的最大值是五,那是不是把五也包含进去了,当我们要从五开始,是不是要找下一个,所以这个偏移量就不能给零了,要给成一,对不对啊,size不变还是三,好走,你看432,这就是滚动查询,每一次查询都记住上一次查询的最小值是谁,这样就能避免重复查询,不用关心啊前边的排名有没有变化,是不是解决了这个问题了。
那我们来总结一下,要想实现滚动查询和滚动分页,其实我们一定要传四个参数,对不对,分别是最大值、分数的最大值、分数的最小值、偏移量offset以及查的数量。在这里面其实有两个值是固定不变的,最小值,因为我们在做滚动分页的时候,我只关心的是上一次查到哪了,以及总共差几条嘛,所以这个东西不用管,永远给零就行了啊,而每页查几条,这个东西值是不是也是固定的,你每页查多少条,那肯定就是三嘛,咱们这个分页将来跟前端商量好是不行了,或者你五什么的,但肯定是固定的,所以呢这两个东西将来咱们是不用管就写死,但是变化的是什么,变化的是这个max,这不是最大值吗,这个最大值我们刚才说了,它是每一次啊查询的时候要去找什么,找上一次查询的那个最小的分数,这样下一次我是不是从这开始往后查就行,是上一次查询最小值,因此它是可能会变化的,每一次就找上查询最小值,谁除外呢,第一次除外,第一次的时候没有上一次查询,对不对,所以第一次的时候怎么办,第一次我们刚才讲了,给时间戳的最大值,也就是当前时间戳啊,这个值将来我们要去动态的变化,还有哪个叫动态变化,还有就是这个limit,第一次limit的时候,我们给零,因为第一次来肯定是从第一条开始,没什么好说的啊,不能有偏移量,但是呢以后就不行了,因为这个五默认是小于等于的意思啊,那如果说你给了零,也就是包含那五就又插回来了,那不行,我们是从它开始不包含它,所以说这个地方offset是一,也就是从它的下一个开始,也就是说第一次来给零,后来给一
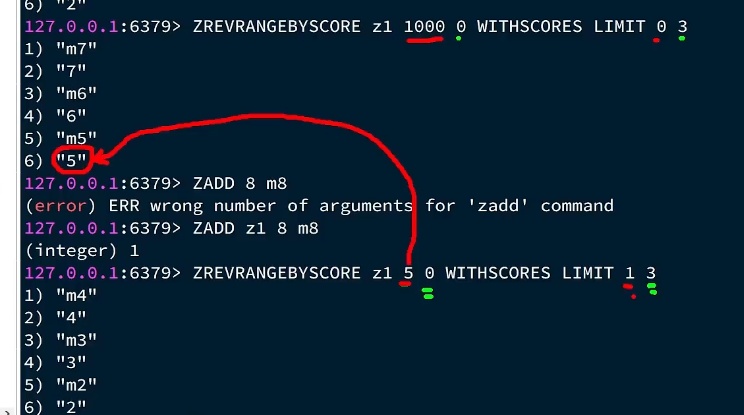
此时z1里面有8个值对, 应该查到的应该是876,543,现在把7号元素的score改为6,我们再打开控制台,在多线程环境中,多个线程可能在同一毫秒内生成时间戳,导致时间戳重复,尤其是秒级时间戳,可能重复。
127.0.0.1:6379> ZREVRANGEBYSCORE z1 1000 0 WITHSCORES LIMIT 0 3
1) "m8"
2) "8"
3) "m7"
4) "6"
5) "m6"
6) "6"
127.0.0.1:6379> ZREVRANGEBYSCORE z1 5 0 WITHSCORES LIMIT 1 3
1) "m4"
2) "4"
3) "m3"
4) "3"
5) "m2"
6) "2"
127.0.0.1:6379> ZREVRANGEBYSCORE z1 6 0 WITHSCORES LIMIT 1 3
1) "m6"
2) "6"
3) "m5"
4) "5"
5) "m4"
6) "4"
显然6被重复查询了,应该跳过和上一次查询大小一样的所有值。跳过的是上一次查询中与最小score一样的元素个数 而不是整个集合set中score一样的元素个数;有bug:当score(时间戳)相同的数量大于count的二倍时,就会重复死循环查询
滚动分页查询的参数总共有四个:max、min、offset和count。在这些参数中,有两个我们通常不需要管理,一个是min,这个时间戳的最小值,我们通常不需要关心,因为它总是零;另一个是count,只要与前端协商好,确定每次查询的条数,它的值就是固定的,比如我们决定每次查三条,那么count就固定为三。
对于max参数,它的值有两种情况:
- 第一次查询时,由于没有上一次查询,所以这个最大值我们给的是当前时间戳,因为对于时间戳来说,当前时间就是最大值。
- 如果不是第一次查询,而是后续的再次查询,那么
max值就是上一次查询的最小值。
对于offset参数,也有两种情况:
- 第一次查询时,我们肯定从第一个元素开始,所以
offset给零。 - 如果不是第一次查询,那么
offset的值取决于上一次查询的结果中,与最小值相同的元素有几个,它就是几。在上一次的结果中,与最小值相同的元素的个数,就是我们的offset值。例如,如果上一次结果中有与最小值相同的元素有两个,那么offset就是二。
滚动分页查询参数:
max:当前时间戳 丨 上一次查询的最小时间戳
min:0
offset:0 | 在上一次的结果中,与最小值一样的元素的个数
count:3
在dto中新建ScrollResult文件
package com.hmdp.dto;
import lombok.Data;
import java.util.List;
@Data
public class ScrollResult {
private List<?> list;
private Long minTime;
private Integer offset;
}
blogController中,和BlogServiceImpl中分别实现,IBlogService实现不予赘述
@GetMapping("/of/follow")
public Result queryBlogByFollow(@RequestParam("lastId")Long max,@RequestParam(value="offset",defaultValue="0")Integer offset) {
return blogService.queryBlogOfFollow(max,offset);
}比如最后一个score是6,总共有三个6分的,但是第一页只查出来两个6分的,你跳了三个6分的,那是不是漏了一个?实际上只会跳过2个6,不是说跳过所有重复的,是跳过上一页重复的条数,上一页重复了多少条,就跳过多少条
public Result queryBlogOfFollow(Long max, Integer offset) {
// 1. 获取当前用户
Long userId = UserHolder.getUser().getId();
// 2. 查询收件箱 ZREVRANGEBYSCORE key Max Min LIMIT offset count
String key = FEED_KEY + userId;
Set<ZSetOperations.TypedTuple<String>> typedTuples = stringRedisTemplate.opsForZSet()
.reverseRangeByScoreWithScores(key, 0, 0, offset, 2);
// 3. 非空判断
if (typedTuples == null || typedTuples.isEmpty()) {
return Result.ok();
}
// 4. 解析数据: blogid, minTime(时间戳), offset
List<Long> ids = new ArrayList<>(typedTuples.size());
long minTime = 0;
int os = 1;
for (ZSetOperations.TypedTuple<String> tuple : typedTuples) { //假设5 4 4 2 2
//这里好像有bug,定义时minTime=max,os=offest才对,否则像5 5 5 5 5 4 4等这样连续的打过2次的话,会出错
//4.1.获取id
ids.add(Long.valueOf(tuple.getValue()));
//4.2.获取分数(时间戳)
long time = tuple.getScore().longValue();
if (time == minTime) {
os++;
} else {
minTime = time;
os = 1;
}
}
//5.根据id查询blog
String idStr = StrUtil.join(",", ids);
List<Blog> blogs =query().in("id",ids).last("ORDER BY FIELD(id," + idStr + ")").list();
for (Blog blog:blogs) {
//5.1.查询blog有关的用户
queryBlogUser(blog);
//5.2.查询blog是否被点赞
isBlogLiked(blog);
}
//6.封装返回
ScrollResult r =new ScrollResult();
r.setList(blogs);
r.setOffset(os);
r.setMinTime(minTime);
return Result.ok(r);
}在这里,我们实现查询关注用户博客的滚动分页逻辑。首先获取当前用户ID,通过用户ID定位到对应的Redis收件箱ZSet键。使用reverseRangeByScoreWithScores方法查询时,参数应为max(最大时间戳)、0(最小值)、offset(偏移量)、2(每页数量),而非代码中的固定0值。查询结果为包含博客ID和时间戳的TypedTuple集合。
解析数据时,遍历TypedTuple集合,将博客ID存入列表。针对时间戳处理:初始化minTime为0,遍历过程中若当前时间戳与minTime不同,则更新minTime并重置os计数器;若相同则os递增。但存在逻辑缺陷——当连续多个相同时间戳时(如5,5,5,4,4),应比较当前时间戳是否小于minTime来动态更新,而非直接覆盖。正确做法应初始化minTime为Long.MAX_VALUE,遍历时取当前时间戳与minTime的较小值,并动态维护os计数。
根据博客ID集合查询数据库时,需处理ID顺序一致性问题,使用FIELD函数保持与Redis查询结果相同的顺序。最后封装ScrollResult时,需返回博客列表、当前最小时间戳和offset偏移量,供下一页查询使用。需注意offset实际应返回当前批次中最后一个时间戳的出现次数,而非累计值。
最后一条刷新重复的,看看有没有设置offset的值,注意是将os的值设置进去r.setOffset(os)
还是有问题吧,一次查两条的话,只要中间有4条时间戳一样的,就一直查这4条中的后两条,查不到之后的数据了



Comments NOTHING